
파드를 안정적으로 유지하는 방법
prob
해당 노드의 kubelet 은 파드의 컨테이너를 실행하고 파드가 존재하는 한 컨테이너가 계속 실행된다.
그럼 kubelet 은 어떻게 파드의 컨테이너가 정상인지 확인할 수 있을까?
그걸 확인하기 위해 사용하는 옵션이 liveness probe 이다
liveness 라는 말 그대로 주기적으로 컨테이너가 살아 있는지 확인할 수 있다. 서비스의 정상 작동이 중요한 운영환경에서는 꼭 적용해야하는 옵션이기도 하다.
만약, 이 liveness 옵션이 적용된 파드의 컨테이너가 살아있지 않음이 확인된다면(주기적으로 확인하는 헬스체크 로직에 응답하지 않는다면) kubelet은 컨테이너를 다시 실행한다.
liveness probe는 이 health check 로직을 애플리케이션의 주요 서비스에 (ex: order/payment 결제) 지정하여 중요 서비스가 정상 작동하는지도 확인할 수 있다.
하지만, 프로브가 너무 많은 일을 하면 컨테이너의 속도를 느려지게 만들기 때문에 1초 내에 완료될 수 있는 로직을 구성해야한다.
prob 는 3가지 계열이 있다
- exec : 전체 JVM 에 대한 health check
- httpGet : http health check
- TCP 소켓 : tcp health check
아래는 그 중 exec 에 관련된 liveness prob 이다.
exec-liveness.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5apply 하고 describe 로 확인해보면 다음과 같이 라이브니스 옵션이 들어간것을 확인할 수 있다.

이번에는 위에서 사용한 옵션을 확인해보자
- initialDelaySeconds : 쿠버네티스는 첫번째 프로브 실행까지 지정한 초만큼 대기
- periodSeconds : 지정한 초 주기로 확인
replicaSet ( ReplicationController)
https://kubernetes.io/ko/docs/concepts/workloads/controllers/replicationcontroller/
https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
레플리케이션컨트롤러는 파드를 항상 실행되도록 보장하는 쿠버네티스 리소스이다. 클러스터에서 노드가 사라지거나 노드에서 파드가 제거된 경우, 레플리케이션컨트롤러는 사라진 파드를 감지해 교체 파드를 생성한다. 또 실행중인 파드의 개수가 실제 지정한 파드의 수와 일치하는지 확인한다.
레플리케이션 컨트롤러의 구성요소 3가지
- label selector : 레플리케이션 컨트롤러가 관리하는 파드
- replica count : 지정한 파드의 수
- pods template : 파드 템플릿
replicationcontroller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80

kubectl apply -f replicationconroller.yaml

근데 이 레플리케이션 컨트롤러는 최근 레플리카셋으로 대체 되었다.
레플리케이션 컨트롤러와 비교해서 레플리카 셋은 더 selector 기능을 더 풍부한 표현식을 사용하게 개선하였다.
그것은 이따 뒤에 보고 일단 레플리카컨트롤러와 별반 다를게 없는 레플리카셋을 먼저 봐보자
replicaset.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# 케이스에 따라 레플리카를 수정한다.
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3

label
레플리케이션 리소스(replicationController, replicaSet) 는 label 기준으로 다루기 때문에 레이블을 다루는 것이 중요하다.
- label 보기
kubectl label pods --show-labels
- 레이블 달기

- 해당 레이블만 보기
kubectl get pods -L type
replica 편집하기
레플리카 즉, 파드의 개수를 편집하는 방법은 3가지가 있다.
- yaml 파일을 편집하고 apply 하기
- kubectl edit rs {rs} (kubectl edit deploy {deploy} )

