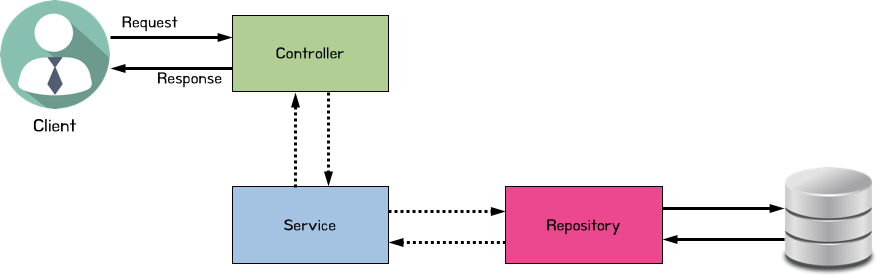
3 Layer Architecture
1. 3 Layer Architecture (3계층)
메모장 프로젝트 문제점
- 한 Controller에서 모든 기능처리
- 코드 이해 어려움 / 코드 추가, 변경 요청에 따라 변경하기 불편함
- Controller / Service / Repository로 나누기 (3계층)
2. 역할 분리
- Controller
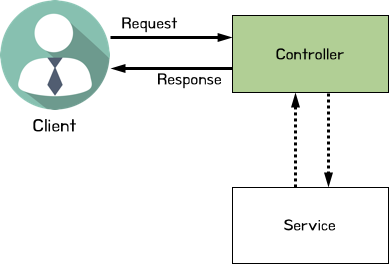
- Client의 Request 받기
- Request에 대한 로직 처리는 Service에게 넘기기
- Service에서 처리한 로직에 대한 결과를 Client에게 Response
- Service

- 사용자의 Request를 처리 →
비즈니스 로직 - DB 저장 및 조회는 Repository에게 넘기기
- 사용자의 Request를 처리 →
- Repository

- DB 관리 (연결, 해제, 자원 관리)
- DB CRUD 작업
IoC와 DI
3. IoC(제어의 역전), DI(의존성 주입)
Ioc(Inversion of Control)
IoC는 설계 원칙,
+ 소프트웨어 프로그래밍에서 개발자가 모든 것을 제어하는 것과 반대로,
+ 개발의 편의성을 위해 사용하는 프레임워크의 사용을 위해 프레임워크가 정의한 규약을 지키게 되는 것
DI (Dependency Injection)
DI는 디자인 패턴, 의존 관계 주입
+ 장점
1. 의존성 줄이기 (느슨한 결합)
2. 재사용성 증가 (다른 클래스에서 재사용)
3. 테스트 용이
4. 가독성 상승
=> 즉, 'DI 디자인 패턴을 사용하여 IoC 설계 원칙을 구현하고 있다'
의존성
- 강하게 결합된 두 객체 예시
public class Consumer {
void eat() {
Chicken chicken = new Chicken();
chicken.eat();
}
public static void main(String[] args) {
Consumer consumer = new Consumer();
consumer.eat();
}
}
class Chicken {
public void eat() {
System.out.println("치킨을 먹는다.");
}
}- 느슨하게 결합된 두 객체 (Loosely Coupling) 예시
public class Consumer {
void eat(Food food) {
food.eat();
}
public static void main(String[] args) {
Consumer consumer = new Consumer();
consumer.eat(new Chicken());
consumer.eat(new Pizza());
}
}
interface Food {
void eat();
}
class Chicken implements Food{
@Override
public void eat() {
System.out.println("치킨을 먹는다.");
}
}
class Pizza implements Food{
@Override
public void eat() {
System.out.println("피자를 먹는다.");
}
}다시 보는 인터페이스와 메서드 오버라이딩
"오버라이딩된 메서드가 항상 우선권을 갖는다"
→ interface의 다형성 원리를 통해 코드 수정 및 확장성 증가
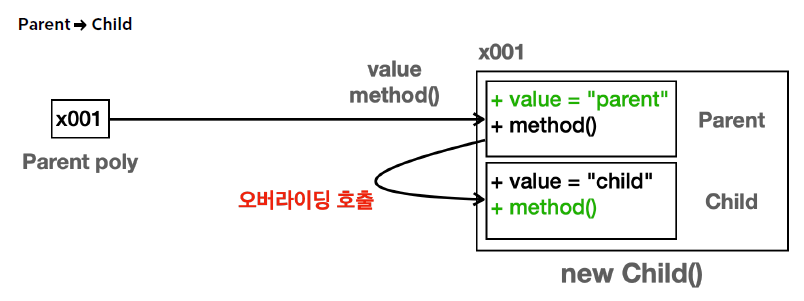
주입 (Injection)
한 객체가 필요로 하는 다른 객체를 전달하는 것
1. 필드 직접 주입
2. 메서드 주입 (setter)
3. 생성자 주입
4. 메모장 프로젝트의 IoC & DI
- 객체 중복 생성 코드 바꾸기
// Before 메서드마다 MemoRepository를 계속 생성
public class MemoService {
private final JdbcTemplate jdbcTemplate;
public MemoService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public MemoResponseDto createMemo(MemoRequestDto requestDto) {
// DB 저장
MemoRepository memoRepository = new MemoRepository(jdbcTemplate);
...
}
}
// After 생성자를 통해 하나만 생성해서 사용
public class MemoService {
// 멤버 변수 선언
private final MemoRepository memoRepository;
// 생성자: MemoService(JdbcTemplate jdbcTemplate)가 생성될 때 호출됨
public MemoService(JdbcTemplate jdbcTemplate) {
// 멤버 변수 생성
this.memoRepository = new MemoRepository(jdbcTemplate);
}
public MemoResponseDto createMemo(MemoRequestDto requestDto) {
(MemoRepository memoRepository = new MemoRepository(jdbcTemplate);)
Memo memo = new Memo(requestDto);
...
}
}- 강한 결합 -> 느슨한 결합
- 강한 결합의 경우, Controller가 직접 Service를 생성
- Controller가 여러 개 있을 경우, Service도 그만큼 여러 개 생성
- 동시에 그만큼 Repository도 여러 개 생성
// Before
public MemoController(JdbcTemplate jdbcTemplate) {
this.memoService = new MemoService(jdbcTemplate);
}
...
public MemoService(JdbcTemplate jdbcTemplate) {
this.memoRepository = new MemoRepository(jdbcTemplate);
}
// After
public MemoController(MemoService memoService) {
this.memoService = memoService;
}
...
public MemoService(MemoRepository memoRepository) {
this.memoRepository = memoRepository;
}- 변환 결과
그렇다면, 생성자에 주입받을 객체는 어디서, 어떻게 생성?
+ Repository의 생성자에서 JdbcTemplate는 라이브러리에 존재하므로 생성 가능
+ Service의 생성자에서 Repository는 어떻게 생성되어야 하는가?
+ Controller의 생성자에서 Service는 어떻게 생성되어야 하는가
5. IoC Container와 Bean
Spring IoC 컨테이너
Spring 프레임워크에서 필요한 객체를 생성하고 관리하는 역할을 수행
→ Spring 프레임워크가 생성한 객체 →Bean
→Bean을 모아둔 컨테이너 →Spring IoC Container
Bean 등록
@Component :
Bean으로 등록하려는 클래스에 설정
→ Spring 서버 실행시, Component Scan을 통해 어노테이션 확인 후, Spring Container에 등록
Bean 사용
@Autowired : 생성된 객체를 주입하는 곳 (필드, setter, 생성자...)
→ Spring이 관리하는 클래스 내에서만 사용 가능
- 3계층 어노테이션
- @Service
- @Repository
- @Controller / @RestController => Controller의 경우, DispatcherServlet이 Mapping을 통해 데이터를 이동시키고, 메서드를 실행할 때, 내부적으로 객체를 생성한다.
