개요
회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 통칭한다.
머신러닝 회귀 예측의 핵심은 주어진 피처와 결정 값 데이터 기반에서 학습을 통해 최적의 회귀 계수(W)를 찾아내는 것이다.
Y: 종속변수
X1,X2,X3,X4,...,Xn: 독립변수
W1,W2,W3,W4,...,Wn: 회귀계수(Regression coefficients)
머신러닝의 회귀 예측의 핵심
주어진 feature와 결정 값 데이터 기반에서 학습을 통해 최적의 회귀 계수를 찾아내는 것이다.
유형
가장 중요한 것은 회귀 계수이다. 선형 회귀가 정형 데이터일 경우, 비선형 회귀보다 예측 성능이 좋다. 선형으로 계수를 예측함에도 불구하고 비선형으로 되어 있는 것보다 예측성능이 좋다.
선형 회귀는 말 그대로 선형 계수가 선형적으로 결합되어 있는 것이다. 회귀 계수가 어떻게 결합이 되어있는지를 의미한다.
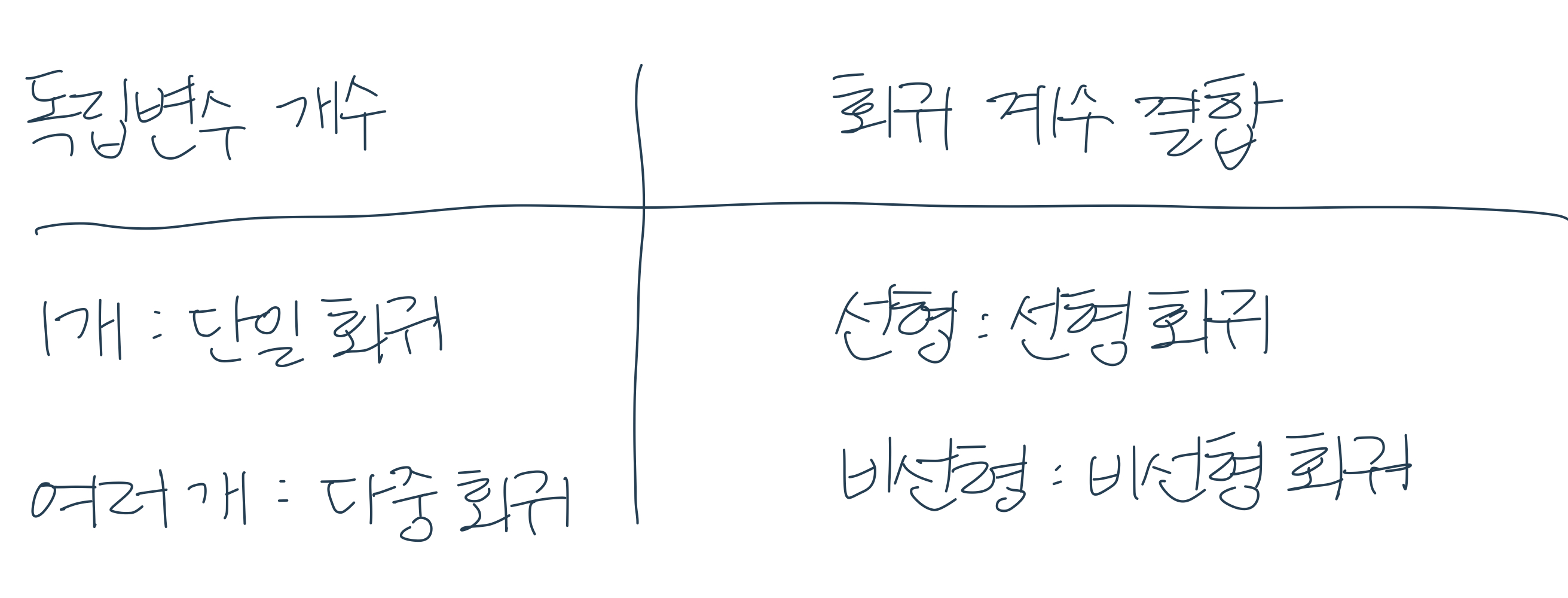
다중회귀가 더 많이 사용된다.