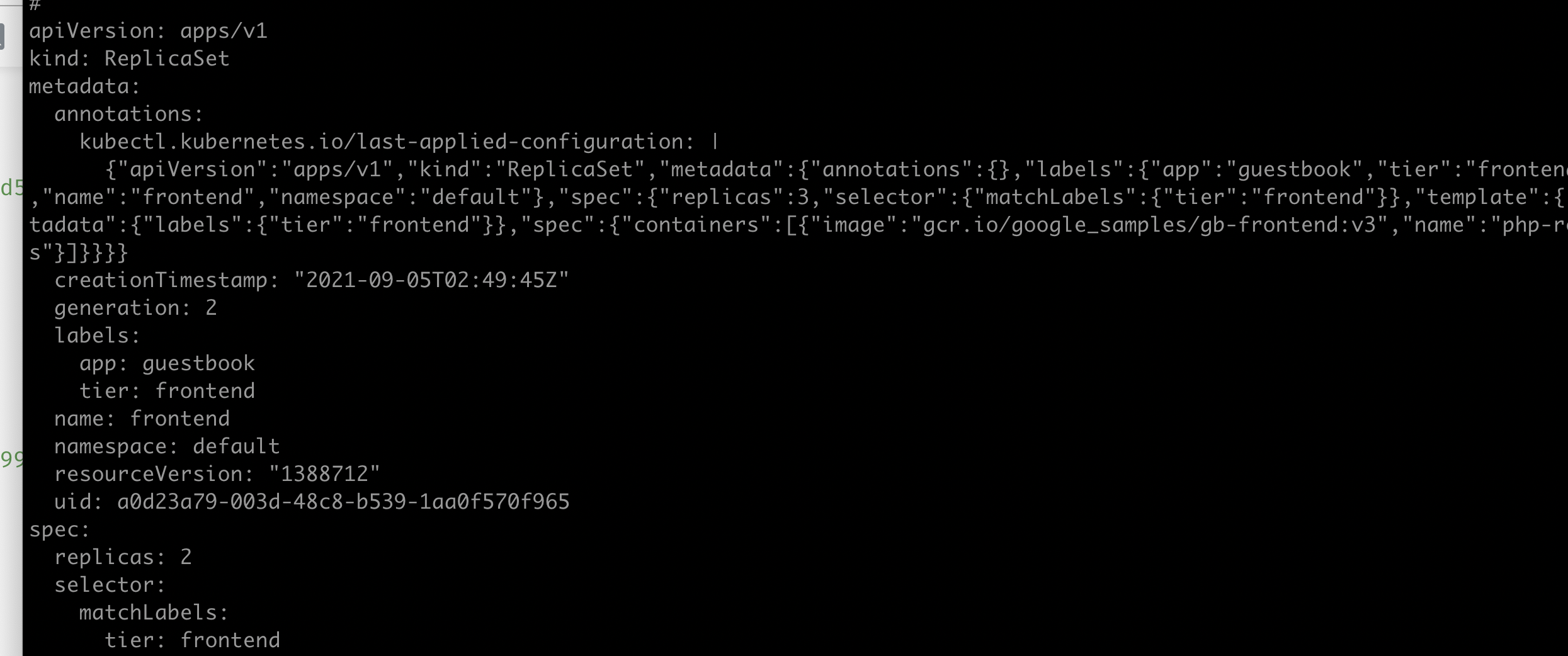
- kubectl scale rs frontend --replicas=3

이렇게 파드의 개수를 조장하는 것을 수평 파드 스케일링이라고 하고 scale out 이라고 한다.
이번에는 다 사용한 리소스를 삭제해보자
kubectl delete rs {rs 이름 } --cascade=false
--cascade=false 옵션은 파드를 계속 유지시킨다. true 로 주면 실행하는 파드도 삭제할 수 있다.

replicaSet 의 표현식
앞서 말했던 것처럼 레플리카셋은 더 풍부한 표현식, matchExpressions 을 사용할 수 있다.
selector:
metchExpressions:
- key: app
operator: In
values:
- app2이 셀렉터는 파드의 키가 app 인 레이블을 포함해야하고 레이블의 값은 app2여야 한다.
또 셀랙터에 다음 옵션을 추가할 수 있다.
- In : 레이블의 값이 지정된 값중 하나와 일치
- NotIn : 레이블의 갓이 지정된 값과 안일치
- Exists : 파드는 지정된 키를 가진 레이블이 포함되야함
- DoesNotExist : 파드는 지정된 키를 가진 레이블이 포함돼 있지 않아 한다.
데몬셋
https://kubernetes.io/ko/docs/concepts/workloads/controllers/daemonset/
쿠버네티스 클러스터는 보통 하나의 노드로 구성되지 않는다. 여러가지의 노드로 구성되있는 환경에서 각각의 노드에 한개씩 파드를 배포하고 싶을 대는 daemonSet 을 사용한다.
데몬셋은 노드수 만큼 파드를 만들고 각 노드에 배포한다.
데몬셋을 사용하면서도 특정 노드에만 배포하게 설계할 수 있는데 그것은 node-selector 속성을 사용하는 것이다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
EFK 에서 각각의 파드의 노드를 로그를 수집하기 위해서는 fluentd와 elasticsearch 를 각각의 노드에 설치해야한다. 위의 예제를 보면 그것에 응용하는 yaml 스크립트이다
배포할 노드도 선택하여 배포 할 수 있는데 노드에 label 을 달고 deplement, rs, daemonset 에 label 을 달면 해당 파드가 지정한 노드로 배포 된다
kubectl get node
kubectl label node {node name} disk=ssd
kubectl label node {node name} disk=hdd --overwride
잡
잡에서 하나 이상의 파드를 생성하고, 지정된 수의 파드가 성공적으로 종료될 때까지 계속해서 파드를 재시도한다. 파드가 성공적으로 완료되면 완료된 잡을 추적하여 잡을 완료 시킨다. 만약, 잡이 삭제된다면 잡이 생성한 파드도 삭제한다.
job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4

