포트폴리오) 바로우산

💼개요
ChatGPT, 객체인식, 수요예측 인공지능을 융합해 보유 자산을 관리할 수 있도록 이식한 공유경제 자동화 서비스 개발과 협업 방식을 익히기 위한 목적으로 팀 프로젝트를 진행했다.
📝 프로젝트 진행 기록
💳 주요 기능
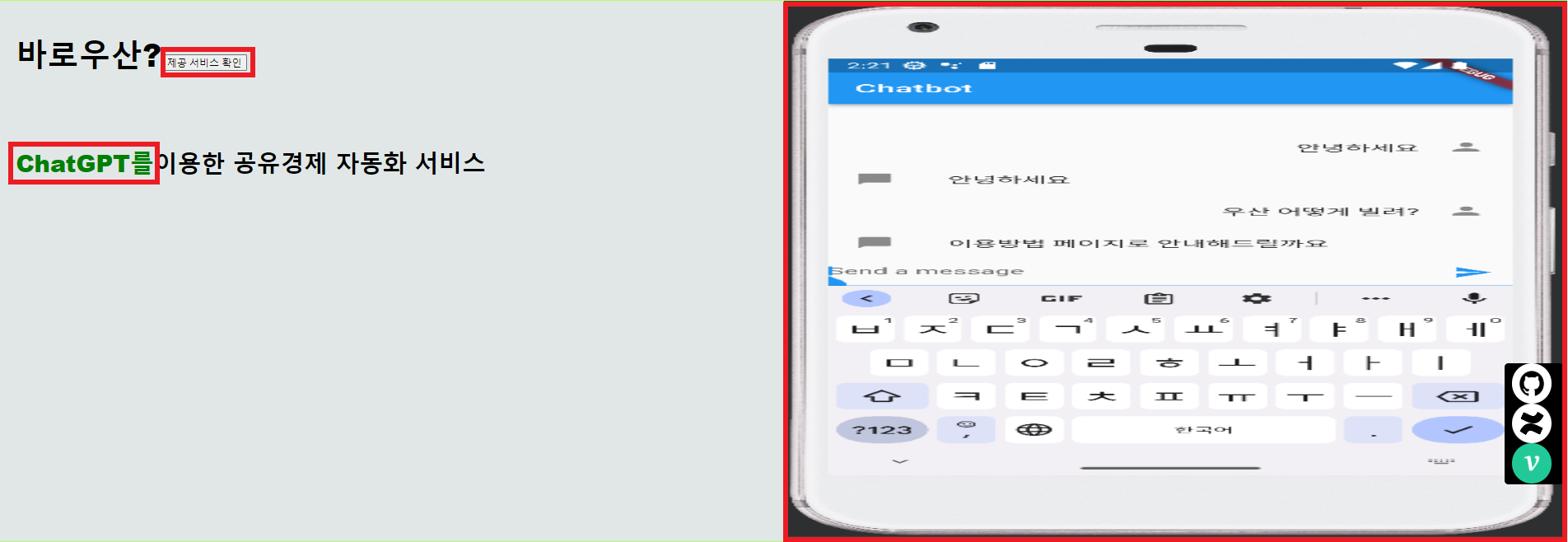
- YOLOv5를 통한 자산 파손 여부 인식
- ChatGPT를 통한 이용자 안내
- Keras를 사용한 인공지능으로 지역에 따른 서비스 수요 예측
👨💻 업무
공통 업무
- Jira, Confluence를 사용한 프로젝트 진행 내역 정리
- FastAPI를 통한 서버 구축
- AWS를 통한 배포
- ERD 작성
전담 업무
- 개발 환경 설정
- 데이터 정형화
- 크롤링을 통한 데이터 수집
- 딥러닝 프레임워크를 사용한 주요 기능에서 사용할 모델 구현
- 웹 목업 작성
- 랜딩페이지 제작
📚 기술 스택 및 툴
- Ptyhon 3.9
- FastAPI
- AWS
- Vue.js
- Keras
- Pytorch
- Flutter
- Github
- Jira
- Confluence
- Slack
개발 환경 설정 ✅
1. Install Django Framework
2. Docker with MySQL
2.1 2022.12. 기준 디폴트로 설정되어 있는 값으로 설치
2.2 재부팅 후 나타나는 링크로 들어가서 업데이트 진행
2.3 create mysql container
# powershell
# 윈도우 터미널을 통해 Docker Container 목록 출력하기
# (-a 옵션은 실행하지 않은 Container도 출력)
(base) PS C:\Users\Quiet\DjangoProject> **docker ps -a**
# 윈도우 터미널을 통해 Docker Container를 생성 및 실행하기
(base) PS C:\Users\Quiet\DjangoProject> **docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root mysql:5.7**
# 컨테이너 접속
# (container ID 값에 해당하는 uuid 값을 컨테이너 name 자리에 넣어주어도 실행할 수 있다)
(base) PS C:\Users\Quiet\DjangoProject> **docker exec -it mysql bash**
# yum update
bash-4.2# **yum update**
# yum install -y vim
bash-4.2# **yum install -y vim**
# my.cnf 설정
bash-4.2# **cd etc**
bash-4.2# **vim my.cnf**
# 키보드 i 누르면 insert 가능
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld] # 추가해주기
lower_case_table_names=1
collation-server = utf8_unicode_ci
init-connect='SET NAMES utf8'
character-set-server = utf8
# 키보드 esc 누르고 ":wq!" 입력 후 Enter
(base) PS C:\Users\Quiet\DjangoProject> exit
(base) PS C:\Users\Quiet\DjangoProject> docker restart mysql # container ID
(base) PS C:\Users\Quiet\DjangoProject> docker exec -it mysql bash
# DB서버 접속
bash-4.2# **mysql -u root -p** (Enter 후 password 입력)
Enter password:
# DB서버에 접속하면 Databases와 Tables를 통제할 수 있다.(DB서버의 함수 사용 가능)
mysql> **show databases;**
# DB를 생성하고 싶다면 create 함수를 이용한다.
mysql> **create database mydb;**
# show에서 볼 수 있는 DB서버의 DB를 사용하고, Tables를 볼 수 있다.
mysql> **use mydb;**
mydb> **show tables;**
mydb> **status;**
# 서버 실행하기
****mydb> **exit**
Bye
****bash-4.2# **exit**
exit
****(base) PS C:\Users\AIA\PycharmProjects\djangoProject> **python .\manage.py runserver**
2.4 PyCharm Database Tab(right side)
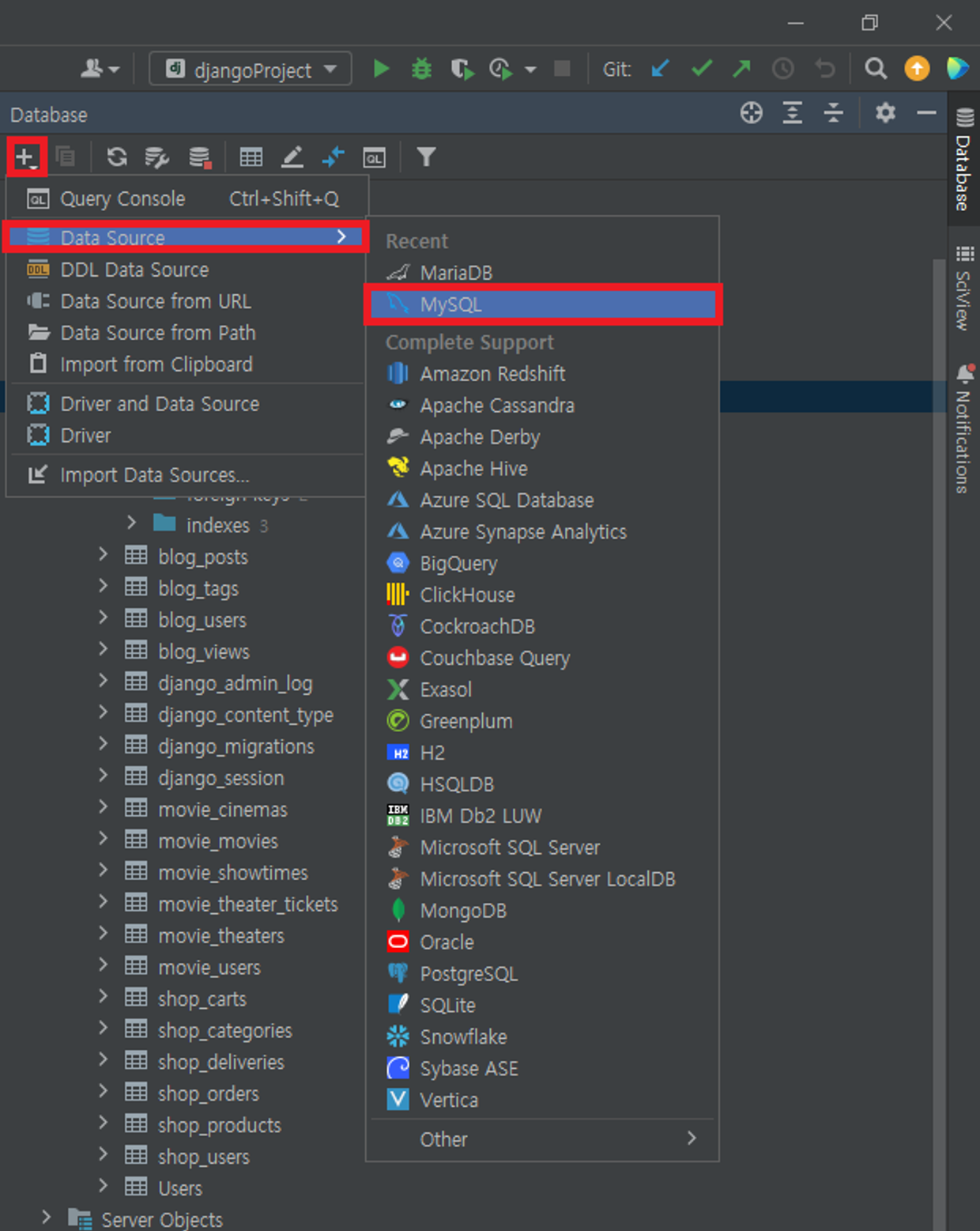
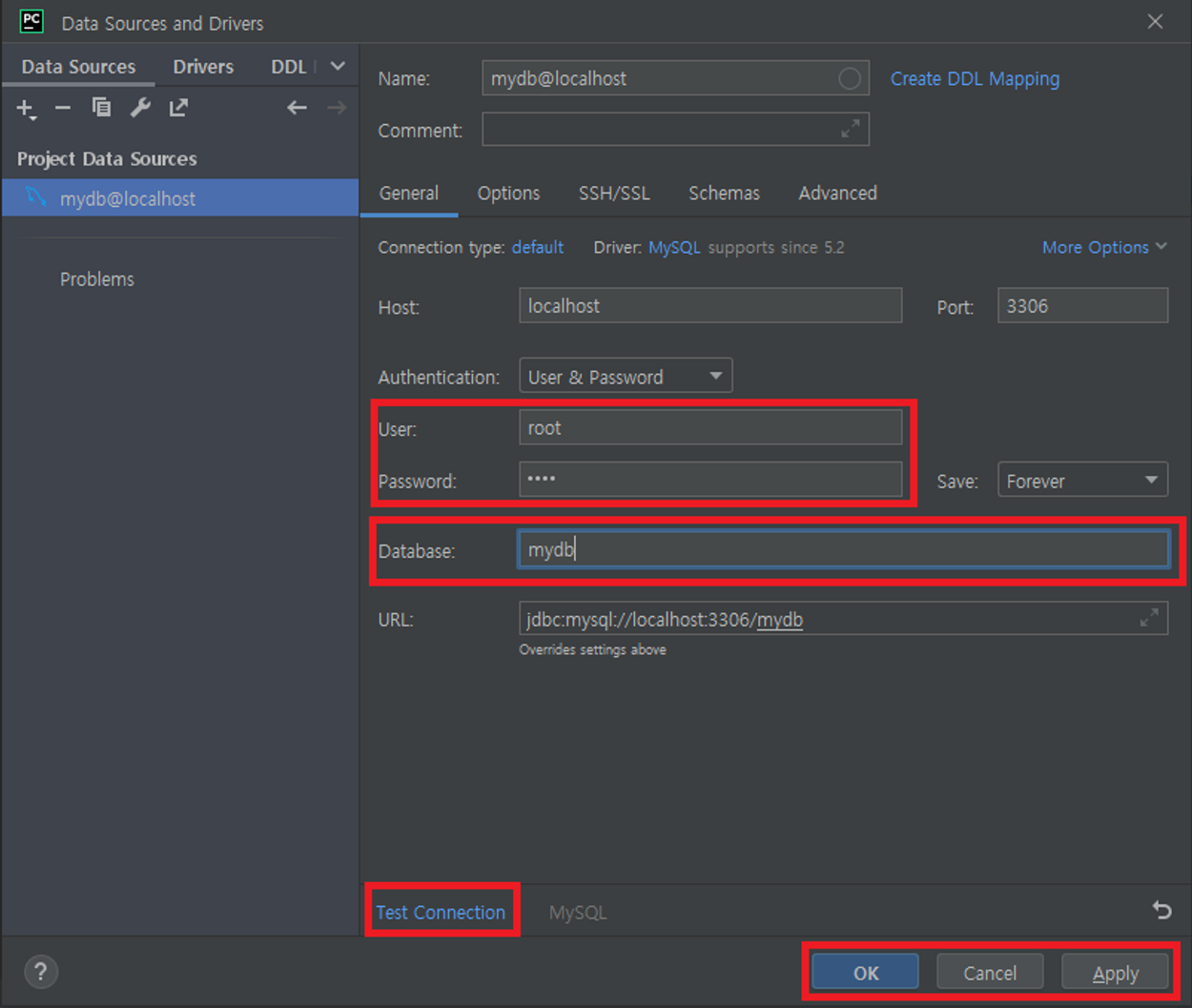
⇒ Test Connection 반드시 누르기
3. Python / MySQL 네트워크 연결
# powershell
# Python과 MySQL 네트워크 연결을 위한 라이브러리 설치
(base) PS C:\Users\Quiet> pip install mysqlclient
(base) PS C:\Users\Quiet> pip install mysql-connector-python
(base) PS C:\Users\Quiet> pip install django-cors-headers4. Install Tensorflow & Pytorch
4.1 Version Check(Tensorflow, Python, cuDNN, CUDA)
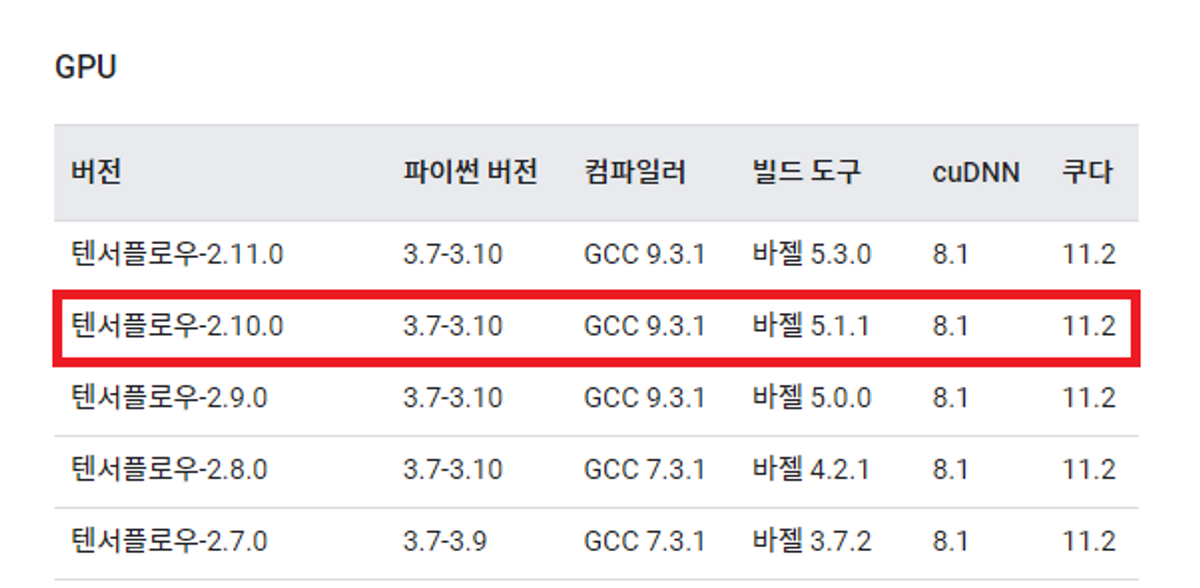
⇒ Tensorflow gpu 사용을 위해 2.10.0 버전을 사용한다.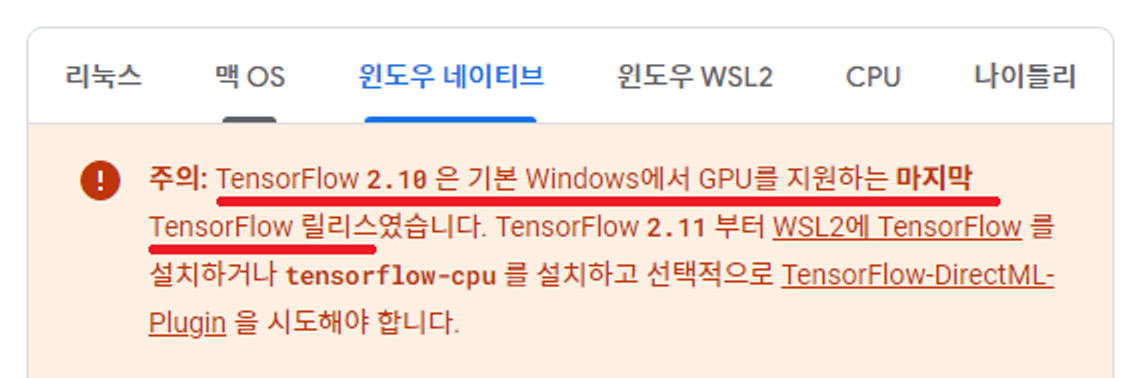
5. Install NVIDIA Driver(GeForce RTX 2080)
5.1 최신 공식 NVIDIA 드라이버 다운로드
⇒ 그래픽카드(GeForce RTX 2080) 기준 설치
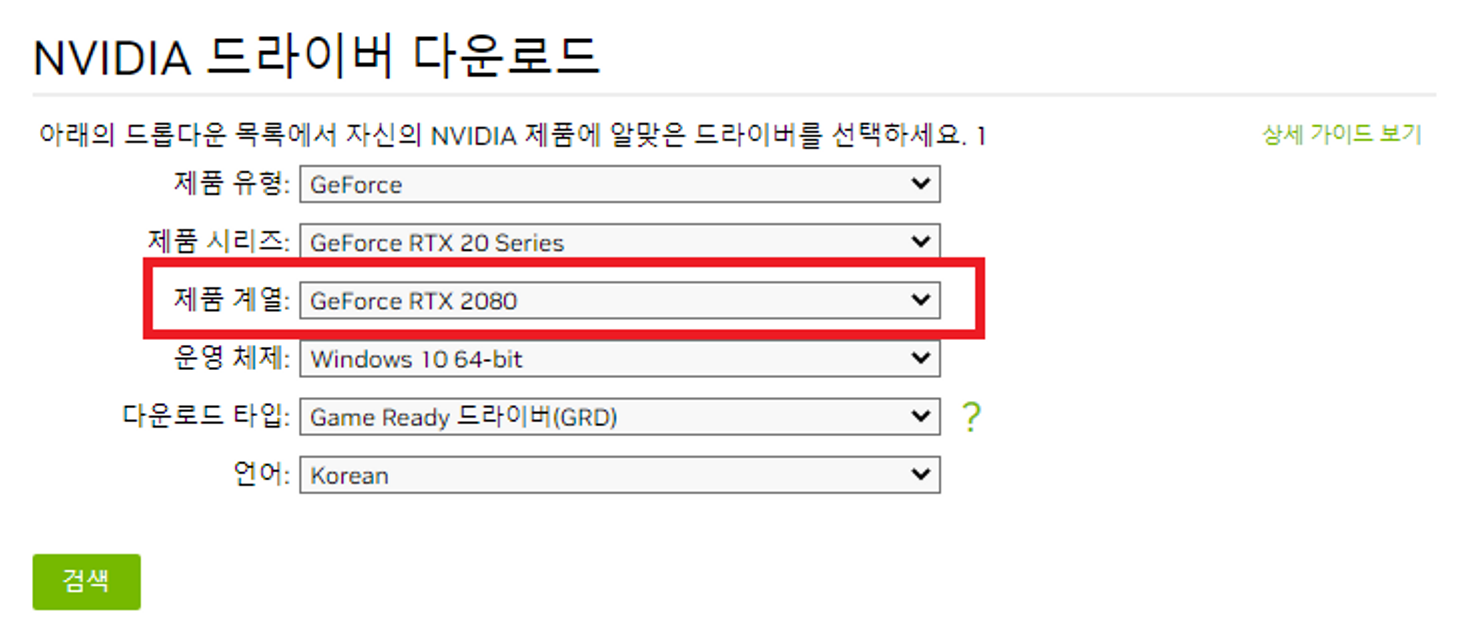
⇒ 디폴트로 설정된 옵션으로 설치6. Install CUDA(ver 11.2)
uninstall NVIDIA FrameView SDK
📖 appwiz.cpl >> NVIDIA FrameView SDK 1.3.8107.31782123
6.1 CUDA Toolkit 11.2 Downloads
⇒ 디폴트로 설정된 옵션으로 설치7. Install cuDNN(8.1.0)
7.1 NVIDIA Developer login
7.2 Download cuDNN v8.1.0 (January 26th, 2021), for CUDA 11.0,11.1 and 11.2
7.3 압축파일 다음 경로에 풀기
📖 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include
7.4 Install Tensorflow(2.10.1)
Update conda and pip
# powershell # 관리자 모드 윈도우 탐색기 (base) PS C:\> pip install --upgrade pip (base) PS C:\> conda update -n base conda (base) PS C:\> conda update --allInstall tensorflow & tensorflow-gpu
# powershell # 관리자 모드 윈도우 탐색기 (base) PS C:\> pip install tensorflow==2.10.1 (base) PS C:\> pip install tensorflow-gpu==2.10.1 # 가상환경에 설치되었는지 확인 (base) PS C:\> conda list
8. Install Pytorch(1.13.1)
0.14.1 Check Install code