생성자로 주입하는 이유 : 객체의 불변성
cf) 필드에 final을 선언하는 이유? final은 객체 생성과 동시에 초기화를 해야하므로,,
생성자 주입만 가능하도록
Lombok을 통한 주입
클래스에 @RequiredArgsConstructor 달기 => 필드는 final
Autowired가 아닌 수동으로 주입하기
// ApplicationContext => BeanFactory의 상속을 받아 기능을 확장한 컨테이너 // 스프링 컨테이너의 일종 // 컨테이너에서 직접 가져와서 주입하기 public MemoService(ApplicationContext context){ // 1. Bean 이름을 통해 가져오기 MemoRepository memoRepository = (MemoRepository)context.getBean("memoRepository"); this.memoRepository = memoRepository; // 2. 'Bean' 클래스 형식으로 가져오기 MemoRepository memoRepository = context.getBean(MemoRepository.class); this.memoRepository = memoRepository; }
JPA Core
6. JPA
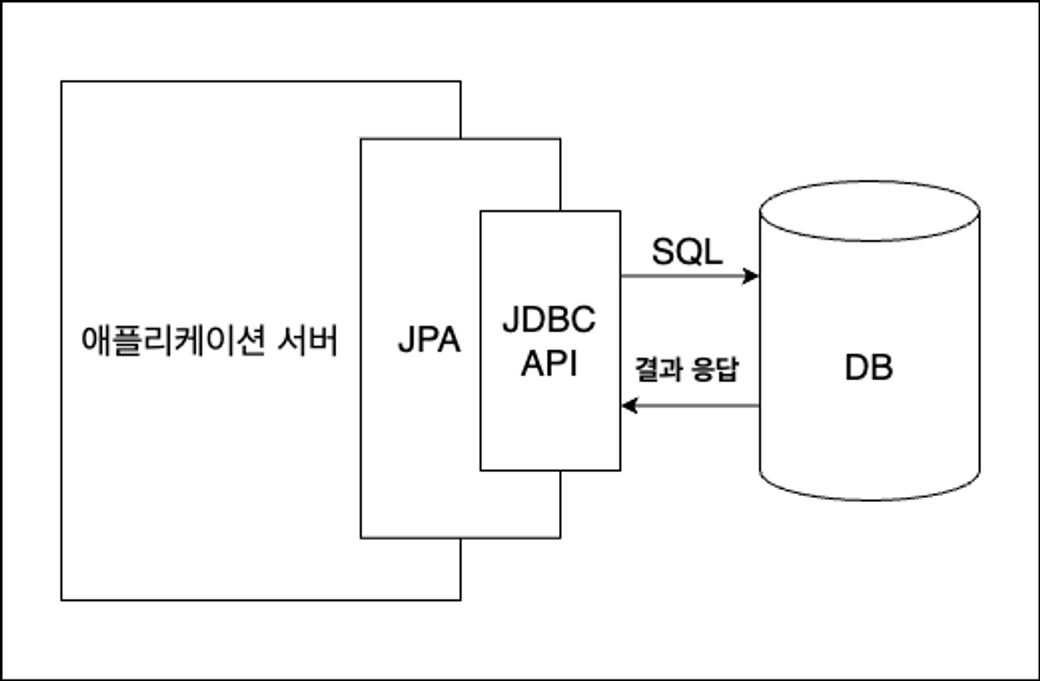
DB 직접 다루기 (순수 JDBC / JdbcTemplate)
객체(Table)의 필드(row)가 변경될 경우, SQL 문장을 바꾸는 작업 多
→ SQL 의존적
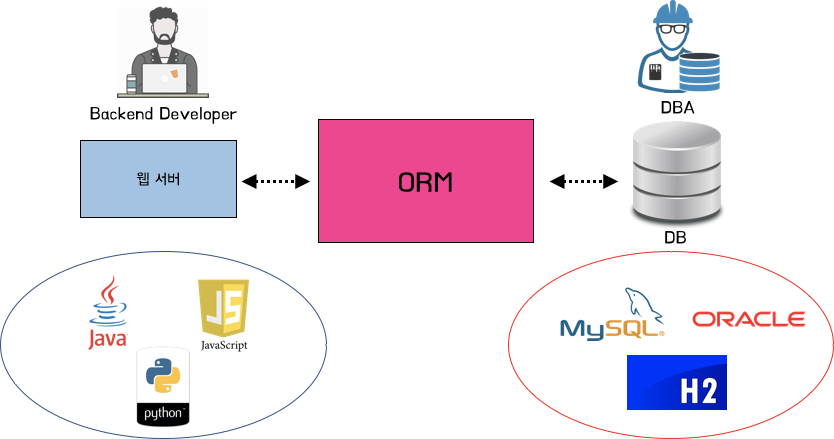
ORM (Object Relational Mapping)
ORM은 객체 관계형 맵핑을 의미 → 기술적 용어
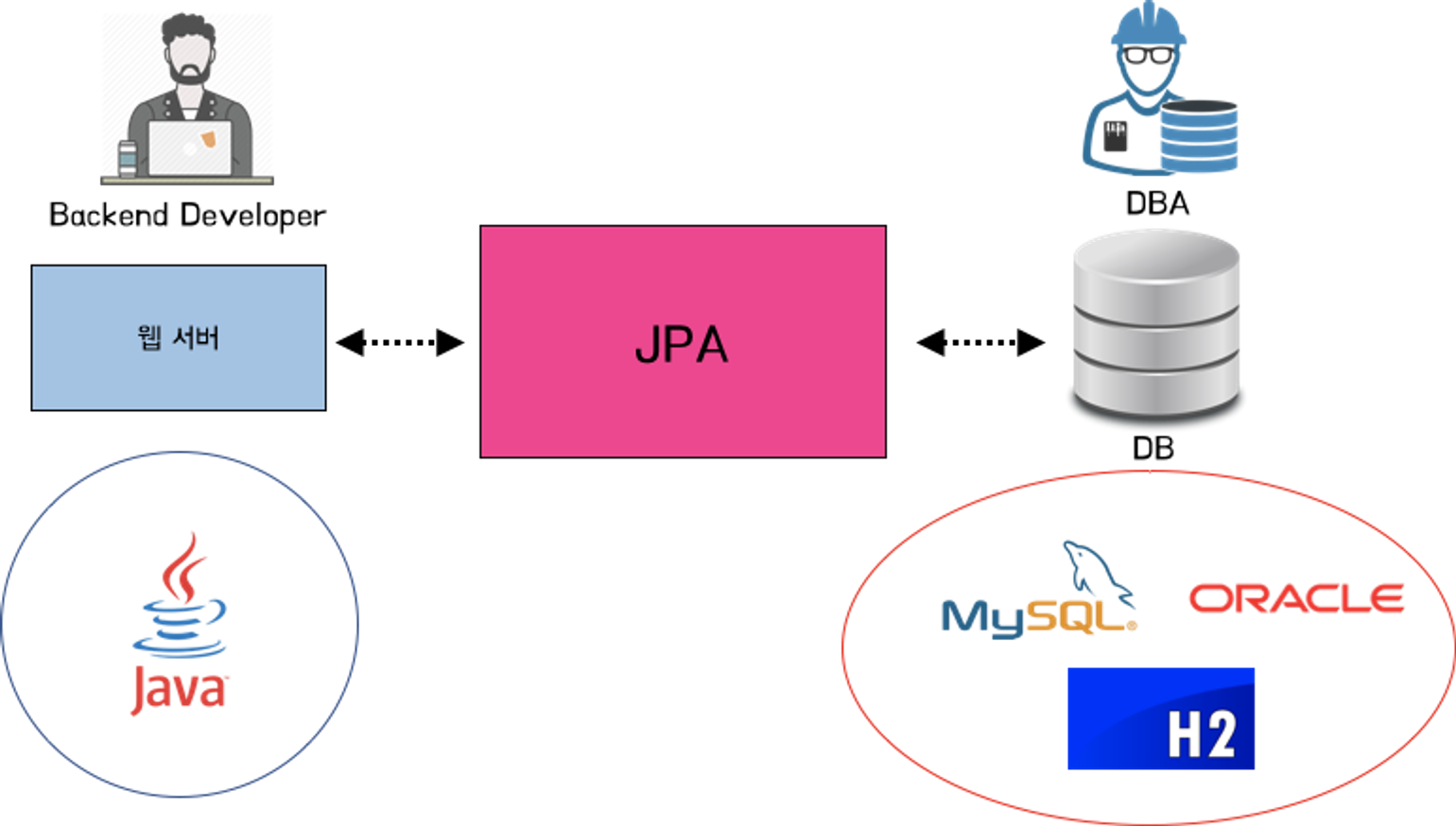
JPA (Java Persistence API)
JPA는 ORM 기술에 대한 Java의 표준 명세(Interface)
- JPA는 애플리케이션 서버와 JDBC 사이에서 동작
- DB 연결 과정에 대한 코드 없이, DB와 연결 가능
- 객체를 통해 DB를 다루기 때문에, SQL 작성이 적으며 쉽게 DB 작업 가능
- JPA(interface)를 구현한 여러 회사가 있으며, 이 중 가장 많이 사용되는 Hibernate
- 스프링 부트는 기본적으로 Hibernate를 사용 (de facto)
7. Entity
Entitiy는 JPA에서 관리되는 클래스 (객체) → DB의 테이블과 매핑되어 JPA에 의해 관리
@Entity // JPA가 관리할 수 있는 Entity 클래스 지정, default는 className이며, 이름이 다를 경우 (name = "")
@Table(name = "memo") // 매핑할 테이블의 이름을 지정, default는 클래스명
public class Memo {
// JPA는 Entity 클래스를 인스턴스화할 때, 기본 생성자를 통해 생성
// 따라서, 기본 생성자 必
// id는 식별자 역할 (영속성 컨텍스트) - primary key
// GenerationType을 통해 Auto_Increment 부여
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// nullable: null 허용 여부 / default = true
// unique: 중복 허용 여부 (false 일때 중복 허용)
// default는 필드명이므로, 아래의 경우 name을 생략해도 된다.
