참고
- https://coe.gitbook.io/guide/log/efk
- https://jonnung.dev/system/2018/04/06/fluentd-log-collector-part1/
- https://ko.wikipedia.org/wiki/%EC%83%A4%EB%93%9C_(%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4_%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98
- https://ko.wikipedia.org/wiki/%EC%9D%BC%EB%9E%98%EC%8A%A4%ED%8B%B1%EC%84%9C%EC%B9%98
- https://bcho.tistory.com/1115+&cd=3&hl=ko&ct=clnk&gl=kr
- https://en.wikipedia.org/wiki/Parsing
- https://docs.fluentbit.io/manual/pipeline/inputs/forward
- https://logz.io/blog/fluentd-vs-fluent-bit/
0. 🙃 환경
kubernetes 1.20
linux
1. 🤔 EFK란?
ElasticSearch + Fluentd (fluent bit) + Kibana
마이크로 서비스는 각각의 애플리케이션을 띄워서 로그 또한 각각 관리하는 것이기 때문에 서비스간에 이어지는 트랜젝션의 흐름을 파악하기 어렵다. EFK는 마이크로 서비스에서 로그를 중앙 집중적으로 저장하고 분석하기 위해 사용하는 로깅 솔루션이다.
2. 😃 구성 요소 역할
😏 Elasticsearch : 로그 저장소, 검색 엔진
- 실시간 로그를 저장하여 필요한 내용을 검색하는 검색엔진
- 모든 종류의 문서를 검색하는데 사용할 수 있고, 분산 방식이므로 인덱스를 여러 샤드로 나눌 수 있으며 각 샤드는 0개 이상의 복제물을 지원.
샤드(shard) : 데이터베이스나 웹 검색 엔진의 데이터의 수평분할. 각 파티션은 샤드 또는 데이터 베이스 샤드라고 불린다. 어떤 데이터는 모든 샤드에 존재하지만 어떤 데이터는 한 샤드에만 존재한다. RDBMS에서 물리적인 분할이라고 생각하면 이해하기 쉽다. elasticsearch에서는 데이터를 분산해서 저장하는 샤딩 방법을 사용한다.
인덱스(index) : 엘라스틱 서치에서 index는 database 이다.
클러스터(cluster) : 하나 이상의 노드로 이루어진 노드의 집합
노드(node) : 이 글에서 구성하는 elastic search 에서는 data node 가 구성되는데 이는 crud 작업과 관련되어 있는 노드이다.
😒 Fluentd, Fluent bit : 로그 적재기
Fluentd 란?
- 로그 수집하고 저장소에 저장하는 로그 적재기
- 서로 다른 애플리케이션에서 로그를 수집하고 트래픽을 조정해 로그저장소에 로그를 수집힌다.
기존에 ELK를 구성하던 Logstash 보다 경량화된 버전으로 http, tcp 등 다양한 데이터를 수집가능하다.
Fluentd 같은 경우 7가지 컴포넌트로 구성되어 있는데, 기본으로 필요한 Engine을 제외하고 나머지, Input, Output, Parser, Filter, Buffer, Formatter 등 을 조합해 원하는 기능을 커스터마이징 가능하다.
- Input : 수집
- Output : 데이터 저장소에 데이터 저장
- Parser : 정규표현식 기반으로 데이터를 파싱(구문분석
- Filter : 필요한 정보만 필터링해서, 전송한 서버에 대한 데이터 필드를 추가, 혹은 삭제함
- Buffer : Input 에서 들어온 데이터를 Output으로 보내기전에 잠시 보관. 종류는 memory 와 file 이 있고, tag 단위로 chunk 가 생성
- Formatter : 저장하는 데이터 포맷 정의
위 같은 fluentd 컴포넌트 설정은 fluentd.conf 라는 파일에 정의한다.
또한 이 컴포넌트를 정의할 때 플러그인 을 사용할 수 있는데,
플러그인이란 컴포넌트를 정의할 때 추가적으로 사용하는 기능을 말한다.
