
역시 적어두지 않으면 백날 공부해도 기억이 나지를 않는다.
김영한님 강의도 다 듣고, 여러 블로그를 봤지만 남들 앞에서 속 시원하게 내가 설명할 수가 있나? 아무런 지식도 없는 사람한테 설명해야한다고 생각하고 집중해보자.
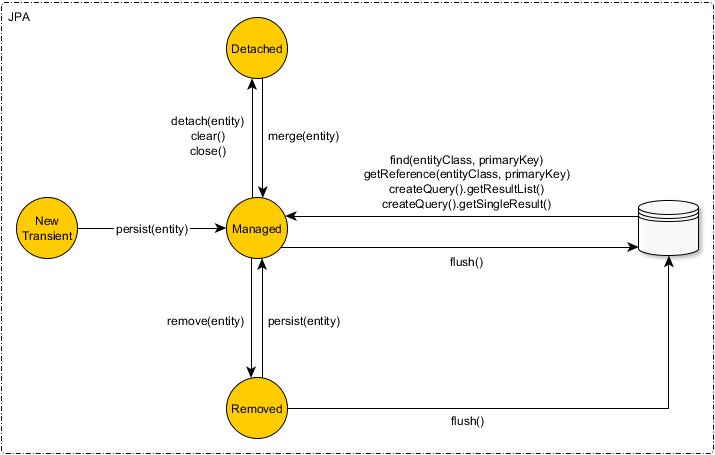
1차 캐시
1차 캐시의 속살
1차 캐시에 저장된다는 건, Map 에 저장된다는 뜻이다.
Map<EntityUniqueKey, Object> entitiesByUniqueKey = new HashMap<>(INIT_COLL_SIZE);Map 에서 Key 는 중복을 허용하지 않는다. 즉 Entity 는 동일한 identifier 로 저장될 수 없다. 이는 트랜잭션 내에서 데이터의 무결성을 보장한다.
EntityUniqueKey 객체는 아래와 같다.
public class EntityUniqueKey implements Serializable {
private final String entityName;
private final String uniqueKeyName;
private final Object key;
private final Type keyType;
...
@Override
public boolean equals(Object other) {