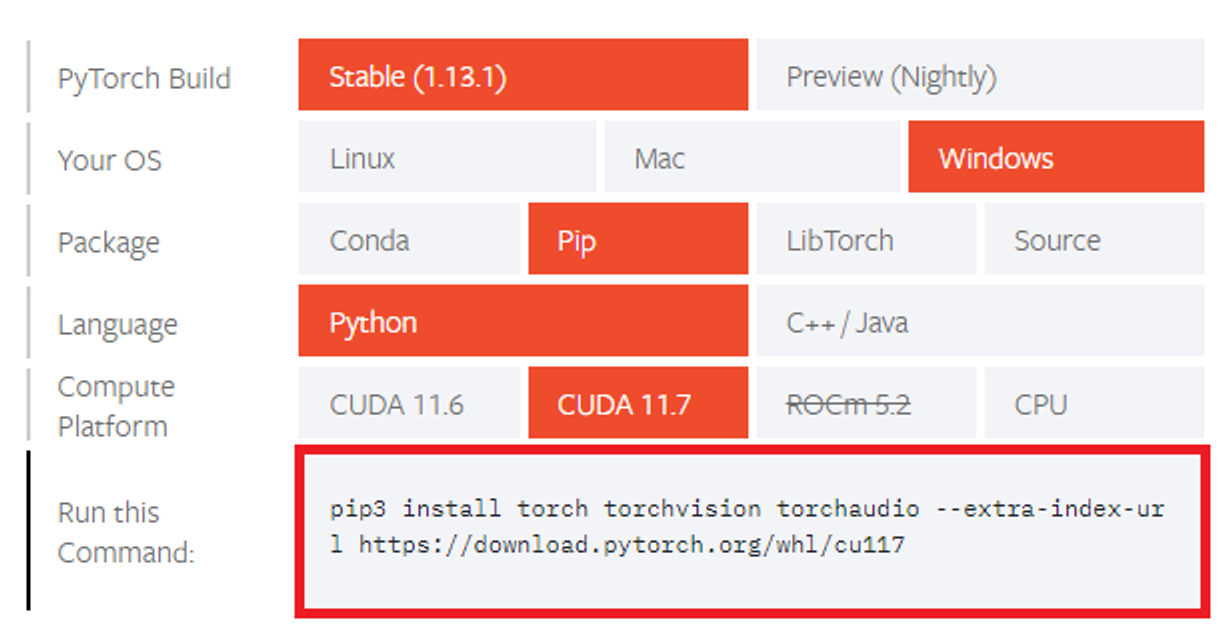
⇒ Conda Package로는 설치가 되지 않았다.(원인미상)
# powershell (base) PS C:\Users\Quiet> pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
※ 참고 CUDA를 분명 11.2를 설치했는데 11.7로 설치하는 이유가 뭐지?
📖 https://kjy042386.tistory.com/324
⇒ 추정) pytorch 구동환경 내 cuda library 복사본을 설치
→ 설정값은 CUDA 11.2 지만, pytorch 구동환경 내 상태값은 11.7인 것
9. Check Version
#**Python Code**
# python
import os
import numpy as np
import tensorflow as tf
import torch
import sklearn
from tensorflow.python.client import device_lib
# TF_CPP_MIN_LOG_LEVEL Default Setting 관련 경고 임시 조치
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
if __name__ == '__main__':
print(f'numpy version : {np.__version__}')
print(f'tensorflow version : {tf.__version__}')
print(f'torch version : {torch.__version__}')
print(f'sklearn version : {sklearn.__version__}')
print(f'이 PC에 설치된 디바이스 상세보기 : {device_lib.list_local_devices()}')
print(f'CUDA 프로그래밍 가능여부 : {torch.cuda.is_available()}')
print(f'CUDA 프로그래밍 가능여부 : {torch.cuda.get_device_name()}')
print(f'사용 가능 GPU 갯수 : {torch.cuda.device_count()}')
```10. Install FastAPI & uvicorn
10.1 pip install
#powershell
# Install
(base) PS C:\fastApiServer> pip install fastapi 'uvicorn[standard]'
# 서버 생성
(base) PS C:\fastApiServer> uvicorn main:app --reload11. 애자일 방식을 위한 Tool 연동
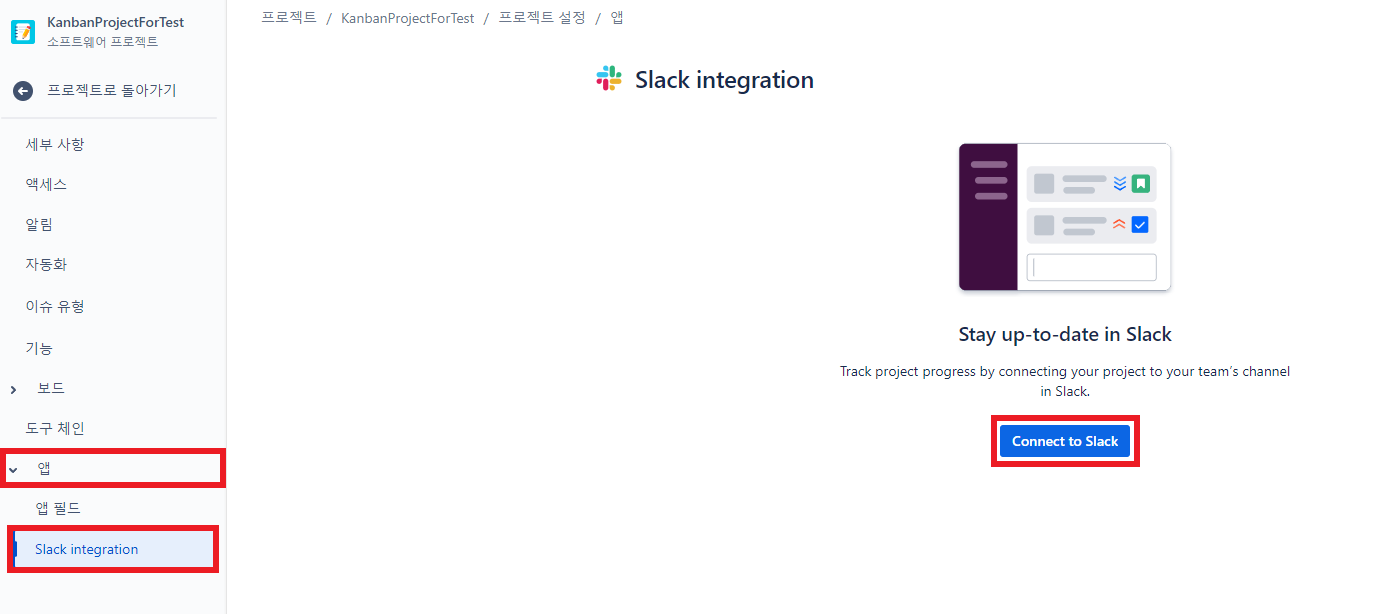
11.1 slsck-jira 연동
- 프로젝트 설정
- Connect to Slack 클릭
11.2 jira-Confluence 연동
11.3 jira-GitHub 연동
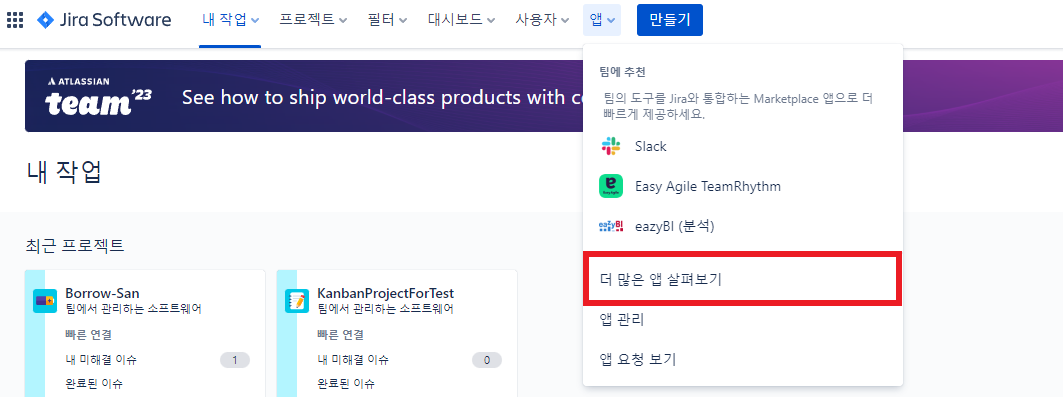
- GitHub for Jira 검색

- 바로우산에서 사용한 앱
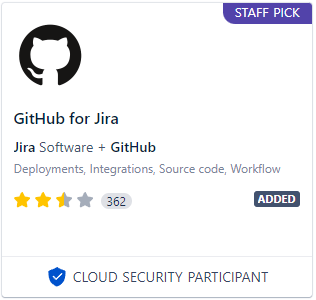
- 추가한다
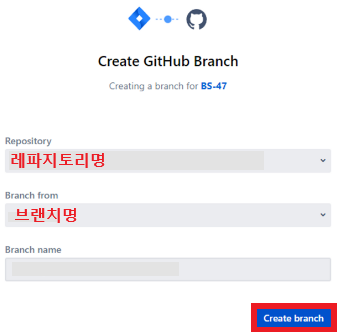
- 추가한 뒤에는 컨플루언스의 업무에서 브랜치 만들기, 커밋 만들기를 누르면
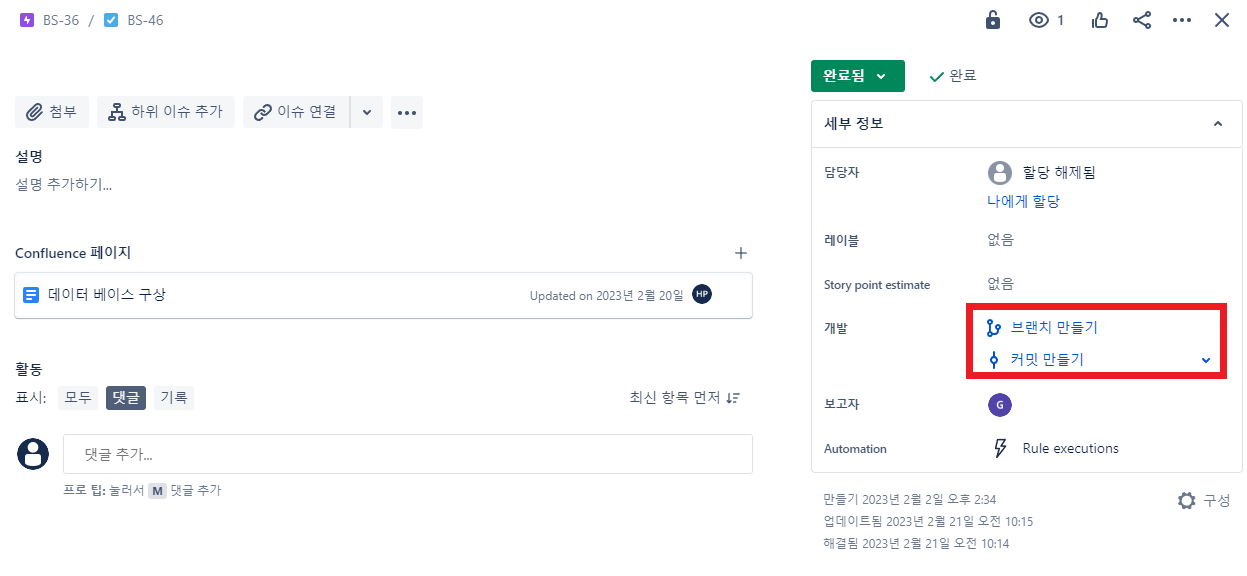
- 아래 이미지가 나오고 Create branch를 누르면 깃허브에 브랜치가 생성된다
AWS☁
1 설정
- fastapi requirements.txt에 추가
- main.py에 handler = Mangum(app) 추가
1.1 DB
- 데이터 베이스 수정에서 db 파라미터를 사용중인 db로 변경
- db가 제대로 들어갔는지는 하이디로 확인
- 하이디의 ip는 db의 연결 보안에 있는 엔드포인트
- fastapi의 db도 host는 AWS의 엔드포인트
이제 docker/mysql 내부의 코드들은 발생x, docker/api만 발생
2. 진행 순서
RDS -> IAM -> S3
3 RDS
3.1 RDS 작성
- 도커파일 및 yml파일 변경 후 dockerfile의 경로인 docker/api로 들어가서 'docker build -t 이미지명 .' 입력
- 원래 경로로 돌아가서 docker compose up
- 자동으로 테이블이 들어와야 성공
🐋 docker compose up 방법이 기억안나면
3.2 RDS 인스턴스 생성
생성하면서 확인
- 표준 생성
- 사용 엔진(이번에는 MySQL)
- 템플릿 : 프리티어
- 인스턴스 크기 : t3(t2도 상관없으나 t3도 프리데이터)
- 스토리지 : 범용, 20, 자동 조정 비활성화
※ 스냅샷 체크를 해제해도 사용으로 된 경우도 있으므로 확인 필요
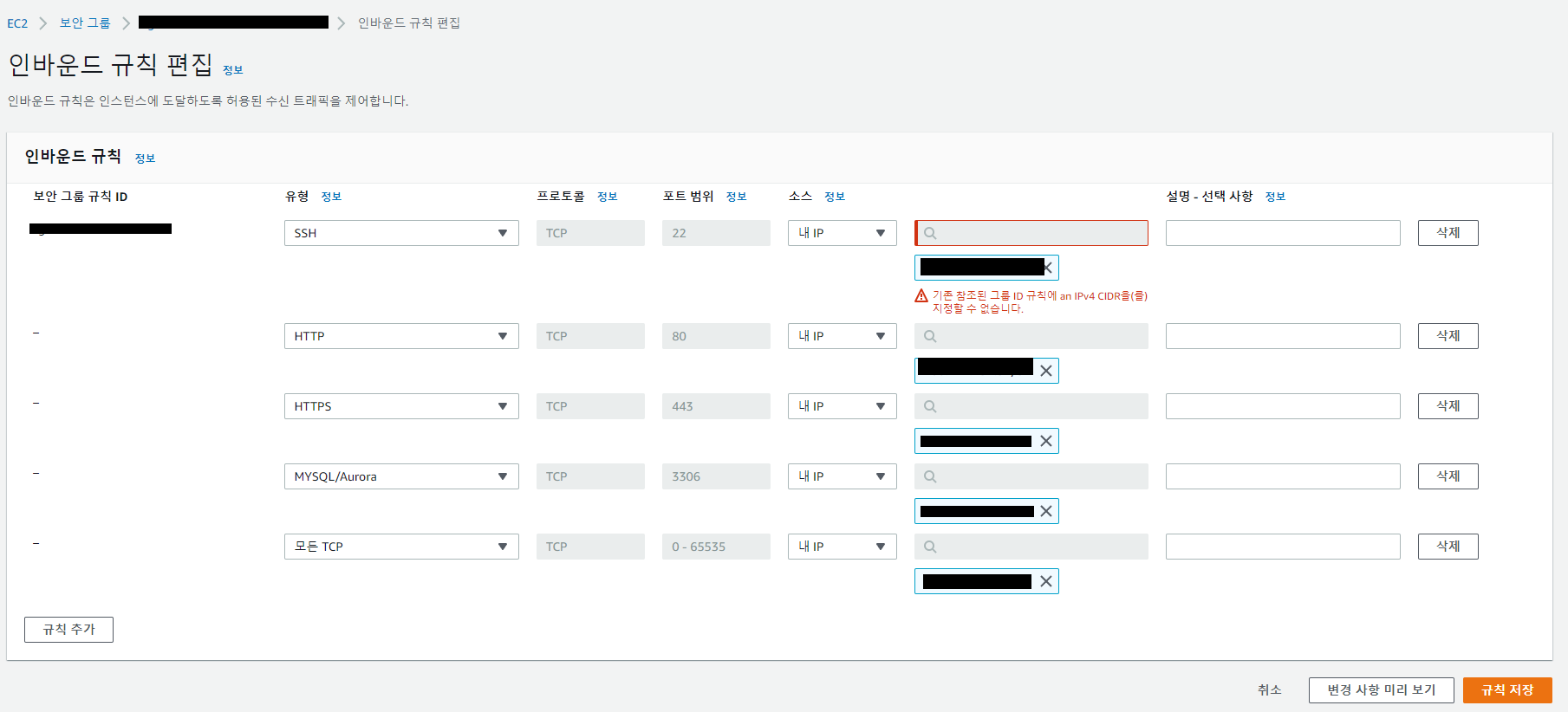
3.3 보안그룹 생성
주의사항
잘못하면 DB 해킹의 위험이 있는 부분이므로 주의
- SecurityGroup 설정에서 보안 그룹을 생성하고 인바운드 규칙을 추가
- 외부 접속 방지를 위해 로컬에서 개발하는 동안은 개인 IP 주소를 설정하지만 EC2로 접속하는 과정이 있으면 추가
- 위치 무관을 체크해야 ubuntu에서 apt-get-update가 적용된다
- 우측 상단 수정 → 생성한 식별자 선택
- 퍼블릭 액세스: 예(마이너 버전으로 변경시 요금 발생)
- 포트폴리오 사용할 일 없으면 : 아니오
- 백업 보존기간 : 0일
- 스냅샷 : 해제
이거 보고도 모르겠으면 여기 참고
3.4 파라미터 그룹 생성
좌측사이드바에서 파라미터 그룹(이하 Parameters)에서 파라미터 편집으로 넘어간다. 검색창에 char, coll 을 각각 입력 후 셀렉트박스에서 utf-8과 utf-8_general_ci 를 선택
- DB 수정 → DB옵션에서 파라미터 그룹을 방금 설정한 그룹으로 변경
4. IAM
4.1 IAM 생성하기
S3 만들기 전에 반드시 iam 을 생성해야 한다. 이 파트를 생략해도 S3 가 만들어지지만, CORS 에서 많은 오류를 경험하기 싫으면 일단 생성하자
, s3
5. S3
5.1 env.py 양식
USERNAME = "AWS 유저명"
PASSWORD = ""
HOSTNAME = "aws 사용시의 엔드포인트"
DATABASE = "AWS의 DB명"
PORT = 3306
CHARSET = "utf8"
DB_URL = f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}"5.2 dockerfile 양식
FROM python:3.9
WORKDIR /app
ADD requirements.txt .
RUN pip install --trusted-host pypi.python.org -r requirements.txt
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--reload", "--host", "AWS엔드포인트", "--port", "8000"]
6. 한글 깨짐
- 파라미터 그룹 -> 파라미터 편집에서
- char : 전부 utf8mb4로 변경(0,1로 나오는 항목은 제외)
- coll : collation_connection, collation_server의 값을 utf8mb4_general_ci로 변경
7. 보안🔒
개인적인 피해를 막기 위한 최소한의 보안
- 인바운드는 어렵게 아웃바운드는 쉽게
1) 사용자 그룹 생성- 권한 정책 연결 : AmazonS3FullAccess 선택
2) MFA 설정
- 준비 : Google OTP 어플리케이션
- root 계정에서 보안자격 증명 → MFA 활성화 → 가상 MFA 디바이스 체크 후 계속
- 먼저 본인 핸드폰에 설치한 Google OTP로 해당 QR코드 인식 후 MFA 코드 1 입력
