- OS란?
- OS Structure
- Process
- Process Scheduling
- Thread Concurrency
- Synchronization Tools
3. Process Scheduling
CPU Scheduler
Process execution에는 cycle이 존재한다.
CPU burst -> I/O burst -> CPU burst -> I/O burst ...
그럼 이렇게 누가 CPU에 앉을지 결정하는 것은 누가할까? 바로 CPU Scheduler!
이 CPU Scheduler는 Policy와 Mechanism을 나눠서 구현한다.
- Policy : 누구를 CPU에 앉힐까?
- Mechanism(Dispatcher): 바꿔주는 행동 그 자체
즉, Dispatcher은 인이어를 낀 경호원이고 Policy는 경호원에게 명령을 내리는 사람이라고 생각할 수 있당.
Dispatcher
그런데 Dispatcher도 작동하기 위해서는 결국 CPU에 앉아야 한다.
어떻게 Dispatcher가 CPU에 앉을 수 있을까?
1) Traps & Faults : user process 내의 이벤트
ex) system call, floating point exceptions, page faults
2) Interrupts : user process 외부에서 발생한 이벤트
ex) I/O 작업 완료, 타이머(타이머가 끝나면 다시 OS에게 돌아가게 됨) 등
① Non-preemptive way : 스스로 양보!
- running -> waiting : I/O 요청을 수행하기 위해 기다려야할 때 process가 직접 dispatcher 호출
- running -> terminated : process가 종료 될 때 dispatcher 호출
② Preemptive way : 자리 뺏기!
- waiting -> ready : I/O 작업을 다 수행해서 다시 CPU로 돌아갸아 할 때 dispatcher에게 신호(interrupt)를 보냄. dispatcher는 신호가 오면 CPU에 올라가서 자리를 뺏고, 신호를 보낸 process에게 자리를 넘겨줌
- running -> ready : 돌고 있던 process가 더 돌 수 있는데, 위의 경우에 의해 자리를 뺏기게 됨
→ 이때, 일단 dispatcher가 제어권을 갖게 된 경우 그 다음 누구를 앉힐 지는 Policy가 결정!
Dispatcher의 역할들
디스패처는 Policy에서 정한 프로세스를 CPU에 앉혀주는 역할을 한다.
loop forever {
run the process a while
// choice another process to run (policy)
stop it and save its state
load state of another process
}① context switching : 원래 프로세스 stop & save -> 새로 load !!!
② switching to user mode
③ user program의 적절한 위치로 jump 하여 다시 시작
Context Switching
CPU 스케쥴러 중 Policy가 CPU를 점유할 프로세스를 정하고, Dispatcher가 그것을 수행한다는 것은 알겠음!
그런데 여기서 의문! CPU를 올라가거나 CPU에서 내려갈 때, 어떤 정보들을 가지고 가야할까?
Dispatcher는 이걸 어떻게 관리하지? 바로 Context Switch Mechanism을 통해 관리한다.
저장해야하는 정보들
- 현재 프로세스가 수행하고 있는 instruction의 주소
- 프로세스가 사용하던 CPU의 상태 정보
- register들
→ 이때, 메모리(책장)는 너무 크기 때문에 코스트가 비싸짐! 그래서 Dispatcher의 소관이 아님
//여기 작성
Scheduling Policies
스케쥴링은 하는 방법에 따라 코스트와 성능이 천차만별임!
스케쥴링은 queue를 통해 이루어짐
그렇다면 스케쥴링 정책에는 무엇이 있을까?
① CPU Utilization : CPU 는 최대한 쉬지 않고 많이 일한다.
② Throughput : 최대한 많은 process를 완료시킨다.
③ Turnaround Time : 각 프로세스가 실행되고 종료되기까지 걸린 시간으로 적을 수록 좋다.
④ Waiting Time : 각 프로세스들이 ready queue에서 기다린 시간은 적을 수록 좋다.
⑤ Response Time : 프로세스의 요청으로부터 응답까지 걸리는 시간은 적을 수록 좋다.
→ 이렇게 하기위해서는 Cycle, CPU burst, I/O burst 들을 잘 고려해야한다.
여러가지 스케쥴링 방식
① FCFS(First Come First Served)
먼저 들어온 순서대로 처리한다.
단순하고, 직관적이다.
- 문제점 : 하나의 프로세스가 CPU를 오랫동안 차지할 수 있다. -> convoy effect
- 해결 방법 : context switching 없이 실행될 수 있는 maximum 시간을 정해놓는다. -> time slice
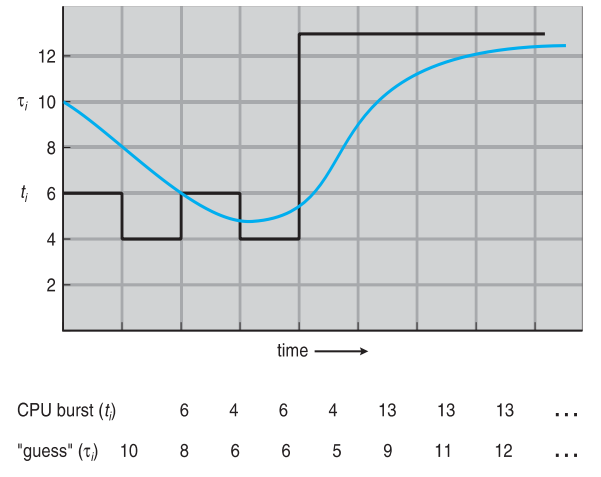
② SJF(Shortest Job First)
짧은 작업부터 처리한다.