EntityUniqueKey that = (EntityUniqueKey) other;
return that != null &&
that.entityName.equals(entityName) &&
that.uniqueKeyName.equals(uniqueKeyName) &&
keyType.isEqual(that.key, key);
}
...
}
DB 에서 조회할 때, DB 에 저장할 때 모두 1차 캐시, 2차 캐시에 저장된다. 다시 한번 말해보자면 DB 에 존재하는 데이터와 캐시된 데이터가 100% 일치한다는 것이다.
1차 캐시 는 엔티티마다 독립적이다.
1000개의 DB 요청 발생 시, EntityManager 가 100개 정도 생성되고, Thread 소멸 시, 함께 소멸된다.
2차 캐시 는 Application 과 함께한다.
cache synchronization
batch
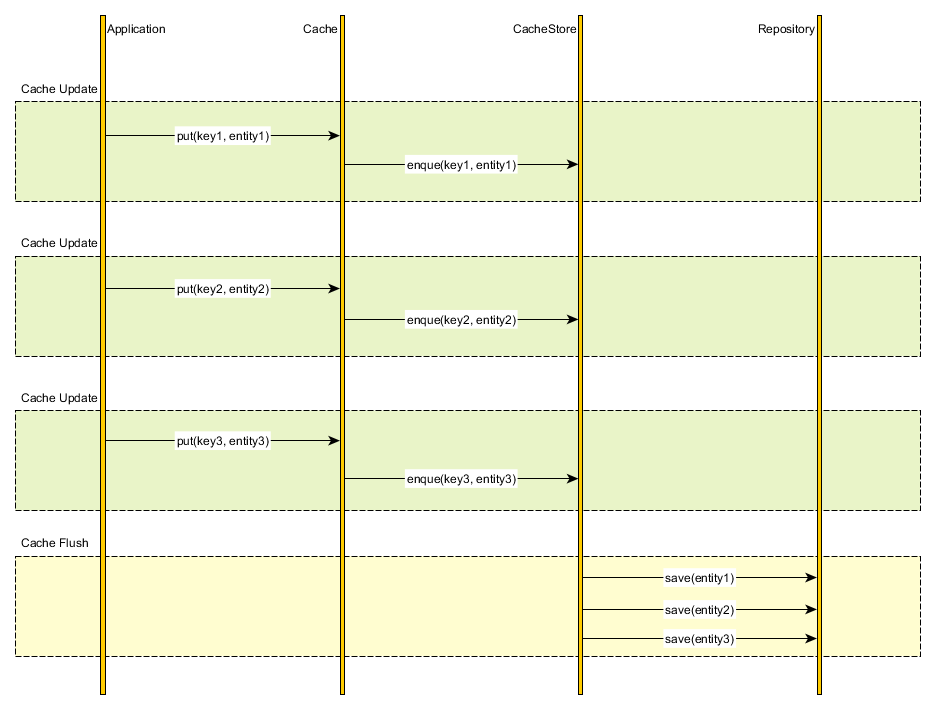
.flush() 를 하는 시점에, DB에 반영 된다. 그 전에는? cache 에 넣고 일단 지켜보는거야~
LoadEntityEvent
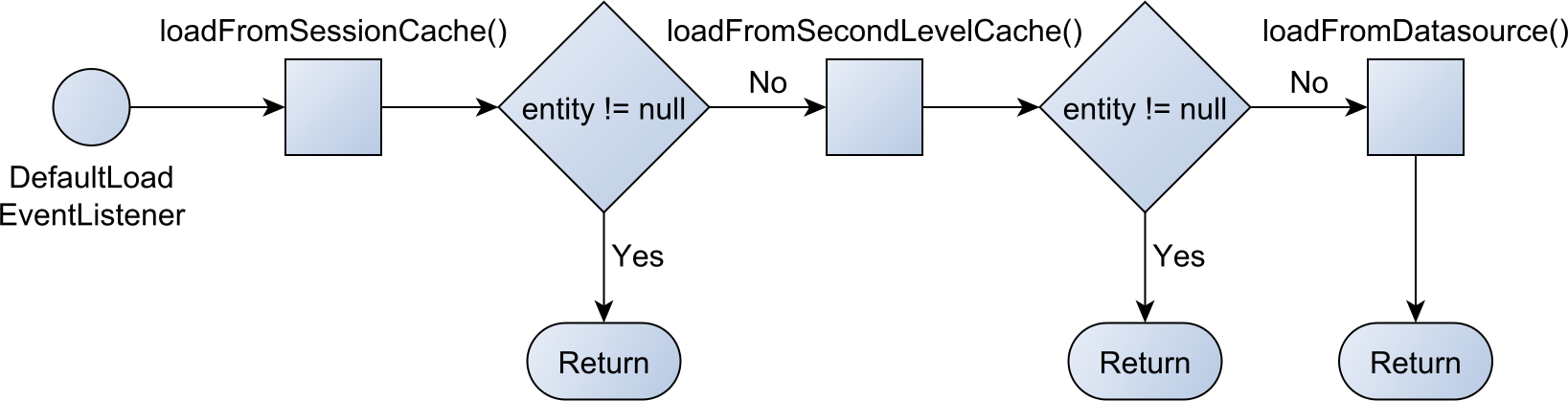
JPA 는 1차 캐시, 2차 캐시, DB 순서로 데이터가 존재하는지 찾는다. 데이터를 찾은 다음에는?
