What is Conntrack?
Connection tracking is the basis of many network services and applications. For example, Kubernetes Service, ServiceMesh sidecar, software layer 4 load balancer (L4LB) LVS/IPVS, Docker network, OpenvSwitch (OVS), OpenStack security group (host firewall), etc, all rely on it.
As the name illustrates itself, connection tracking tracks (and maintains) connections and their states.
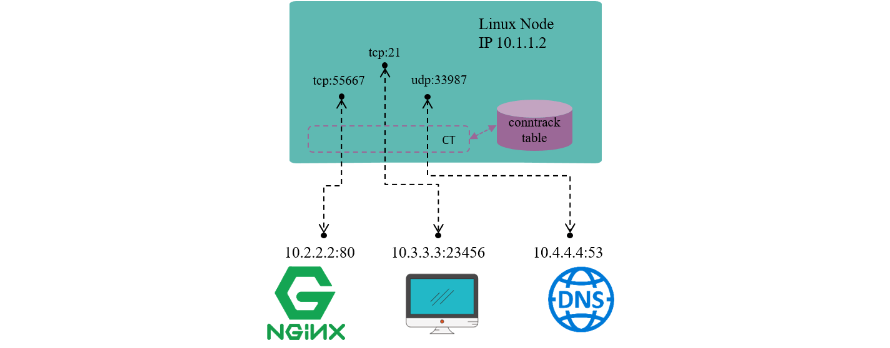
Conntrack module is responsible for discovering and recording connections and their statuses, including:
- Extract tuple from packets, distinguish flow and the related connection.
- Maintain a “database” (conntrack table) for all connections, deposit information such as connection’s created time, packets sent, bytes sent, etc.
- Garbage collecting (GC) stale connection info
- Serve for upper layer functionalities, e.g. NAT
How Conntrack works
Theory
In order for Conntrack to track all states of the connections on a node, it needs to:
1. Hook (or filter) every packet that passes through this node, and analyze the packet.
2. Setup a “database” for recoding the status of those connections (conntrack table).
3. Update connection status timely to database based on the extracted information from hooked packets.
Thus,
- When a
new connection atteptis under the way(hooked TCP sync packet), create a new conntrack entry to record the connection. - When a
existing connectionpacket arrives, update the conntrack entry statistics(bytes sent, packets sne,t timeout value, etc) - When
no packets match the conntrack entryfor more than 30 minutes, we consider to delete this entry.
++ needs to consider performance degration.
Design
- Netfilter
Connction tracking in Linux kernel is implemented as a module in Netfilter framework.
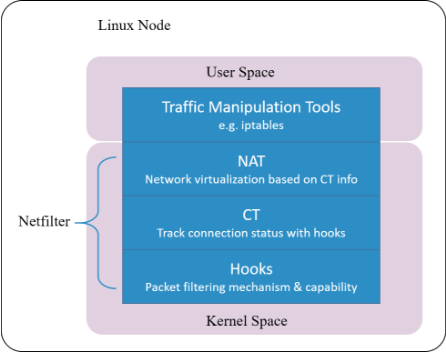
Netfilter is a packet manipulating and filtering framework inside the kernel. It provides several hooking points inside the kernel, so packet hooking, filtering and many other processings could be done.
hooking is a mechanism that places several checking points in the travesal path of packets. When a packet arrives a hooking point, it first gets checked, and the checking result could be one of:
1. let it go: no modifications to the packet, push it back to the original travesal path and let it go
2. modify it: e.g. replace network address (NAT), then push back to the original travesal path and let it go
3. drop it: e.g. by firewall rules configured at this checking (hooking) point
Note that conntrack module only extracts connection information and maintains its database, it does not modify or drop a packet.
After more than 20 years’ evolvement, it gets so complicated that results to degraded performance in certain scenarios.
Further Consideration

Cilium, a cloud native networking solution for Kubernetes, implements such a conntrack and NAT mechanism. The underlyings of the impelentation:
Hook packets based on BPF hooking points (BPF’s equivalent part of the Netfilter hooks)
Implement a completely new conntrack & NAT module based on BPF hooks (need kernel 4.19+ to be fully functional)
So, one could even remove the entire Netfilter module , and Cilium would still work for Kubernetes functionalities such as ClusterIP, NodePort, ExternalIPs and LoadBalancer [2].