가장 이상적인 알고리즘이다.
그러나, 미래를 예측할 수 없다. 즉 Process가 언제 작업을 마치는지를 알 수 없다.
두 가지 방식이 있음!
- Non-preemptive : CPU burst가 더 짧은 새로운 프로세스가 들어와도 일단 수행 중인 것은 수행한다.
- Preemptive : CPU burst가 더 짧은 새로운 프로세스가 들어오면, 그것을 먼저 수행한다.
-> Shortest Remaining Time First (SRTF) 혹은 Shortest Time to Completion First (STCF) 라고 한다.
③ RR(Round Robin)
FCFS방식대로 하되, time quantum(10~100ms)을 두어서, 그 시간만큼 씩만 순서대로 처리한다. 그리고 다시 ready queue의 맨 뒤로 간다.
- 특징 1 : SJF보다 평균 Turnaround time은 더 높지만, Response Time은 더 좋다.
- 특징 2 : n개의 process가 있고 time quantum이 q일 때, (n-1)q 이상 기다리는 프로세스는 없다.
- 문제점 1 : time quantum이 크면, FCFS가 되고,
time quantum이 너무 작으면, 오버헤드가 커진다. -> Timer interrupt!
또한, time quantum은 context switching time보다 커야한다. 프로세스 환경을 셋팅하다가 시간이 끝날 수도 있기 때문에!! - 문제점 2 : CPU burst time이 전부 다 똑같거나 클 경우, 오히려 FCFS가 효율적이다. Round Robin은 공정하지만, 비효율적일 수 있다.
- 해결 방안 : CPU bound process의 q는 길게, I/O bound process의 q를 짧게 하면 효율적이다.
④ Priority
priority number를 각 process 별로 부여한다.
우선순위가 높은 프로세스부터 실행한다.
- 문제 : 우선순위가 낮은 프로세스는 영원히 실행 안될 수도 있음 -> starvation
- 해결 방안 : 나이 개념을 도입해서 시간이 지나면 우선순위가 증가하도록 만든다 -> Aging
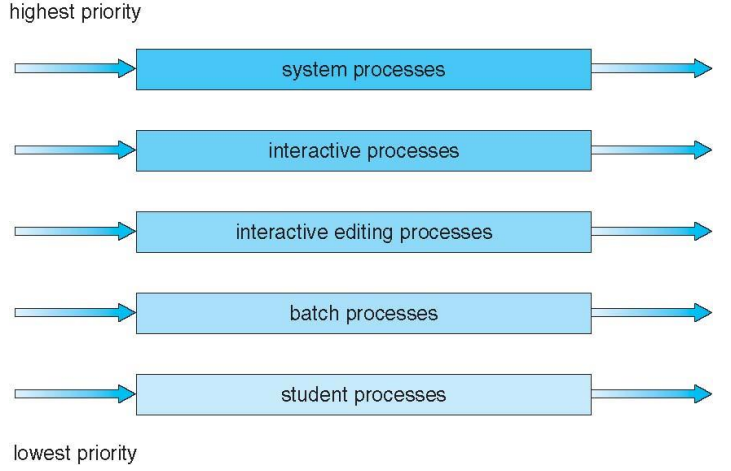
⑤ Multilevle Queue
I/O bound 와 CPU bound를 애초에 2개의 큐로 따로 관리한다.
- foreground(interactive) : 빠른 반응성, Shortest job 등 -> RR
- background(batch) : CPU 점유가 필요한 애들 -> FCFS
특징에 맞는 다른 policy를 적용한다. - 특징 : 높은 반응성이 필요한 foreground에 더 높은 우선순위와 더 긴 CPU 시간을 부여한다. -> 따라서 starvation 가능성이 있다.
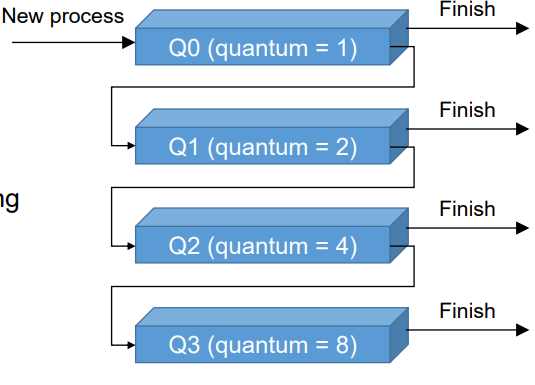
⑥ Multilevel Feedback Queue
프로세스들이 queue를 옮겨 다닐 수 있다.
quantum time이 다른 여러 개의 queue를 만든다.
이전 스케쥴링의 결과를 가지고 feedback하여 다음 번에 들어갈 큐를 정한다.
참고 : https://sanghyunj.tistory.com/18
⑦ Linux Scheduling
Completely Fair Scheduler(CFS)
- priority 대신 nice value 사용 (-20 ~ +19) -> nice value가 같으면 할당받을 수 있는 quantum time도 동일.
- virtual run time을 이용하여 virtual run time이 낮은 순으로 우선 순위를 정함.
- weight는 nice value에 의해 정해지는 값임. ex) P1 weight : P2 weight = 3 : 1
- decay factor는 weight의 역수. 즉, ex) P1 decay factor : P2 decay factor = 1 : 3
virtual runtime = 실제 CPU를 돈 시간 * scale factor
- 장점 : priority는 무조건 높은 애가 가져감. 하지만 decay factor을 이용한 방법은 CPU 타임이 적절히 분배가 된다.
즉, nice value -> weight -(역수)-> decay factor