2nd level cache
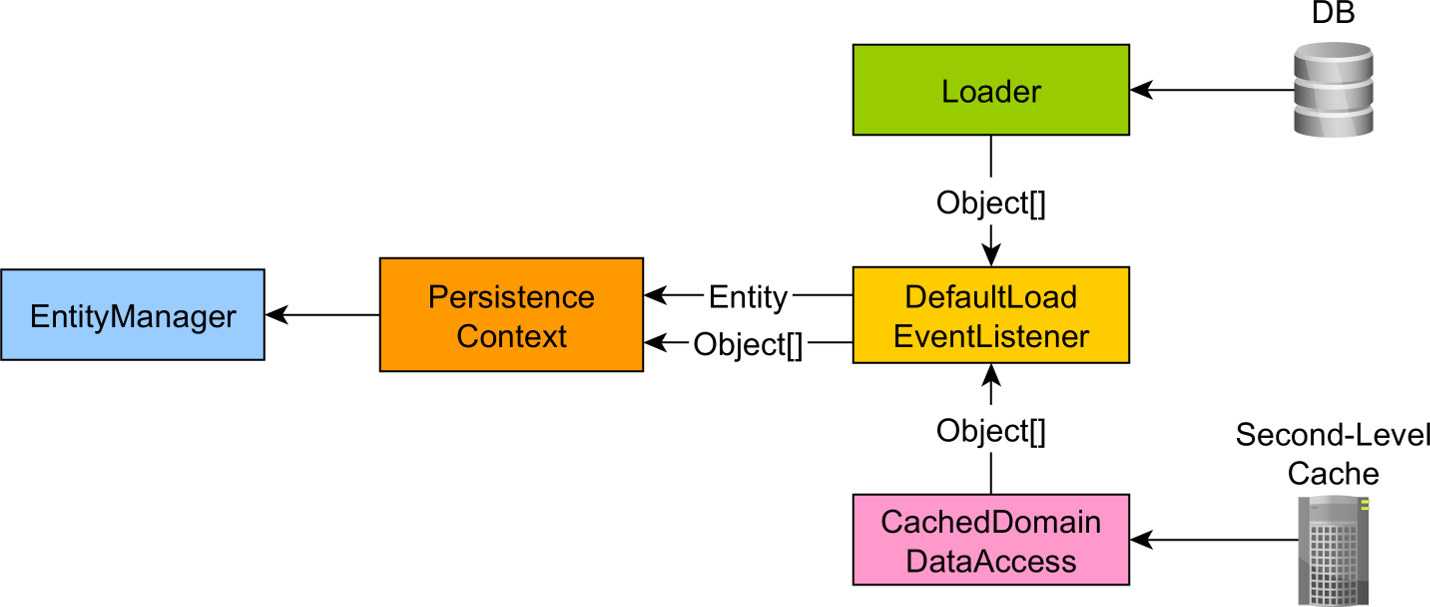
DB 에서 받아오는 엔티티와 더불어, 2차 캐시에도 데이터를 저장하는 부담이 생긴다. 데이터가 1000만건, 1억건이 되면 어떻게 될까?
스케일링 시 서버가 너무 많은 양의 데이터를 감당해야할 것이다.
여기서 Dirty Checking 메커니즘이 등장한다.
dirty checking
아우 뭐가 이렇게 복잡해
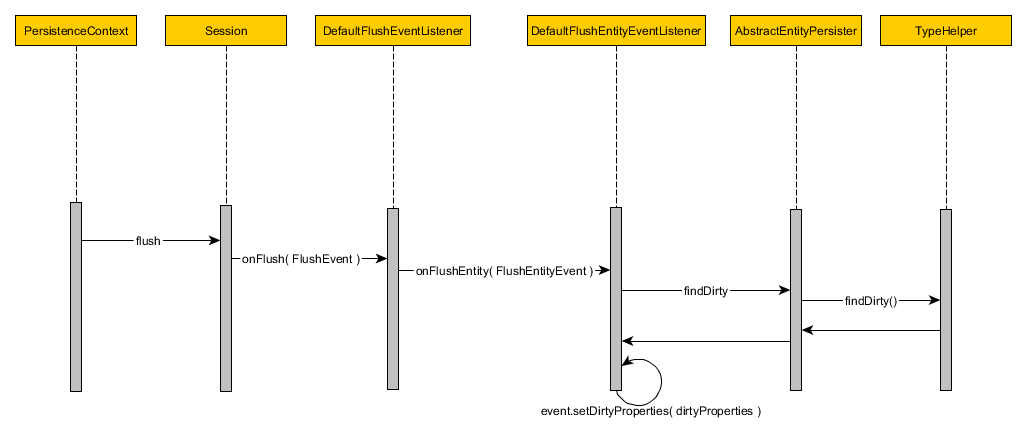
10000개 엔티티 중 1개만 변하는 상황이어도, Hibernate 는 모든 엔티티의 상태를 체크한다.
.flush() 과정에서 엔티티가 변했다면, SQL 쿼리문이 생성된다.
따라서 성능최적화를 위해 데이터를 단순히 읽기만 한다면 read-only 를 @Transactional 에 지정해주는게 좋다.
@DynamicUpdate
@DynamicUpdate 어노테이션을 사용해서 엔티티의 N가지 필드 중, 실제 변경이 이루어지는 필드만을 변경하도록 할 수 있다.