분류와 회귀
분류와 회귀는 많이 유사하다. 분류는 category값(이산값)을 반환한다. regression은 숫자값(연속값)을 반환한다.
선형 회귀의 종류
- 일반 선형 회귀: 예측값과 실제값의 RSS(Residual Sum of Squares)를 최소화할 수 있도록 회귀 계수를 최적화하며, 규제(Regularization)을 적용하지 않은 모델이다.
- 릿지(Ridge): 릿지 회귀는 선형 회귀에 L2규제를 추가한 회귀 모델이다.
- 라쏘(Lasso): 라쏘 회귀는 선형 회귀에 L1규제를 적용한 방식이다.
- 엘라스틱 넷(ElasticNet): L2, L1규제를 함께 결합한 모델이다.
- 로지스틱 회귀(Logistic Regression): 로지스틱 회귀는 회귀라는 이름이 붙어 있지만, 사실은 분류에 사용되는 선형 모델이다.
Simple Regression
잔차: 오류 값을 회귀에선 잔차라고 한다.
최적의 회귀 모델을 만든다는 것, 그것은
1. 전체 데이터의 잔차(오류값) 합이 최소가 되는 모델을 만든다는 의미이다.
2. 동시에 오류값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는다는 의미이다.
RSS
미분 등의 계산을 편리하게 하기 위해 RSS방식으로 오류 합을 구한다.
오류 값의 제곱을 구해서 더하는 방식이다.
RSS는 회귀식의 독립변수 X, 종속변수Y가 중심 변수가 아니라 w변수(회귀 계수)가 중심 변수임을 인지하는 것이 매우 중요하다.
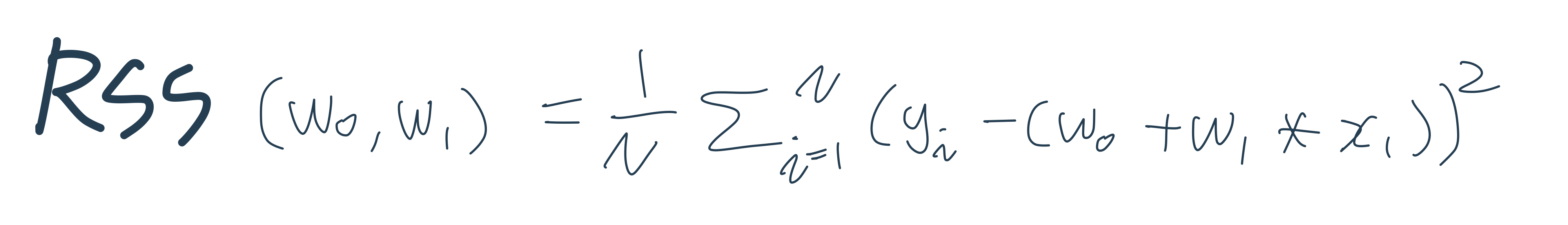
회귀의 비용함수(Cost function)
회귀에서 RSS는 비용이며 w변수(회귀 계수)로 구성되는 RSS를 비용 함수라고 한다.
Gradient Descent
많은 w파라미터가 있는 경우에 경사 하강법은 보다 간단하고 직관적인 비용함수 최소화 솔루션을 제공한다.
점진적으로 반복적 계산을 통해 w파라미터 값을 계속 업데이트 한다.
오류값이 최소가 되는 w파라미터 값을 구한다.
경사 하강법의 핵심은 어떻게 오류가 작아지는 방향으로 w값을 보정할 수 있을지이다.
미분
미분은 증가 또는 감소의 방향성을 나타낸다.
Chain Rule
합성함수의 미분이다.