Usecase
-Network address translation (NAT)
As the name illustrates, NAT translates (packets’) network addresses (IP + Port).
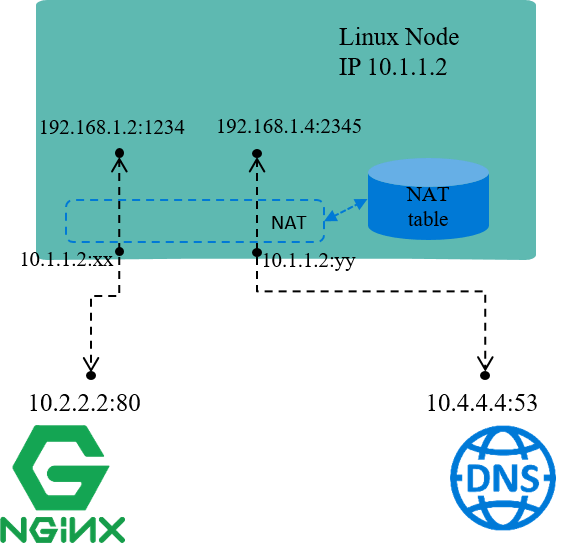
For example, in the above Fig, assume node IP 10.1.1.2 is reachable from other nodes, while IP addresses within network 192.168.1.0/24 are not reachable. This indicates:
Packets with source IPs in 192.168.1.0/24 could be sent out, as egress routing only relies on destination IP.
But, the reply packets (with destination IPs falling into 192.168.1.0/24) could not come back, as 192.168.1.0/24 is not routable within nodes.
One solution for this scenario:
On sending packets with source IPs falling into 192.168.1.0/24, replace these source IPs (and/or ports) with node IP 10.1.1.2, then send out.
On receiving reply packets, do the reverse translation, then forward traffic to the original senders. This is just the underlying working mechanism of NAT.
The default network mode of Docker, bridge network mode, uses NAT in the same way as above.
NAT relies on the results of connection tracking, and, NAT the most important use case of connection tracking.
Stateful Firewall