- MFA 코드 2는 MFA 코드 1 시간 경과 후 나오는 다음 코드
7.1 Root가 IAM에게 비밀번호 변경 권한 주기
- IAM에서 '계정 설정' 클릭
- '암호 정책-> 편집'에서 체크
- 사용자 지정 : 암호감독 체크박스 전체,
- 기타 요구사항 :사용자 자신의 암호 변경 허용
7.2 IAM 로그인시 비밀번호 지정
IAM -> 사용자 -> 사용자명 클릭
-
보안 자격 증명 -> 콘솔 액세스 관리 -> 활성화 후 비밀번호 지정
-
권한을 받은 IAM사용자명, 방금 지정한 비밀번호로 로그인 가능
7.3 권한 부여
- Root 사용자의 IAM으로 들어가서 권한을 준다
7.4 IAM 사용자 결제 대시보드 접근 권한 설정
-
builling은 AdministratorAccess에 포함되어 있다
기본적으로 결제 정보 메뉴에 대한 권한이 없는 IAM 사용자가 해당 권한을 얻기 위한 조건은
- (1) 이 계정이 IAM 및 페더레이션 사용자가 결제 정보에 액세스하도록 허용
- (2) 필요한 IAM 권한을 보유하도록 함으로써 사용자 또는 그룹에 대해 권한
-
(1)은 Root 계정으로만 설정 가능
- 계정 → 결제 정보에 대한 IAM 사용자 및 역할 액세스 :편집
- IMA 액세스 활성화 체크 → 업데이트
8. AWS에서 lambda 사용
yaml(context file)을 사용하는 Serverless Framework보다 IaC방식(TypeScript 사용)인 Pulumi를 더 많이 사용
- serverless와 pulumi 방식중 선택해서 사용
9. CLI(커맨드 라인 인터페이스)
리액트 사용시에는 서버리스 프레임워크를 사용하지만 리액트 같은 프론트 요소가 없는 경우는 CLI를 사용한다
CLI?
AWS 클라우드 리소스를 생성, 편집, 검사하는 방식 중 하나1) 언제 사용?
리액트 같은 프론트엔드 부문의 작업을 위한 경우는 서버리스 프레임워크를 사용하지만, 프론트엔드부분을 신경쓰지 않는 작업에서는 CLI를 사용2) 장점
- 코드(CLI 명령 포함)가 사용자의 변경을 기록
- 버전 제어(깃 등)하에 코드를 배치하고 변경사항을 효과적으로 관리 => 커밋하면 아마존 내부의 코드도 변경
- 수동적인 단계의 수행을 줄여서 작업을 빠르게 다시 실행할 수 있다
- 인적 오류 발생 가능성이 낮다
10. 로컬 AWS 환경 설정
# 액세스 키 만들기
- 경로 : AWS 사용자 설정 - 보안자격 증명 - 액세스 키 만들기 - 액세스 키, 비밀 액세스 키, .csv 파일 다운로드(!!!이 내용은 절대 커밋 금지)
- 유닉스계열(맥 등)은 셸 설정에서 환경변수를 추가
- KMS는 유료 서비스다
# 설정 확인(아래 코드 차례대로 실행)
- aws --version
- aws s3 li s3://
- aws configure 11 S3 버킷 생성
OAC방식
- OAC 설정시 '웹 사이트 엔드포인트 사용'을 누르면 OAC 설정이 사라지니까 먼저 누르지 말것
- S3 버킷 액세스
- 원본 액세스 제어 설정(권장) - 제어설정 생성 : s3로
- 속성 - 생성한 버킷에서 정적 웹 사이트 호스팅 편집 - 활성화 후 변경사항 저장(CF연결할거니까 테스트목적 아니면 하지 말것)
- OAC 방식이 아니더라도 ACM(인증서)가 아니면 자신이 사용하는 리전으로 등록해야한다
11.1 정책 설정
- 경로 : 정책 - 버킷 정책 - 새 문 추가 - 아래 코드 입력
- CF 사용시 버킷정책
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Statement1", "Effect": "Allow", "Principal": {"Service":"cloudfront.amazonaws.com"}, - cloudfront.amazonaws.com를 통해서만 권한 부여 "Action": "s3:*", - 모든 crud를 사용 "Resource": "arn:aws:s3:::seongbae.shop/*", "Condition": { -condition == if "StringEquals" : { - "AWS:SoursArn"의 문자열이 ""과 같다면 "AWS:SoursArn":"클라우드 프론트의 ARN" } } } ] }
12 CloudFront
도메인 | CF | S3
- CF관련 비용 절감 방법
- CF를 억지로 만들 필요 없이 도메인과 S3를 만들면 알아서 생성된다
- 그러니까 CF를 먼저 만들지 마라
- cf의 오리진 = 버킷
12.0 특징
- 고비용에 더 느리지만 보안에 더 유리
- S3에서 CF로의 데이터 전송은 요금이 없으나 인터넷으로 전달하는건 비용이 요구된다
- 같은 리전에서의 전송만 무료니까 설정시 자신이 속한 리전을 설정
12.1 DNS 연결(아마존은 Route53)
- route53 - 시작하기 - 호스팅 영역 생성
- NS(Name Server), SOA가 생겼는지 확인 (NS, SOA에 대한 설명 참고)
- 값/트래픽 라우팅 대상에 있는 값을 NDS에 등록 (이번에는 가비아에서 도메인을 받음. 상세설명은 여기)
- 등록 장소 : 가비아 - My가비아 - 도메인 - 관리 - 네임서버 설정
- 가비아는 NS의 마지막 '.'을 지워야 한다
- 등록 장소 : 가비아 - My가비아 - 도메인 - 관리 - 네임서버 설정
12.2 CNAME 등록
AWS에서
- AWS Certificate Manager에서 인증상태 확인
인증이 안된 상태면 route53에 레코드 자동 생성을 눌렀는지 생각해보자- 도메인 - CNAME 확인
- 'Route53에서 레코드 생성' 클릭
- 한 번 지운 경우는
- Route53 - 호스팅 영역에서 CNAME이 생기면 된다
- A 레코드를 추가하면서 'ping 주소'나온 IP입력
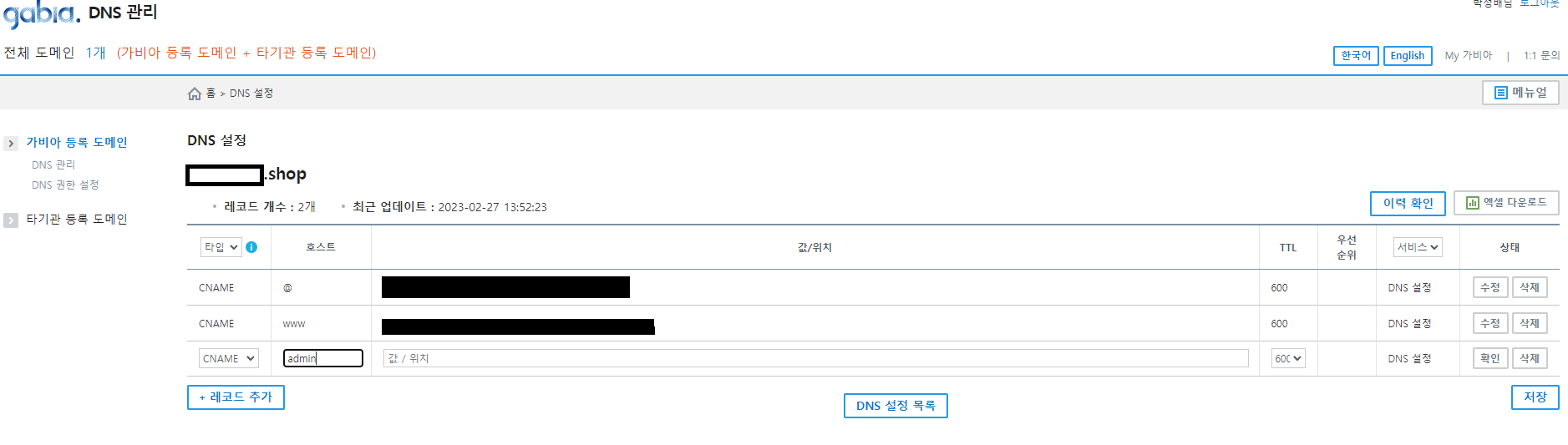
가비아에서
- My가비아 - DNS 관리툴 - DNS설정
- 호스트 : ~.com은 @ / www.~.com은 www(이때 www를 쓴다면 값도 www가, admin을 쓰는 주소라면 admin.이 포함돼야 한다)
- 값/위치 : AWS에서 카피한 CNAME 이름 입력
- TTL:3600
✅가비아에서 제대로 등록됐는지 확인하는 방법
- cmd에서 'ping 주소' 입력
- 후이즈 도메인 검색
- 결과가 안나올 경우 ping 네임서버 1차 주소를 넣고 나온 값을 사용해서 A레코드를 만든다
- 후이즈 통과 후 CF로 이동
12.3 CF 배포
- cloundfront 생성에서 원본 도메인 선택하고 여기를 참고
- 가격 분류는 본인이 사용할 리전이 속해있는 곳에 해야 과한 비용을 막을 수 있다
- CNAME 추가('www.주소.com'과 '주소.com'을 둘 다 해야한다) -> A 레코드로 연결했으면 CNAME의 값을 도메인 이름으로 해도 괜찮다
- ACL를 사용하기 위해서는 먼저 아마존에서 사용하는 DNS인 Route53을 먼저 설정해야 한다(2.2 CNAME 등록 참고)
- SSL은 optional로 되어있지만 보안 요소라 사실상 필수
- IPv6: off(필수는 아니고 수업에서는 일단 off로 지정함 디폴트는 on)
- 버킷과 연결
- Amazon S3 - 버킷 - 권한 - 버킷 정책 편집에서 CF의 ARN추가
"Condition": {
"StringEquals": {
"AWS:SoursArn": "배포하는 CF의 ARN"
}
}12.4 CF 주의사항
- 정적콘텐츠를 s3에 올리지 마라
- OAI는 이제 죽으니까 OAC로 가야된다
- AWS : EC2 / S3 / CloudFront 트래픽 요금 분석
- https://docs.aws.amazon.com/ko_kr/AmazonCloudFront/latest/DeveloperGuide/private-content-restricting-access-to-s3.html
- 왜 쓰나?
