데이터 추상화 / 데이터 모델
인스턴스와 스키마
데이터 베이스의 인스턴스와 스키마는 데이터베이스 분야에서 사용하는 용어인데, 프로그래밍에서의
변수의 값과타입(type)에 대응되는 유사한 개념이다. 인스턴스(instance)는 실질적인 데이터 리소스를 이야기하고, schema는 데이터베이스의 구조를 의미하니, 거의 유사한 개념이라고 봐도 될 것 같다.
데이터베이스 스키마는 데이터베이스의 논리적(추상적? 의미적?) 또는 물리적 구조(실질적 데이터)를 의미한다.구체적으로 데이터베이스 모델에 따라서 또한 데이터베이스를 보는 높이에 따라 다르다. 그러나 데이터베이스 스키마는 데이터가 저장되는 공간에 대한 구조를 표현한다는 점에서는 같다. 우선 데이터 스키마가 결정되고 나면 실제 데이터 값이 스키마 형태로 저장하고 관리되는데 데이터의 실질적인 값을 인스턴스라고 부른다.일반적으로 시간이 지나면 데이터베이스의 인스턴스는 계속 바뀌고 수정되지만, 스키마는 시간에 따라서(효율성에 따라서 바뀔 수도 있지만) 대체로 바뀌지 않는 형식이다.
데이터 추상화
일반적으로 컴퓨터과학에서는 추상화가 어떤 사물에 대한 세세한 개체로부터 중요한 개념을 분리하는 프로세스라고 길게 이야기하는데, 어떤 기능 구현을 위해서 필요한 과정들을 하나로 뭉쳐서 핵심을 볼 수 있도록 만드는 과정이다. 저번에는 밥을 먹는 과정을 이야기했지만, 이번에는 조금 컴과틱하게 예시를 들어보겠다.
가령, 정수 100보다 작고, 0보다 큰 숫자들의 모임인 n배열이 있다고 했을 때 n배열을 구해보도록 하자.
그러면 답 n을 구하고자 할때 과정의 중간 단계들이 있을 것이다.
중간 단계가 다음과 같다고 가정해보자.
- 우선 전체 0에서 100까지의 숫자를 가지고 각각의 숫자들이 소수인지 아닌지 확인해야할 것이다.
- 확인한 뒤에는 n이라는 배열 변수에 담아주어야 한다.
- 이후에 이를 출력하는 과정이 필요하다.
가볍게 적어봤다. 작은 문제를 세세히 나누려고 하니 쉽지않다. 여기에서 좀 더 나눠 본다고 하면, 두번째 소수체크 부분이 나누어진다.
2. 해당 숫자가 소수인지 확인해야 한다. (isPrime(num))
2-1. target인 num의 제곱근 범위까지 나누어 떨어지는 숫자가 1외에 있는지 확인한다.
2-1-1. 만약 1이외에 숫자가 있다면, false
2-1-2. 1이외에 숫자가 없다면, true
이렇게 세가지 과정이 되면, 중간의 소수인지 확인하는 과정을 따로 묶어 isPrime(num)과 같이 표현할 수 있다. 물론 문제를 해결하려고 할 때 알고리즘을 작성해야하는 것은 마찬가지지만, 소수를 구하는 기능이 되고나면 isPrime이라는 하나의 방법적인 도구가 된다. 이런 식으로 큰 문제에서 떨어져 나온 세부적인 사항들을 묶어서, 단순화 시켜나가는 방식이다. 데이터베이스 역시, 관련된 데이터를 묶어서 연관데이터를 구성할 수 있고, 이를 통해서 특정한 데이터베이스 구축이라는 목표를 달성할 수 있다. 내가 이해한 것이 맞는지는 모르나, 후에 더 공부하다보면 상세히 알게되리라 믿는다. 현실에서의 실눈뜨고 보기랑 비슷해보인다.
