kaggle link
Kaggle에서 제공하는 "Anime Recommendations Database" 데이터셋을 사용하여 나의 히어로 아카데미아와 헌터X헌터만 골라서 서버에 다운로드 해봤습니다.
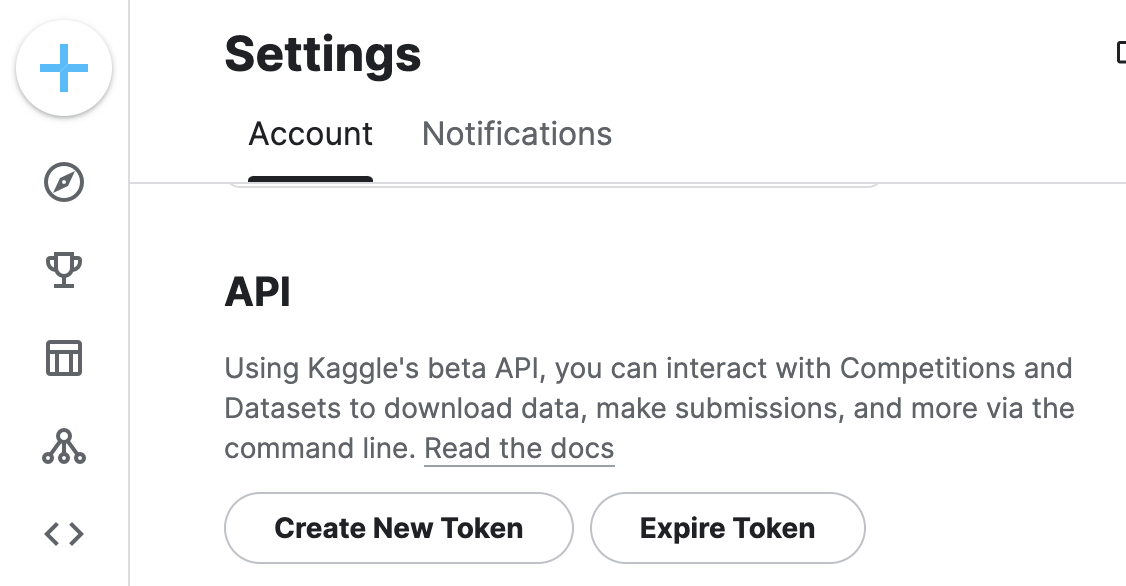
kaggle프로필 클릭 > settings > Account> create New Token
이렇게하면 kaggle.json 파일이 다운로드 됩니다.
import os
import requests
import pandas as pd
from bs4 import BeautifulSoup
# Kaggle 데이터셋 로드
anime = pd.read_csv('./dataset/anime.csv')
# My Hero Academia와 Hunter x Hunter 데이터 필터링
mha = anime[anime['name'].str.contains('My Hero Academia', case=False)]
hxh = anime[anime['name'].str.contains('Hunter x Hunter', case=False)]
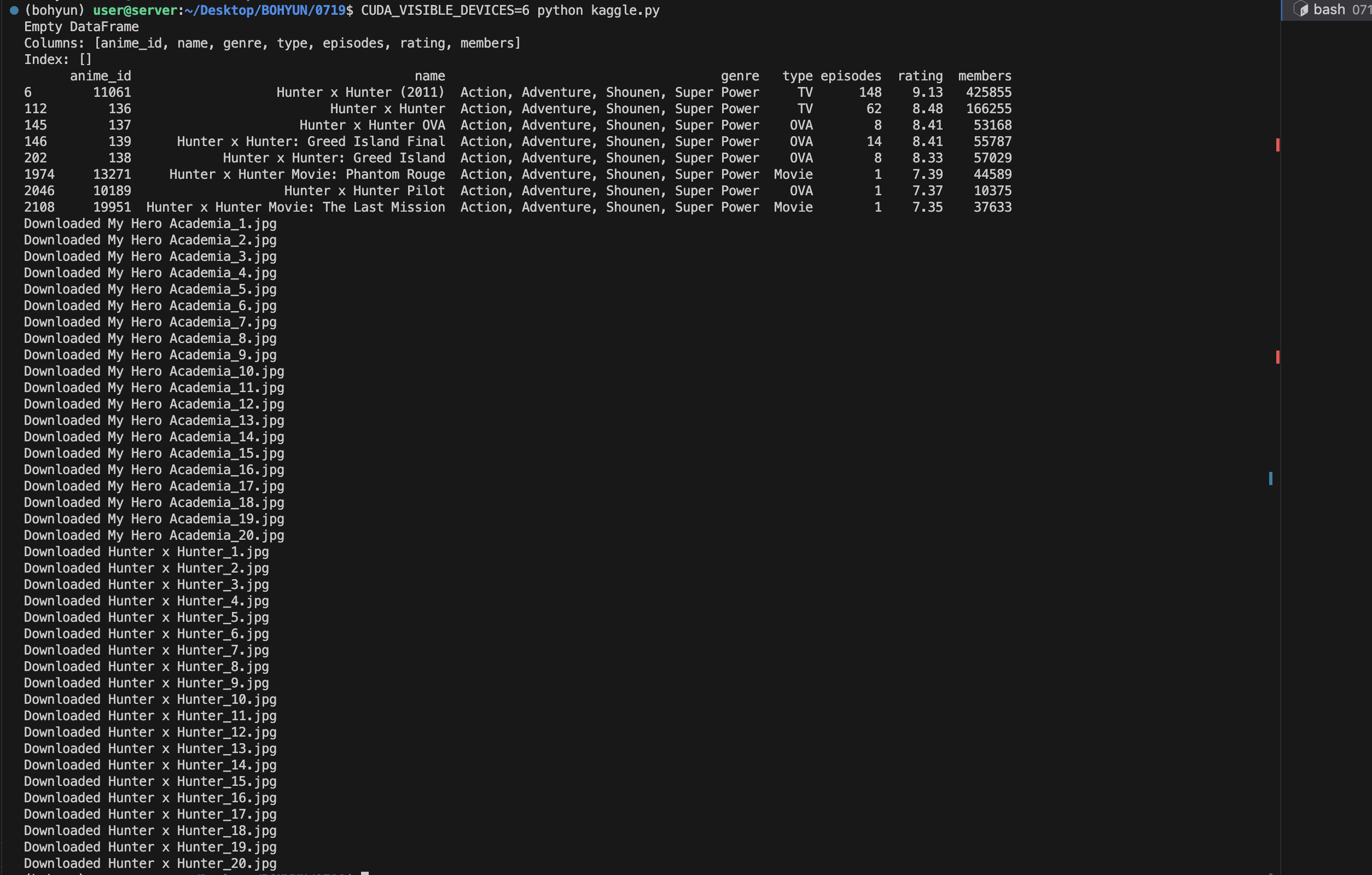
print(mha)
print(hxh)
def download_images(query, folder_name, num_images=10):
if not os.path.exists(folder_name):
os.makedirs(folder_name)
search_url = f"https://www.google.com/search?q={query}&source=lnms&tbm=isch"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(search_url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all("img", limit=num_images + 1) # 첫 번째 이미지는 구글 로고일 수 있으므로 추가로 하나 더 가져옵니다.
for i, img_tag in enumerate(img_tags[1:num_images + 1], start=1): # 첫 번째 이미지를 건너뜁니다.
img_url = img_tag.get("src")
if not img_url.startswith('http'):
img_url = 'https:' + img_url # 상대 경로를 절대 경로로 변환
try:
img_data = requests.get(img_url).content
with open(os.path.join(folder_name, f"{query}_{i}.jpg"), 'wb') as handler:
handler.write(img_data)
print(f"Downloaded {query}_{i}.jpg")
except Exception as e:
print(f"Could not download {query}_{i}.jpg: {e}")
download_images('My Hero Academia', 'my_hero_academia', num_images=100)
download_images('Hunter x Hunter', 'hunter_x_hunter', num_images=100)최애 애니이자 7기 방영중인 히로아카를 불러올 수 있어서 흥미로웠지만, 데이터로 쓰기는 힘들 것 같다.
다음엔 직접 구글에서 확장 프로그램을 사용해서 내가 좋아하는 키스오브라이프 하늘이로 데이터셋을 만들어야겠다.

Fall in love with Computer Vision