자동확장 : 스케일링
13 EC2
13.1 보안그룹 확인
보안그룹 생성은 설정 필기에서 확인
13.2 인스턴스 생성
경로 : EC2 - 인스턴스 - 인스턴스 생성
- 우분투 선택
- 인스턴스 시작 후 PuTTY 사용
- .pem을 .ppk로 하는건 Puttygen사용
- 퍼블릭 ip를 입력하고 세이브 (먼저 있던 경우는 )
- Connection - SSH - Credentioal에서 .ppk 연다
☕install java
sudo apt-get update
sudo apt-get install -y --no-install-recommends tzdata g++ git curl
sudo apt-get update
sudo apt-get install openjdk-11-jdk
java -version
javac -version
vim ~/.bashrc
- i 입력으로 insert로 두고 가장 아랫줄에
- ``export JAVA_HOME=(dirname $(dirname $(readlink -f $(which java)))) export PATH=PATH:$JAVA_HOME/bin``` 추가
- Esc 누르고 :wq!
source ~/.bashrc설정 적용
echo $JAVA_HOME
🐍intall python
sudo apt update
sudo apt-get install -y python3-pip python3-dev
sudo apt install software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa
13.3 pip3 pip로 변경
cd /usr/local/bin
sudo ln -s /usr/bin/pip3 pip
pip3 install --upgrade pip13.4 sudo apt-get clean
13.5 install nginx
# 설치
sudo apt-get update
sudo apt-get install nginx
sudo systemctl start nginx- /etc/nginx/sites-available 내 file에 쓰기 권한이 없으므로 chmod를 쓰기 권한을 추가해준다.
sudo chmod 775 /etc/nginx/sites-available - nginx config 추가: cd /etc/nginx/sites-available && vim <서버이름>
퍼미션 에러 나오면 앞에 sudo를 붙혀준다.
AWS route53에서 도메인을 추가한다. A record를 생성하기 위해서는 고정된 IP 주소가 필요하다. lightsail 인스턴스에서 고정된 public IP를 생성해 A record에 연결한다. 생성한 도메인은 nginx conf에 추가한다.
server{
server_name <your-site-domain>;
location / {
include proxy_params;
proxy_pass http://사용할 IP:8000;
}
}- symlink: sites-available/ → sites-enabled
sudo ln -s /etc/nginx/sites-available/<your-server-name> /etc/nginx/sites-enabled/ 13.6 run app
git clone <your-server-repo>
cd /var/www
git clone <server-repo>
cd <server-repo>
- nginx 확인
sudo nginx -t - restart nginx
sudo systemctl restart nginx.service- 안되면
sudo systemctl restart nginxfailed가 나올 경우 putty에서 /etc/nginx/sites-available과 /etc/nginx/sites-enabled/에 둘 다 같은 vim 파일이 있는지 확인한다.
- 안되면
- gunicorn으로 ASGI 서버 실행 :
python3 -m gunicorn -k uvicorn.workers.UvicornWorker main:app
🔗연결 확인
- route 53에 레코드를 CNAME으로 들어간 놈을 A로 바꾸고 그 레코드에 고정 IP(탄력적 ip)로 입력했는지 확인
- putty의 vim 파일이 아래 같은 모양인지 확인
}```server{ server_name 사용할 도메인 이름; location /{ include proxy_params; proxy_pass http://사용할 IP:8000; }
! 사용할 IP자리에 사용하기 위해 받은 탄력적 IP를 넣었을 때 실패- 사용할 IP에 127.0.0.1(로컬호스트)을 주로 사용하는 이유는 EC2 자체가 하나의 PC이기 때문에 로컬로 돌리는 것이기 때문에다
14 EC2와 서브 도메인 연결
루트 도메인을 이미 사용했으므로 새 인증서를 요청
참고
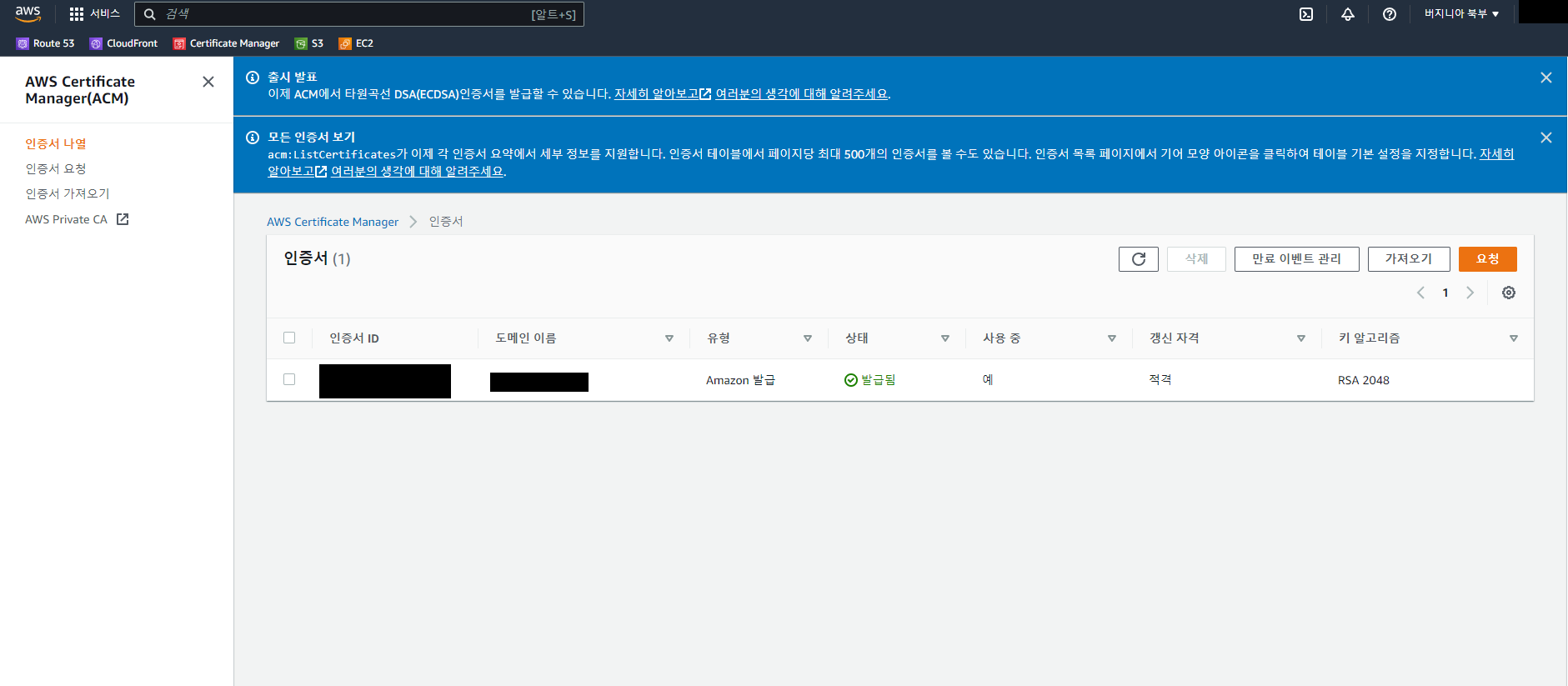
인증이 완료돼서 CNAME을 얻으면 가비아로 가서 등록
14.1 탄력적 IP를 사용
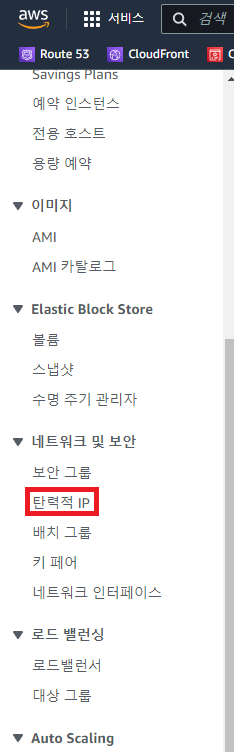
-
할당
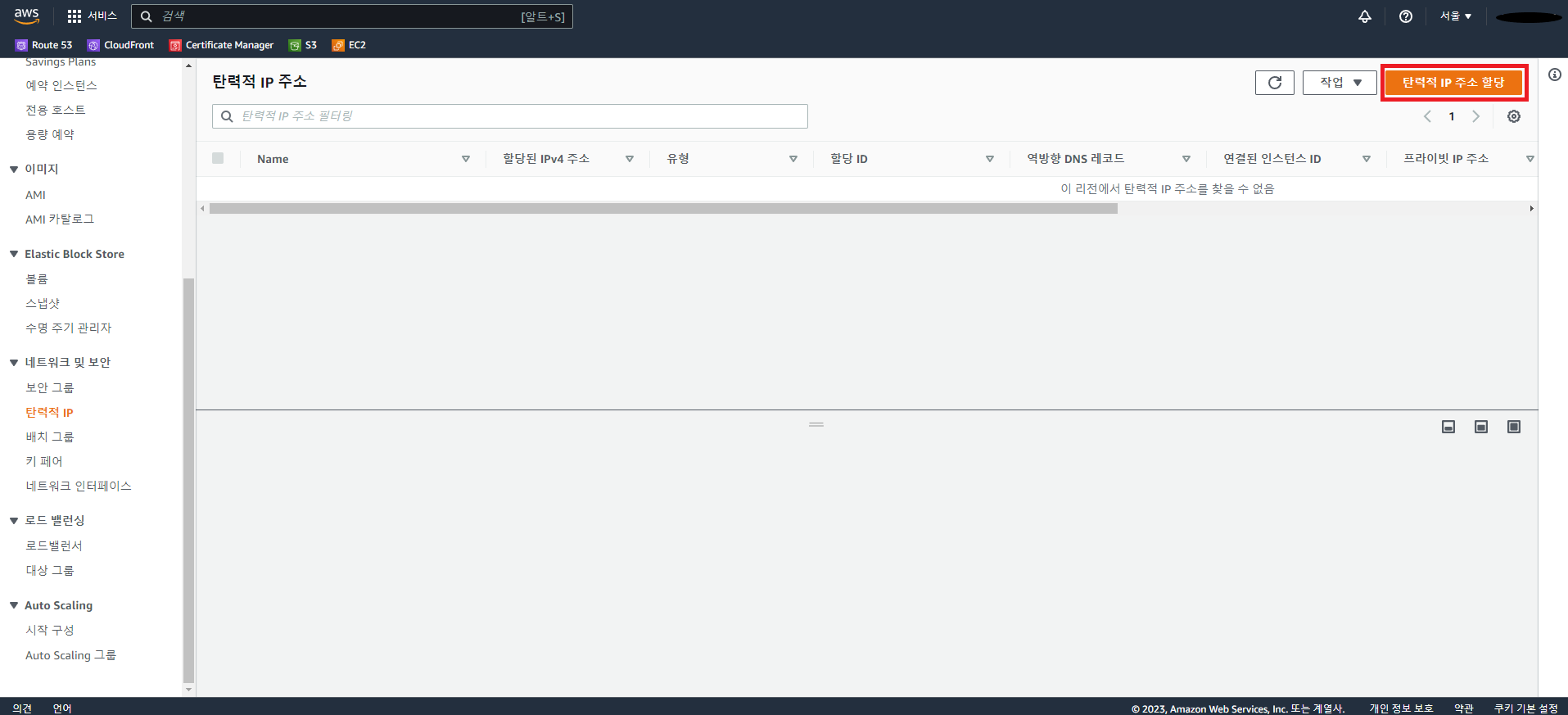
-
확인
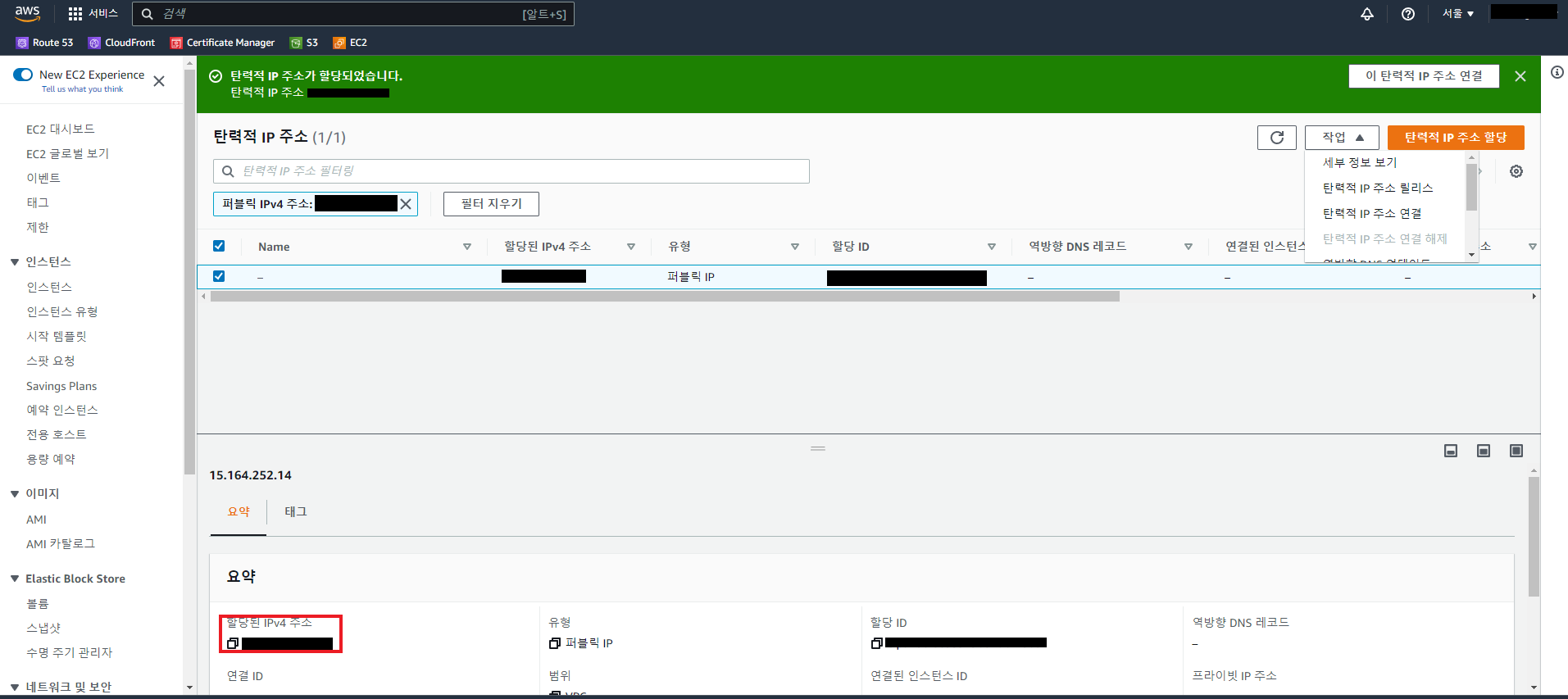
-
EC2 연결
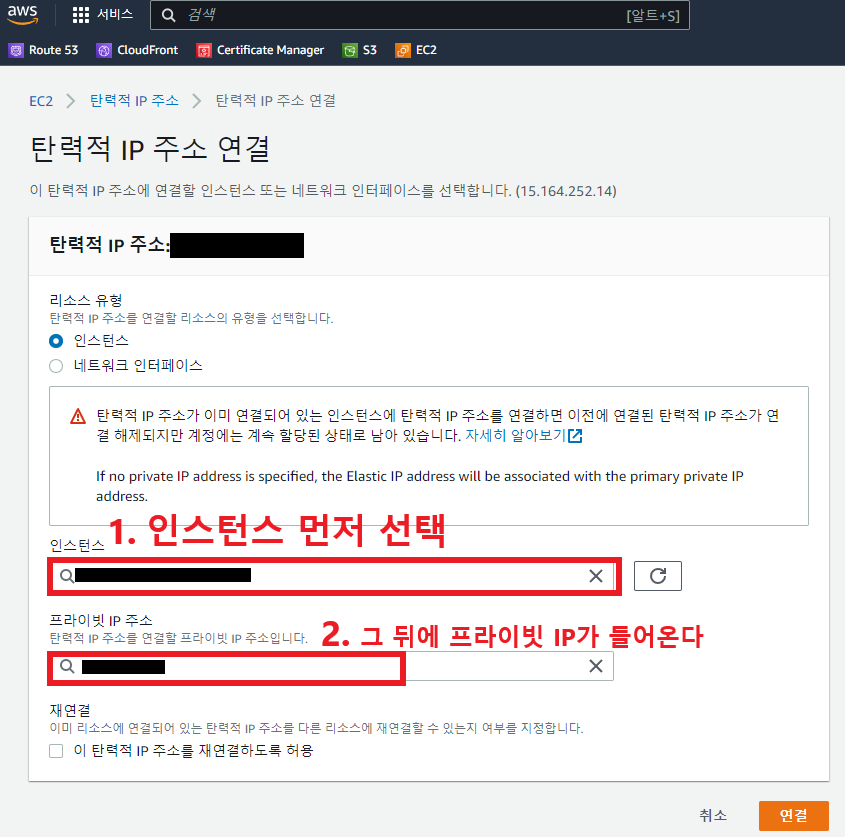
💻 putty 사용
EC2의 인스턴스에서 사용할 인스턴스 재시작
Putty에서 .ppk 실행
- 푸티의 ip는 'EC2- 인스턴스'에서 우클릭 후 연결을 선택해서 여기에 있는 퍼블릭 IP 입력
2.? error😕
도메인 주소로 접속시 주소 앞에 '주의 요함'이 나오는 경우

원인
- 배포한 CF에 인증서인 SSL이 없는 경우
해결
s3은 되는데 CF가 안되면?