예를 들어 s3라는 플러그인은 s3로 전달할때 사용, tail이란 플러그인은 로그의 끝부터 읽어드릴 때 사용한다.
fluentd 는 좋은 수집기이지만, 더욱 필요 없는 리소스 사용을 줄이기 위해서 이 포스팅에서는 fluent bit 라는 친구를 사용해볼 것이다!
fluent bit란?
그러면 fluentd 와 fluentbit는 어떠한 차이가 있는 걸까?
fluent bit는 앞서 자바 런타임이 필요한 JRuby logstash 에서 가벼워진 자바 런타임이 필요하지 않는 CRuby fluentd에서 더욱 경량화 된 C 로 만들어진 전송에 특화된 로그 수집기이다.
fluent bit 공식 사이트에 들어가면 이 둘의 차이를 디테일하게 보여준다.

결론적으로 요약하자면 fluentd는 플러그인 등 확장성이 좋고, fluent bit 는 리소스를 적게 차지 한다. 따라서 EFK 를 구성할 때 이 둘을 조합해서 사용하는 것이 좋다.
왜 조합하는 것이 좋은지는 아래 구조 파트에서 이어서 언급해보겠다.
😖 Kibana : 대시 보드
- 수집한 로그를 시각화 하는 대시 보드
3. 😃 구조
이번에 구성할 efk의 구조이다.
elasticsearch - fluentd - fleunt bit - kibana 조합이다.
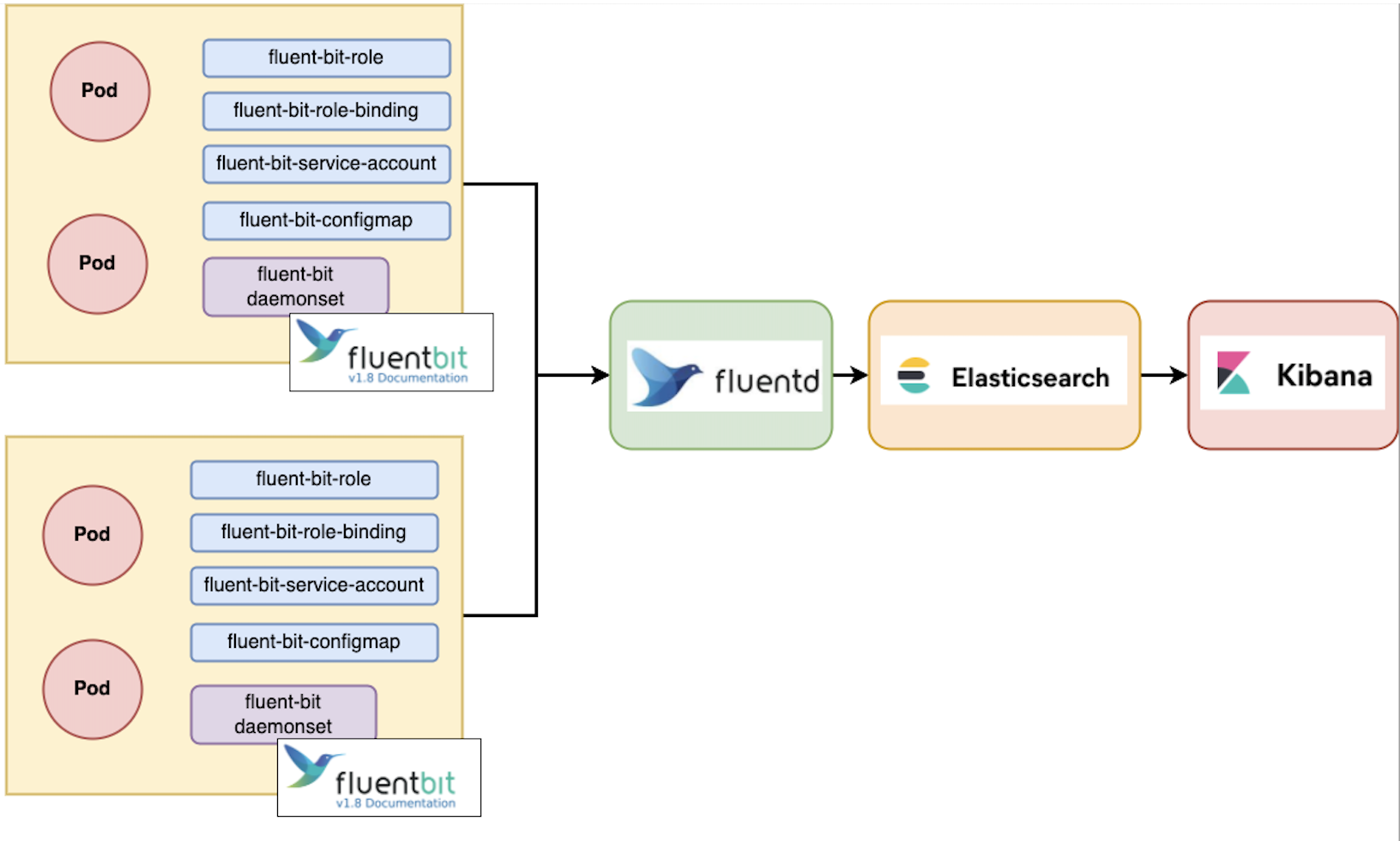