Stateful firewall is relative to the stateless firewall in the early days. With stateless firewall, one could only apply simple rules like drop syn to port 443 or allow syn to port 80, and it has no concept of flow. It’s impossible to configure a rule like “allow this ack if syn has been seen, otherwise drop it”, so the funtionality was quite limited.
Apparently, to provide a stateful firewall, one must track flow and states - which is just what conntrack is doing.
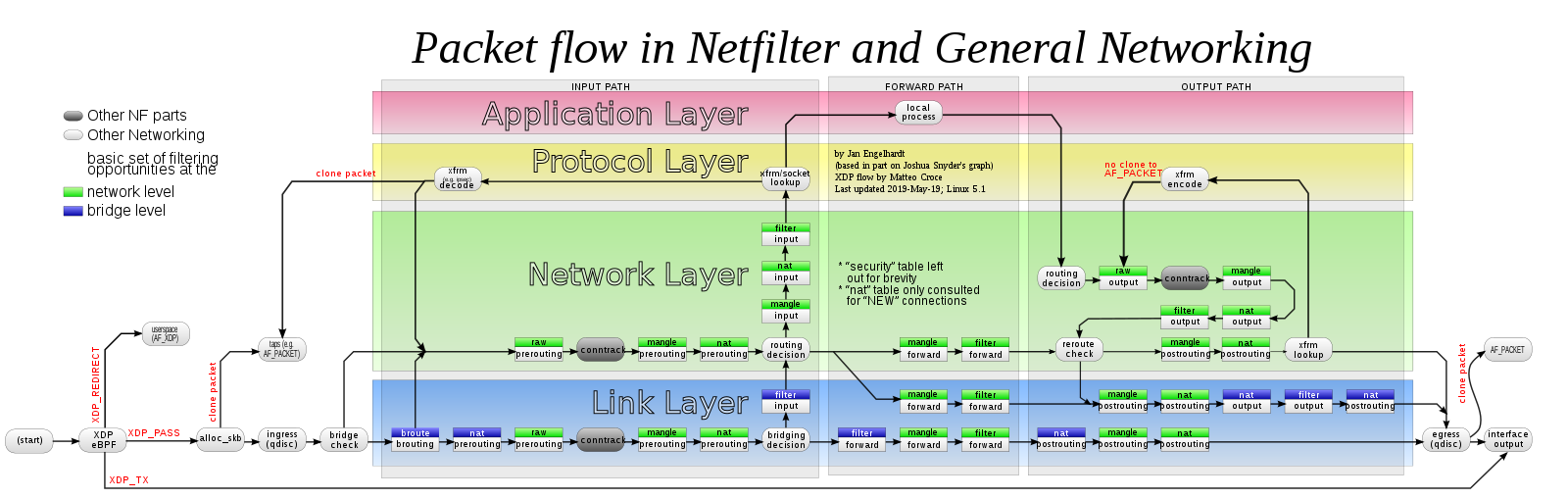
Implementation
Netfilter
The 5 hooking points
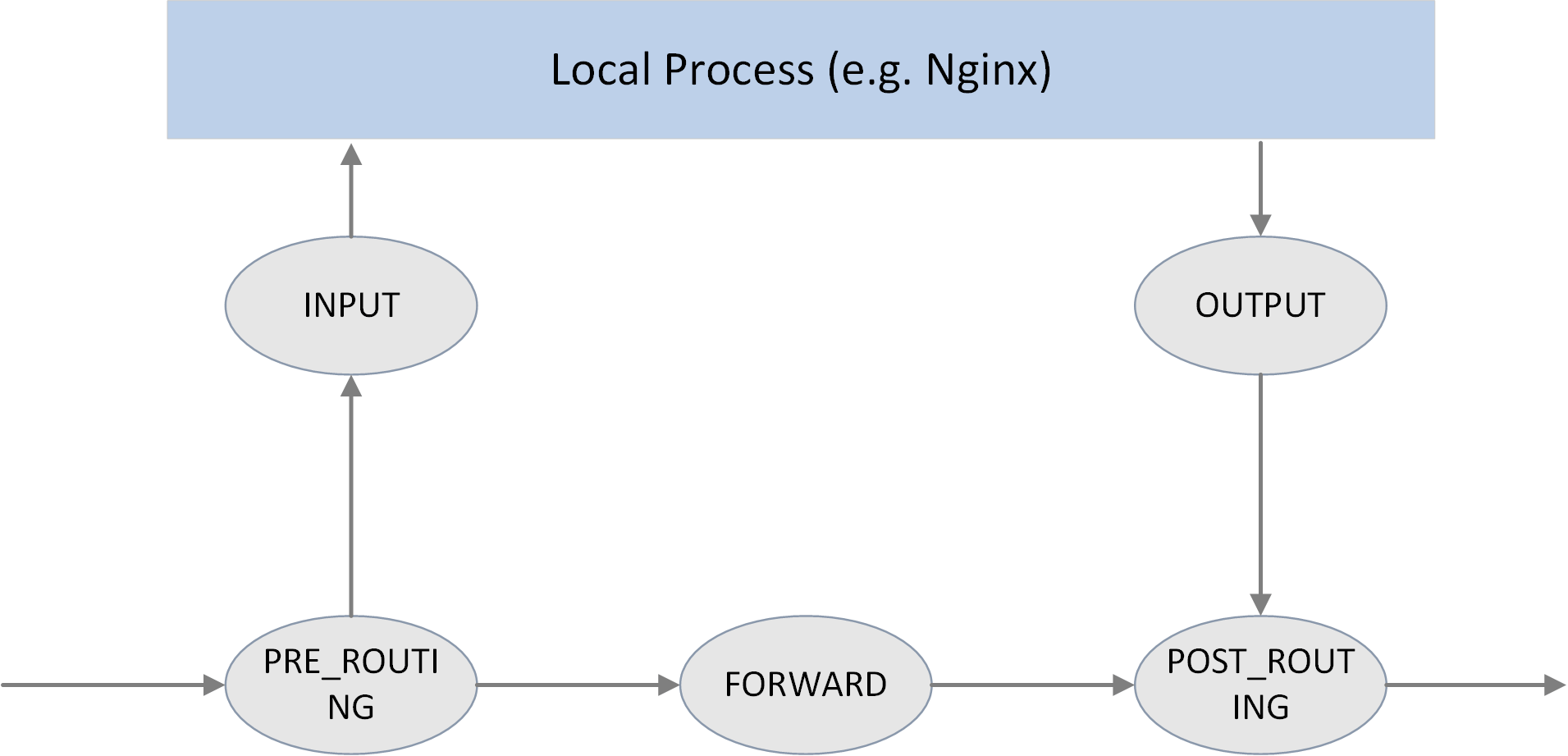
As shown in the above picture, Netfilter provides 5 hooking points in the packet travesing path inside Linux kernel:
// include/uapi/linux/netfilter_ipv4.h
#define NF_IP_PRE_ROUTING 0 /* After promisc drops, checksum checks. */
#define NF_IP_LOCAL_IN 1 /* If the packet is destined for this box. */
#define NF_IP_FORWARD 2 /* If the packet is destined for another interface. */
#define NF_IP_LOCAL_OUT 3 /* Packets coming from a local process. */
#define NF_IP_POST_ROUTING 4 /* Packets about to hit the wire. */
#define NF_IP_NUMHOOKS 5Users could register callback functions (handlers) at these points. When a packet arrives at the hook point, it will triger the related handlers being called.