원인
route53 문제
해결
- 호스팅 영역 삭제 후 다시 만들어라 (영역 삭제가 안되면 A, CNAME 레코드를 삭제 후 영역 삭제를 진행하면 된다)
- A 레코드의 값을 ip가 아니라 CF의 배포 도메인 이름으로 바꿔준다(별칭 활성 - CF 엔드포인트 선택 배포 도메인 이름 입력)
!!! 동적 ip를 사용하는 경우는 퍼블릭 엑세스 차단 활성화 + CORS 코드 삭제
- 자동으로 안들어오는 경우 대체 CF에서 도메인 이름을 설정하면 해결된다
15 🐋Docker 설정
안되면 앞에
sudo
155.1 Docker 설치
apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
apt update
apt-cache policy docker-ce
apt install docker-ce
15.2 Docker에 sudo 권한 부여
usermod -aG docker $USER
newgrp docker
15.3 설치 확인
systemctl status docker
15.4 Docker-compose
curl -L "https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose15.5 Docker-compose에 실행권한 부여
chmod +x /usr/local/bin/docker-compose
15.6 설치확인
systemctl status docker
curl -L "https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-composechmod +x /usr/local/bin/docker-compose
docker-compose version
16 🐍Python 설치
sudo apt install python3
sudo apt install python3-venv
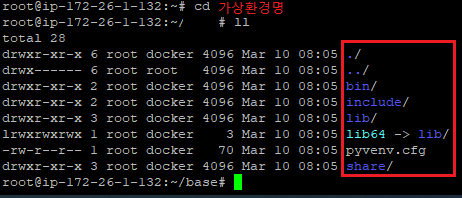
python3 -m venv 가상 공간 이름
- 가상환경 설정여부 확인
cd 가상환경명
ll
아래 사진처럼 나온다면 ok
- 가상환경 활성화
source 가상 환경 경로/bin/activate

17 Pycharm 연동
- 먼저 .pem 키를 가져오고
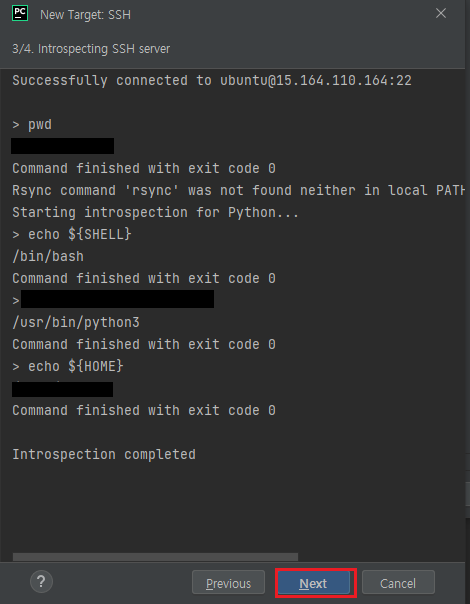
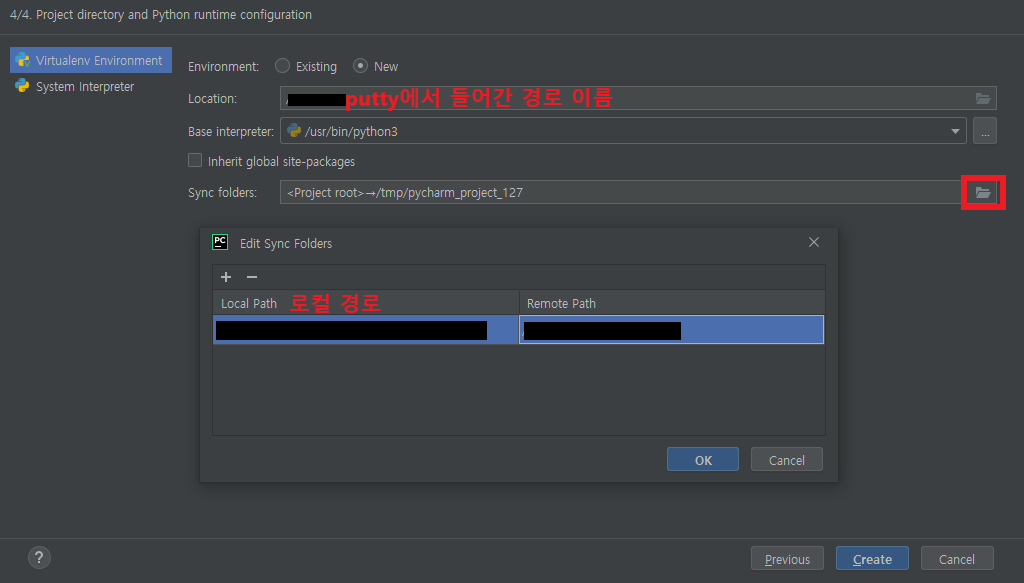
해당 경로에 폴더만 생성되고 파일이 안들어오는 경우는
remote path 경로를 var/www를 기본으로 사용하고 권한이 없어서 못만드는 경우는 putty에 직접 들어가서 mkdir 폴더명 실행하고 remote path를 지정해준다
**/var/www는 먼저 enginx
권한 오류가 나오는 경우는 ?.4 참고
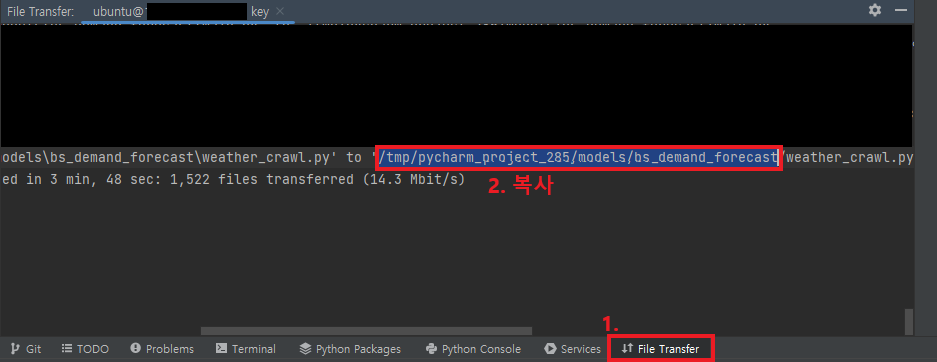
- 방금 만든 SSH로 터미널 열고 cd 복사한 경로
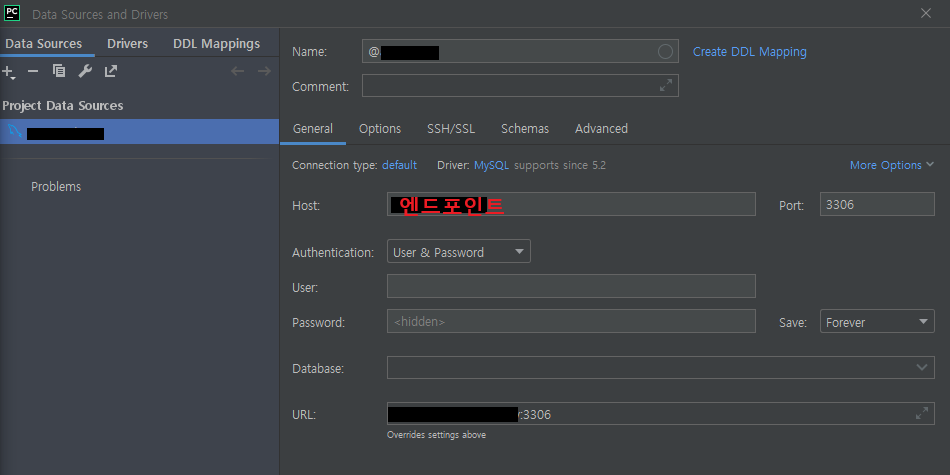
17.1 DB 연결
18. 프리티어 사용시 주의
- 인스턴스 구성시 t2로 설정
- RDS에서 스토리지의 할당된 스토리지는 20으로(스토리지 자동 조정 활성화는 체크를 해제)
EC2를 사용해서
주의
- 인공지능 모델은 lambda
- 상시로 열려있는 페이지는 EC2가 더 유리하다
이제는 매번 도커에 설치할 필요 x
리전은 ACM에서만 버지니아 북부를 사용
📁데이터 베이스
1. ERD 구성
- 운영 시 수집 될 데이터를 보관 할 저장소를 구축한다.
1.1 1차
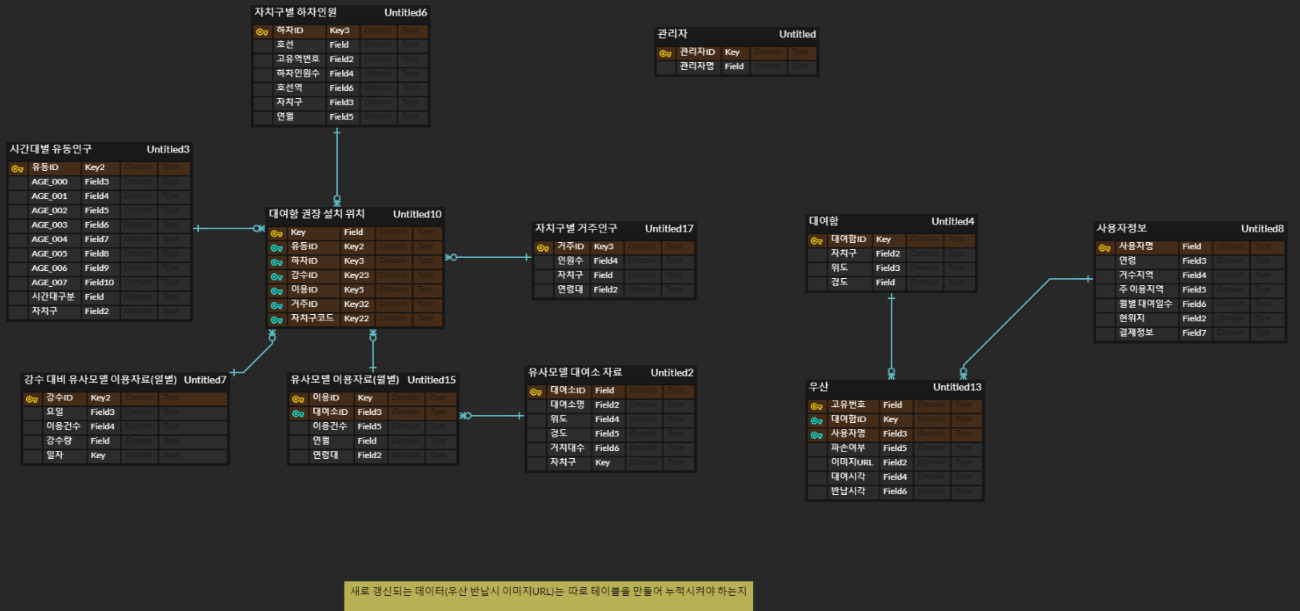
1.2 2차
변경사항
- 사용자엔티티와 우산엔티티는 다대다 관계이므로 크로스엔티티를 추가해 역정규화
- 우산 파손여부 외에 파손율 변수 추가
- 대여함 설치위치와 관련된 데이터들과 우산 배치개수와 관련된 데이터로 분리
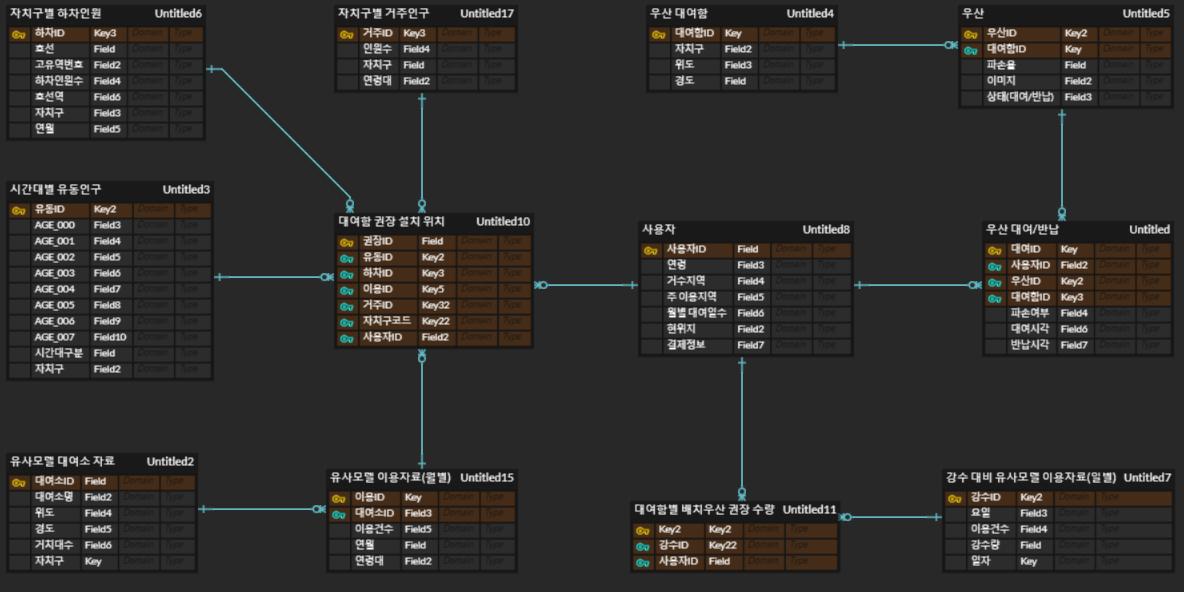
1.3 3차
변경사항
- 필요이상으로 많은 테이블이 만들어져서 테이블 종류를 제한
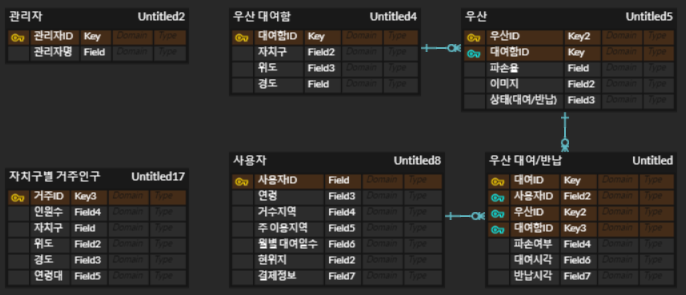
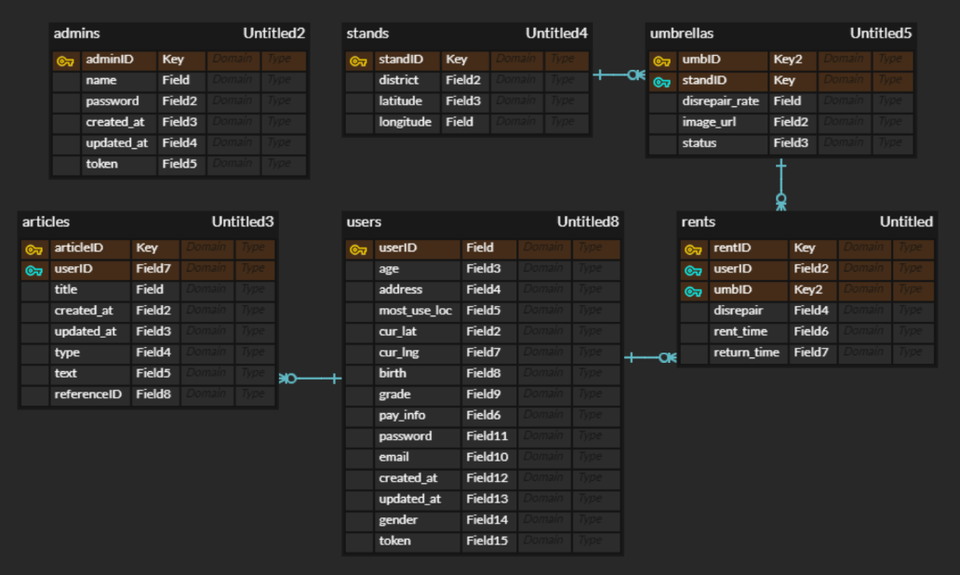
1.4 최종 ERD
변경사항
- 사용자 엔티티 필드 중 위치를 위도/경도로 구분하고 비밀번호 필드 추가
- 게시판(boards)엔티티를 추가
- 프런트와 필드명 일치 검토 필요하다.
- 테이블은 관리자, 우산, 대여함, 대여 일지, 사용자, 게시판의 총 6개로 분류한다.
각 테이블의 세부 내용
관리자
관리자ID, 이름, 비밀번호, 가입 일자, 수정 일자, 토큰
모든 테이블에 접근 권한이 있다.
우산
- 우산ID, 파손율, 이미지, 상태
- 외래 키로 대여함 테이블의 대여함ID를 받는다.
대여함- 대여함ID, 자치구, 위도, 경도
대여 일지- 대여ID, 파손 여부, 대여 시각, 반납 시각
- 외래 키로 우산 테이블의 우산ID와 사용자 테이블의 사용자ID를 받는다.
사용자- 사용자ID, 연령, 거주 지역, 주 이용 지역, 현 위치 위도, 현 위치 경도, 생년월일, - 등급, 결제정보, 비밀번호, 이메일, 가입 일자, 정보 수정 일자, 성별, 토큰
게시판- 게시 글ID, 제목, 작성 일자, 수정 일자, 유형, 내용, 원 글ID
- 외래 키로 사용자 테이블의 사용자ID를 받는다.
2. FastAPI 데이터 베이스 구축
-
ERD 구성을 바탕으로 각 테이블과 컬럼을 코드로 생성한다.
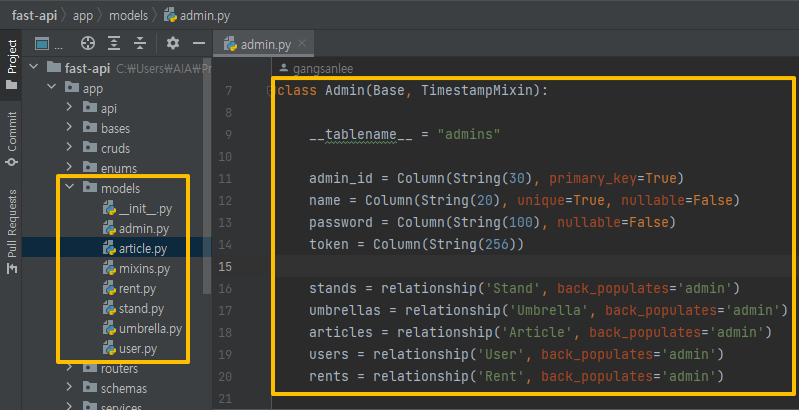
-
Docker 를 사용하기 때문에 Docker compose up 명령어 입력 시 테이블이 자동으로 생성된다.
