
(썸네일 이미지는 Ollama github에서 모셔왔습니다)
로컬에서 llm을 사용할 수 있는 방법으로 Ollama가 유명합니다. 또한 우리는 로컬에서 Streamlit을 통해 손쉽게 웹페이지를 구현할 수 있습니다. 그렇다면 이런 생각도 듭니다. 로컬에서 chatGPT와 같이 llm을 사용하는 챗봇 페이지를 만들 수 있지 않을까요? 사실 OpenAI의 chatGPT가 무료로 지원되고 있는 상황에서 굳이 로컬 페이지를 만들 이유는 없긴 합니다. 하지만, 희박한 확률이지만 인터넷이 안 되는 오지로 여행을 가서 llm을 사용하고 싶을 수도 있으니까요(?) 사실상 Ollama 실습과 Streamlit 실습을 위해, 그리고 이를 기록하는 글을 써볼까 합니다.
Ollama
Ollama란?
Ollama에 대해 공식적으로 보여주는 설명은 단 한 줄이 끝이었습니다.
Get up and running with large language models.
즉, 몇 가지 llm 모델을 손쉽게 로컬에서 실행할 수 있게 도와주는 툴이라고 보면 될 것 같습니다. Ollama를 설치하게 되면 llama 일부를 포함해 Ollama에서 지원하는 몇 가지 모델들을 이용하고 커스터마이징할 수 있게 됩니다. (지원 모델: https://ollama.com/search)
Ollama 설치 (macOS 기준)
먼저 Ollama 홈페이지를 들어가면 다운로드 버튼이 보입니다. 여기에서 자신의 OS에 맞는 Ollama를 설치합니다. 저는 macOS 기준으로 설치해보겠습니다.
이런 창이 뜨면서 Ollama를 설치하게 됩니다. Ollama 설치는 매우 쉽고 귀엽습니다.
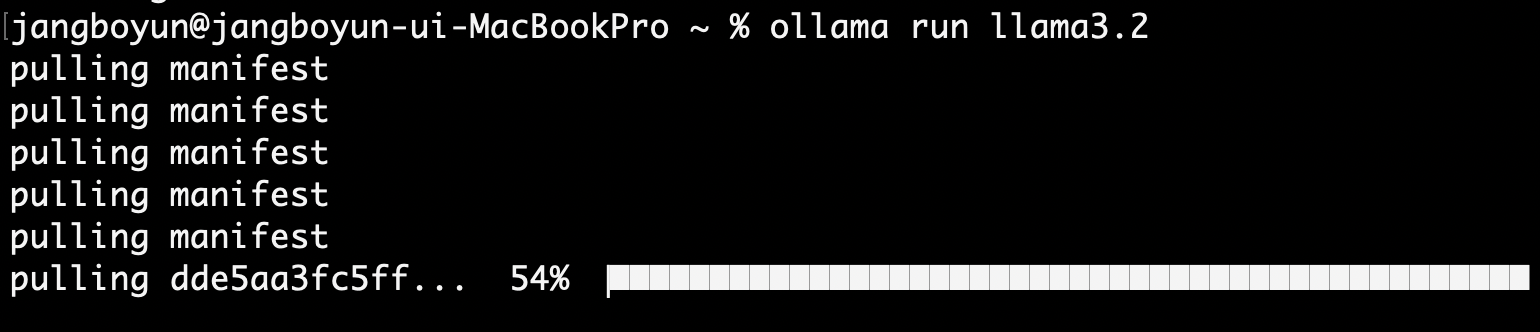
설치 시에 테스트를 위해 llama3.2 모델을 사용하는 커맨드가 나옵니다.
ollama run llama3.2그대로 실행하면 먼저 모델을 가져오게 되며
커맨드 메시지를 통해 모델을 이용할 수 있다면 이제 Ollama를 사용할 수 있게 되었습니다.

다음 단계를 위해 아쉽지만 /bye 명령어로 귀여운 라마와의 대화를 나와봅시다.
Langchain으로 Ollama 사용하기
커맨드 명령어를 통해 Ollama를 사용할 수도 있지만, 우리의 목적은 Streamlit과 연동시키는 것이다보니 파이썬에서 Ollama를 사용할 수 있게 해야 합니다. Langchain을 이용하면 쉽게 Ollama를 파이썬 코드로 실행시킬 수 있습니다.
