
이번 글에서는 BeautifulSoup을 이용해서 웹크롤링을 한 뒤, 원하는 형식으로 데이터를 정제해 지도로 표현해보겠습니다.
데이터 불러오기
from bs4 import BeautifulSoup
from urllib.request import Request, urlopenurl_base = 'http://www.chicagomag.com'
url_sub = '/Chicago-magazine/november-2012/best-sandwiches-chicago/'
url = url_base + url_sub
req = Request(url, headers={'User-Agent' : 'Chrome'})
html = urlopen(req).read()
soup = BeautifulSoup(html, 'html.parser')
soup<!DOCTYPE html> <html lang="en-US"> <head> <meta charset="utf-8"/> <meta content="IE=edge" http-equiv="X-UA-Compatible"> <link href="https://gmpg.org/xfn/11" rel="profile"/> <script src="https://cmp.osano.com/16A1AnRt2Fn8i1unj/f15ebf08-7008-40fe-9af3-db96dc3e8266/osano.js"></script> <title>The 50 Best Sandwiches in Chicago – Chicago Magazine</title> <style type="text/css"> .heateor_sss_button_instagram span.heateor_sss_svg,a.heateor_sss_instagram span.heateor_sss_svg{background:radial-gradient(circle at 30% 107%,#fdf497 0,#fdf497 5%,#fd5949 45%,#d6249f 60%,#285aeb 90%)} div.heateor_sss_horizontal_sharing a.heateor_sss_button_instagram span{background:#000!important;}div.heateor_sss_standard_follow_icons_container a.heateor_sss_button_instagram span{background:#000;} .heateor_sss_horizontal_sharing .heateor_sss_svg,.heateor_sss_standard_follow_icons_container .heateor_sss_svg{ background-color: #000!important; background: #000!important; color: #fff; border-width: 0px; border-style: solid; border-color: transparent; } .heateor_sss_horizontal_sharing .heateorSssTCBackground{ color:#666; } .heateor_sss_horizontal_sharing span.heateor_sss_svg:hover,.heateor_sss_standard_follow_icons_container span.heateor_sss_svg:hover{ border-color: transparent; ... } } </script> </body> </html>우리가 원하는 데이터는 'sammy' 클래스에 있다는 것을 확인했습니다.
데이터 분석하기
랭크, 메뉴, 가게이름, 링크 불러오기
print(soup.find_all('div','sammy'))[<div class="sammy" style="position: relative;"> <div class="sammyRank">1</div> <div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/> Old Oak Tap<br/> <em>Read more</em> </a></div> </div>, <div class="sammy" style="position: relative;"> <div class="sammyRank">2</div> <div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/"><b>Fried Bologna</b><br/> Au Cheval<br/> <em>Read more</em> </a></div> </div>, <div class="sammy" style="position: relative;"> <div class="sammyRank">3</div> <div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/"><b>Woodland Mushroom</b><br/> Xoco<br/> <em>Read more</em> </a></div> </div>, <div class="sammy" style="position: relative;"> <div class="sammyRank">4</div> <div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/"><b>Roast Beef</b><br/> Al’s Deli<br/> <em>Read more</em> </a></div> </div>, <div class="sammy" style="position: relative;"> <div class="sammyRank">5</div> <div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/"><b>PB&L</b><br/> Publican Quality Meats<br/> <em>Read more</em> </a></div> ... <div class="sammyListing"><a href="https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Phoebes-Bakery-The-Gatsby/"><b>The Gatsby</b><br/> Phoebe’s Bakery<br/> <em>Read more</em> </a></div> </div>]너무 많으니 첫 번째 데이터만 보겠습니다.
print(soup.find_all('div','sammy')[0])<div class="sammy" style="position: relative;"> <div class="sammyRank">1</div> <div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/> Old Oak Tap<br/> <em>Read more</em> </a></div> </div>원하는 랭크, 메뉴, 가게이름, 링크가 있는 것을 확인할 수 있습니다. 그것을 이용해 데이터 프레임을 만들어보겠습니다.