@Column(name = "username", nullable = false, unique = true)
private String username;
// length: 컬럼 길이 지정 / default는 255
@Column(name = "contents", nullable = false, length = 500)
private String contents;
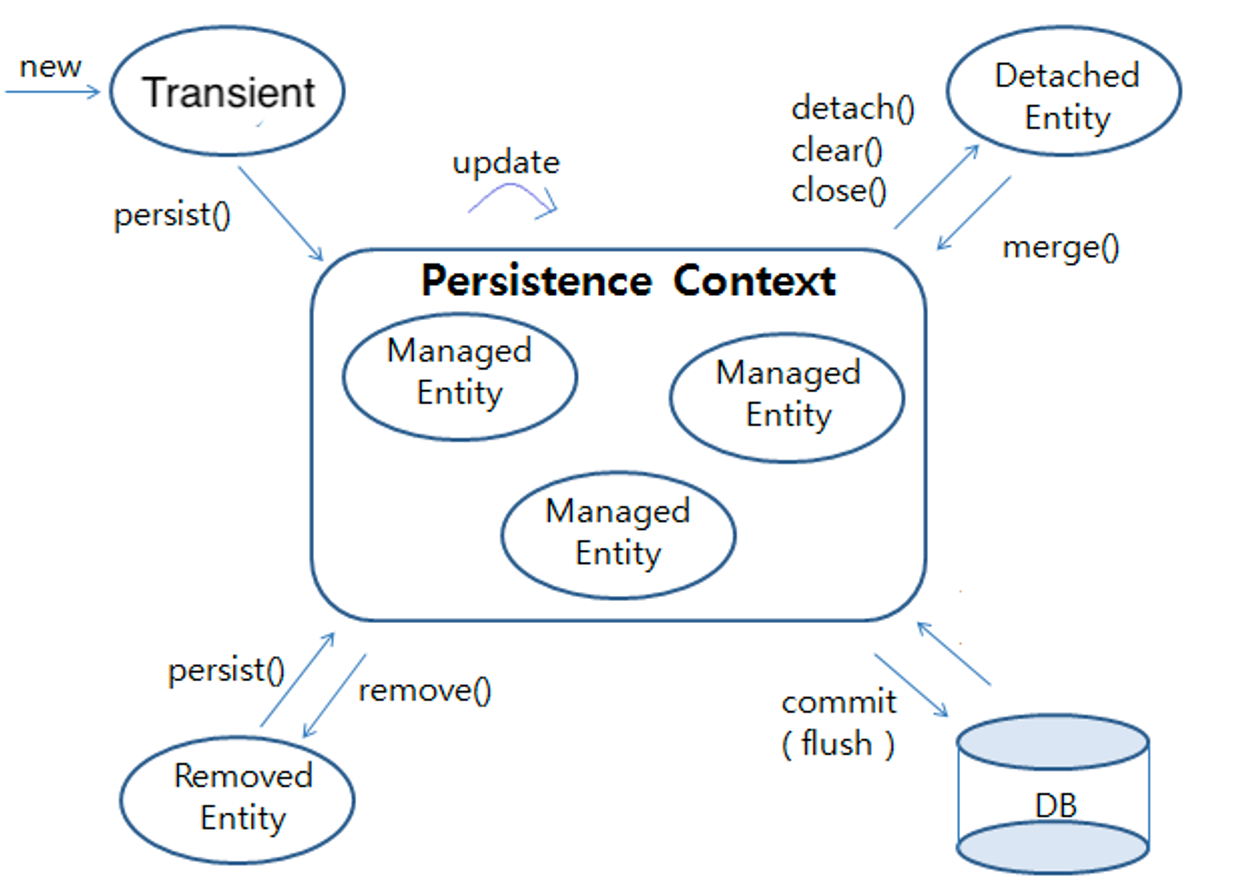
}8. 영속성 컨텍스트
Persistence (영속성, 지속성)
→ 객체가 생명(유지)이나 공간(객체의 위치)를 자유롭게 유지하고 이동할 수 있는 성질
→ Entity 객체를 효율적으로 쉽게 관리하기 위해 만들어진 공간
→ 영속성 컨텍스트에 Entity들을 저장하여 관리, DB와 연결
사용하는 이유
DB는 하드디스크 저장 vs 영속성 컨텍스트는 메모리 저장
→ 효율성, 속도 측면에서도 효율적
EntityManager
영속성 컨텍스트에 접근하여 Entity 객체를 조작하는 관리자 객체
→ EntityManager는 EntityManagerFactory를 통해 생성 가능
→ EntityManagerFactory는 DB당 1개 생성
→ EntityManagerFactory 생성을 위해서는 DB에 대한 정보 전달 필요 (persistence.xml)
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="memo">
<class>com.sparta.entity.Memo</class>
<properties>
<property name="jakarta.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="jakarta.persistence.jdbc.user" value="root"/>
<property name="jakarta.persistence.jdbc.password" value="{비밀번호}"/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/memo"/>
<property name="hibernate.hbm2ddl.auto" value="create" />
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments" value="true"/>
</properties>
</persistence-unit>
</persistence>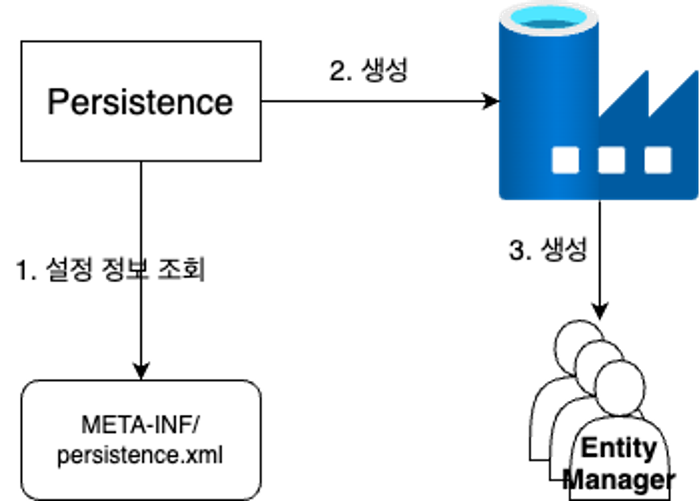
// Persistence를 통해 Factory 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("memo");
// Factory를 통해 Manager 생성
EntityManager em = emf.createEntityManager();JPA의 트랜잭션
트랜잭션(Transaction): DB 데이터들의 무결성을 유지하기 위한 논리적 개념
→ SQL 문장 실행은 DB 반영으로 이어지지만, 하나라도 틀린다면 다시 되돌려야한다.
→ Transaction을 통해 모든 SQL문이 끝나고, Commit하기 전에 되돌리기
→ SQL의 트랜잭션과 마찬가지로 Entitiy에 데이터를 저장한 뒤, 마지막 확인 후 DB 저장
public class EntityTest {
EntityManagerFactory emf;
EntityManager em;
@BeforeEach
void setUp() {
emf = Persistence.createEntityManagerFactory("memo");
em = emf.createEntityManager();
}
@Test
@DisplayName("EntityTransaction 성공 테스트")
void test1() {
EntityTransaction et = em.getTransaction(); // EntityManager 에서 EntityTransaction 을 가져옵니다.
et.begin(); // 트랜잭션을 시작합니다.
try { // DB 작업을 수행합니다.
Memo memo = new Memo(); // 저장할 Entity 객체를 생성합니다.
memo.setId(1L); // 식별자 값을 넣어줍니다.
memo.setUsername("Robbie");
memo.setContents("영속성 컨텍스트와 트랜잭션 이해하기");
em.persist(memo); // EntityManager 사용하여 memo 객체를 영속성 컨텍스트에 저장합니다.
et.commit(); // 오류가 발생하지 않고 정상적으로 수행되었다면 commit 을 호출합니다.
// commit 이 호출되면서 DB 에 수행한 DB 작업들이 반영됩니다.
} catch (Exception ex) {
ex.printStackTrace();
et.rollback(); // DB 작업 중 오류 발생 시 rollback 을 호출합니다.
} finally {
em.close(); // 사용한 EntityManager 를 종료합니다.
}
emf.close(); // 사용한 EntityManagerFactory 를 종료합니다.
}
}9. 영속성 컨텍스트의 기능
Entity Context는 Entity 객체를 효율적으로 쉽게 관리하기 위해 만들어진 공간
→ 효율적으로 관리하는 방법 살펴보기
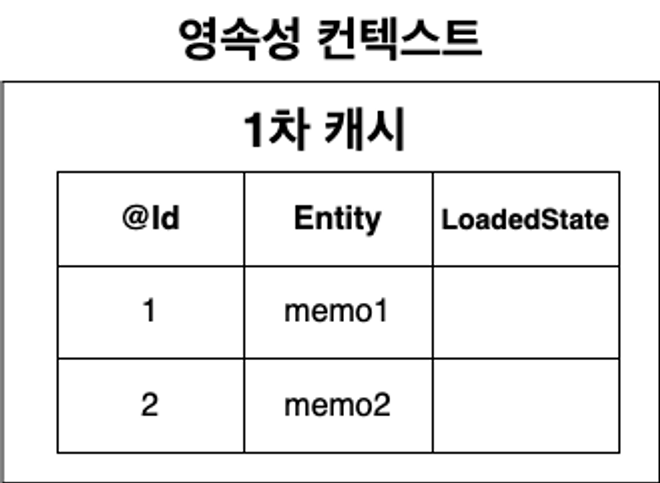
1차 캐시
→ 영속성 컨텍스트는 내부 캐시 저장소 보유!
- Entity 객체들이 1차 캐시 즉, 캐시 저장소에 저장
- 캐시 저장소는 Map 자료구조 형태
- key값은 @Id로 매핑한 Primary key(식별자)
- value값은 Entity 클래스의 객체
- key값을 통해, Entity 객체를 구분하고 관리
Entity 저장
→ em.persist(객체); 메소드 호출을 통해 객체가 캐시 저장소에 저장

@Test
@DisplayName("1차 캐시 : Entity 저장")
void test1() {
EntityTransaction et = em.getTransaction();
et.begin();
try {
Memo memo = new Memo();
memo.setId(1L);
memo.setUsername("Robbie");
memo.setContents("1차 캐시 Entity 저장");
em.persist(memo); // 저장!!