먼저 langchain과 langchain_community를 설치합니다.
pip3 install langchain langchain_community아래와 같은 간단한 langchain 코드를 작성해봅시다. 모델은 다른 모델을 이용해도 되지만, 앞서 Ollama 설치 시에 llama3.2:latest를 가져왔으니 그대로 이용해보도록 합시다.
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# Ollama 모델을 불러옵니다.
llm = ChatOllama(model="llama3.2:latest")
# 프롬프트
prompt = ChatPromptTemplate.from_template("{topic} is cute")
# 체인 생성
chain = prompt | llm | StrOutputParser()
# 간결성을 위해 응답은 터미널에 출력됩니다.
answer = chain.invoke({"topic": "lama"})
print(answer)파이썬 코드를 실행하면 아래와 같이 모델의 답변이 나오게 됩니다.

Streamlit
Streamlit이란? + 설치하기
간단히 말하면, 파이썬으로 간단하게 프론트를 짤 수 있는 프레임워크입니다. Streamlit에 대한 자세한 설명과 설치 방법은 아래 블로그에 설명해두었으니 이 글에서는 생략하도록 하겠습니다.
Streamlit에 대해 작성했던 글: Streamlit 시작하기 (급하게 프론트를 짜야 할 때)
Ollama 챗봇페이지 만들기
Ollama와 Streamlit을 사용할 준비가 되었다면 이제 우리가 원하는 챗봇 페이지를 만들어봅시다.
GPT의 도움을 받아 다음과 같이 메시지 입력이 가능한 streamlit 페이지를 구성했습니다.
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import streamlit as st
def run_ollama(message):
llm = ChatOllama(model="llama3.2:latest")
prompt = ChatPromptTemplate.from_template("{message}")
chain = prompt | llm | StrOutputParser()
answer = chain.invoke({"message": message})
return answer
def main():
st.title("My Local LLM")
if 'history' not in st.session_state:
st.session_state.history = []
user_message = st.text_input("메시지를 입력하세요:")
if st.button("입력"):
if user_message:
response = run_ollama(user_message)
st.session_state.history.append(("User", user_message))
st.session_state.history.append(("Bot", response))
st.session_state.user_input = "" # Optionally clear the input
st.markdown("""
<style>
.user-message {
background-color: #dcf8c6;
border-radius: 10px;
padding: 10px;
margin: 5px;
text-align: right;
}
.bot-message {
background-color: #dcf8c6;
border-radius: 10px;
padding: 10px;
margin: 5px;
text-align: left;
}
</style>
""", unsafe_allow_html=True)
if st.session_state.history:
for speaker, message in st.session_state.history:
if speaker == "User":
st.markdown(f'<div class="user-message"><strong>{speaker}:</strong> {message}</div>', unsafe_allow_html=True)
else:
st.markdown(f'<div class="bot-message"><strong>{speaker}:</strong> {message}</div>', unsafe_allow_html=True)
if __name__ == '__main__':
main()이제 위의 파이썬 코드를 실행시키면
streamlit run run.py --server.port 20000http://localhost:20000/ 에서 채팅 페이지가 실행되고 있는 것을 확인할 수 있습니다.
빠르게(+대충) 만들었기 때문에 몇 가지 불편한 점들은 있으나 (엔터키로 버튼이 안 된다든지...페이지가 못생겼다든지...) 챗봇 실행이 가능한 것을 확인할 수 있습니다.