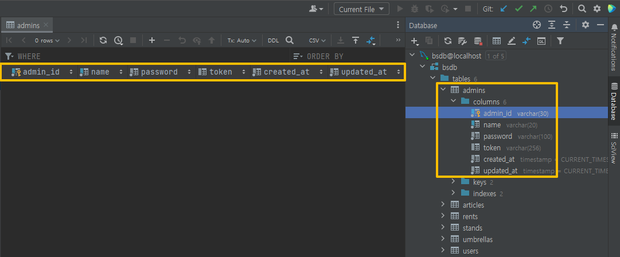
💻웹 제작
프론트엔드 희망하는 팀원이 따로 없고 앱 위주의 서비스이기 때문에 가벼운 랜딩 페이지로 제작
1. 웹 목업 제작
- Balsamiq mockups을 사용해 작업을 진행한다.
- 웹은 고객이 보는 서비스 소개 페이지와, 관리자가 보는 관리자 페이지 2개로 구분된다.
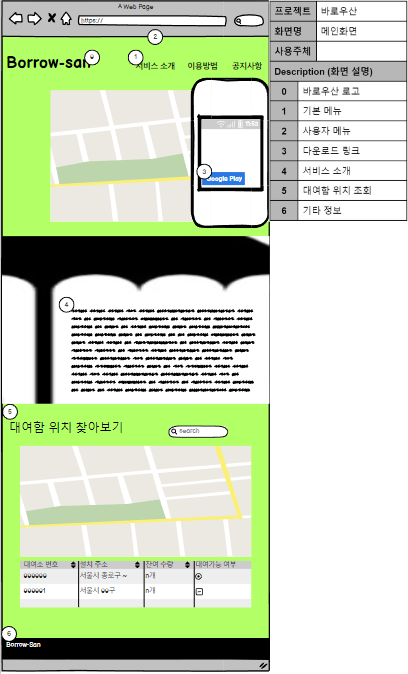
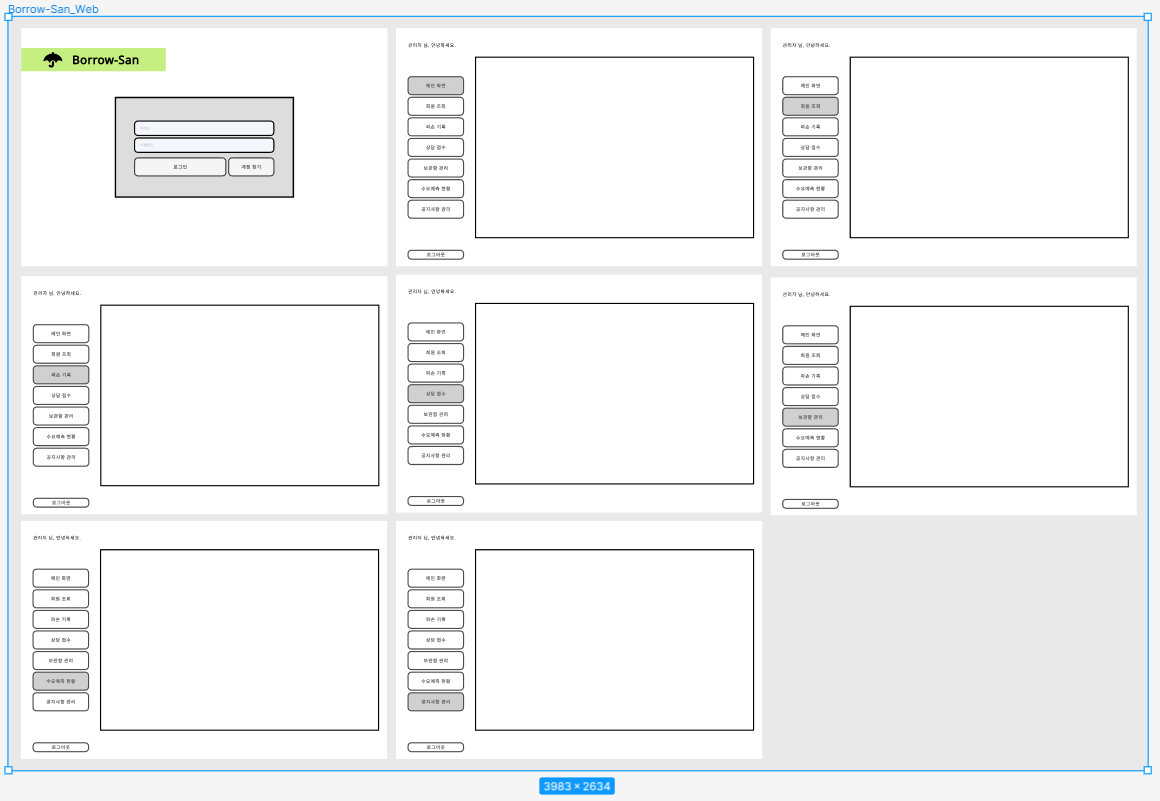
1.1 Figma 제작
- 목업에서 사용 가능한 HTML 코드를 추출하기 위해 Figma를 사용했다.
- 관리자 페이지는 로그인 창과 관리 창으로 구성되며, 관리창은 네비게이터 버튼만 클릭하면 내부 화면이 바뀌는 형태로 구성한다.
2. 랜딩 페이지
2.1 초안

2.1.1 제작 중 추가 내용
- 랜딩페이지에서 깃허브 등 상세 링크로 이동할 때 새 화면이 랜딩페이지의 창에서 열려서 열람에 불편을 끼침
target="_blank"를 태그에 추가해서 해결
2.1.2 보완사항
- 서비스 소개 항목 벨로그 게시물로 교체
- 미구현 항목 제거

👾인공지능 모델링
1. YOLOv5를 이용한 파손 여부 확인
1.1 전처리
1.1.1 train.py에서 실행하기 위해 사용할 데이터를 가져올 yaml 파일을 생성
1.1.2 기본 Dataset에서 학습 시킬 대상을 가진 데이터만 남기고 나머지 데이터 삭제
| 실행 전 | 실행 후 |
|---|---|
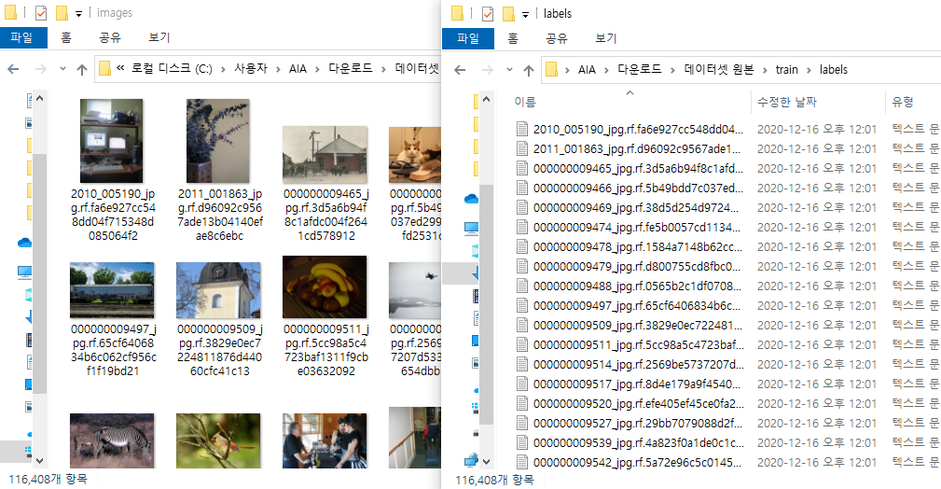 | 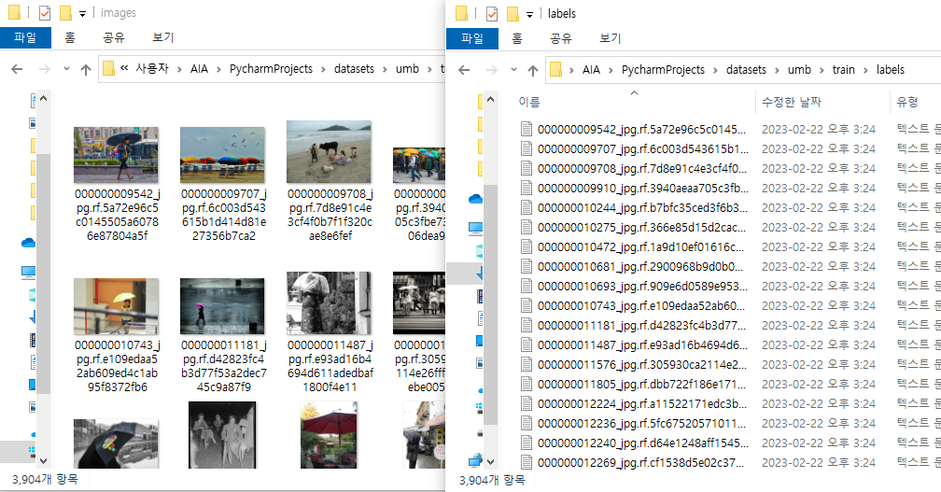 |
| images : 116,408 / labels : 116,408 | images : 3,904/ labels : 3,904 |
1.2 전체 사물 중 우산만 인식
- 학습한 .pt 파일을 실행한 결과
 |  |
|---|
목적인 우산 자체는 인식을 했으나 우산이 아닌 것까지 우산으로 인식하는 문제 발생
- 원인?
- Confidence Threshold가 0.25로 낮아서 발생한 문제
- 아래 설명에서 알 수 있듯이 이 값이 너무 낮으면 자신감 넘치는 상대의 말은 무조건 믿는 것처럼 정확도가 낮은 결과를 받게된다.Confidence Threshold?
- 말 그대로 Confidence에 대한 신뢰도로 Confidence가 일정 수준에 미달이면 버리게 하는 수준이다 .
- 단, 이 값이 너무 높으면 작은 차이로도 인식에 문제가 생기기 때문에 중간점을 잘 잡아야 한다.
- 해결
- Confidence Threshold의 값을 0.4정도로 설정해서 정확도가 낮은 박스를 사용하지 않게 했다.
1.3 우산의 파손 여부 인식
1.3.1 이미지 크롤링
- 우산 파손여부 인식을 위해 기본 데이터셋에 없는 파손된 우산 이미지와 라벨이 필요
- 크롤링 결과로 나온 이미지들에 라벨링 작업 시행
1.3.2 1차 시도
- 파손 데이터의 양이 너무 적고 각 파손된 형태가 제각각이기 때문에 정사 우산과 파손 우산을 구분하지 못함
-파손 데이터를 추가하고 epoch 50으로 실행한 결과


이제는 우산과 파손을 잘 잡지만 아직도 이상한 곳에서 우산을 인식한다… 이건 우산관련 데이터를 늘리는 방법이 최선이라고 생각한다.
1.3.3 2차 시도
- 2차 학습에서 사용한 데이터셋에서 데이터량을 늘려서 학습
- 구글 이미지 크롤링으로 검색된 파손된 우산 이미지를 모두 모아서 크롤링으로는 우리가 원하는 데이터를 더 구할 수 없으니 다음 단계에서는 직접 데이터셋을 늘리는 방식을 찾아야 한다

이전 시도보다는 높은 정확도를 가지게 됐다.
2. KoGPT2를 이용한 Borrow-San 서비스 챗봇
2.1 전처리
2.2 학습
가장 많이 사용되는 송영숙님의 깃허브에 있는 챗봇 데이터셋을 참고해서 프로젝트 시나리오를 추가
메타데이터는 사용자 입력, 원하는 대답, 내용 분류된다
2.2.1 1차 시도
서비스 시나리오를 구상해서 약 100개의 대화 유형을 데이터셋으로 만들어 학습
-
결과
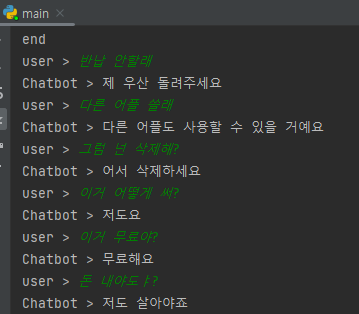
-
고정된 답변만 가능하고 그마저도 틀리는 경우가 발생
-
서비스 이외의 대답은 불가
대안 :
송영숙님의 데이터셋을 추가해서 대화 가능한 범위 확대
2.2.2 2차 시도
- 1차 시도의 대안으로 데이터셋을 추가해서 학습
- 결과
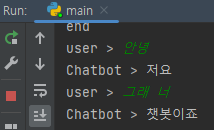
- 대화 가능범위는 늘었지만 알아듣지 못한다
원인 :
기존 데이터셋에 내용 분류에 해당하는 값들을 넣어주지 않아서 생긴 문제
대안 :
내용 분류에 해당하는 값으로 서비스 관련(3)을 추가했다.
대안 적용 후
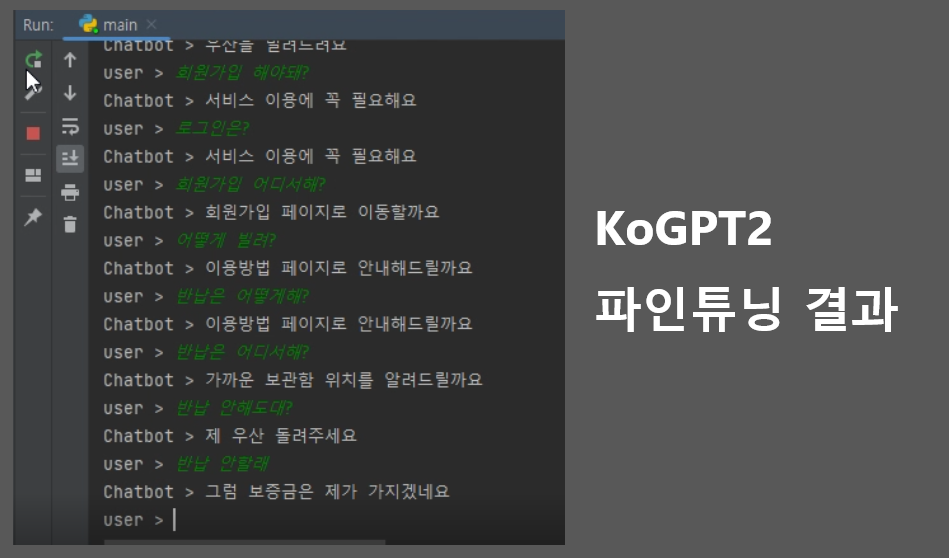
2.3 ChatGPT3로 변경
ChatGPT3 출시로 기존에 있던 KoGPT2를 파인튜닝하는 방식보다 더 쉽게 좋은 성능을 낼 수 있어서 ChatGPT3를 사용한 서비스용 챗봇으로 변경
2.3.1 준비(API키)
- OpenAI에서 회원가입 후 진행
- API키 가져오기
- API키 생성
2.3.2 코드 작성
openAI 설치
터미널에서 아래 명령어 입력으로 설치
pip install openaiAPI 호출
import pandas as pd
import openai
openai.organization = "Organization 키를 입력"
openai.api_key = "발급받은 API 키를 입력."- Organization 키 확인
3. 수요예측 모델
3.1 1차
3.1.1 🧾전처리
공공데이터의 범위가 너무 넓어서 서비스 지역을 2호선에 한정하고 그에 따른 전처리 진행
y값 생성
- 원본 데이터에서는 승차총승객수와 하차총승객수만 나와있어서 y값으로 사용할 컬럼이 없는 상태이므로 각 일자별 승하차 변동을 나타내는 컬럼을 추가
전처리 과정에 역별로 csv파일을 분리하는 과정 추가
역별 csv로 변경한 이후 아래 코드로 y값 생성
분할 및 y값 생성 결과
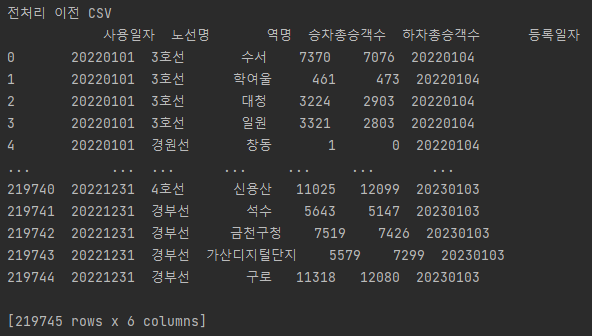
- 전처리 이전
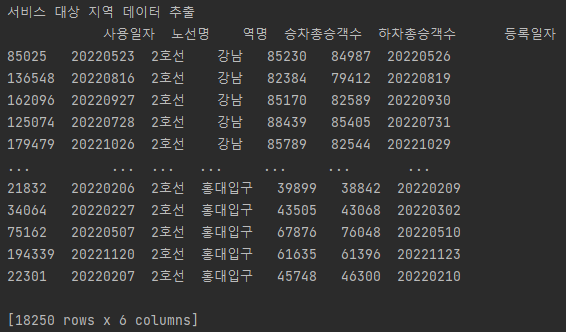
- 서비스 대상 지역 축소
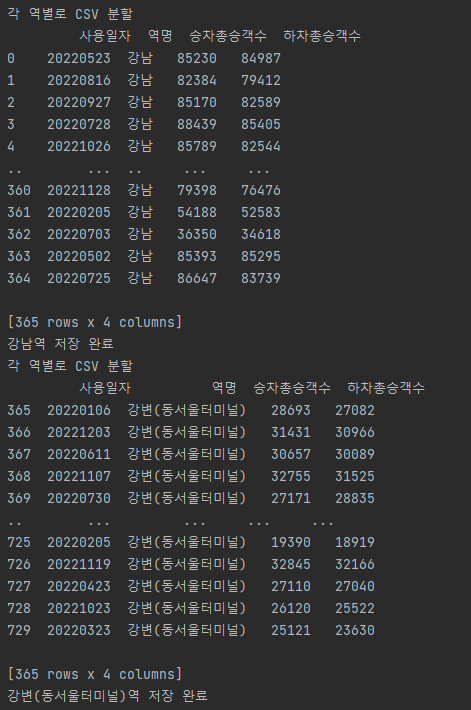
- 각 역별 csv 생성
- y값인 승하차 승객수 변동 컬럼 추가
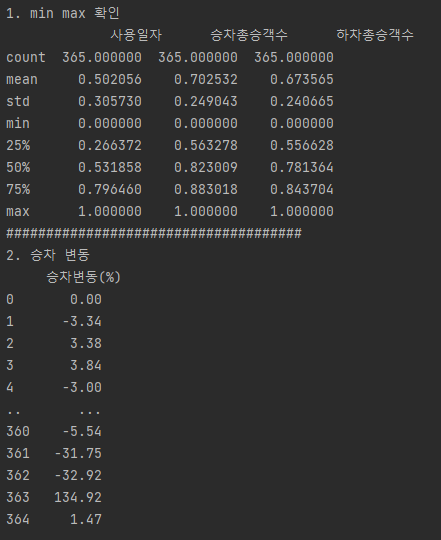
Min Max Scale
3.2 모델 생성
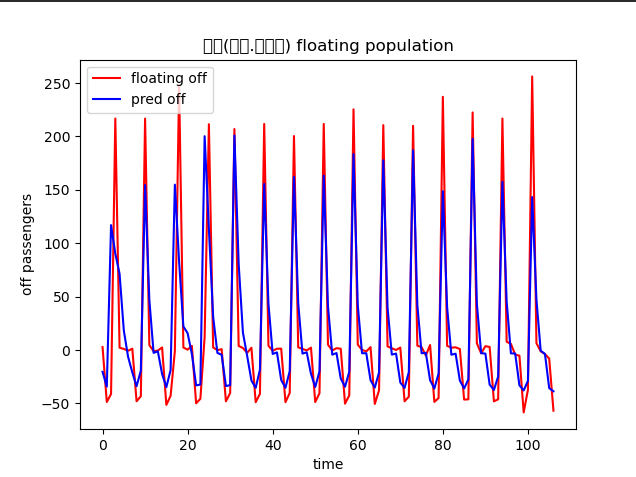
- 계획 : 각 역별로 일별 승하차총승객수를 바탕으로 하차총승객수를 예측한다
보완사항
각 역별로 모델을 만들고 같은 기간동안 지하철 승객 변동이 가장 심한 지역 위주로 지도에 나타내는게 기존의 계획이었으나 모든 역이 요일을 기준으로 거의 일정한 요동인구 변화를 나타내기 때문에 지하철을 이용한 승객 변화를 통해 학습한 모델의 메리트가 떨어진다.