et.commit();
} catch (Exception ex) {
ex.printStackTrace();
et.rollback();
} finally {
em.close();
}
emf.close();
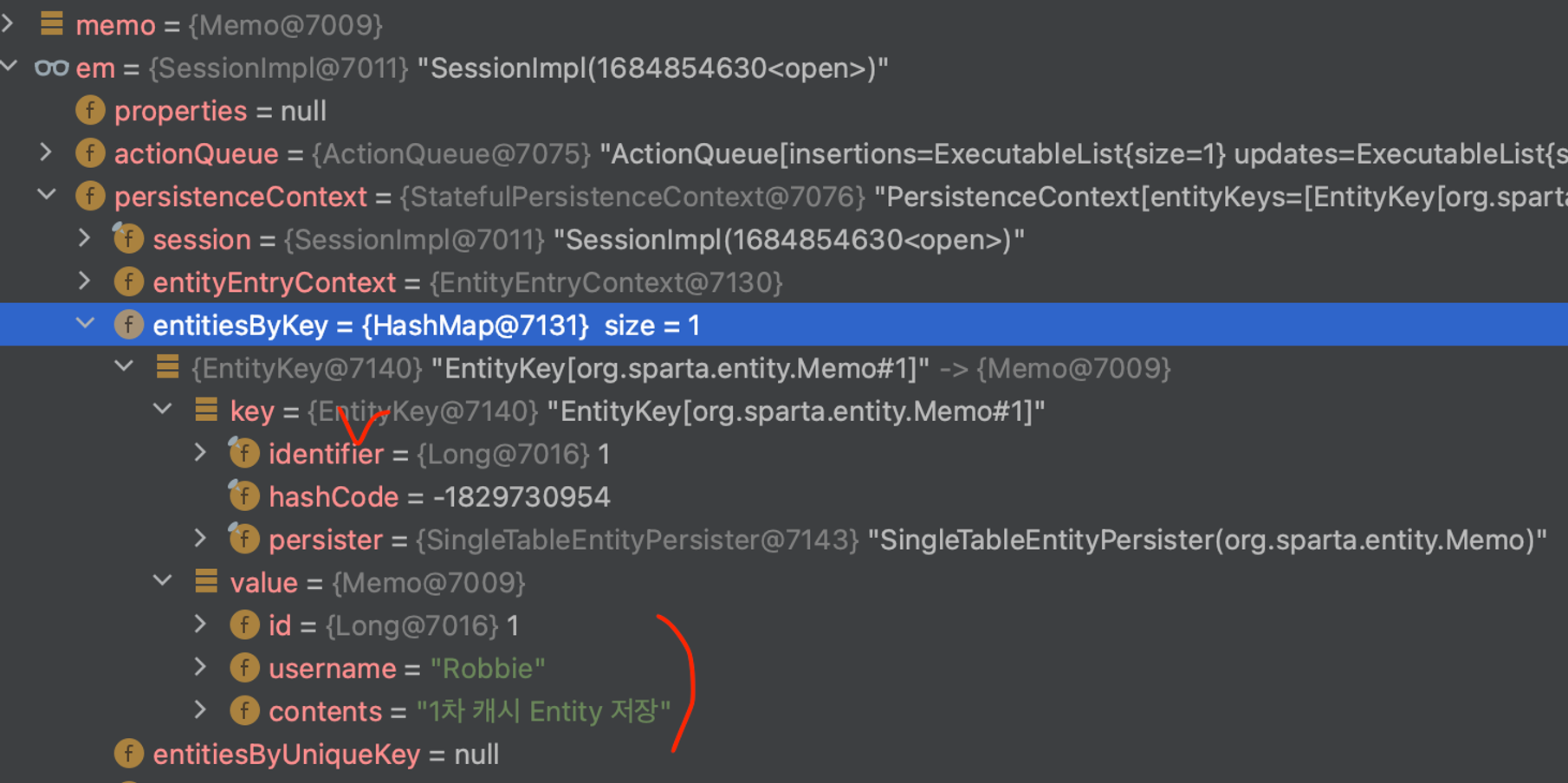
}→ 디버깅을 통한 확인 작업
- em > persistenceContext > entitiesBykey를 통해 key - value 형태로 정보가 저장됨을 확인
Entity 조회
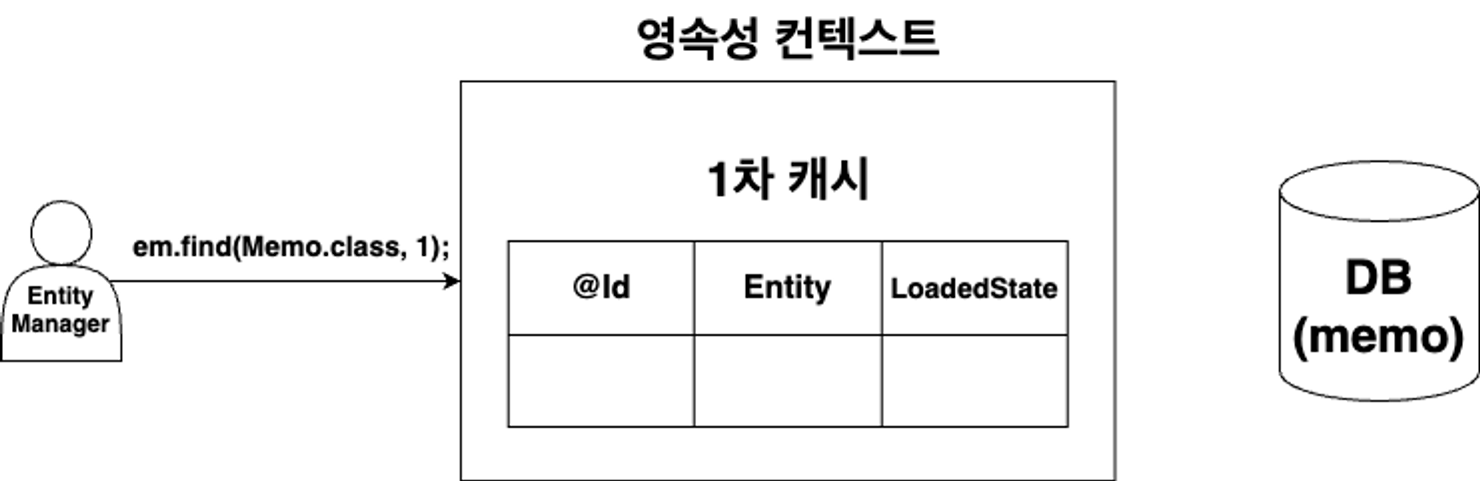
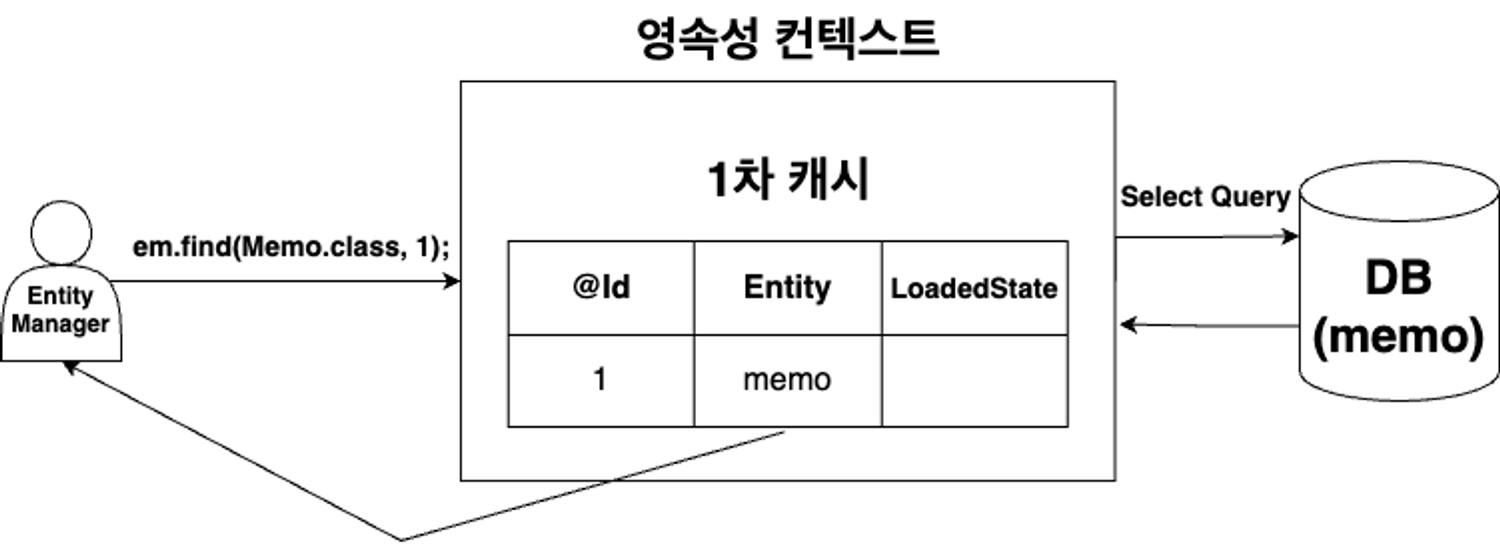
em.find(객체.class, Id)를 통해 특정 객체를 조회할 경우, 2단계에 걸쳐 조회 진행
1. 캐시 저장소 조회: 캐시 저장소에 객체가 존재한다면 (Entity타입과 Id), 해당 객체를 반환
2. DB SELECT 조회 후, 캐시저장소에 저장: 없다면, DB에 SELECT문을 통해 조회 후, 존재하는 값을 캐시 저장소에 저장한 후 반환
→ 1차로 캐시 저장소를 조회하기 때문에, 불필요한 DB 조회를 방지할 수 있다.
→1차 캐시를 사용함으로써, DB row 1개당 하나의 객체가 사용되는 것을 보장받는다. (객체 동일성 보장)
→ 객체 동일성 : 2개의 변수명에 같은 동일한 row를 조회하여 값을 대입한 경우, 두 인스턴스의 참조값은 동일하다.