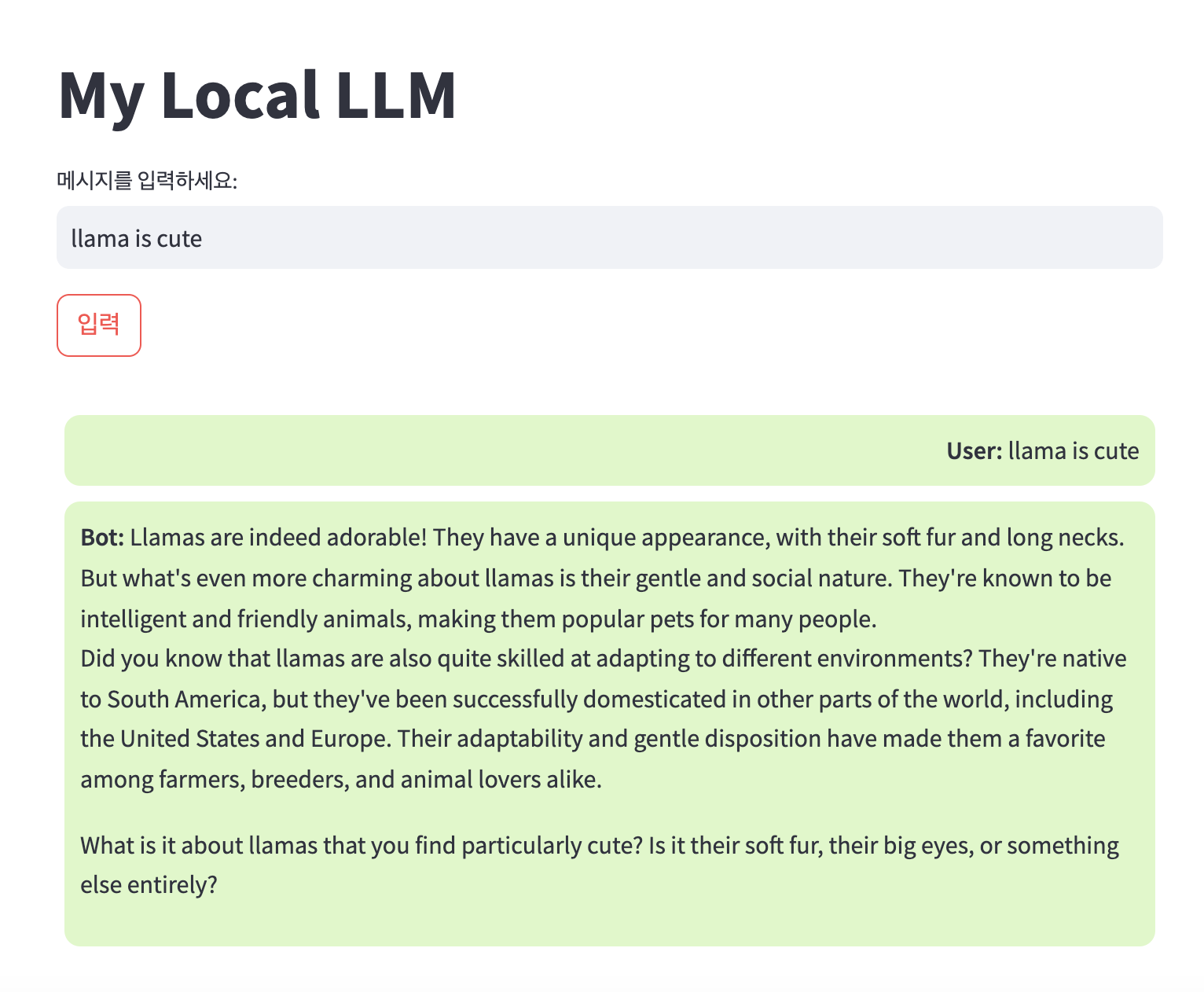
메시지를 여러 개 남기고 이어서 볼 수도 있습니다.

마치며
실행을 해보며 느낀 점은, 라마는 귀엽다...가 아니라 조금 더 다듬는다면 응용할 수 있는 범위가 많을 것 같다는 점입니다. UI를 더 다듬을 수도 있고, 멀티턴으로는 안 만들었는데 멀티턴 기능도 구현해둘 수 있을 것입니다. 한국어 성능이 좋은 다른 모델도 사용할 수 있을 것입니다. 또한 찾아보니 PDF를 주고 해당 PDF 데이터를 이용해 RAG를 구현한 예시도 볼 수 있었습니다. (https://medium.com/@vndee.huynh/build-your-own-rag-and-run-it-locally-langchain-ollama-streamlit-181d42805895)
그리고 추가하자면 사실 ollama가 아니라 openAI, huggingface 등에서 모델을 가져와서 구현할 수도 있을 것입니다. 그럼에도 ollama로 테스트를 해본 건, 무료로 간단하게 테스트해볼 수 있으니까요. (그리고 귀여우니까요.) 직접 테스트를 해 보면서 실습에 들인 시간보다 깃허브에 코드 올리려다가 access 문제를 해결하는 데 시간을 더 잡아먹었다는 걸 생각해보면 충분히 간단하게 테스트해볼 수 있을 것이라고 봅니다.