위에서 언급했던 것 처럼 이 구조를 사용할 예정인데 이유는
elasticsearch - fluent bit - kibana 로 되어 있는 구조보다 elasticsearch 에 부담이 덜가고 EKS 상에서는 가벼운 fluent bit 가 위치해 EKS의 리소스를 덜 사용하고, 또한 fluentd의 무수히 많은 플러그인을 사용할 수 있기 때문이다.
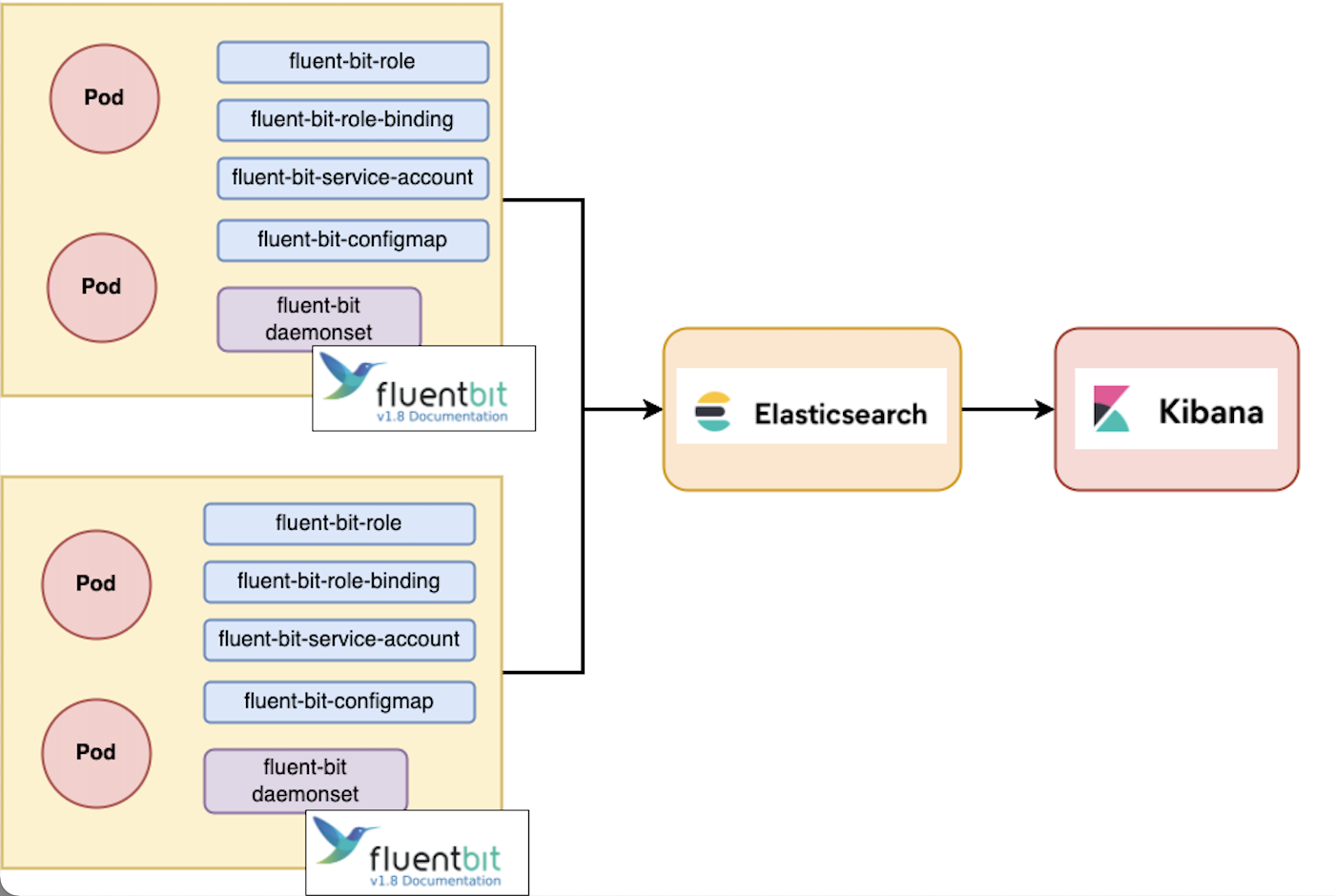
이번 실습에서는 위 그림의 2가지 구조다 구성하는 방법을 확인해볼 것이다.
4.🖐 daemonset 등 쿠버네티스 오브젝트 사용
잠깐! 이제 fluentd, fluent bit 가 뭔지, elasticsearch 가 어떤 역할을 하는지도 알았는데 그럼 쿠버네티스 클러스터 구조에서 대체 로그를 어떻게 fluent bit를 사용해서 elasticsearch나 fluent bit로 보낼 수 있을까?
😎 fluent-bit daemonset
이때 사용하는 것이 daemonset 이다.
데몬셋이 무엇인지 모르는 사람을 위해 간단히 설명하자면 노드 하나당 꼭 배포되는 파드이다.
즉, 클라우드 환경에서 autoscale이 되어 노드가 늘어 난다고 해도, 각 노드당 데몬셋으로 배포된 파드는 설정한 개수대로 존재한다.
참고 : https://kubernetes.io/ko/docs/concepts/workloads/controllers/daemonset/
위에 그림을 다시 확인해보면 fluent bit는 각 노드당 하나씩 만 존재해도 쿠버네티스에서 노드를 수집할 수 있다.
따라서 fluent bit daemonset 을 노드에 배포 해줄 것이다.
🥸 fluent-bit configmap
fluent bit는 conf 정보가 필요하다. 쿠버네티스 환경에서 fluent-bit.conf 정보를 저장하기 위해 사용하는 것이 configmap이다.
🧐 이외에도...
fluent-bit-service-account
fluent-bit-role
fluent-bit-role-binding
을 사용한다.
😚 5. 쿠버네티스 환경에서 애플리케이션 로그 수집 시나리오
이제 그럼 실습해보자.
먼저 할 구조는 elasticsearch - fluent bit - kibana 이다.
😛 5-1. elasticsearch - fluent bit - kibana 생성
참고 : https://docs.fluentbit.io/manual/installation/kubernetes
이 구조는 fluent bit가 바로 elasticsearch에 연동 되는 구조인데, 공식 가이드를 따라서 쉽게 구성할 수 있다.