Hook handler return values
// include/uapi/linux/netfilter.h
#define NF_DROP 0 // the packet has been dropped this packet in handler
#define NF_ACCEPT 1 // the packet is no dropped, continue following processing
#define NF_STOLEN 2 // silently holds the packet until something happends, no further processing is needed
// usually used to collect fragmented packets (for later assembling)
#define NF_QUEUE 3 // the packet should be pushed into queue
#define NF_REPEAT 4 // current handler should be called again against the packetHook handler priorities
Multiple handlers could be registered to the same hooking point.
When register a handler, a priority parameter must be provided. So that when a packet arrives at this point, the system could call these handlers in order with their priorities.
Conntrack
conntrack module traces the connection status of trackable protocols. That is, connection tracking targets at specific protocols, not all. We will see later what protocols it supports.
Key data structures:
struct nf_conntrack_tuple {}: defines a tuple.
struct nf_conntrack_man {}: the manipulatable part of a tuple
-struct nf_conntrack_man_proto {}: the protocol specific part in tuple’s manipulatable part
struct nf_conntrack_l4proto {}: a collection of methods a trackable protocol needs to implement (and other fields).
struct nf_conntrack_tuple_hash {}: defines a conntrack entry (value) stored in hash table (conntrack table), hash key is a uint32 integer computed from tuple info.
struct nf_conn {}: defines a flow.
Key functions:
hash_conntrack_raw(): calculates a 32bit hash key from tuple info.
nf_conntrack_in(): core of the conntrack module, the entrypoint of connection tracking.
resolve_normal_ct() -> init_conntrack() -> ct = __nf_conntrack_alloc(); l4proto->new(ct): Create a new conntrack entry, then init it with protocol-specific method.
nf_conntrack_confirm(): confirms the new connection that previously created via nf_conntrack_in()
- struct nf_conntrack_tuple {} : Tuple
A tuple uniquely defines a unidirectional flow, this is clearly explained in kernel code comments:
//include/net/netfilter/nf_conntrack_tuple.h
A tuple is a structure containing the information to uniquely identify a connection. ie. if two packets have the same tuple, they are in the same connection; if not, they are not.
// include/net/netfilter/nf_conntrack_tuple.h
// ude/uapi/linux/netfilter.h
union nf_inet_addr {
__u32 all[4];
__be32 ip;
__be32 ip6[4];
struct in_addr in;
struct in6_addr in6;
/* manipulatable part of the tuple */ / };
struct nf_conntrack_man { /
union nf_inet_addr u3; -->--/
union nf_conntrack_man_proto u; -->--\
\ // include/uapi/linux/netfilter/nf_conntrack_tuple_common.h
u_int16_t l3num; // L3 proto \ // protocol specific part
}; union nf_conntrack_man_proto {
__be16 all;/* Add other protocols here. */
struct { __be16 port; } tcp;
struct { __be16 port; } udp;
struct { __be16 id; } icmp;
struct { __be16 port; } dccp;
struct { __be16 port; } sctp;
struct { __be16 key; } gre;
};
struct nf_conntrack_tuple { /* This contains the information to distinguish a connection. */
struct nf_conntrack_man src; // source address info, manipulatable part
struct {
union nf_inet_addr u3;
union {
__be16 all; // Add other protocols here
struct { __be16 port; } tcp;
struct { __be16 port; } udp;
struct { u_int8_t type, code; } icmp;
struct { __be16 port; } dccp;
struct { __be16 port; } sctp;
struct { __be16 key; } gre;
} u;
u_int8_t protonum; // The protocol
u_int8_t dir; // The direction (for tuplehash)
} dst; // destination address info
};There are only 2 fields (src and dst) inside struct nf_conntrack_tuple {}, each stores source and destination address information.
