
2. MIPS를 들어가기 앞서서
(1) 메모리 명령어
🖥︎컴퓨터는 아쉽지만 한글로도, 영어로도 대화할 수 없는 상대이다. 컴퓨터 하드웨어가 일을 하려면 하드웨어가 알아들을 수 있느 언어로 이야기를 해주어야 한다. ⌨ 그 때 사용하는 단어를 명령어, 어휘를 명령어 집합이라고 부른다.
(2) 특징
-
동일한 ISA family🖥︎는 동일한 명령어로 구성되어 있다. Intel, ARM, MIPS등 내부적으로는 동일한 명령어 구조이며, 중요한 특징 중 하나로 이전 버전과 호환이 되는 하위호환성을 지원한다.
-
다른 컴퓨터는 다른 명령어 집합으로 구성되어 있다. 그러나 이와 동시에 공통적인 요소도 많이 있다. 그래서 컴퓨터 구조를 우리는 배울 수 있다. 👩💻 👨💻
(3) CISC, RISC
컴구조론 관련해서 면접 대비 질문에 종종 포함되어 있는 것을 발견할 수 있는 그 두 방식이다. 이 둘의 공통점은 CPU를 설계하는 방식이라는 점이며,CPU가 작동하기 위해서는 명령어를 주입해서 설계를 해줘야 한다.
✔CISC(Complex Instruction Set Computer) 💽
100개 ~ 250개 정도의 복잡하고 많은 종류의 명령어와 주소 지정 모드를 사용하며, 가변 길이 명령어 형식이다. 또한 마이크로 프로그래밍(S/W) 제어 방식이며, 명령어가 소프트웨어적이므로 호환성이 좋다. 컴파일 과정이 역시 어렵지 않고 호환성이 좋다는 장점이 있지만 속도가 느리다.
✔RISC(Reduced Instruction Set Computer) ⚙
Reduced에서 힌트를 얻자! 이후에도 나오겠지만 결국 CPU에서의 연산이 대부분 몇 개의 명령어의 응용인 것에서 영감을 받았다. 이로 인해 간단하고 적은 종류의 명령어와 주소 지정 모드를 사용한다. 효율적인 파이프라이닝 구조를 사용하며 명령어가 하드웨어적이므로 호환성이 낮다. 성능이 비교적 떨어지며 전력 소모도 적다. 🔋 처리 비트 단위가 변하거나 프로세서 구조가 조금만 바뀌어도 하위 프로세서와의 호환성이 떨어진다.
2.2 하드웨어 연산
기본적으로 모든 컴퓨터는 산술연산을 할 수 있어야 한다. 다음 MIPS 어셈블리어는 두 변수 b와 c를 더해서 a에 넣는 것
add a, b, cMIPS 산술 명령어는 반드시 한 종류의 연산만 지시하며 항상 변수 세 개를 갖는다. 그렇다면 4개는 계산이 불가능한가? 아니다.
add a, b, c add a, b, c
add a, a, d or add f, d, e
add a, a, e add a, a, f위와 같이 2개, 2개를 나눠서 계산하면 된다.
덧셈과 같은 피연산자는 더해질 숫자와 합을 기억할 장소, 총 세 개인것이 자연스럽다. 이렇게 피연산자를 세 개로 고정하는 것은 하드웨어를 단순하게 하자는 원칙에도 부합한다. 이렇게 우리는 하드웨어 설계 3대 원칙 중 첫 번째를 도출할 수 있다.
✔설계 원칙 1: 간단하게 하기 위해서는 규칙적인 것이 좋다.
2.3 피연산자
상위 수준의 언어프로그램과 달리 산술 명령어의 피연산자에 제약이 있다. 레지스터라고 하는 하드웨어로 직접 구현된 특수 위치 몇 곳에 있는 것만을 사요할 수 있다. 🧱레지스터🧱는 하드웨어 설계의 기본 요소인 동시에 프로그래머에게 보이는 부분으로 벽돌과 같은 역할을 한다. MIPPS구조에서 레지스터의 크기는 32비트이다. 그리고 이렇게 한 덩어리로 처리되는 일이 매우 빈번하므로 이것을 워드라고 부른다
레지스터 개수를 32개로 제한하는 이유는 하드웨어 기술의 바탕이 되느 세가지 설계 원칙 중 두 번째 원칙에서 찾을 수 있다.
✔설계원칙 2: 작은 것이 더 빠르다
레지스터가 아주 많아지면, 전기 신호가 당연히 더 멀리까지 전달되어야 하므로 클럭 사이클 시간이 길어진다. 또한 2.5에 나오지만 명령어 형식에서 레지스터가 사용하는 비트 수와 관련이 있다.