Entity 삭제
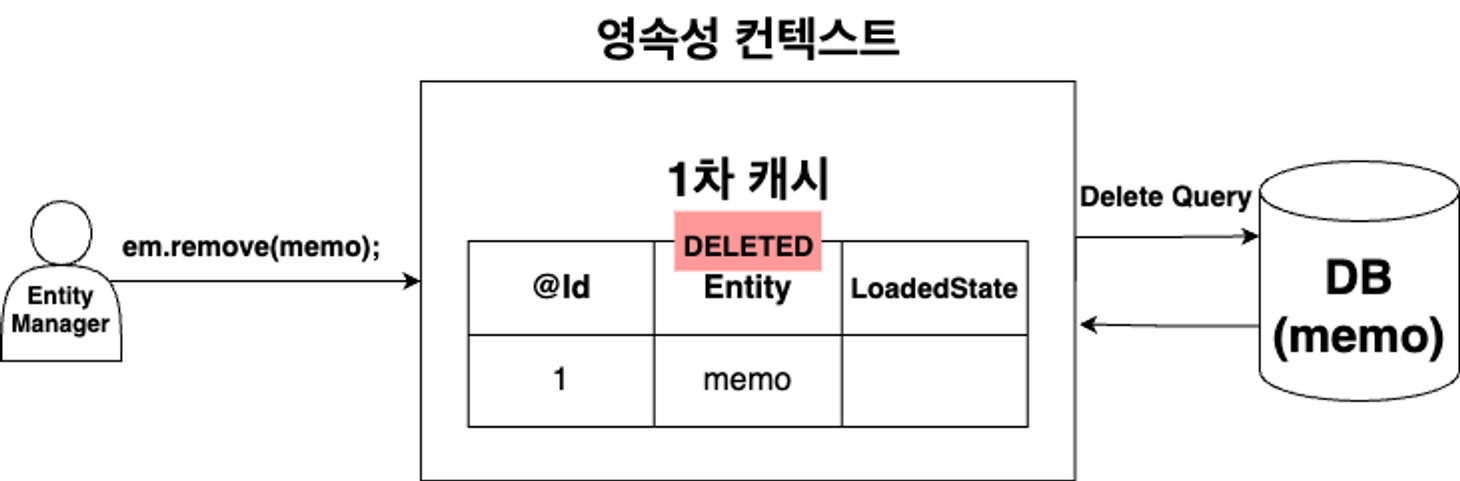
→ DB에 바로 접근하여 삭제 X
→ 먼저, 캐시 저장소로 불러온 뒤, em.remove(Entity)를 통해 삭제를 진행한다.
1. 삭제할 Entity를 조회한 후, 캐시 저장소에 저장
2. em.remove(Entity); 메서드를 통해, 캐시 저장소에 저장된 Entity의 상태를 DELETED 상태로 전환
3. 트랜잭션 commit이 이루어진 뒤, 실제 DB에서 삭제
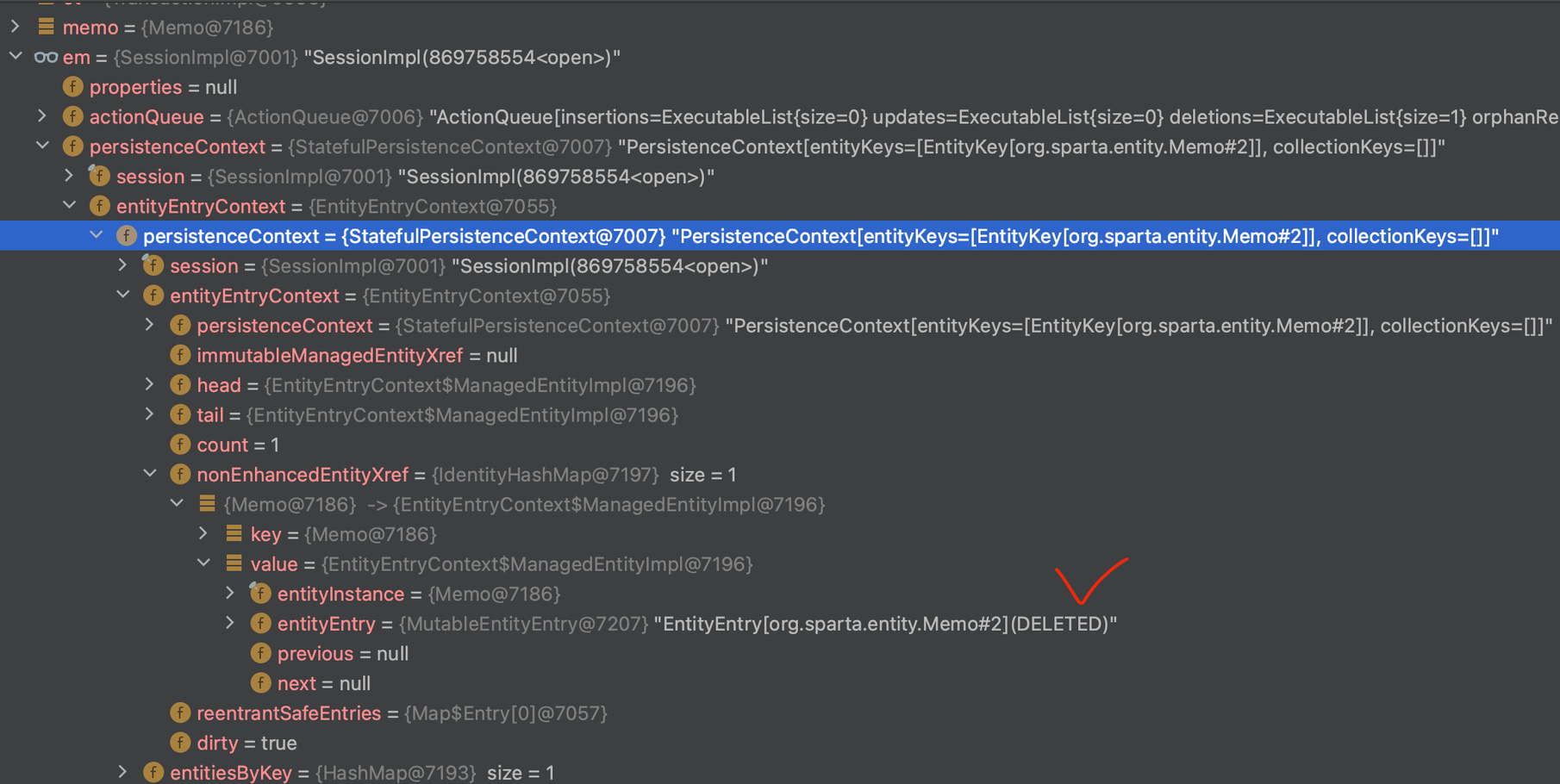
→ 디버깅을 통한 확인 작업
- em > persistenceContext > entityEntryContext > persistenceContext > entityEntryContext > nonEnhancedEntityXref > value > entityEntry 확인 가능
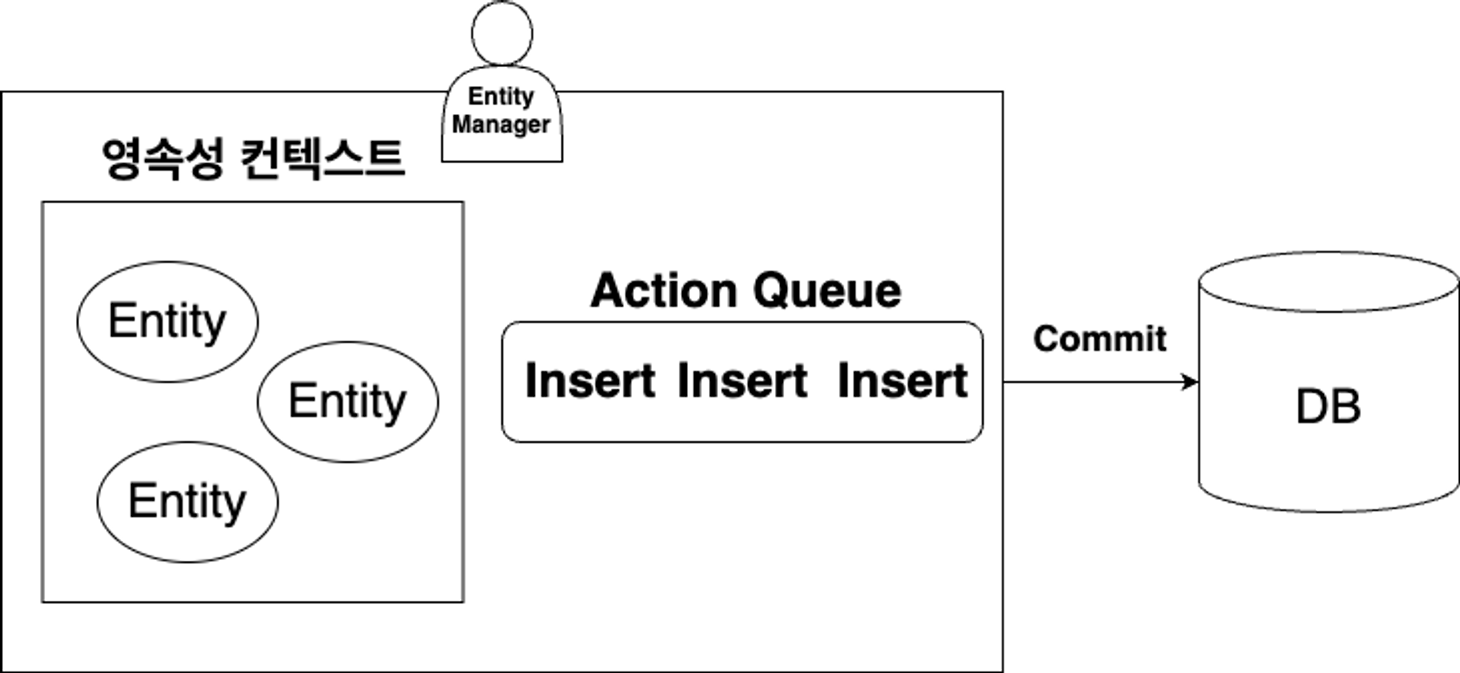
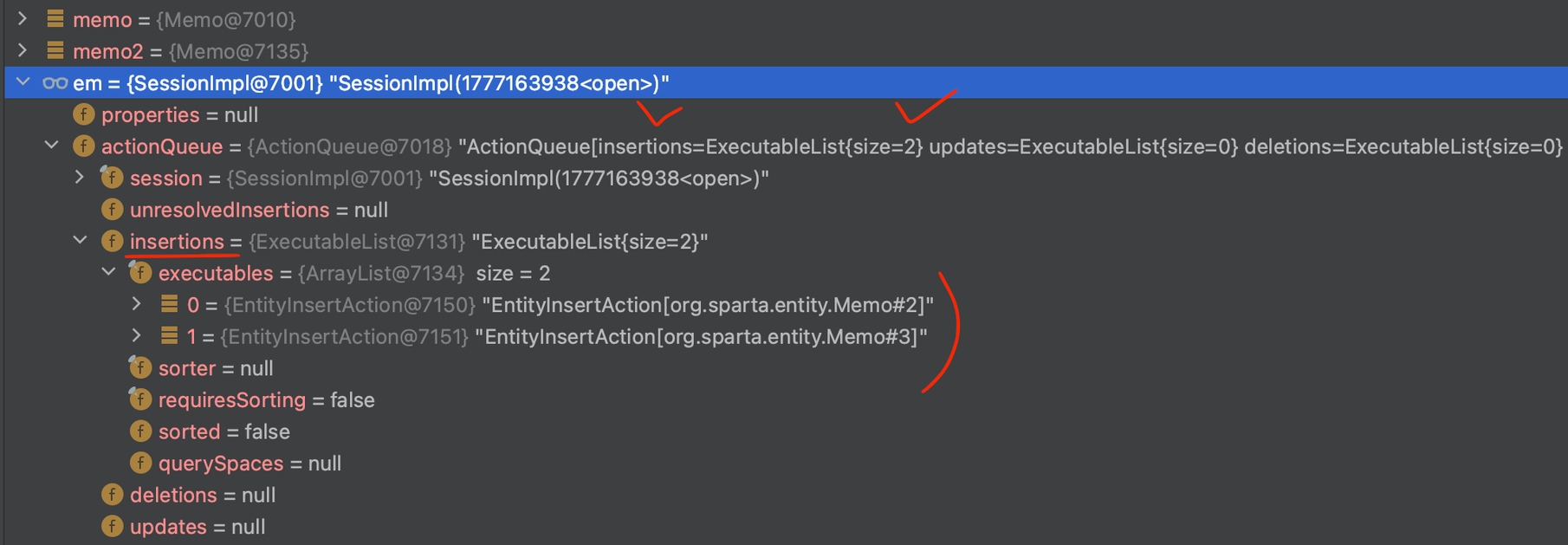
쓰기 지연 저장소 (ActionQueue)
JPA 트랜잭션은 SQL처럼 한 번에 Entity의 상태를 관리
→ 이를 구현하기 위해 쓰기 지연 저장소를 만들어 SQL을 모아두고 있다가 트랜잭션 commit 후, 한 번에 DB에 반영
- et.commit() 전 상황
→ em > actionQueue > insertions > exeutables
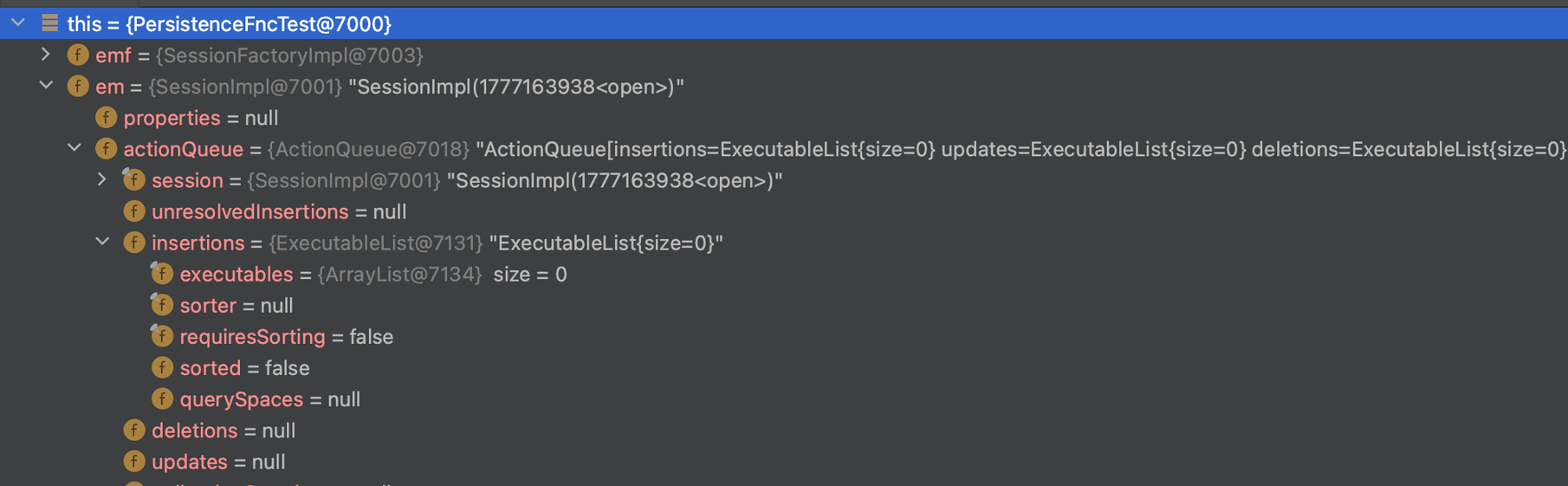
→ em.persist(Entity)를 통해 들어온 2개의 persist()-SQL 문장이 ActionQueue에 대기 중인 상태- et.commit() 후 상황
→ size 0으로 DB에 Commit 되어 사라짐
flush()
→ 트랜잭션 commit 후, 쓰기 지연 SQL 저장소에 모인 SQL 문장들이 한 번에 요청되어 DB에 저장