But src and dst are themselves also structs, storing protocol specific data. Take IPv4 UDP as example, information of the 5-tuple stores in the following fields:
dst.protonum: protocol type (IPPROTO_UDP)src.u3.ip: source IP addressdst.u3.ip: destination IP addresssrc.u.udp.port: source UDP port numberdst.u.udp.port: destination UDP port number
Pay attention to the ICMP protocol. People may think that connction tracking is done by hashing over L3+L4 headers of packets, while ICMP is a L3 protocol, so it could not be conntrack-ed. But actually it could be, from the above code, we see that the type and code fields in ICMP header are used for defining a tuple and performing subsequent hashing.
- struct nf_conntrack_l4proto {}: methods trackable protocols need to implement
Protocols that support connection tracking need to implement the methods defined in struct nf_conntrack_l4proto {}, for example pkt_to_tuple(), which extracts tuple information from given packet’s L3/L4 header.
// include/net/netfilter/nf_conntrack_l4proto.h
struct nf_conntrack_l4proto {
u_int16_t l3proto; /* L3 Protocol number. */
u_int8_t l4proto; /* L4 Protocol number. */
// extract tuple info from given packet (skb)
bool (*pkt_to_tuple)(struct sk_buff *skb, ... struct nf_conntrack_tuple *tuple);
// returns verdict for packet
int (*packet)(struct nf_conn *ct, const struct sk_buff *skb ...);
// create a new conntrack, return TRUE if succeeds.
// if returns TRUE, packet() method will be called against this skb later
bool (*new)(struct nf_conn *ct, const struct sk_buff *skb, unsigned int dataoff);
// determin if this packet could be conntrack-ed.
// if could, packet() method will be called against this skb later
int (*error)(struct net *net, struct nf_conn *tmpl, struct sk_buff *skb, ...);
...
};- struct nf_conntrack_tuple_hash {}: conntrack entry
conntrack modules stores active connections in a hash table:
- key: 32bit value calculated from tuple info
// net/netfilter/nf_conntrack_core.c
static u32 hash_conntrack_raw(struct nf_conntrack_tuple *tuple, struct net *net)
{
get_random_once(&nf_conntrack_hash_rnd, sizeof(nf_conntrack_hash_rnd));
/* The direction must be ignored, so we hash everything up to the
* destination ports (which is a multiple of 4) and treat the last three bytes manually. */
u32 seed = nf_conntrack_hash_rnd ^ net_hash_mix(net);
unsigned int n = (sizeof(tuple->src) + sizeof(tuple->dst.u3)) / sizeof(u32);
return jhash2((u32 *)tuple, n, seed ^ ((tuple->dst.u.all << 16) | tuple->dst.protonum));
}- value: conntrack entry (struct nf_conntrack_tuple_hash {})
// include/net/netfilter/nf_conntrack_tuple.h
// Connections have two entries in the hash table: one for each way
struct nf_conntrack_tuple_hash {
struct hlist_nulls_node hnnode; // point to the related connection `struct nf_conn`,
// list for fixing hash collisions
struct nf_conntrack_tuple tuple;
};- struct nf_conn {}: connection
Each flow in Netfilter is called a connection, even for those connectionless protocols (e.g. UDP). A connection is defined as struct nf_conn {}, with important fields as follows:
// include/net/netfilter/nf_conntrack.h
// include/linux/skbuff.h
------> struct nf_conntrack {
| atomic_t use; // refcount?