우리는 단순히 번호 0부터 31까지를 사용해 명령어를 작성하지만 레지스터를 나타내기 위해서는 MIPS 관례는 달러 기호 뒤에 두 글자가 따라 나오는 이름을 사용한다.
C code f = (g + h) – (i + j);
위와 같은 C 코드를
dd t0, g, h add f, g, h
add t1, i, j or sub f, f, i
sub f, t0, t1 sub f, f, j
다음과 같이 컴파일된 MIPS 코드로 나타낼 수 있다. (t0, t1은 임시레지스터)
메모리 피연산자 👀
프로그래밍 언어에는 단순 변수 외에도 배열이나 구조체 같은 복잡한 자료구조도 존재한다. 이런 큰 구조는 어떻게 표현되고 또 사용될까?
프로세서는 소량만 레지스터에 저장이 가능하지만 메모리는 수십 억개의 데이터를 저장할 수 있다. 그러므로 구조체, 배열 등은 메모리에 보관한다.
앞서 살펴본 것처럼 MIPS의 산술연산은 레지스터에서만 실행되므로 메모리와 레지스터 간에 데이터를 주고 받는 명령이 있어야 한다. 🔀 이런 명령어를 전송 명령어라고 한다. 🔀 메모리에 기억된 데이터 워드에 접근하려면 명령어가 메모리 주소를 지정해야 한다.

메모리에서 레지스터로 데이터를 복사해 오는 데이터 전송 명령을 적재(load)라고 한다. MIPS에서 이 명령어의 실제 이름은 lw(load word)이다. 적재와 반대로 레지스터에서 메모리로 데이터를 보내는 명령을 저장(store) 이라 하며 MIPS에서 이 명령어의 실제 이름은 sw(store word)이다.
하드웨어 소프트웨어 인터페이스❗❗
변수를 레지스터와 연관 짓는 일뿐 아니라 배열이나 구조체 같은 자료 구조를 메모리에 할당하는 것도 컴파일러의 역할이다. 그런 다음 컴파일러는 자료구조의 시작 주소를 데이터 전송 명령에 넣을 수 잇다.
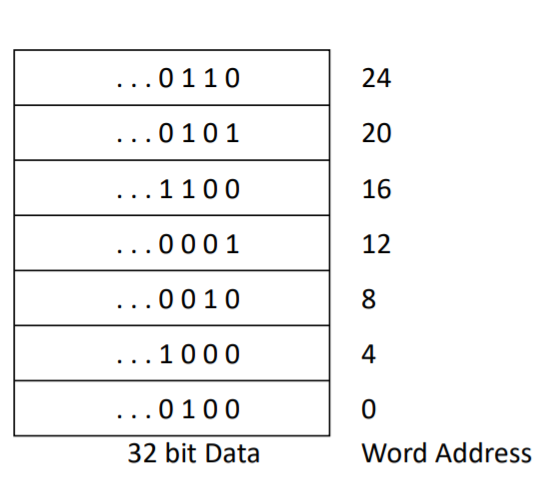
프로그램에서는 8비트로 구성된 바이트를 많이 사용하므로 대부분의 컴퓨터는 바이트 단위로 주소를 지정한다. 워드 주소는 워드를 구성하는 3바이트 주소 중 하나라를 사용한다. 그러므로 연속된 워드의 주소는 4씩 차이난다. 위의 그림은 실제 주소를 보여주는 것이다. 예를 들어 세 번째 워드의 바이트 주소는 8이다.
MIPS에서 워드의 시작 주소는 언제나 4의 배수여야 한다. 이런 요구 사항을 정렬 제약이라고 하며 많은 컴퓨터에서 이 방법을 사용한다.
정렬 제약: 메모니 내에서 데이터는 자연스러운 경계를 지켜서 정령되어야 한다는 요구 조건
컴퓨터의 주소를 사용하는 방식에는 크게 두 가지 계열이 잇는데 MIPS는 최상위 주소를 사용하는 빅-엔디안(big-endian) 계열에 속한다.
이러한 주소 사용은 배열의 인덱스에도 영향을 미친다. a[8]과 같은 코드에서 바이트 주소를 제대로 구하려면 베이스 레지스터에 *4를 한 값인 32를 더해야 한다.
상수 또는 수치 피연산자 🧮
프로그램의 연산에서 상수를 사용하는 경우가 많다. 이제까지 배운 명령어만으로 상수를 사용하려면, 메모리에서 상수를 읽어와야 한다. 여기서 적재 명령을 사용하지 않는 방법은 피연산자 중 하나가 상수인 산술연산 명령어를 제공하는 것이다. 이 상수를 수치(immediate) 피연산자라고 한다. 수치 피연산자를 갖는 덧셈 명령어는 addi(i만 붙었당)이다.
addi $s3, $s3, 4 상수 피연산자는 자주 사용되므로 🏃자주 생기는 일을 빠르게🏃 라는 원칙의 예가 된다. 이와 더불어, 상수 0은 복사 등의 연산도 가능하게 한다. 그래서 레지스터 $zero 값을 0으로 고정해두도록 회로가 구현되어 있다.