대안
모든 역에 대한 수요예측 후 비교라는 초반의 방식을 버리고 하나의 역에 대한 작업 우선 진행
강남 하나만 집어서 날씨 등 다른 변수 추가 (2023-02-27)
3.2 2차(날씨 추가)
3.2.1 전처리
이전 단계에서 사용한 데이터셋에는 변수가 너무 적기 때문에 하나의 역을 정해서 강수 여부를 추가
3.2.2 학습
결과
- 서비스 항목인 우산과 비슷하게 날씨에 영향을 받는 상품의 수요 변화를 변수로 둘 필요가 있다
날씨 추가 후
😅 다시 생각해보니 날씨가 지하철을 이용량에 영향을 미치지 않고 이걸 뽑아내더라도 우산 대여와 관련이 없다
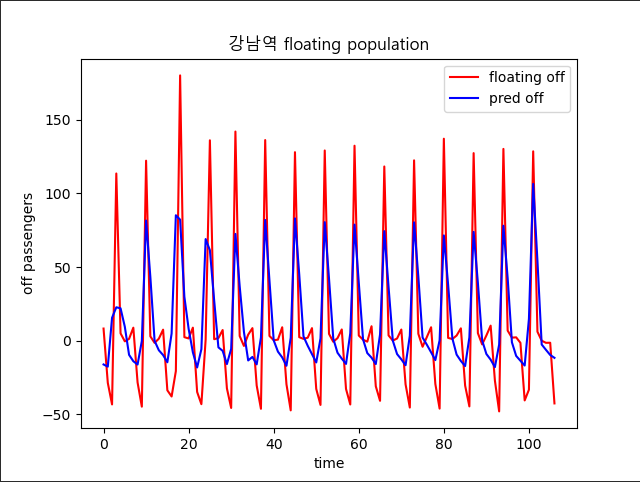
3.3 3차(따릉이 대여정보 추가)
예시 상품인 우산처럼 날씨의 영향을 많이 받으면서 수요의 증감이 우산 사용량과 반비례 관계를 가졌을 것이라고 예상되는 따릉이 대여기록을 추가
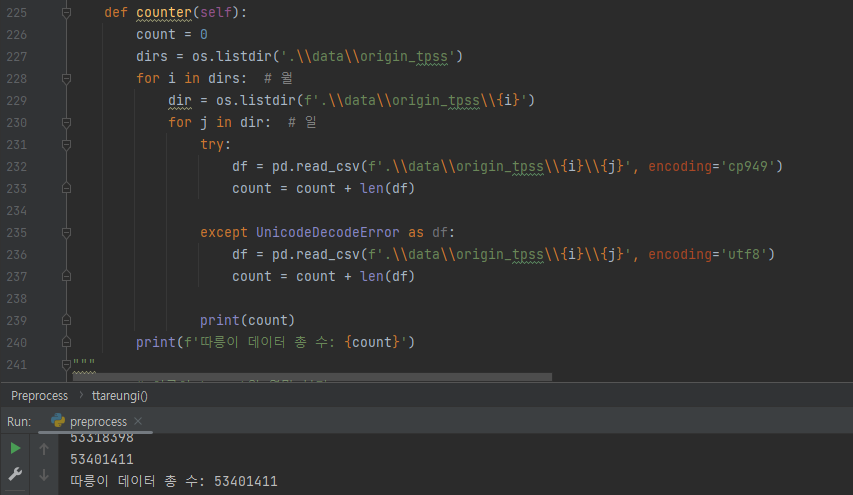
따릉이 데이터 수 : 53,401,411개
3.3.1 전처리
우산과 수요가 반비례하는 따릉이의 자료를 가져오고 y값을 승하차 변동률이 아니라 따릉이 대여량으로 바꾸기 위해 전처리 과정을 거침'
서울역 승하차정보 추출
- 서울역의 역별 승하차 정보와 따릉이 대여소 위치정보 간의 연결이 가장 수월하기 때문에 강남역을 대상으로 한 이전 전처리 결과를 버리고 서울역으로 다시 진행
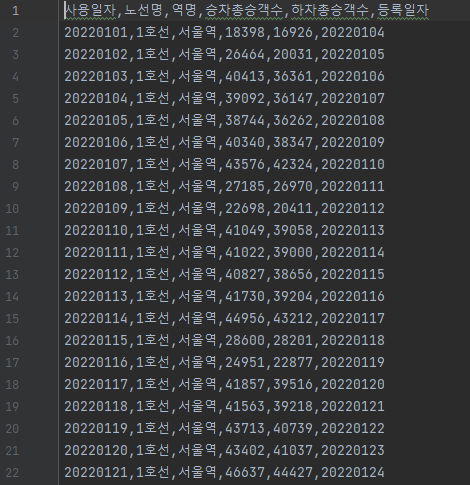
따릉이 대여량 추출
1년치 따릉이 대여정보가 하루를 기준으로 적게는 5만에서 20만개의 데이터가 모여있어서 전처리가 필수
- 서울역 승하차 정보와 따릉이 대여량 join
- 365개의 csv 파일 중 일부 파일의 메타데이터, 인코딩 방식이 일치하지 않아서 에러 발생
3.3.2 학습
결과
- epoch : 80
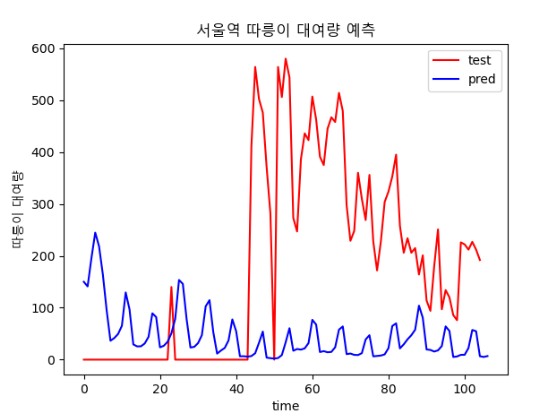
- epoch : 800
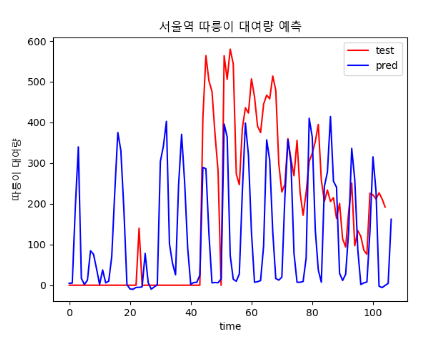
날씨 데이터가 빠진 채로 학습해서 그런거라고 생각된다
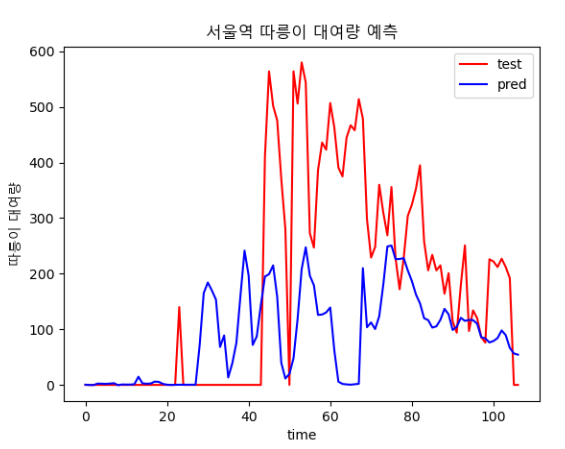
3.4 4차(기온, 풍속 추가)
3.4.1 전처리
- 3차 시기의 데이터에 기온, 풍속 등 변수 추가
3.4.2 학습
결과
- 3차 시도 때보다는 loss가 감소했다
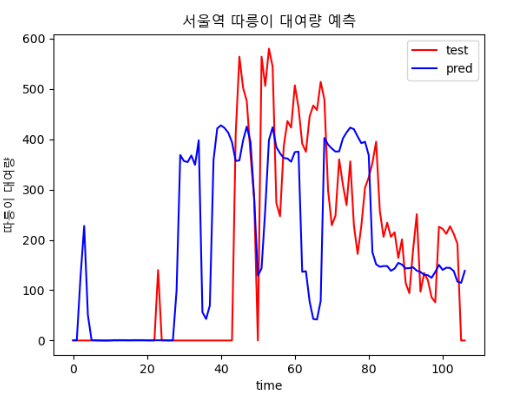
epoch, batch size에 따른 결과 비교
| epoch : 300, batch size : 20 | epoch : 400, batch size : 20 |
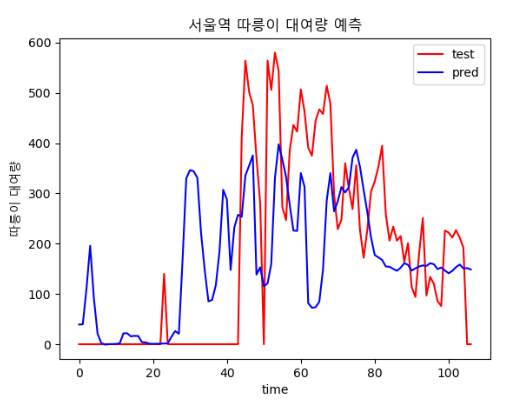 | 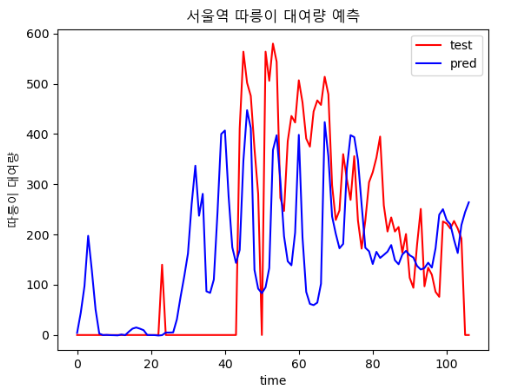 |
| epoch : 400, batch size : 30 | epoch : 500, batch size : 20 |
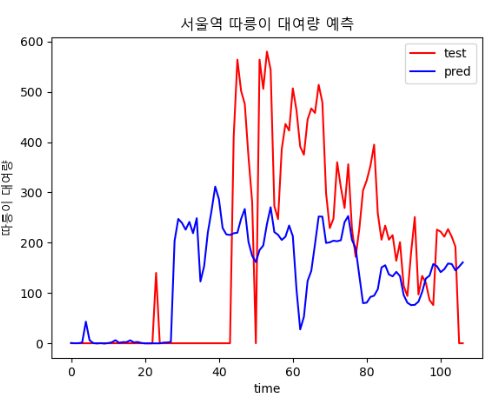 |  |
| epoch : 600, batch size : 12 | epoch : 700, batch size : 30 |
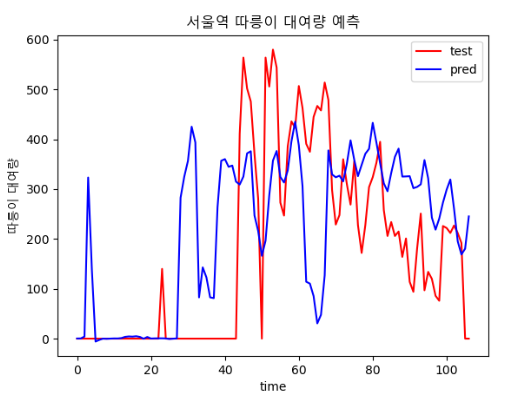 | 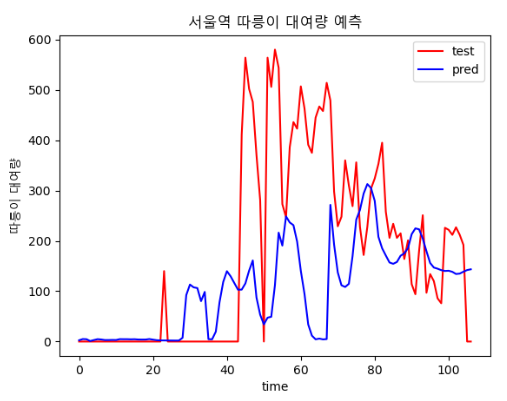 |
| epoch : 800, batch size : 15 | epoch : 4000, batch size : 64 |
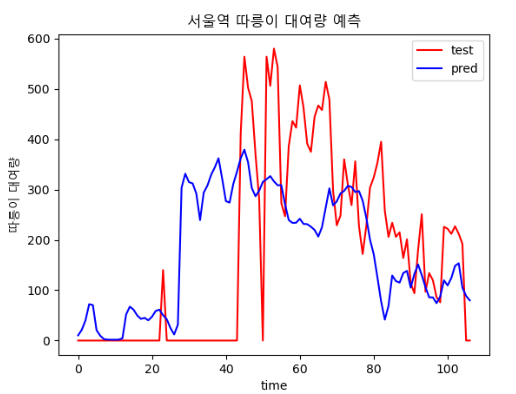 | 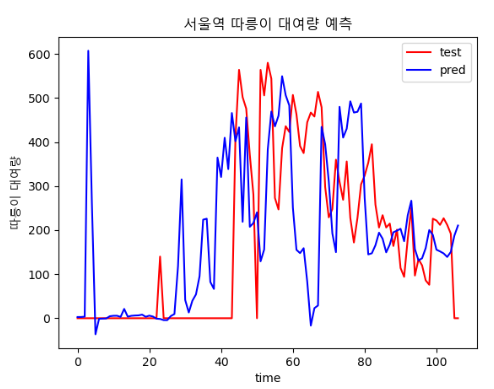 |
batch size
각 사이즈 테스트시 에포크는 1000
|||
|---|---|
|15|20|
||
|
|30|64|
||
|
- 16 단위로 batch 사이즈 비교
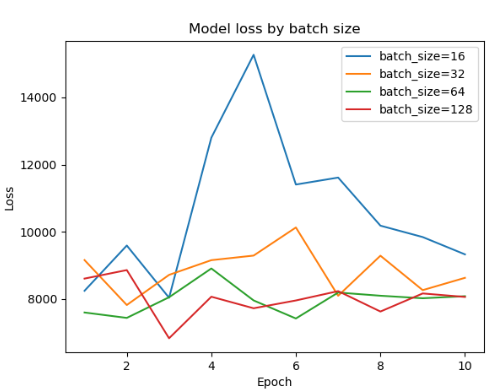
- 5 단위로 비교
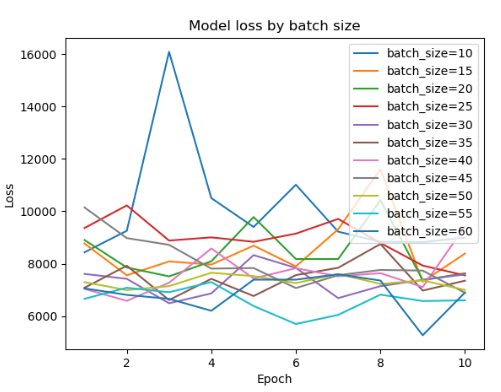
--
😨오류
FastAPI💨
1. Invalid argument(s) 'encoding' sent to create_engine()
🤔원인
기존까지 잘 작동되던 코드인데, 포맷 후 버전이 달라지면서 발생한 에러
😊해결
- 버전이 업그레이드 되면서 encoding을 명시하는 것이 레거시가 되었다.