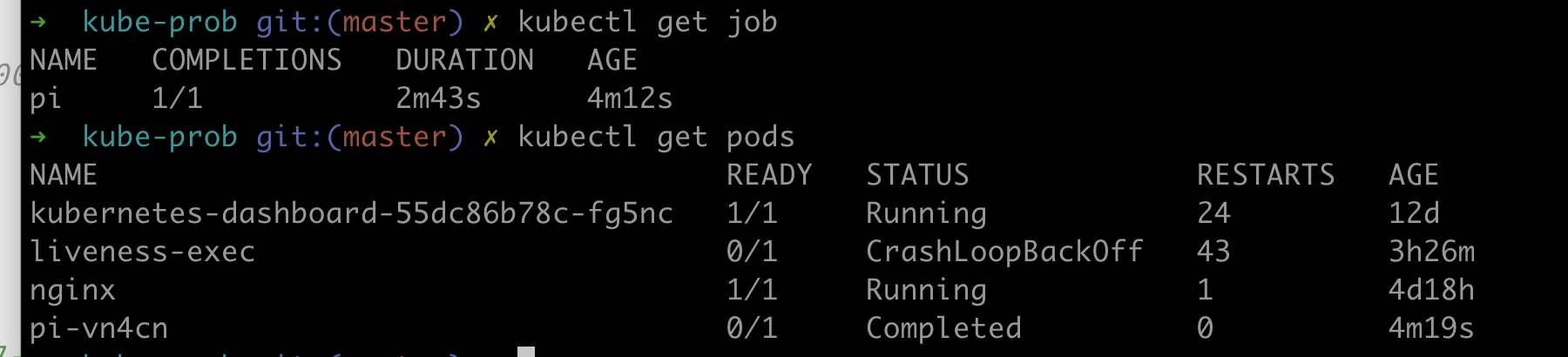
만약 다섯개의 파드를 순차적으로 실행할려면 다음과 같이 Completions 옵션을 사용하면 된다.
apiVersion: batch/v1
kind: Job
metadata:
name: multi-job
spec:
completions: 5
template:
spec:
containers:
- name: pi2
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]


그리고 5개의 파드를 병렬로 실행하고 싶다 하면 parallelism 로 몇개 까지 병렬 할지 지정해서 사용할 수 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: multi-job
spec:
completions: 5
parallelism: 2
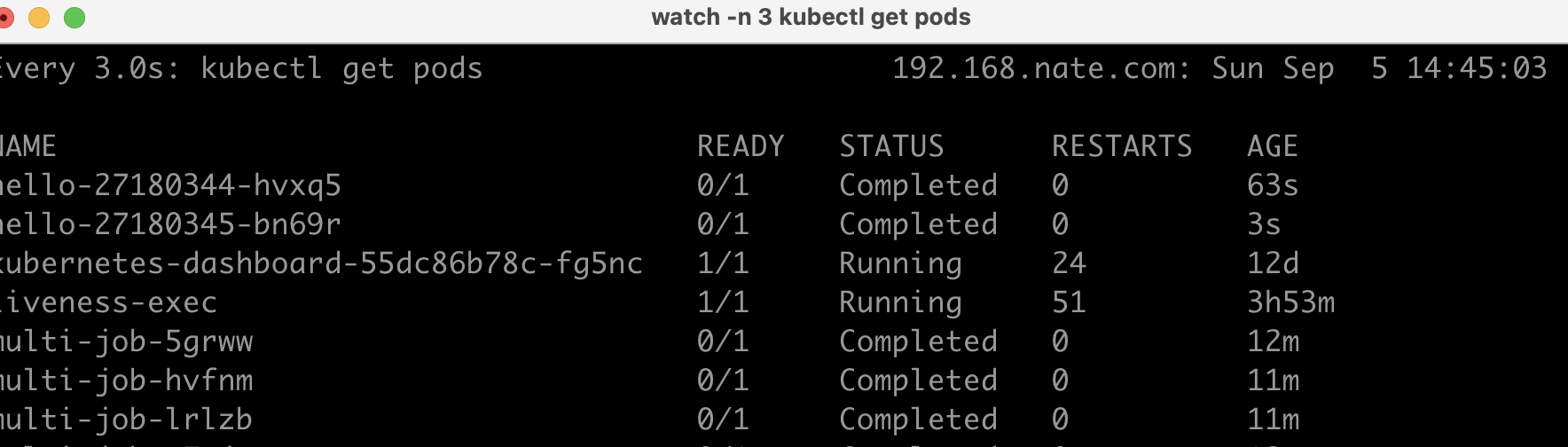
아래 실행 파일을 보면 동시에 2개가 실행되는 것을 볼 수 있다.

이런 잡을 일정한 시간마다 실행하고 싶으면 어떻게 해야할까?
크론잡
https://kubernetes.io/ko/docs/concepts/workloads/controllers/cron-jobs/
그럴 때는 Crontab 을 사용하면된다.
아래의 스크립트는 1분에 한번씩 hello pods 를 생성해난다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
시간을 거는것은 schedule 옵션으로 배치 스케줄링이랑 같이 참고하면 된다.
참고
쿠버네티스 공식문서
쿠버네티스 인 액션