tmp_one = soup.find_all('div','sammy')[0]
type(tmp_one)bs4.element.Tag
from urllib.parse import urljoin
import re
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all('div', 'sammy')
for item in list_soup:
rank.append(item.find(class_='sammyRank').get_text())
tmp_string = item.find(class_='sammyListing').get_text()
main_menu.append(re.split(('\n|\r\n'),tmp_string)[0])
cafe_name.append(re.split(('\n|\r\n'),tmp_string)[1])
url_add.append(urljoin(url_base, item.find('a')['href']))import pandas as pd
data = {'Rank': rank, 'Menu': main_menu, "Cafe": cafe_name, "URL": url_add}
df = pd.DataFrame(data)
df.head()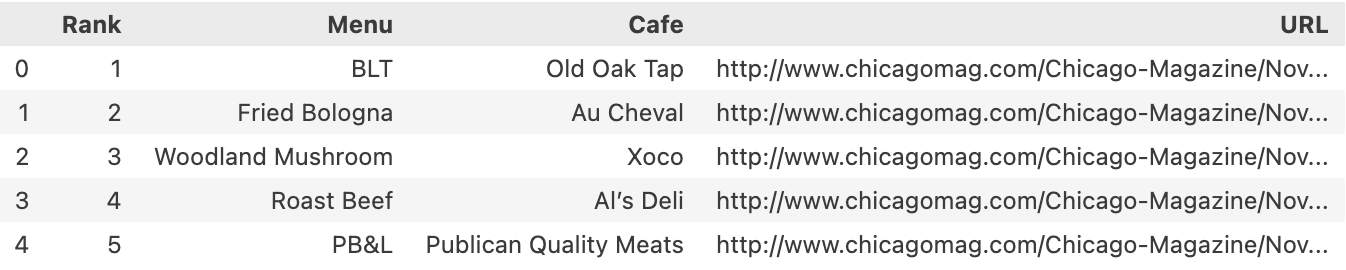
가격, 위치 불러오기
req = Request(df['URL'][0], headers = {'User-Agent':'Chrome'})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'html.parser')print(soup_tmp.find('p','addy'))<p class="addy"> <em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>
price_tmp = soup_tmp.find('p','addy').get_text()
price_tmp'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
import re
re.split('.,',price_tmp)['\n$10. 2109 W. Chicago Ave', ' 773-772-040', ' theoldoaktap.com']
price_tmp = re.split('.,', price_tmp)[0]
price_tmp'\n$10. 2109 W. Chicago Ave'
tmp = re.search('\$\d+\.(\d+)?', price_tmp).group() # Regular Expression
tmp'$10.'