| };
struct nf_conn { |
struct nf_conntrack ct_general;
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX]; // conntrack entry, array for ingress/egress flows
unsigned long status; // connection status, see below for detailed status list
u32 timeout; // timer for connection status
possible_net_t ct_net;
struct hlist_node nat_bysource;
// per conntrack: protocol private data
struct nf_conn *master; union nf_conntrack_proto {
/ /* insert conntrack proto private data here */
u_int32_t mark; /* mark skb */ / struct nf_ct_dccp dccp;
u_int32_t secmark; / struct ip_ct_sctp sctp;
/ struct ip_ct_tcp tcp;
union nf_conntrack_proto proto; ---------->----/ struct nf_ct_gre gre;
}; unsigned int tmpl_padto;
};The collection of all possible connection states in conntrack module, enum ip_conntrack_status:
// include/uapi/linux/netfilter/nf_conntrack_common.h
enum ip_conntrack_status {
IPS_EXPECTED = (1 << IPS_EXPECTED_BIT),
IPS_SEEN_REPLY = (1 << IPS_SEEN_REPLY_BIT),
IPS_ASSURED = (1 << IPS_ASSURED_BIT),
IPS_CONFIRMED = (1 << IPS_CONFIRMED_BIT),
IPS_SRC_NAT = (1 << IPS_SRC_NAT_BIT),
IPS_DST_NAT = (1 << IPS_DST_NAT_BIT),
IPS_NAT_MASK = (IPS_DST_NAT | IPS_SRC_NAT),
IPS_SEQ_ADJUST = (1 << IPS_SEQ_ADJUST_BIT),
IPS_SRC_NAT_DONE = (1 << IPS_SRC_NAT_DONE_BIT),
IPS_DST_NAT_DONE = (1 << IPS_DST_NAT_DONE_BIT),
IPS_NAT_DONE_MASK = (IPS_DST_NAT_DONE | IPS_SRC_NAT_DONE),
IPS_DYING = (1 << IPS_DYING_BIT),
IPS_FIXED_TIMEOUT = (1 << IPS_FIXED_TIMEOUT_BIT),
IPS_TEMPLATE = (1 << IPS_TEMPLATE_BIT),
IPS_UNTRACKED = (1 << IPS_UNTRACKED_BIT),
IPS_HELPER = (1 << IPS_HELPER_BIT),
IPS_OFFLOAD = (1 << IPS_OFFLOAD_BIT),
IPS_UNCHANGEABLE_MASK = (IPS_NAT_DONE_MASK | IPS_NAT_MASK |
IPS_EXPECTED | IPS_CONFIRMED | IPS_DYING |
IPS_SEQ_ADJUST | IPS_TEMPLATE | IPS_OFFLOAD),
};Source: https://arthurchiao.art/blog/conntrack-design-and-implementation/
TODO
- iptables netfilter conntrack 구조 및 구현 이해
- Conntrack call stack 분석
- Conntrack DB (Entries가 저장되는 방식) 에 대한 이해
conntrack is stored as below:
struct nf_conn {
/* Usage count in here is 1 for hash table, 1 per skb,
* plus 1 for any connection(s) we are `master' for
*
* Hint, SKB address this struct and refcnt via skb->_nfct and
* helpers nf_conntrack_get() and nf_conntrack_put().
* Helper nf_ct_put() equals nf_conntrack_put() by dec refcnt,
* except that the latter uses internal indirection and does not
* result in a conntrack module dependency.
* beware nf_ct_get() is different and don't inc refcnt.
*/
struct nf_conntrack ct_general;
spinlock_t lock;
/* jiffies32 when this ct is considered dead */
u32 timeout;
#ifdef CONFIG_NF_CONNTRACK_ZONES
struct nf_conntrack_zone zone;
#endif
/* XXX should I move this to the tail ? - Y.K */
/* These are my tuples; original and reply */
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];
/* Have we seen traffic both ways yet? (bitset) */
unsigned long status;
possible_net_t ct_net;
#if IS_ENABLED(CONFIG_NF_NAT)
struct hlist_node nat_bysource;
#endif
/* all members below initialized via memset */
struct { } __nfct_init_offset;
/* If we were expected by an expectation, this will be it */
struct nf_conn *master;
#if defined(CONFIG_NF_CONNTRACK_MARK)
u_int32_t mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
u_int32_t secmark;
#endif
/* Extensions */
struct nf_ct_ext *ext;
/* Storage reserved for other modules, must be the last member */
union nf_conntrack_proto proto;
};1. CONFIG_NF_CONNTRACK_ZONES if defined:
static inline const struct nf_conntrack_zone *
nf_ct_zone(const struct nf_conn *ct)
{
#ifdef CONFIG_NF_CONNTRACK_ZONES
return &ct->zone;
#else
return &nf_ct_zone_dflt;
#endif
}
static inline const struct nf_conntrack_zone *
nf_ct_zone_init(struct nf_conntrack_zone *zone, u16 id, u8 dir, u8 flags)
{
zone->id = id;
zone->flags = flags;
zone->dir = dir;
return zone;
}
...