데이터 추상화 레벨
데이터베이스 시스템은 데이터베이스에 대한 추상화를 제공하는데, 추상화를 위해 관점(높이 또는 레벨)은 세 가지로 구성되어있다. 데이터베이스는 사실 컴퓨터 내부에는 물리적으로 아주 어렵게 저장되어있겠지만, 세가지 다른 관점에서 편하게 볼 수 있다. 논리적 레벨의 데이터 추상화는 데이터베이스에 저장되어 있는 데이터와 데이터간의 관계를 논리적 관점에서 추상화하는 것이다.
Type student = record
ID : string;
name : string;
department : string;
grade : string;
end;다음과 같은 스키마를 선언한다고 할 때, student는 하나의 레코드이고, ID(string 타입), name(string타입), department(string 타입), grade(string 타입) 4가지 구성요소로 이루어져있다고 선언하는 것이다.
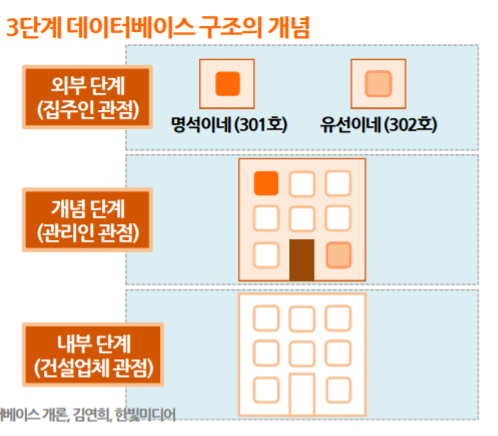
3단계 추상화
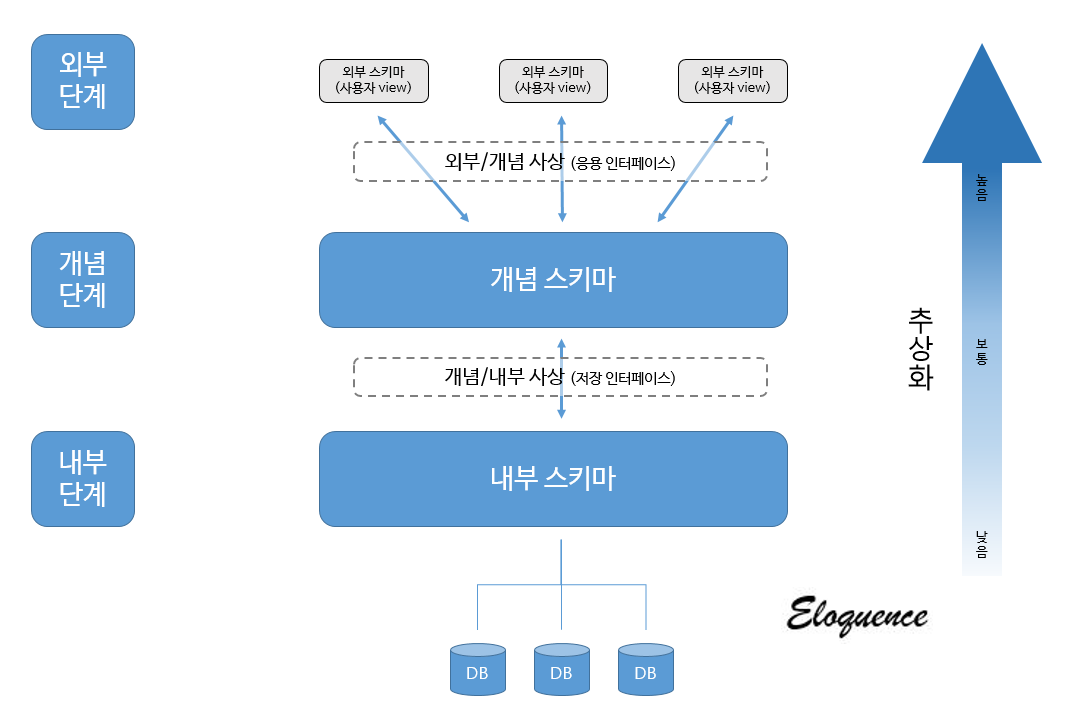
3단계 추상화를 나타낼 때, 위와 같이 나타낸다. 내부 단계를 내부 스키마 혹은 물리적 스키마라고 부르고, 개념 단계를 논리적 스키마 혹은 개념 스키마라고 부른다. 가장 최외곽을 외부 스키마 혹은 뷰 레벨이라고 부르는데, 나눠진 것이 어려운 것이지 이해하면 쉽다.
