torchvision 라이브러리를 사용하면 FashionMNIST 데이터셋을 간편하게 다운로드하고 사용할 수 있다.
라이브러리 설치
가상환경 bohyun에 torchvision을 설치합니다.
사용중인 서버 확인

nvidia-smi 명령어를 터미널에 입력해서 사용 중인 서버를 파악합니다.
FashionMNIST 데이터셋을 불러오기
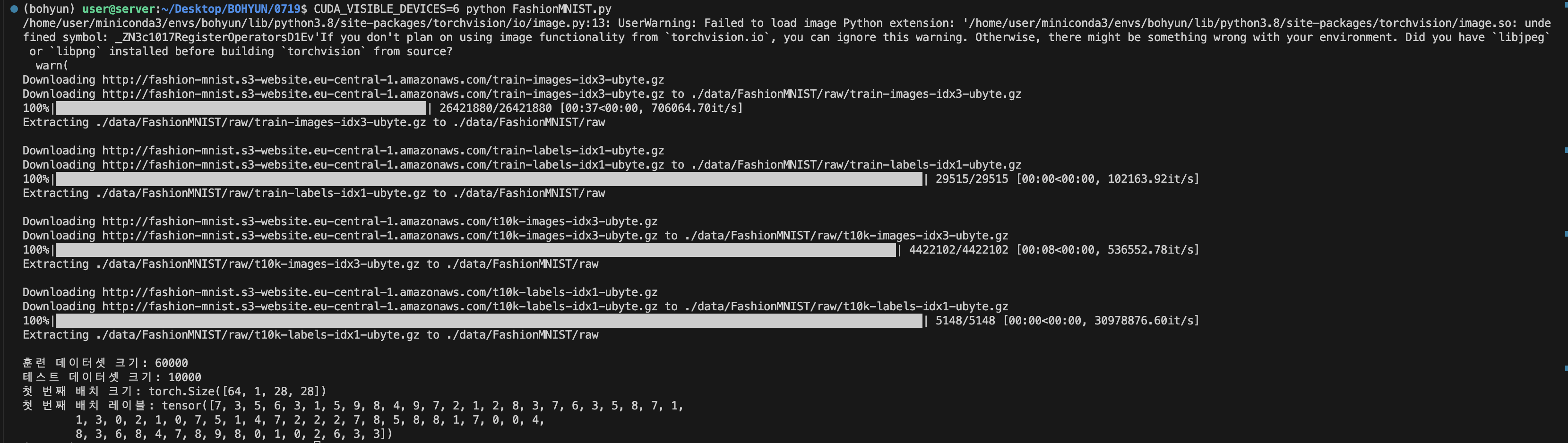
CUDA_VISIBLE_DEVICES=6 python FashionMNIST.py
차례대로 서버번호, 사용언어, 파일이름입니다.
터미널에 입력하면 됩니다.
6번 서버를 사용해서 FashionMNIST.py파일을 실행시켰습니다.

제가 설정한 경로에 data가 생성된 것을 확인할 수 있습니다.
그럼 이제 FashionMNIST.py의 코드를 살펴보겠습니다.
FashionMNIST.py
전체 코드
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
print(f'훈련 데이터셋 크기: {len(train_loader.dataset)}')
print(f'테스트 데이터셋 크기: {len(test_loader.dataset)}')
examples = enumerate(train_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(f'첫 번째 배치 크기: {example_data.shape}')
print(f'첫 번째 배치 레이블: {example_targets}')- 전처리
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])transforms.ToTensor()데이터를 텐서로 변환한다.
transforms.Normalize((0.5,), (0.5,)) 평균 0.5, 표준편차 0.5인 정규화를 수행한다. FashionMNIST 데이터셋은 흑백 이미지이다. 따라서 평균과 표준편차를 단일 값으로 설정하면 된다.
cf) RGB 이미지
RGB 이미지는 세 개의 채널(R, G, B)을 가지므로, 각 채널별로 평균과 표준편차를 각각 설정해야한다.
- RGB 이미지 정규화
transforms.Normalize((mean_R, mean_G, mean_B), (std_R, std_G, std_B))- 흑백 이미지 정규화
transforms.Normalize((mean,), (std,))- 데이터셋 불러오기
train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)datasets.FashionMNIST로train과test데이터셋을 불러온다.root는 데이터를 저장할 경로이다. 나는./data로 설정해서 현재 작업 디렉토리./안에data라는 폴더를 생성시켰다.download=True로 설정하여 데이터가 없을 경우 자동으로 다운로드한다.
- DataLoader로 배치 단위로 데이터를 로드하기
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)batch_size=64: 각 배치의 크기가 64이다.
shuffle=True: 데이터를 무작위로 섞는다.

Fall in love with Computer Vision