→ commit 전, 하나의 과정이 더 존재: em.flush();
→ flush 메서드는 영속성 컨텍스트의 변경 내용들을 DB에 반영하는 역할을 수행
→ 즉, 쓰기 지연 저장소의 SQL문을 DB SQL문과 동기화 (등록, 수정, 삭제)
→ et.commit()을 실행하면, DB SQL에 저장된 SQL 문장들을 실제로 실행, DB에 저장
Memo memo = new Memo();
memo.setId(4L);
memo.setUsername("Flush");
memo.setContents("Flush() 메서드 호출");
em.persist(memo);
System.out.println("flush() 전");
em.flush(); // flush() 직접 호출
System.out.println("flush() 후\n");
Memo memo1 = new Memo();
memo1.setId(5L);
memo1.setUsername("Flush2");
memo1.setContents("Flush() 호출 후, 새로운 메모");
em.persist(memo1);
System.out.println("트랜잭션 commit 전");
et.commit();
System.out.println("트랜잭션 commit 후");
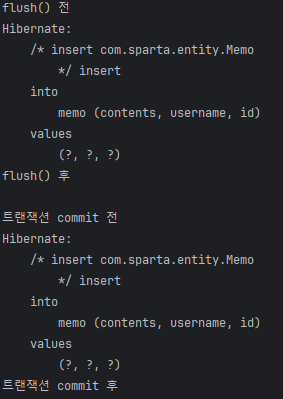
→ Hibernate를 통해 SQL문이 flush()된 순간, DB와 동기화된 SQL 문장을 출력
→ flush()는 transaction이 반드시 필요하며, 데이터의 추가, 수정, 삭제 시에 반드시 transaction이 필요
변경 감지 (Dirty Checking)
JPA는 em.update(Entity); 처럼 update 메서드를 지원하지 않는다.
→ JPA에서 수정은 변경감지와 매핑된 객체를 통해 이뤄진다.