뷰 레벨에서는
개념 스키마를 이용해서 사용자가 원하는데이터 조합으로 만들어 낸 뷰를 볼 수 있다. 내가 뽑아내는 방식에 따라 뷰가 달라지기 때문에 조합은 무한에 가깝다.(그래도 조합으로 따지면 범위를 찾을 수는 있겠지만..)논리적 레벨에서는개략적인 데이터 구조를 보여준다. ID, name, department, grade와 같이 이런 데이터들을 포함하고 있다는 것을 보여준다.물리적 레벨에서는 추상화는실제 데이터 레코드가 어떻게 저장되는지를 보여주며,데이터 필드의 길이, 필드간의 간격길이, 레코드의 전체 길이와 같은 것이 들어가기도 한다.
각 레벨마다 추상화하는 방식은 DBMS마다 좀 다르기도 하지만, 기본적으로 한 데이터베이스에 기반하고 있는 정보들이라는 것이 중요하다. 어찌됐던 스키마와 뷰들이 가르키고 있는 곳은 컴퓨터에 저장되어있는 데이터 베이스 하나다. 데이터베이스에서 3단계 추상화가 성립되면, 추상화에 따라 데이터베이스 스키마를 생성하고, 그 결과 3단계 스키마 구조가 짜여진다. 각 레벨에 따른 스키마는 뷰 스키마, 논리적 스키마, 물리적 스키마로 부른다. 참고로, 3단계 스키마 구조는 1978년에 제안되었고, 일명 ANSI/SPARC 구조라고도 한다. 상용 데이터베이스는 기본적으로 3단계 스키마 구조를 지원하려고 한다.
데이터 모델(data model)
데이터 모델은 데이터, 데이터 관계성, 데이터 의미, 데이터 제약 조건 등을 기술하는 specification 또는 개념적인 도구다. 데이터 모델은 데이터 추상화를 지원하는 도구이며, 우리는 데이터 모델을 이용해서 데이터를 개념화하거나 조작할 수 있다.
데이터 모델의 종류에는 관계형 데이터 모델, 객체지향 데이터 모델, 객체관계형 데이터모델, 네트워크 데이터 모델, 계층 데이터 모델등이 있으며 또한 개체-관계 데이터 모델, XML 데이터 모델 등 다수가 제안되어있다. 네트워크 데이터 모델 및 계층(트리 구조)데이터 모델은 현대사회에서는 더이상 사용되지 않으며 이를 지원하는 구 시스템을 레거시라고 부른다. 상용 DBMS는 위에서 하나를 제공하는데 관계형 데이터모델은 관계형 데이터베이스만을 지원한다. 데이터 모델은 사용자가 데이터베이스를 보는 관점을 나타내기 때문에 데이터 모델이 다른 DBMS은 동일 데이터베이스를 저장/관리해도 서로 완전히 다른 DBMS로 보인다.
Relation 예제
| sId | name | gender | deptName | age | GPA | totalCredits |
|---|---|---|---|---|---|---|
| 152 | Eric Lee | M | CS | 22 | 3.54 | 15 |
| 201 | Alice Kim | F | AT | 24 | 3.99 | 103 |
| 301 | Jordan Park | M | Bio | 21 | 4.4 | 54 |
| 157 | Brian Kim | CS | M | 29 | 3.85 | 22 |
| 154 | Jason Ban | Media | F | 24 | 2.45 | 19 |
관계형 데이터 모델은 80년대 이후 가장 많이 사용되는 데이터 모델이며, 위의 그림은 관계형 데이터 모델의 기본 요소인 Relation(릴레이션)을 보여준다. 우리가 일반적으로 인지하고 있는 테이블 형식이다. 각 column은 속성을 의미하고, 각 row는 단일 records다.
일단 여기까지만 정리하고 넘어가자. 객체형 데이터 베이스나 NoSQL도 공부해야하고 공부해야할 것이 산더미다..
