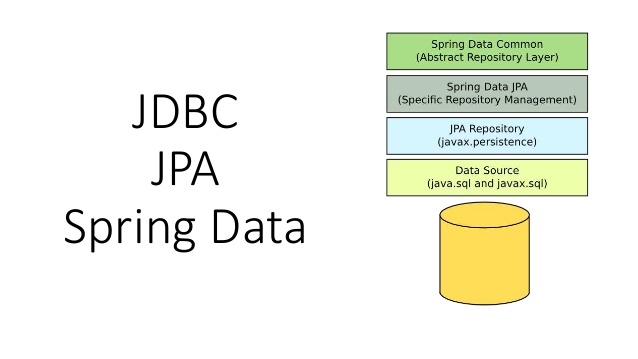
Spring Data JDBC의 탄생 배경
Spring Data JPA는 Java ORM 표준 JPA와 Hibernate로 만들어진 프레임워크입니다. 대부분의 Java 개발자들은 JPA를 공부하고 사용합니다.
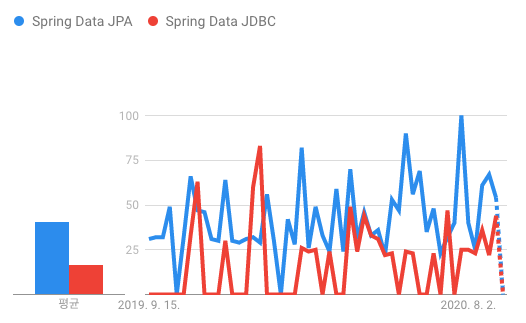 구글 트렌드에서 본 대한민국의 Data JPA와 Data JDBC 검색량
구글 트렌드에서 본 대한민국의 Data JPA와 Data JDBC 검색량
하지만 Spring에는 새로운 ORM인 Spring Data JDBC 또한 존재합니다. 이미 광범위하게 사용하는 JPA와 어떤 차이점이 있을까요?
JPA는 복잡하다
보통 JPA를 학습하기 전에 러닝 커브(learning curve)가 높다고들 이야기 합니다. 다음에 나와 있는 JPA의 특징들이 복잡하기 때문이죠.
- Lazy Loading
- Dirty Checking
- Session / 1st Level Cache
- Proxy
- M to x Mapping
Lazy Loading (Exception)
코드만 보고 파악하기 힘든 Exception입니다. 코드가 복잡해질수록 지연 로딩으로 가져오는 객체가 어느 시점에 초기화되는지 알기 힘듭니다. 또한 코드만으로 다음에 어떤 SQL 문이 발생할지 예상하기 힘들다는 문제도 있죠.
Dirty Checking
Entity Manager에 save를 하는데, 원치 않은 save가 발생할 수 있습니다. 그냥 테스트를 위해 객체를 조작하고 싶어도, 저장까지 되는 문제가 발생합니다. 특정 객체만을 제외하고 저장하고 싶은 경우에도 복잡한 원리를 이해해야만 합니다.
Session / 1st Level Cache
영속성 컨텍스트로 인해 항상 같은 객체만을 사용합니다. DB로부터 불러온 데이터와 조작한 객체를 가지고 비교하는 연산 등을 힘들게 합니다.
Proxy
엔티티 간 비교 시 프록시인지 아닌지를 확인해야만 하는 경우가 생깁니다. 이 경우 어떤 객체가 프록시이고 아닌지 판단하기 어렵죠.
M to x Mapping
M 대 N 연관관계는 다양한 문제를 야기하고 예측할 수 없습니다.
Simple is King
Complexity의 반대는 뭘까요? Simple입니다. Spring Data JDBC의 특징은 단순함입니다.
- No lazy loading
- No Session(Caching)
- No Proxies
- No Flushing : save와 동시에 Query (쓰기 지연 저장소가 없음)
- No Many to x Relation
Spring Data JDBC는 Domain Driven Design을 기반으로 합니다. 따라서 모든 Repository는 Aggregate Root 기준으로 존재합니다. 라이프사이클 또한 Aggregate Root와 하위 속성들이 동일합니다. 서로 다른 Aggregate 간 참조는 Id를 통해 수행합니다. 이러한 개념이 코드를 통해 알기 쉽게 설계되어있습니다.
Spring Data JDBC는 지연 로딩이 없고 항상 즉시 로딩 전략을 사용합니다.
Aggregate는 항상 완전한 상태라는 걸 보장받을 수 있죠. Lazy Loading Exception 또한 고민할 필요가 없습니다. 하지만 불필요한 데이터까지 함께 가져오는 단점이 있습니다. 이 부분에 대한 자세한 설명이 없지만, 발표에서는 JPA에서도 fetch type을 Eager로 설정하면 발생하는 버그니까 대수롭지 않다는 듯이 넘어가더군요..😂
JPA에서 굉장히 효율적이라고 생각했던 기능인 Flushing도 없습니다. 소스 코드만으로 Flushing에서 생성될 Query문은 예측하기 매우 까다롭습니다. 이런 부분에서 Spring Data JDBC는 직관적으로 다가옵니다.
마지막으로 대망의 연관관계입니다. Spring Data JDBC는 일대다 혹은 일대일 단방향 관계만을 추구합니다.
사실, 테이블 설계 과정에서 M to X 연관 관계는 피하려 해도 피할 수 없는 녀석이죠. Spring Data JDBC는 이러한 부분을 ID 참조로 피해갑니다.
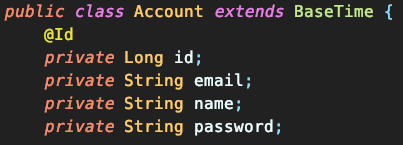
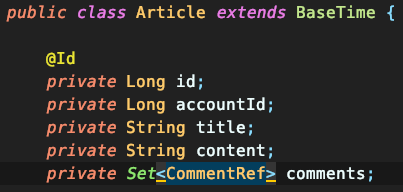
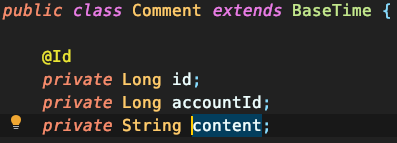
게시판의 회원, 게시글, 댓글을 기준으로 고려해보면, Article과 Account는 M to 1 연관 관계입니다. 보시는 것처럼 accountId로 단순한 Long 값만을 가지고 있는 걸 보실 수 있습니다.
반대로 Article과 Comment는 1 to M 관계입니다. 기본적으로 Set을 사용하여 연관 관계를 표현하죠. 하지만 서로 다른 Aggregate Root인 경우 ID 참조를 통해 연관 관계를 표현해야 하므로 Ref 테이블이 생기죠. DDD의 개념을 코드에서 그대로 드러나게 됩니다.
결론
Spring Data JDBC는 아직 완성되지 않은, 지속적으로 개선되어가는 프레임워크입니다. Derived Query나 Soring & Paging도 얼마전 2.0.0버전부터 지원하게 되었죠. 성능적으로 JPA에 비해 비효율적인 부분이 많지만, 직관적인 Spring Data JDBC가 굉장히 매력적인 ORM이라고 생각합니다.
Naver의 Spring Data JDBC Plus 프레임워크에 대해서도 설명해 드리고자 했으나 내용이 너무 길어질 것 같아서 다음 글에서 다뤄보도록 하겠습니다.

그렇다면 만약 article에서 account 객체를 찾고싶을땐 어떻게 해야되나요?
Spring data jpa에선 JoinColumn을 이용해서 객체를 땡겨오는데...
jdbc는 어떻게 처리하나요?