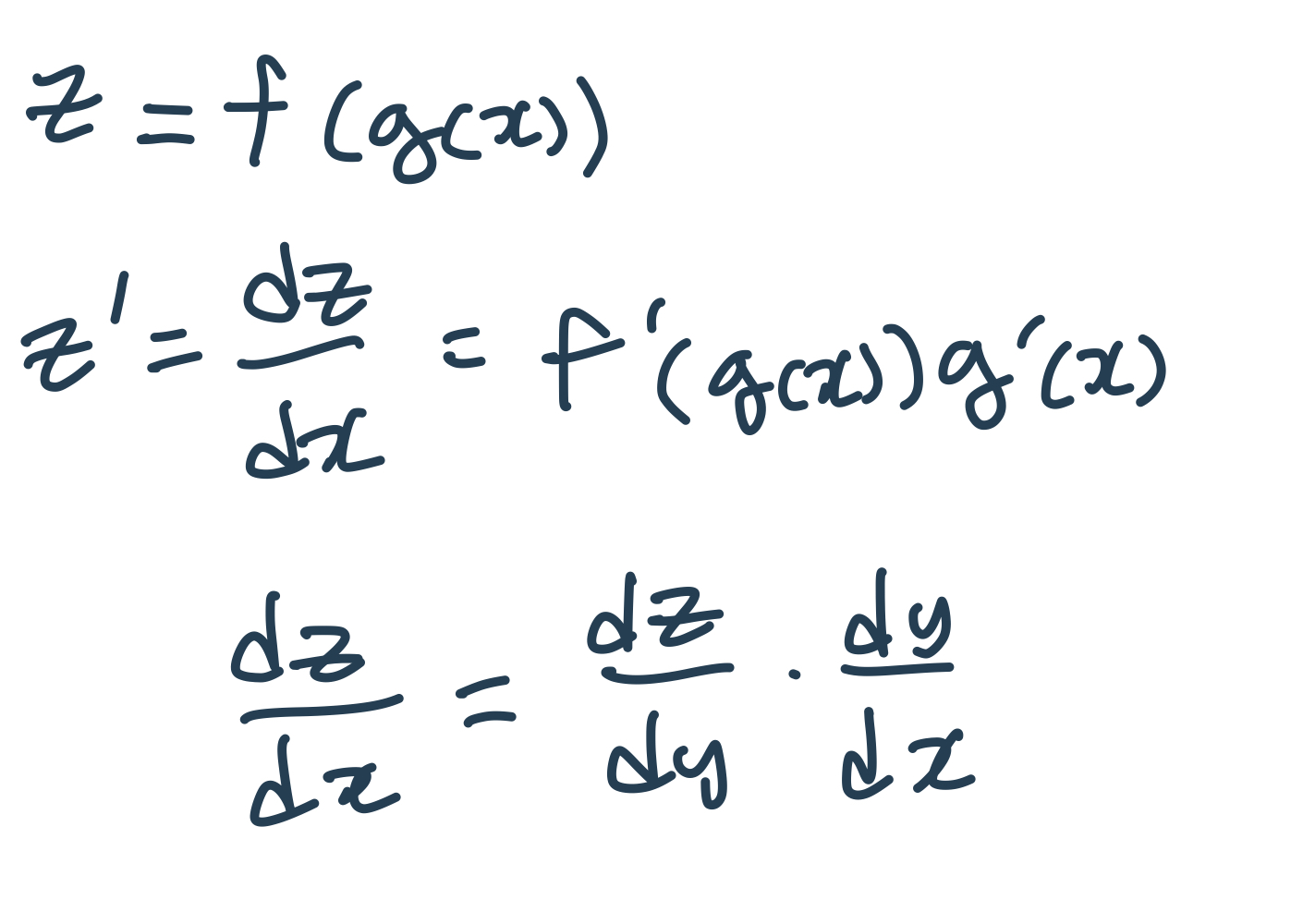
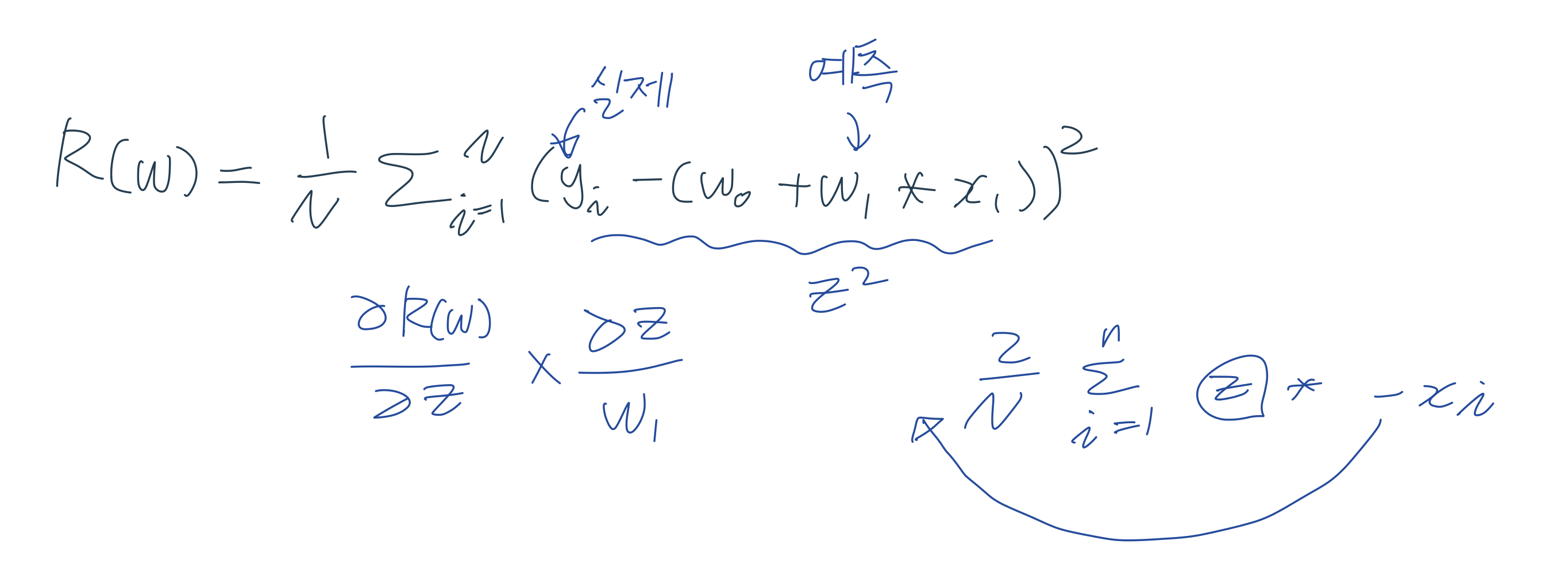
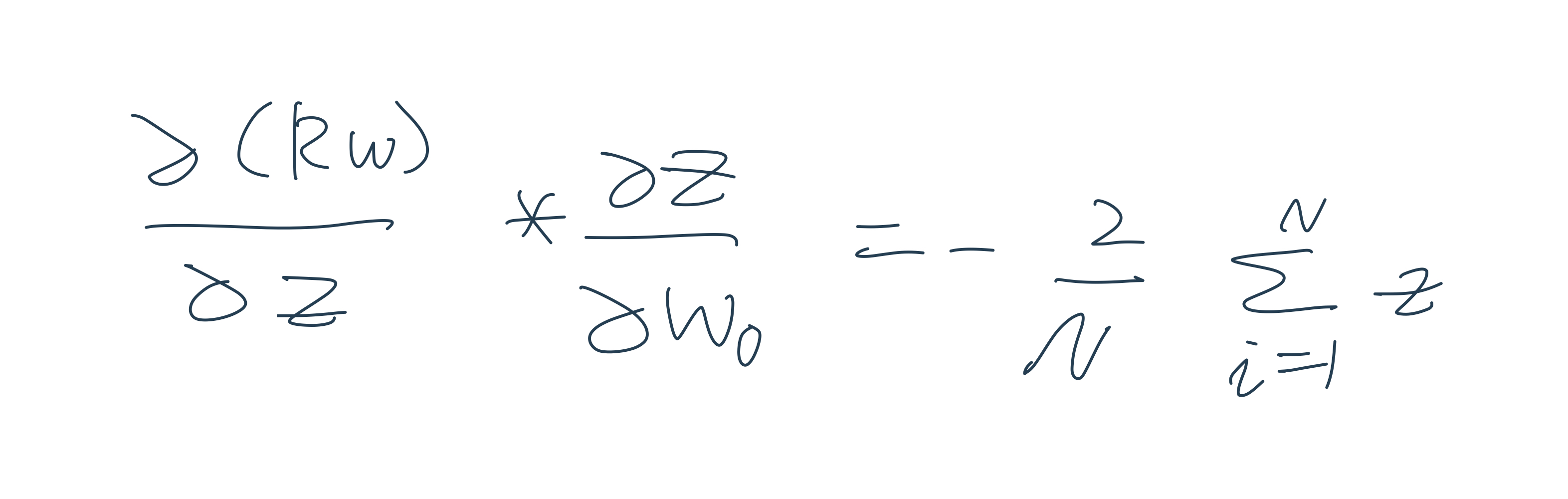
LinearRegression
LinearRegression클래스
: 예측값과 실제값의 RSS(Residual Sum of Squares)를 최소화하는 OLS(Ordinary Least Squares)추정 방식으로 구현한 클래스이다.
LinearRegression클래스는 fit()메서드로 x,y 배열을 입력받으면 회귀 계수(Coefficients)인 W를 coef_속성에 저장한다.
intercept: 절편
class sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False,
copy_X=True,n_jobs=1)절편을 intercept라고도 이야기하고 bias라고도 이야기한다.