2.4 명령어의 컴퓨터 내부 표현 👀

MIPS 언어를 조금 더 자세하게 들여다보도록 하자 🔍
갑자기 새로운 표가 나와서 놀랐겠지만 익숙해져야 한다. 위와 같은 레이아웃을 명령어 형식(instruction foramt)이라고 한다. 표시하기 쉽게 MIPS 명령어의 각 필드에는 외계어가 붙어있다. (변수명을 잘 지어야 하는 이유,, 근데 외계어같지만 들여다보면 다 이해가 된다) 위의 외계어들을 하나하나 🔍살펴보자🔍.
- op:명령어가 실행할 연산의 종류로서 연산자(opcode)라고 부른다
- rs: 첫번째 source 피연산자 레지스터
- rt: 두 번째 source 피연산자 레지스터
(tmi: 둘이 헷갈린다. two번째,, 라고 저는 외웠습니다) - rd: 목적지(destination) 레지스터, 연산 결과가 기억된다.
- shamt: 자리 이동량. 이후에 shift연산을 할 때 주인공으로 등장한다.
- funct 기능(function) op랑 헷갈리는데 op는 연산의 종류를 표시하고 funct 필드에는 그중의 한 연산을 구체적으로 지정한다.
이것보다 필드가 길어야 한다면? 설계자는 고민에 빠진다. 여기서 마지막 하드웨어 설계 원칙이 도출된다.
✔설계 원칙3 : 좋은 설계에는 적당한 절충이 필요하다.
MIPS 설계자들이 택한 절충안은 모든 명령어의 길이를 가텍 하되, 명령어의 종류에 따라서 형식은 다르게 하는 것이다. 위를 보면 마치 포켓몬의 불속성, 땅속성, 물속성처럼 R, I, J 타입으로 나뉘어 있는 것을 볼 수 있다.
I타입(Immediate)라는 두번째 명령어 형식은 수치 연산과 데이터 전송 명령어에서 사용된다. 16(5+5+6, 실제로 더해가면서 이해해보자) 비트 주소를 사용하므로 lw명령은 베이스 레지스터 rs에 저장된 주소를 기준으로 ±2^15 = 32,768바이트(8192워드)를 지정할 수 있다. 이로 인해서 addi에서 사용할 수 있는 상수는 ±2^15보다 더 클 수 없다.
명령어 형식이 여러가지가 되면 자연히 하드웨어가 복잡해지지만 모든 형식을 유사하게 함으로써 복잡도를 낮출 수 있다. 예를 들어 R타입과 I타입의 처음 세 필드는 이름과 크기가 같고, I 타입의 네 번째 필드 길이는 R타입의 나머지 세 필드 길이를 더한 것과 같게 하였다.
🍵오늘 내용 정리🍵
오늘날 컴퓨터는 두 가지 중요한 원리에 바탕을 둔다.
1. 명령어는 숫자로 표현된다.
2. 프로그램은 메모리에 기억되어 있어서 숫자처럼 읽고 쓸 수 있다.
이것이 바로 내장 프로그램의 개념이다. 이 개념 덕분에 컴퓨터가 엄청난 속도로 발전해왔다🚀
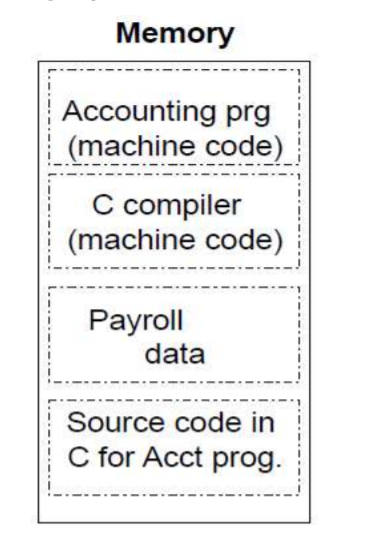
메모리에는 편집기가 편집 중인 소스코드, 컴파일된 기계어 프로그램, 실행 프로그램이 사용하는 텍스트 데이터, 심지어는 기계어를 생성하는 컴파일러까지도 기억된다. 명령어를 숫자로 바라본 결과, 프로그램이 이진수 파일 형태로 배포&판매 되었다. 그렇기 때문에 상업적으로는 만약 기존 명령어 집합과 호환성이 있다면 다른 컴퓨터의 소프트웨어를 물려받을 수 있다는 의미를 갖는다. 이러한 '이진 호환성(binary compatibility)'문제 때문에 상업적으로 살아남는 명령어 집합 구조는 매우 소수다.