- 위 코드에서 encoding=”utf-8” 부분만 지우면 해결 된다.

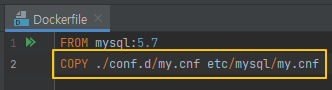
MySQL 로그인 시 my.cnf 파일 인식 불가
🤔원인
Dockerfile 에 my.cnf 경로를 지정하지 않아 발생한 오류
😊해결
- 사진과 같이 경로만 추가하면 해결
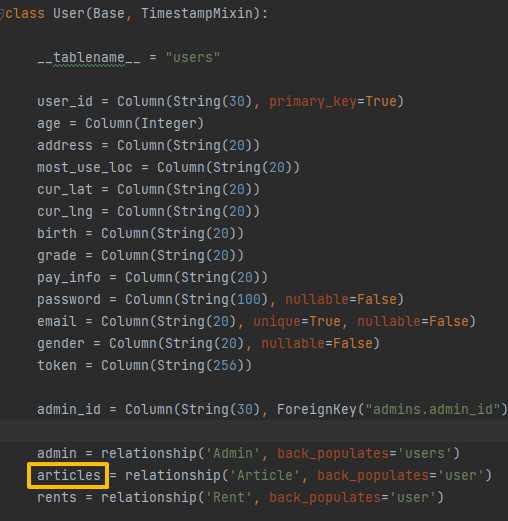
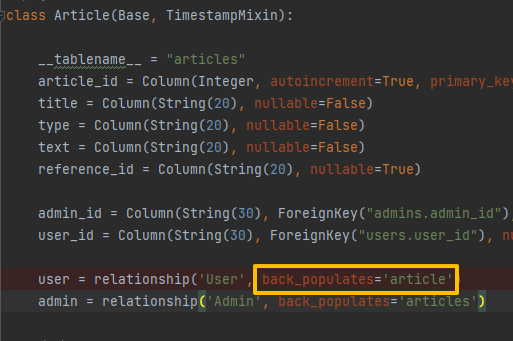
sqlalchemy.exc.InvalidRequestError: One or more mappers failed to initialize
🤔원인
- Postman에서 값 전달 시 발생하는 에러
- Article 테이블의 back_populates에 적힌 속성 값과 User 테이블의 변수 명이 달라 발생하는 에러
😊해결
- 변수 명과 속성 값을 동일하게 변경하면 해결

Docker🐋
다른 컨테이너 실행 오류
🤔원인
git 업로드 시 생성되는 .idea 폴더와 충돌해 기존 컨테이너가 실행되어 발생하는 오류
😊해결
.idea 폴더 삭제 후 명령어를 재 실행하면 해결
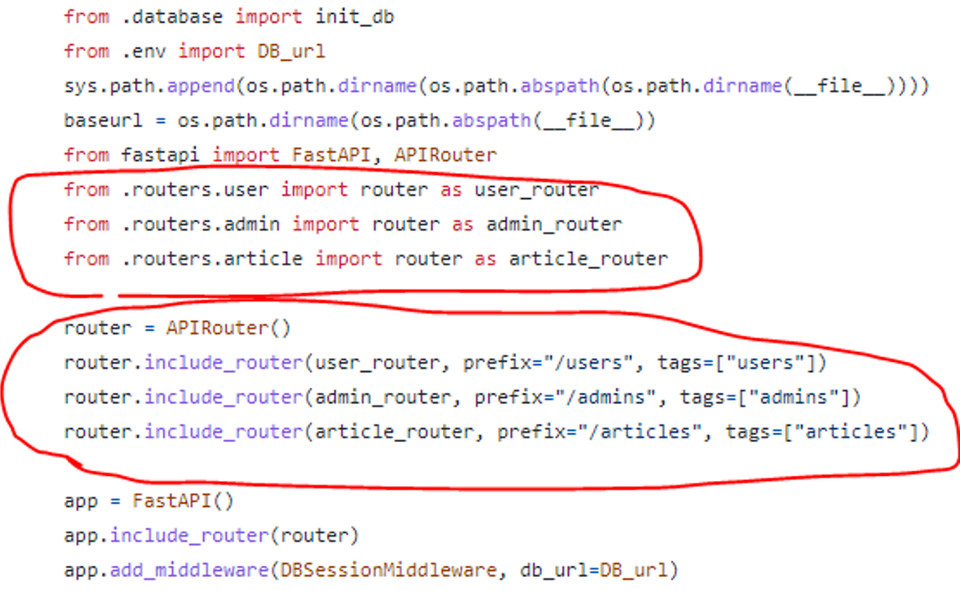
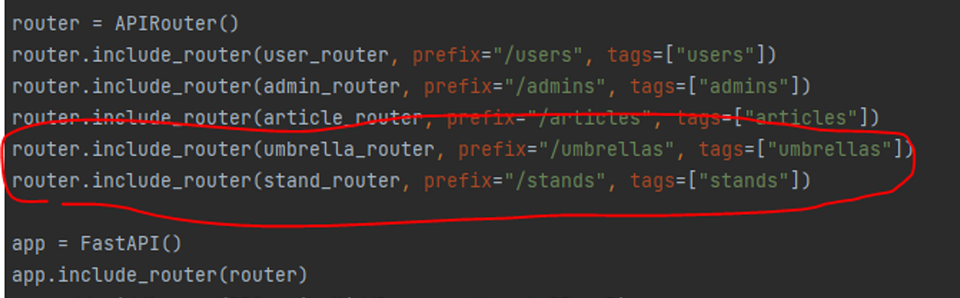
DB 테이블 미 생성
🤔원인
router 연결 코드가 제대로 입력되지 않은 경우 발생하는 에러
😊해결
- main.py → router(schema) → repository → model 순으로 router 연결이 되지 않은 부분이 있는지 확인하고, 빠진 부분에 추가로 코드를 입력하면 해결
- 이번에 발생한 에러는 main.py 에 umbrella, stand의 연결 코드가 없어서 발생
- umbrella, stand 연결 코드를 추가한 뒤 docker compose up 명령어를 다시 입력하면 테이블이 생성
도커 허브 이미지 업로드시 아래 문제 발생

🤔원인
버전 이슈로 node 16.0 이하의 버전에서는 html 태그를 지원하지 않는다
😊해결
버전을 올려서 사용해준다.
물론 이 과정에서 다른 문제가 발생하지 않았는지 확인하는건 당연
Vue
Unhandled Runtime Error
🤔원인
Table 내부 구조를 잘못 짜 발생한 오류
😊해결
<td>태그만 사용해 구성했던 테이블을<tr>태그 내부에<td>태그를 넣어 구성하자 해결
YOLOv5
KeyError: 'path'
🤔원인
아래 코드를 추가해서 yaml 파일의 내용을 변경하는 과정에서 원래 있던 path:가 사라져서 발생한 문제
😊해결
yaml을 수정해주자
전처리 과정에서 한 개의 파일만 제거하고 다음 파일은 찾지 못하는 문제 발생
🤔발생 코드
train_label_list = glob('C:/Users/AIA/PycharmProjects/datasets/umb/train/labels/*.txt') for path in train_label_list: print(path) f = open(path, "rt") umbrella = [] for line in f: if line.startswith("76"): umbrella.append(line) f.close() if len(umbrella) == 0 : # person 이 없으면 삭제한다 os.remove(path) os.remove(path.replace(".txt", ".jpg").replace("/labels/","/images/")) else : f2 = open(path, 'wt') for p in umbrella: f2.write(p.replace("76","0",1)) f2.close()
😊해결
12번 라인의 replace("/labels/","/images/")를 replace("labels","images")로 바꿔서 다시 실행
전처리 후 학습시 nc 이외의 범위에서 키에러 발생
🤔원인
발생 당시 train과정에서는 전처리가 완료되어 모든 네임클래스가 0으로 정리된 파일을 사용했지만 valid 과정에서는 전처리가 제대로 이뤄지지 않은 파일이 적용돼서 발생한 문제
😊해결
- 에러지점 네임클래스 확인
- 0 이외의 다른 nc가 들어온걸 볼 수 있다
- 전처리 코드를 valid 폴더 내부에도 실행해준다
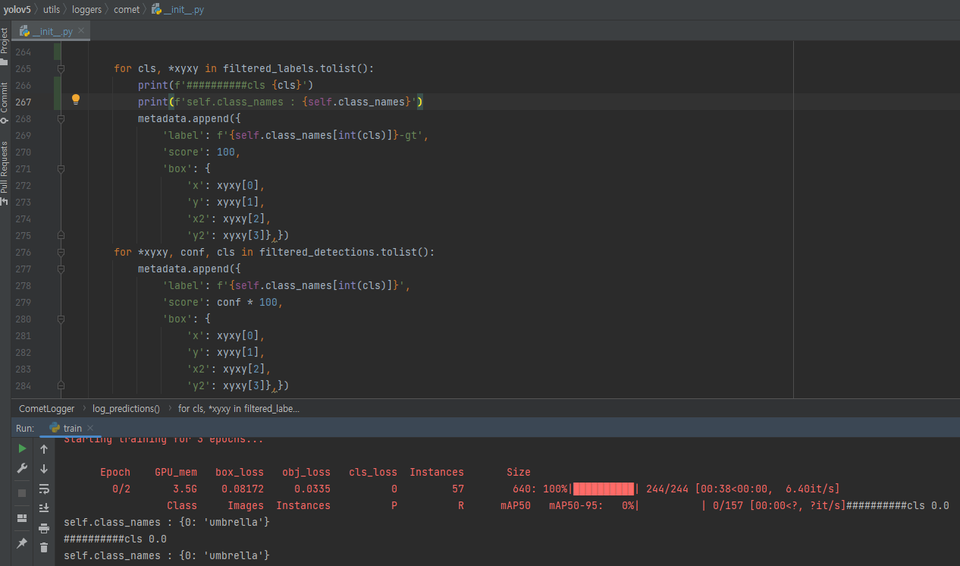
# 에러 발생 for cls, *xyxy in filtered_labels.tolist(): metadata.append({ 'label': f'{self.class_names[int(cls)]}-gt', # 변경 for cls, *xyxy in filtered_labels.tolist(): metadata.append({ 'label': f'{self.class_names}-gt',
KoGPT2
RuntimeError: Expected all tensors to be on the same device, but found at least two devices
🤔원인
텐서 별로 사용하는 디바이스가 달라서 발생
😊해결
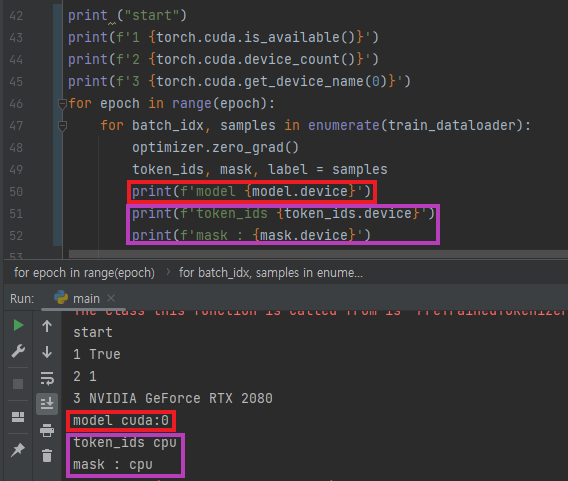
- 사용중인 디바이스 확인
- model과 token_ids의 디바이스가 다른 것을 확인
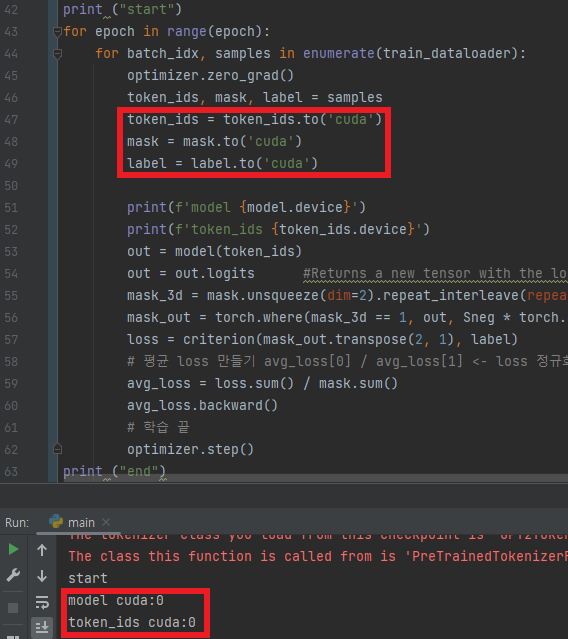
- 동일한 디바이스를 사용하게 해서 해결
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
🤔원인
GPU에 할당된 텐서를 넘파이 배열로 변환하려 해서 발생
😊해결
이전 에러 해결을 위해 CUDA로 사용중이던 텐서의 디바이스를 넘파이 배열 사용 전에 cpu로 바꾼다.
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
😊해결
재실행하면 된다
수요예측 모델
TypeError: numpy boolean subtract,
🤔원인
MinMaxScale 과정에서 String값을 가지는 컬럼까지 포함돼서 발생한 문제
😊해결
int값만 사용될 수 있도록 바꿔준다
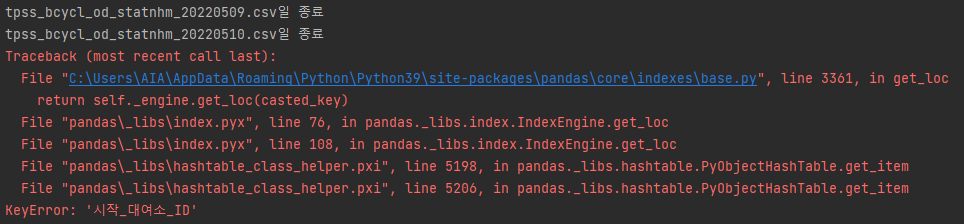
전처리 과정중 키에러가 반복적으로 발생
🤔원인
전체 csv 파일 중 일부 파일의 메타데이터, 인코딩 방식이 일치하지 않아서 발생
😊해결
따로 정해진 방식은 없고 아래 코드를 통해 해결
- 이번 에러는 아래 코드로 해결했다
dirs = os.listdir('.\\data\\tpss') for i in dirs: # 월 dir = os.listdir(f'.\\data\\tpss\\{i}') for j in dir: # 일 try: df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='cp949') if df.columns[2] != '시작_대여소_ID': df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True) df.to_csv(f'.\\data\\tpss\\{i}\\{j}') except UnicodeDecodeError as df: df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='utf8') if df.columns[2] != '시작_대여소_ID': df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True) df.to_csv(f'.\\data\\tpss\\{i}\\{j}') print(f'{j}일 종료')
ValueError:

🤔원인
확인 결과 각 역 별로 csv파일을 나누는 과정에서 딱 역의 종류만큼 인덱스가 다른 것을 알 수 있다
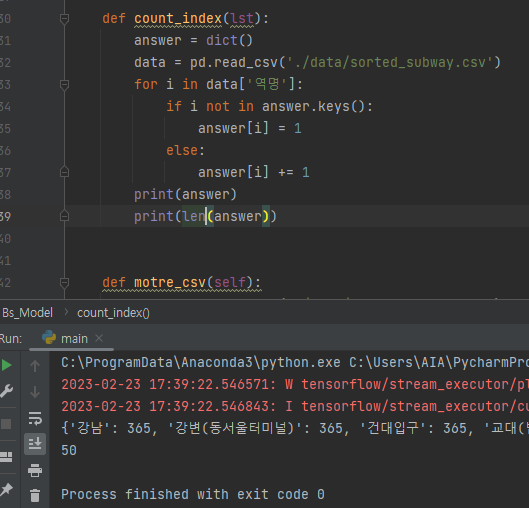
😊해결
모든 역을 한 번에 비교하기보다 각 역별 이동인구 변동율을 예측하고 이를 비교하는 방향으로 변경
npm run serve 실행시 noscript만 나오는 경우

🤔원인
발생 당시 main.js의 내용은 아래처럼 작성됐는데import { createApp } from 'vue' import App from './App.vue' import { router } from '@/router/index'
createApp(App).use(router).mount('#src')
여기서 createApp() 메소드는 인자로 전달된 DOM element를 찾아, 해당 DOM element를 Vue 인스턴스에 마운트(Mount)한다. 위에서 DOM element로 전달된 #src가 잘못된 선택자라서 발생한 문제다.
> 😊해결
- 원래는 default인 #src가 맞는 인자지만 이번 프로젝트에서는 App.vue를 통해 전달된 파일들을 보여주는 형태라서 #src를 #app으로 변경해줘야 한다.