conntrack zone defined as:
struct nf_conntrack_zone {
u16 id;
u8 flags;
u8 dir;
};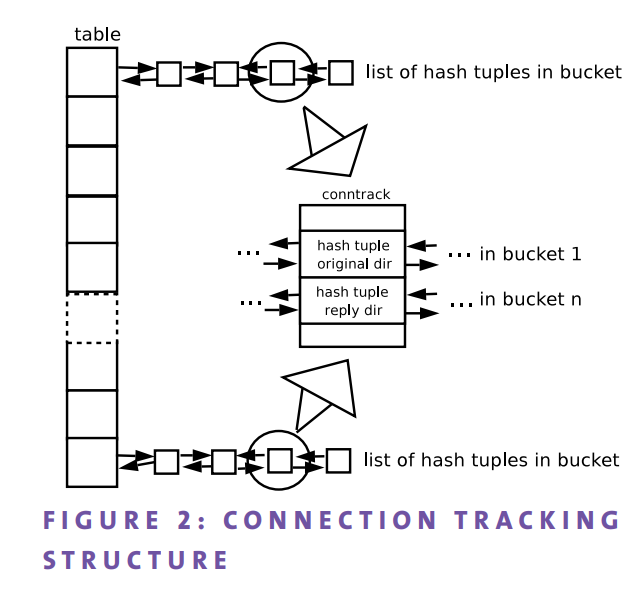
Connection tracking system is implemented with a hash table (Fig. 2) to perform efficient lookups. Each bucket has a doublelinked list of hash tuples. There are two hash tuples for every connection: one for the original direction (i.e., packets coming from the point that started the connection) and one for the reply direction (i.e., reply packets going to the point that started the connection).
Tuples
nf_conntrack_tuple_hash
/* Connections have two entries in the hash table: one for each way */
struct nf_conntrack_tuple_hash {
struct hlist_nulls_node hnnode;
struct nf_conntrack_tuple tuple;
};nf_conntrack_tuple
//nf_conntrack.h
/* This contains the information to distinguish a connection. */
struct nf_conntrack_tuple {
struct nf_conntrack_man src;
/* These are the parts of the tuple which are fixed. */
struct {
union nf_inet_addr u3;
union {
/* Add other protocols here. */
__be16 all;
struct {
__be16 port;
} tcp;
struct {
__be16 port;
} udp;
struct {
u_int8_t type, code;
} icmp;
struct {
__be16 port;
} dccp;
struct {
__be16 port;
} sctp;
struct {
__be16 key;
} gre;
} u;
/* The protocol. */
u_int8_t protonum;
/* The direction (for tuplehash) */
u_int8_t dir;
} dst;
};(nf_inet_addr)
union nf_inet_addr {
__u32 all[4];
__be32 ip;
__be32 ip6[4];
struct in_addr in;
struct in6_addr in6;
};services like NAT use tuplehash right away:
static int set_sig_addr(struct sk_buff *skb, struct nf_conn *ct,
enum ip_conntrack_info ctinfo,
unsigned int protoff, unsigned char **data,
TransportAddress *taddr, int count)
{
const struct nf_ct_h323_master *info = nfct_help_data(ct);
int dir = CTINFO2DIR(ctinfo);
int i;
__be16 port;
union nf_inet_addr addr;
for (i = 0; i < count; i++) {
if (get_h225_addr(ct, *data, &taddr[i], &addr, &port)) {
if (addr.ip == ct->tuplehash[dir].tuple.src.u3.ip &&
port == info->sig_port[dir]) {
/* GW->GK */
...