입력 파라미터
fit_intercept: 불린 값이다. 디폴트는 True이다. 절편 값을 계산할 것인지 아닌지를 결정한다. False로 지정하면 파라미터 값이 0으로 지정된다. (디폴트 값으로 놔두는게 좋을지도?)
normalize: 불린 값으로 디폴트는 False이다. fit_intercept가 False인 경우에는 이 파라미터가 무시된다. 만일 True이면 회귀를 수행하기 전 입력 데이터세트를 정규화한다.
속성
coef: fit()메서드를 수행했을 때 회귀 계수가 배열 형태로 저장하는 속성이다. Shape는 (Target값 개수, 피처 개수이다.)
intercept: intercept값이다.
다중 공선성
선형 회귀는 입력 피처의 독립성에 많은 영향을 받는다.
피처간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 매우 민감해진다.
이런 현상을 multi-collinearity문제라고 한다.
상관관계가 높은 피처가 많은 경우 독립적인 중요한 피처만 남기고 제거하거나 규제를 적용한다.
회귀 평가 지표
MAE, RMSE, RMSLE를 많이 쓴다.
MAE
: 실제값-예측값의 절댓값을 평균함
MSE
: MAE에서 실제값예측값차이를 제곱
MSLE
: 로그 -> 결정값 클수록 오류값도 커지기 때문에..
RMSE
: MSE에 루트를 씌운 것이 RMSE이다.
RMSLE
: RMSE에 로그를 적용한 것이다.
MAE와 RMSE의 비교
MAE에 비해 RMSE는 큰 오류값에 상대적인 페널티를 더 부여한다.
다섯개의 오류값(실제값과 예측값의 차이) 10,20,10,10,100과 같이 다른 값에 비해 큰 오류값이 존재하는 경우 RMSE는 전반적으로 MAE보다 높다.
MAE = (10+20+10+10+100)/5 = 30이고 RMSE는 루트씌워서 √(100+400+100+100+10000)/5=√2140=46.26 상대적으로 큰 오류값이 있을 때 이에 대한 페널티를 더 부과한다.