1. em.find(entity.class, Id)를 통해 객체로 저장
- 이때, Entity의 최초상태를 LoadedState에 저장 (스냅샷)
2. 객체의 정보를 수정
- em.flush();가 호출되어 실제 DB와 동기화할 때,
- LoadedState에 저장된 최초 상태와 변경된 사항을 비교하여, Update SQL 작성
- transaction이 commit되면서 변경
3. 변경 사항을 탐지하는 과정 Dirty Checking
→ 디버깅에서 확인
→ 즉, Transaction 환경에서 Create, Update, Delete 가능
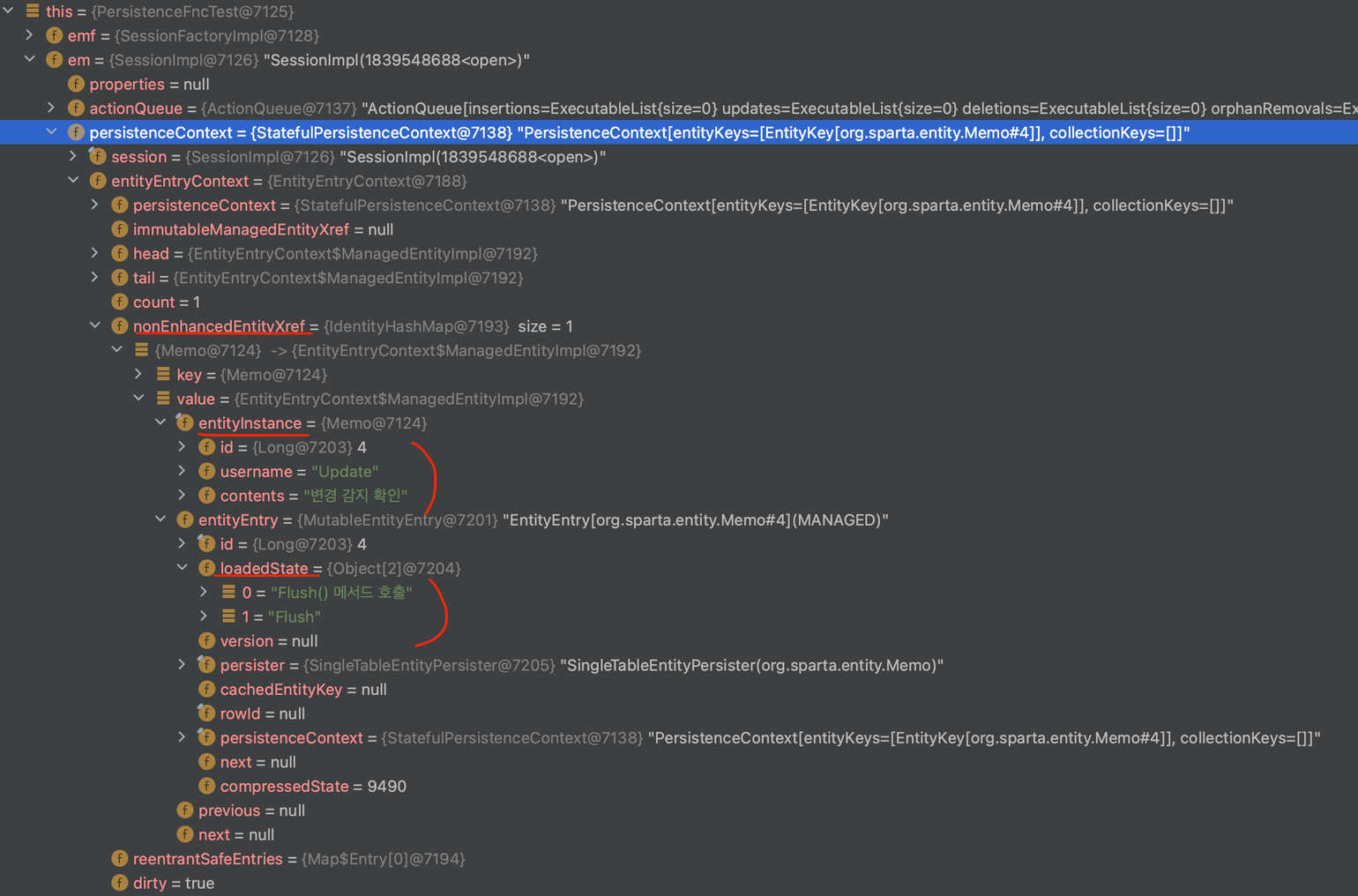
읽기 전용 트랜잭션
@Transactional(readOnly = true) 옵션을 통해, Hibernate의 flush가 매번 발생하지 않도록 설정
→ flush()는 기본적으로 commit()이 발생하면 자동 호출 → JPQL 쿼리 실행시에도 마찬가지
→ flush를 사용해야 하는 부분에 강제 적용
→ flush에서 발생하는 DirthChecking 로직이 수행되지 않기 때문에 성능 향상
10. Entity의 상태
비영속 (Transient) / 영속 (Managed) / 준영속 (Detached) / 삭제 (Removed)
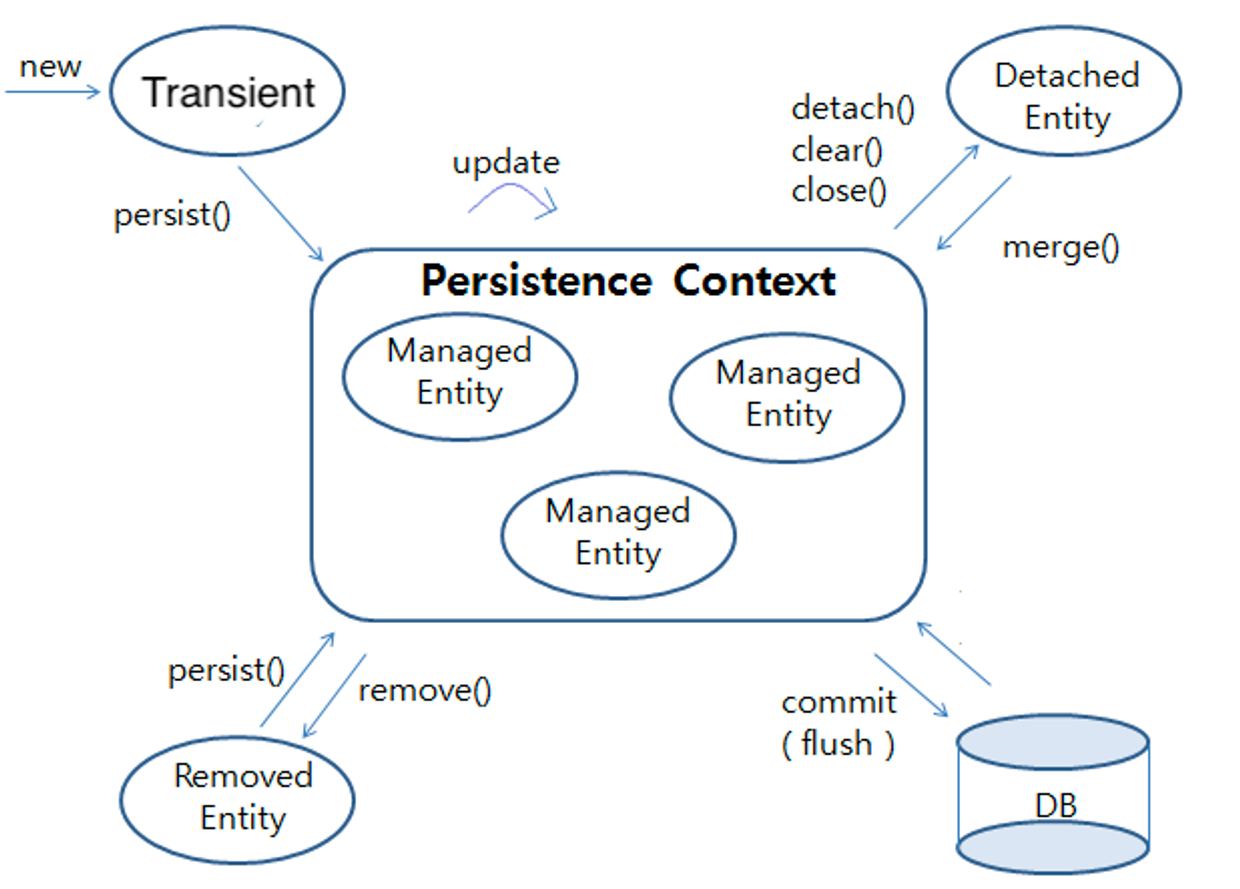
1. 비영속 (Transient)
new 연산자를 통해 인스턴스화 된 Entity 객체를 의미
→ 영속성 컨텍스트에 저장되지 않았기 때문에 (persist전), JPA의 관리를 받지 않는다.
2. 영속 (Managed)
em.persist(entity) : 비영속 Entity를 EntityManager를 통해 영속성 컨텍스트에 저장, 관리되는 상태로 전환
3. 준영속 (Detached)
영속성 컨텍스트에 저장되어 관리되다가, 분리된 상태
+ 영속 상태를 준영속 상태로 바꾸는 방법 3가지
1. detach(entity)
- 특정 Entity를 준영속 상태로 전환 (Managed → Detached)
- 영속성 컨텍스트에서 제거되는 것이지, 실제 DB에서 삭제되는 것은 아니다.