price_tmp[len(tmp) +2: ] # 가격 뒤에는 주소'2109 W. Chicago Ave'
# 방금 진행한 과정 50번 반복하기
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req= Request(row["URL"], headers={"User-Agent": "Mozilla/5.0"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'html.parser')
gettings = soup_tmp.find('p','addy').get_text()
price_tmp = re.split('.,', gettings)[0]
tmp = re.search("\$\d+\.(\d+)?",price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2 :])50it [01:44, 2.10s/it]
df['Price'] = price
df['Address'] = address
df = df.loc[:, ["Rank","Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace = True)
df.head()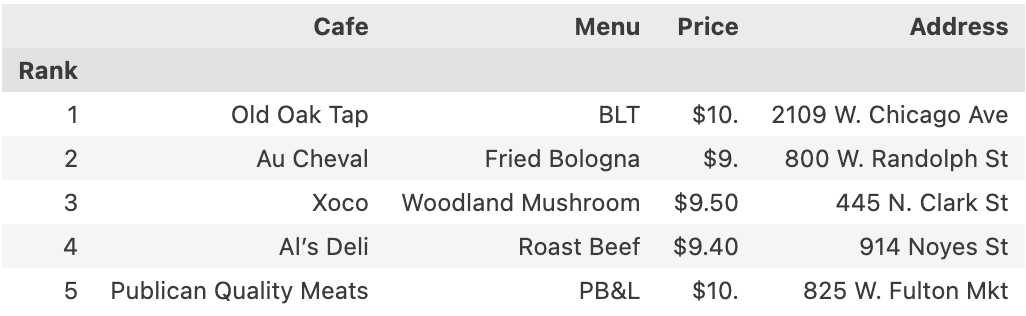
지도로 표현하기
import folium
import googlemaps
import numpy as npgmaps_key = 'AIzaSyDaMnoVWZaz1CPPRVFb4vl8wv6Mny2Pt_o'
gmaps = googlemaps.Client(key = gmaps_key)lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)50it [00:07, 6.46it/s]
df["lat"] = lat
df["lng"] = lng
df.head()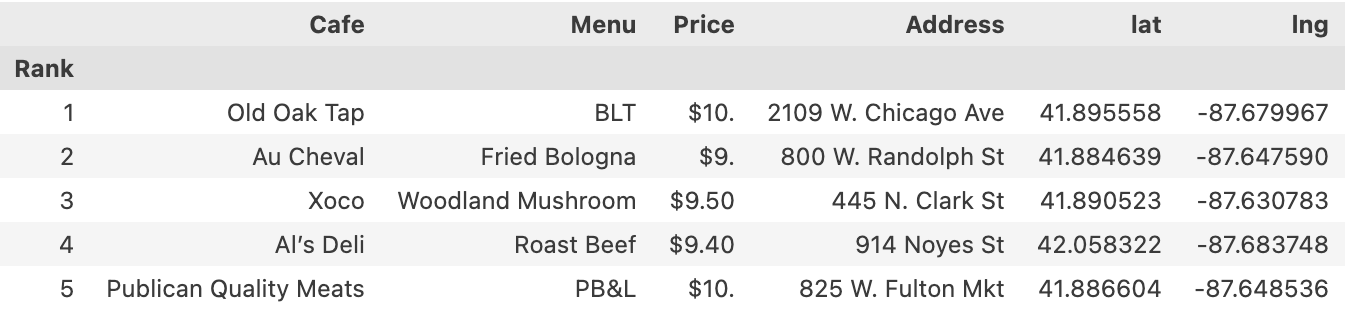
mapping = folium.Map(location=[41.8781136, -87.629782], zoom_start = 11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location = [row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon =folium.Icon(
icon = "coffee",
prefix = 'fa'
)
).add_to(mapping)
mapping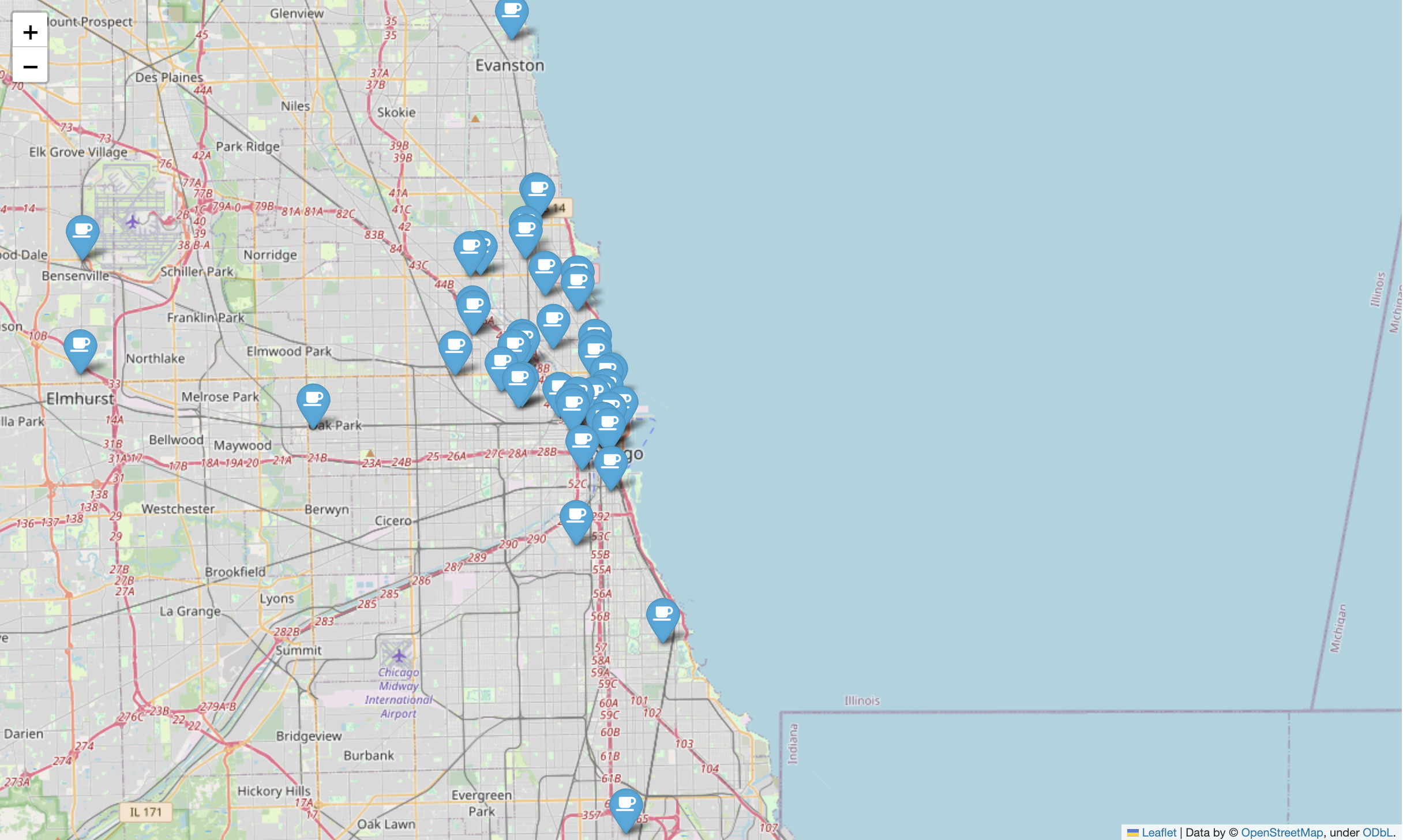

낭만젊음사랑