실제로 변경이 이루어진 컬럼만 추적하면 좋은거 아닌가? 무조건 써야겠네. 라는 생각이 들었다. 하지만 한번만 더 생각해보자. JPA 기술을 구현하는 구현체로 Hibernate 를 사용한다. 그리고 Hibernate 도 결국에는 DB 와 커넥션을 할 때, PreparedStatement, ResultSet 등을 사용해야한다.
3개의 필드를 가지고 있는 엔티티의 필드 중, name 을 UPDATE 하는 경우를 생각해보자. DB 에는 버퍼 캐시 히트율 이라는 것이 존재한다. (Buffer Cache Hit Ratio, BCHR)
다음과 같은 SQL 문을 필요한 시점에 바로 꺼내서 사용하기 위해 미리 저장해두는 것이다.
PreparedStatement prst = connection.prepareStatement(
"UPDATE product SET name = ?, price = ? WHERE id = ?"
);
prst.setString(1, "myProduct");
prst.setInt(2, 50000);
prst.setLong(3, 1);
이 때, @DynamicUpdate 어노테이션을 사용한다는 것은 전체 필드가 다 있는 쿼리문이 아니라 1개만을 집어넣는 쿼리문이 새롭게 생성되는 것이고, 이는 BCHR 을 떨어뜨린다.
또한 엔티티의 주소값만을 비교해서 변경 여부를 감지했던 상황과는 다르게, 모든 필드의 변경 여부를 확인해야한다. 필드 레벨까지 모두 뒤지는 로직을 타야한다.
그렇게 때문에 @DynamicUpdate 를 사용하는 대표적인 경우를 몇 가지 적어본다.
- 컬럼이 15-20개 정도로 많은 경우 (정해진 숫자는 아니고 주관적, 상황에 따라 달라짐)
- 테이블에 인덱스가 많은 경우
- DB 가 컬럼 락을 지원할 때
- DB 가 컬럼 비저닝을 지원할 때
- 특정 테이블에 동시성 이슈가 발생할 때
- A 라는 테이블에, 동시에 여러가지 트랜잭션이 들어와서 트랜잭션 경합이 발생하는 경우, 캐시된 SQL 문을 사용하면 하나의 트랜잭션만 실행되고 나머지는 롤백될 수 있다. 이때
@DynamicUpdate는 캐시된 값과는 다른 새로운 쿼리문을 생성하기 때문에 트랜잭션 경합 발생 시 활용할 수 있다.
flush
Persistence Context 에 있는 '변경 내용' 을 DB 에 반영한다.
'쓰기 지연 저장소' (= Transactional Write-Behind)
DB 에 데이터를 저장되는 시점은 서버에서 쿼리문을 전달하는 시점이다. 즉 쿼리문이 발생하지 않으면, DB 에 데이터는 들어가지 않는다.
flush 는 어떤 곳에 캐시 되어 있던 SQL 쿼리를 날리는 역할을 한다. 데이터가 쌓일 때까지 기다렸다가, 한번에 데이터를 DB 로 보낸다.
영속성 컨텍스트를 없애는 역할을 하지 않음을 기억해두자.
clear
Persistence Context 를 초기화하고, 해당하는 모든 엔티티를 준영속 상태로 만든다. 싹 비우고, 새롭게 만드는 것.
detatch
1차 캐시, 쓰기 지연 저장소 등 해당 엔티티를 관리하기 위해서 생성된 모든 캐시가 사라진다.
더 이상 Persistence Context 의 영향을 받지 않는 '준영속' 상태가 된다.
close
Persistence Context 를 종료시킨다.
merge
다시 합치는 방법도 당연히 있어야겠지?
쓰기 지연 저장소
Transactional Write-Behind
Cache
캐시된 데이터를 동기화하는 방법이 몇가지 있는데, JPA 는 그 중에서 Write-Behind Caching 을 사용한다. '한번에 모아서 보낸다'
DML 쿼리를 Enque 하여 Caching 해둔다.
commit
commit 메서드가 호출되면 쓰기 지연 저장소에 있던 모든 쿼리문이 DB 로 전달된다. commit 메서드 내에서 flush 메서드를 호출한다.
flush 는 쓰기지연 저장소에 있는 쿼리를 DB 에 전송하고, commit 은 쿼리문의 내용을 실제로 적용시키는 메서드이다.
배치(batch) 작업이라고 볼 수 있는데, 환경설정에서 그 크기를 조절할 수 있다.
spring.jpa.properties.hibernate.jdbc.batch_size=${NUMBER}