- 캐시 저장소 (1차 캐시)에서 제거되므로, JPA의 관리를 받지 못함
- 영속성 컨텍스트의 기능을 사용할 수 없는 상태
- 사용하는 이유
- 트랜잭션 종료 후에도 엔티티를 사용하기 위해
- 변경 사항을 무시하는 객체가 필요한 경우
- 프록시 해제
- 캐시 관리
- 영속성 컨텍스트로부터 추적받지 않으며, 필요한 경우에만 DB와 상호작용하는 경우
- clear()
- 영속성 컨텍스트를 완전 초기화
- 모든 Entity를 준영속 상태로 전환
- 단, 영속성 컨텍스트의 틀은 유지 → 내용만 빈 상태
- close()
- 영속성 컨텍스트 종료
+ 준영속 상태를 영속 상태로 바꾸는 방법
merge(entity)
- 매개변수로 받은 entity를 통해 새로운 영속 상태의 entity 반환
- 먼저, 전달된 entity의 id를 통해 영속성 컨텍스트 조회
- 없으면, DB를 조회하여, 영속성 컨텍스트에 추가
- DB에도 없으면, Entity를 새롭게 생성하여 Insert SQL 수행
Spring Data JPA
11. SpringBoot의 JPA
SpringBoot 환경에서, EntityManagerFactory와 EntityManager를 자동으로 생성
- build.gradle 설정
// JPA 설정
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'- application.properties 설정
// application.properties 설정
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.show_sql=true
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true- Entity 클래스 설정
@Entity // JPA가 관리할 수 있는 Entity 클래스 지정
@Getter
@Setter
@Table(name = "memo") // 매핑할 테이블의 이름을 지정
@NoArgsConstructor
public class Memo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "username", nullable = false)
private String username;
@Column(name = "contents", nullable = false, length = 500)
private String contents;
public Memo(MemoRequestDto requestDto) {
this.username = requestDto.getUsername();
this.contents = requestDto.getContents();
}
public void update(MemoRequestDto requestDto) {
this.username = requestDto.getUsername();
this.contents = requestDto.getContents();
}
}- Test case에서 Entity Manager 사용
@PersistenceContext
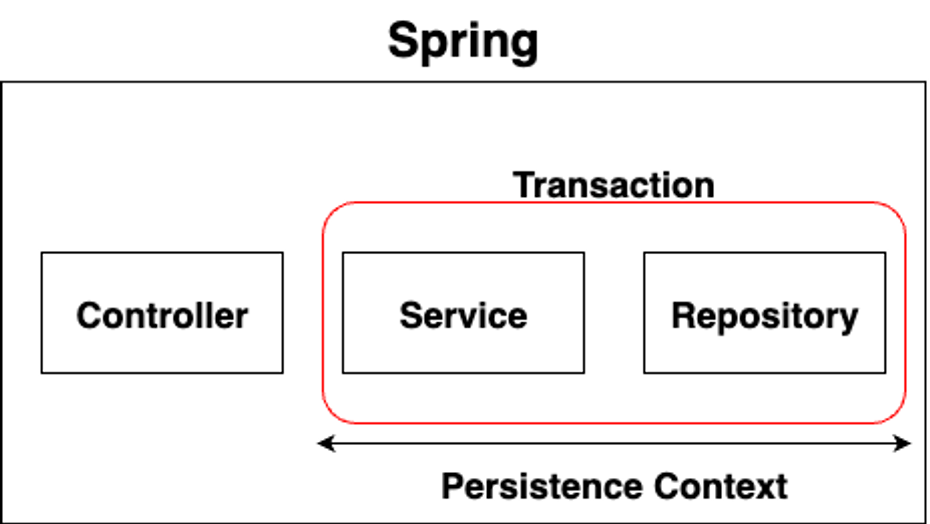
EntityManager em;Transaction 전파 개념
// propagation(전파)의 default가 REQUIRED이므로,
// 부모 메서드에 Transactional이 존재한다면, 자식 메서드의 Transactional은
// 부모 메서드에 합류하게 된다.
// 따라서, 부모메서드가 끝날 때까지, Transaction이 유지된다.
@Transactional(propagation = Propagation.REQUIRED)
public Memo createMemo(EntityManager em) {
Memo memo = em.find(Memo.class, 1);
memo.setUsername("Robbie");
memo.setContents("@Transactional 전파 테스트 중!");
System.out.println("createMemo 메서드 종료");
return memo;
}
12. Spring Data JPA
Spring Data JPA 계층구조
→ JPA를 쉽게 사용하도록 만든 하나의 모듈 (JPA를 추상화시킨 Repository 인터페이스 제공)
→ Repository 인터페이스는 Hibernate와 같은 JPA 구현체를 사용해서 구현한 클래스를 통해 사용
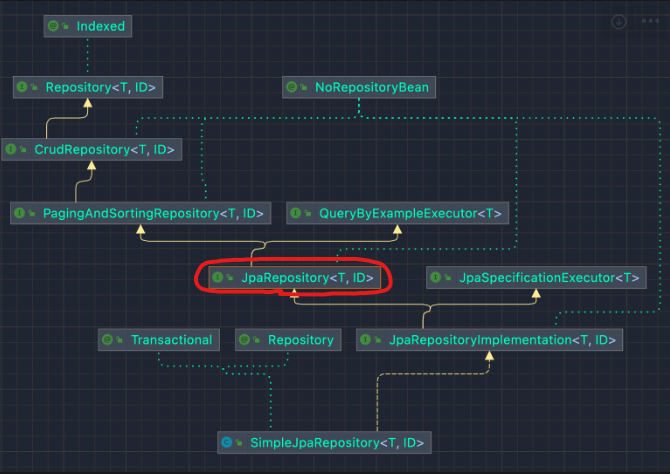
SimpleJpaRepository
→ Spring Data JPA는 JpaRepository 인터페이스를 자동으로 구현해서 생성
→ JpaRepository를 상속받아 사용
public interface ExamRepository extends JpaRepository<Exam, Integer> {
<@Entity 클래스, Id 데이터 타입>
}@Transactional을 사용하는 경우
// Transactional을 거는 이유: findById는 ReadOnly만 있을 뿐
// Update가 이뤄지려면(수정), 영속성 컨텍스트에서
// 스냅샷과 비교하는 과정이 필요
// 이때 반드시 Transaction 환경이 필요하므로, 걸어주기
@Transactional
public Long updateMemo(Long id, MemoRequestDto requestDto) {
// 업데이트
// 해당 메모가 DB에 존재하는지 확인
// Optional 객체 null일 경우 처리 .orElseThrow() -> Exception 발생
Memo memo = findMemo(id);
// 업데이트
memo.update(requestDto);
return id;
}13. JPA Auditing 적용
자주 사용되는 필드들(시간)의 Entity를 따로 생성하여, Auditing 적용
@Getter
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public abstract class Timestamped {
@CreatedDate
@Column(updatable = false)
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime createdAt;
@LastModifiedDate
@Column
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime modifiedAt;
}- Spring Data JPA는 시간에 대한 값을 자동으로 넣어주는 JPA Auditing 제공
- @MappedSuperclass → JPA Entity 클래스들이 해당 클래스를 상속할 경우, 멤버변수를 인식할 수 있음
- @EntityListeners(AuditingEntityListener.class) → Auditing 기능 포함
- @CreatedDate → 생성 시간 자동 저장
updatable = false를 통해 수정 막기 - @LastModifiedDate → 변경 시간 업데이트 자동 저장
- @Temporal → 저장할 타입 지정, DATE / TIME / TIMESTAMP
- Applicaion 클래스에 @EnableJpaAuditing 어노테이션 추가 必
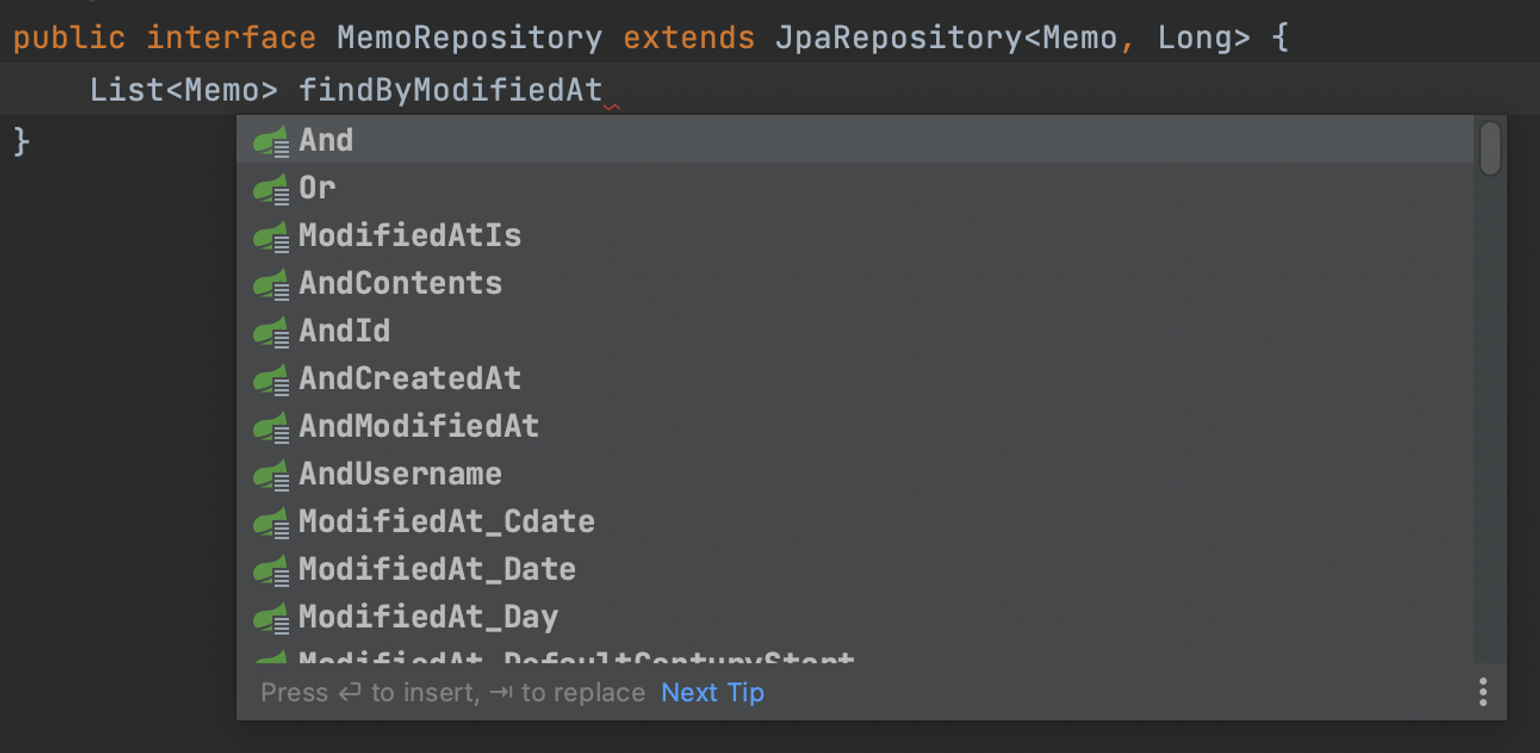
14. Query Methods
메서드 이름으로 SQL을 생성하는 Query Method 기능 제공