1) docker-compose (kibana, elasticsearch)
먼저 공통으로 쓸 elasticsearch와 kibana docker-compose 파일을 만들어 준다.
version: '2.2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.8.1
container_name: es01
ports:
- "9200:9200"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 262144
hard: 262144
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
mem_limit: 2g
cap_add:
- IPC_LOCK
networks:
- elastic
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- bootstrap.memory_lock=true
- cluster.initial_master_nodes=es01
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- TZ=Asia/Seoul
kibana:
image: docker.elastic.co/kibana/kibana:7.8.1
container_name: kib01
links:
- "elasticsearch"
ports:
- 5601:5601
environment:
TZ: "Asia/Seoul"
ELASTICSEARCH_URL: http://es01:9200
ELASTICSEARCH_HOSTS: http://es01:9200
networks:
- elastic
networks:
elastic:
driver: bridge
- elasticsearch 필수 메모리 설정을 위해
ulimits.memlock을 설정해야 한다. TZ=Asia/Seoul한국 시간 설정은 필수- kibana와 elasticsearch는
elastic라는 네트워크를 공유하고 서로 연결되어 있다. ELASTICSEARCH_URL: http://es01:9200,ELASTICSEARCH_HOSTS: http://es01:9200를 잘 기억해두자.
그 다음 해당 도커파일이 있는 위치에 디렉토리를 만들어주고 권한을 변경한다.
mkdir elasticsearch
mkdir elasticsearch/data
chmod 777 elasticsearch
chmod 777 elasticsearch/data
그리고 docker-compose up -d
2) 쿠버네티스 오브젝트 생성
공식 문서 가이드
https://docs.fluentbit.io/manual/installation/kubernetes
# 네임스페이스
$ kubectl create namespace logging
# 서비스 어카운트
$ kubectl create -f https://raw.githubusercontent.com/fluent/fluent-bit-kubernetes-logging/master/fluent-bit-service-account.yaml
# 롤
$ kubectl create -f https://raw.githubusercontent.com/fluent/fluent-bit-kubernetes-logging/master/fluent-bit-role.yaml
# 롤 바인딩
$ kubectl create -f https://raw.githubusercontent.com/fluent/fluent-bit-kubernetes-logging/master/fluent-bit-role-binding.yaml
# 컨피그 맵
$ kubectl create -f https://raw.githubusercontent.com/fluent/fluent-bit-kubernetes-logging/master/output/elasticsearch/fluent-bit-configmap.yaml
# 데몬셋
$ kubectl create -f https://raw.githubusercontent.com/fluent/fluent-bit-kubernetes-logging/master/output/elasticsearch/fluent-bit-ds.yaml
롤바인딩까지는 그냥 쿠버네티스 명령어를 쳐도 되지만 컨피그 맵과 데몬셋은 한 번 설정을 봐주자
fluent-bit-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
labels:
k8s-app: fluent-bit
data:
# Configuration files: server, input, filters and output
# ======================================================
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-kubernetes.conf
@INCLUDE filter-kubernetes.conf
@INCLUDE output-elasticsearch.conf
input-kubernetes.conf: |
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
filter-kubernetes.conf: |
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude Off
output-elasticsearch.conf: |
[OUTPUT]
Name es
Match *
Host ${FLUENT_ELASTICSEARCH_HOST}
Port ${FLUENT_ELASTICSEARCH_PORT}
Logstash_Format On
Replace_Dots On
Retry_Limit False
parsers.conf: |
[PARSER]
Name apache
Format regex
Regex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
... 길어서 생략...
@INCLUDE input-kubernetes.conf .. input-kubernetes.conf: |
: 플러그인 추가하는 방식
[INPUT]
Name tail: Name {플러그인 종류}
fluent-bit-ds.yaml
...길어서 생략
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
... 길어서 생략
FLUENT_ELASTICSEARCH_HOST 의 value에다가 아까 도커 컴포즈 파일을 사용해 띄울 elasticsaerch의 IP 를
FLUENT_ELASTICSEARCH_PORT 의 value에다가 elasticsaerch의 Port를 집어 넣는다.
그리고 각각 생성해준다.
kubectl create -f fluent-bit-configmap.yaml
kubectl create -f fluent-bit-ds.yaml
이러면 화면이 뜨기 시작하고 로그가 수집이된다.
다음 명령어를 도커 컴포즈 파일이 있는 서버에서 쳐서 인덱스가 잘 수집되어 있는지 확인하자
curl -XGET 'localhost:9200/_cat/indices?v'포스팅이 너무 길어져서 2탄에서 계속 진행하겠습니다

2탄 언제적어주세요...? ㅠㅠㅠ