Add:
static void __nf_conntrack_hash_insert(struct nf_conn *ct,
unsigned int hash,
unsigned int reply_hash)
{
hlist_nulls_add_head_rcu(&ct->tuplehash[IP_CT_DIR_ORIGINAL].hnnode,
&nf_conntrack_hash[hash]);
hlist_nulls_add_head_rcu(&ct->tuplehash[IP_CT_DIR_REPLY].hnnode,
&nf_conntrack_hash[reply_hash]);
}delete
static void __nf_ct_delete_from_lists(struct nf_conn *ct)
{
struct net *net = nf_ct_net(ct);
unsigned int hash, reply_hash;
unsigned int sequence;
do {
sequence = read_seqcount_begin(&nf_conntrack_generation);
hash = hash_conntrack(net,
&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple,
nf_ct_zone_id(nf_ct_zone(ct), IP_CT_DIR_ORIGINAL));
reply_hash = hash_conntrack(net,
&ct->tuplehash[IP_CT_DIR_REPLY].tuple,
nf_ct_zone_id(nf_ct_zone(ct), IP_CT_DIR_REPLY));
} while (nf_conntrack_double_lock(net, hash, reply_hash, sequence));
clean_from_lists(ct);
nf_conntrack_double_unlock(hash, reply_hash);
}unsigned int
nf_conntrack_in(struct sk_buff *skb, const struct nf_hook_state *state)
{
enum ip_conntrack_info ctinfo;
struct nf_conn *ct, *tmpl;
u_int8_t protonum;
int dataoff, ret;
tmpl = nf_ct_get(skb, &ctinfo);
if (tmpl || ctinfo == IP_CT_UNTRACKED) {
/* Previously seen (loopback or untracked)? Ignore. */
if ((tmpl && !nf_ct_is_template(tmpl)) ||
ctinfo == IP_CT_UNTRACKED)
return NF_ACCEPT;
skb->_nfct = 0;
}
/* rcu_read_lock()ed by nf_hook_thresh */
dataoff = get_l4proto(skb, skb_network_offset(skb), state->pf, &protonum);
if (dataoff <= 0) {
pr_debug("not prepared to track yet or error occurred\n");
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
ret = NF_ACCEPT;
goto out;
}
if (protonum == IPPROTO_ICMP || protonum == IPPROTO_ICMPV6) {
ret = nf_conntrack_handle_icmp(tmpl, skb, dataoff,
protonum, state);
if (ret <= 0) {
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->_nfct)
goto out;
}
repeat:
ret = resolve_normal_ct(tmpl, skb, dataoff,
protonum, state);
if (ret < 0) {
/* Too stressed to deal. */
NF_CT_STAT_INC_ATOMIC(state->net, drop);
ret = NF_DROP;
goto out;
}
ct = nf_ct_get(skb, &ctinfo);
if (!ct) {
/* Not valid part of a connection */
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
ret = NF_ACCEPT;
goto out;
}
ret = nf_conntrack_handle_packet(ct, skb, dataoff, ctinfo, state);
if (ret <= 0) {
/* Invalid: inverse of the return code tells
* the netfilter core what to do */
pr_debug("nf_conntrack_in: Can't track with proto module\n");
nf_ct_put(ct);
skb->_nfct = 0;
/* Special case: TCP tracker reports an attempt to reopen a
* closed/aborted connection. We have to go back and create a
* fresh conntrack.
*/
if (ret == -NF_REPEAT)
goto repeat;
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
if (ret == -NF_DROP)
NF_CT_STAT_INC_ATOMIC(state->net, drop);
ret = -ret;
goto out;
}
if (ctinfo == IP_CT_ESTABLISHED_REPLY &&
!test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))
nf_conntrack_event_cache(IPCT_REPLY, ct);
out:
if (tmpl)
nf_ct_put(tmpl);
return ret;
}
EXPORT_SYMBOL_GPL(nf_conntrack_in);++ Masquerade
Nat means giving an authorized IP when leaving the internal network to the external network. Snat is to switch from the inside IP to the outside IP, and dnat is to send it to a port on a particular computer on the inside network when it comes inside from outside. Masquerade allows you to communicate with other networks like snat or dnat.
- Maike 실험 중 conntrack 오버헤드 상황 분석 (상황 분석은 했지만, 예상외로 rcv가 아닌 sender side에서 오버헤드가 큰 상황으로 파악되서 더 보고 있는 중입니다.)

who need help improving their coding skills bubble slides, daily game solve cross