시작하며
Binary Search Tree, 줄여서 BST는 문자 적힌대로 이해하면 '이진 탐색 트리'이라고 쓸 수 있다. 처음엔 그저 자료구조라고 생각했는데 개인적으로 자료구조로 넘어오게되면서 가장 큰 생각의 틀을 깨는 느낌을 받았던 부분이다. 자료구조 형태 자체는 단순히 값의 차등을 이용해 둘로 나누어 전체가 트리를 이루게 되는 구조인데, 이런 방식으로 알고리즘을 차용한 것이 BS(이분 탐색)이다.
차후에 만나게 되었던 Greedy나 BFS(Breadthed First Search) 나 DFS(Depth First Search), 혹은 DP(동적계획법, Danamic Programming)보다도 훨씬 충격적이었다. 수학문제나 수수께끼같은 Brain teaser를 해본지가 어언 10년차에 접어들고 있기 때문이기도 하겠고, 통상적인 것들을 직관에만 매달려오던 나로써는 약간 다른 생각을 해보자는 아이디어를 열어준 것이기도 했기 때문이다. 이제 간단하게 글을 적어내려가며, 이것의 개념에 대해서 정확히 정리하는 시간을 갖도록 하겠다.
분명히 3시에 시작하려고 했는데, HA가 끝나고 몇 시간은 영화를 보고 운동을 하며 시간을 보냈다...
자료구조인 BST는 사실 그렇게 재밌진 않고, BS라는 알고리즘이 되게 재밌다. 알고리즘에 대해서 글을 적는 곳에 시리즈로 알고리즘 문제풀이를 심심할 때해서 풀어놓으면 재밌겠다는 생각이 들었다.
BTS가 아니라 BST
Binary 이진 Search 탐색 Tree 트리. 그냥 영단어 그대로 두 갈래로 갈라져 내려오는 Tree 구조를 이르는 줄임말이다. 이게 하다보니 죄다 모든 온갖 용어들이 영어로 되어있어서 계속 헷갈린다. 이름에서 알 수 있듯이 Tree 자료구조의 일종이다. Tree가 난잡하게 배치되어있다면, 원하는 데이터를 찾으려고 할때 수많은 경우의 수를 거쳐야 할지 모른다. 만약에 기준없이 데이터를 Tree 구조로 구축했다면, 탐색을 하는데 수많은 경우를 모두 탐색해야 할 수 있다.

가령 위와 같은 트리구조가 있다고 했을때, 데이터가 기준없이 산발적으로 배치되어있다면... 상상하기도 싫다. 거기에서 효율을 찾을바에야 일렬로 배치해두고 Sort시키는게 나을지도 모른다. 언젠가 다룰지도 모르지..
자료로 보는 Binary Search Tree

아무래도 BST를 검색하게 되면 이런 이미지를 많이 볼 수 있게 되는데, 중심적인 개념을 명확하게 하고있는 이미지라고 볼 수 있다. 동그라미가 node라고 했을 때, left side에는 current 값보다 낮은 값이 매달려서 포도형태를 이루고, right side에는 current값보다 큰 값이 매달려서 포도형태를 이룬다. 이 얘기는 node에서는 항상 왼쪽에 subtree가 구성되고 오른쪽에 subtree가 구성된다는 것을 의미한다. 이 탐색이 효율적일 수 있는 이유는 범위를 줄여주기 때문이다.
예를 들어, 위의 트리에서 17을 찾는다고 했을 때 3차례의 판단과정만 거치면 17이라는 숫자에 도달할 수 있다.
- 19보다 큰가? 작은가?
- 11보다 큰가? 작은가?
- 16보다 큰가? 작은가?
만약에 값의 크기로 배치가 되어있지않고 무작위로 배치가 되어있다면, 17인지 아닌지를 물어서 노드를 전부 찾아봐야하는 상황이 펼쳐진다. 알고리즘의 효율성이라는 문제는 범위를 좁히는 것에서 시작한다. 어떤 문제가 됐든 해결하기 위해서는 내가 봐야할 케이스를 줄이는게 가장 큰 목적이라는 말이다. 물론 컴퓨터는 빨라서 아무리 많은 숫자라도 전부 순회하면서 확인하는게 어렵지 않겠지만,(아무리 긴 숫자라도 수십 초 안에는 쇼부를 볼 수 있을 것이다.) 뭔가 제공되는 서비스를 이용하는 사용자 입장에서는 1초의 지연, 2초의 지연, 더 나아가 10초의 지연이 된다면 서비스에 불만을 품을 수 있을 것이다. 그렇기 때문에 연산이나 순회를 위한 속도는 최소한으로 줄여내는 것이 가장 중요하다. BST인 이유는 2갈래로 양분해서 배치했기 때문이다. 기냐 그르냐의 갈림길의 연속이라고 보면 된다.
BST의 종류
BST는 값에 따라 갈라져서 노드가 배치되는 형태의 자료구조 Tree의 한 형식이다. Binary, 즉 2진 2갈래 길로 나누어 배치했다는 것을 이야기하는 것 뿐이다. 일종의 편의성과 효율성을 보장하기위해 배치하는 방법을 제안한 것인데, 거기에는 또 여러 종류가 있다. 이건 형태의 차이, 즉 규칙이 바뀌는 것이 아니라 포도알이 어떻게 매달려있나를 가지고 종류를 분별하는 것 뿐이다. 원칙에는 변화가 없고 그저 형태에 따라 이름을 붙인 것이다. 모두 이진트리이고, 이진 논리로 search가 가능하지만 형태가 다르다라고 이해하면 된다.
정 이진 트리(Full:proper or plane Binary Tree)
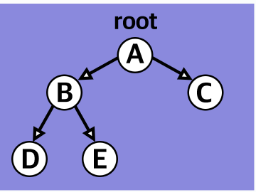
마지막 노드를 제외하고 모든 노드가 이진 형태를 이루고 있는 이진트리형태다. 쉽게 말하면 모든 노드가 0개 또는 2개의 자식노드를 가지고 있다는 이야기다. 예외없이 두갈래 길이거나 자식이 전혀 없는 노드밖에 없다.
포화 이진 트리(Perfect binary tree)
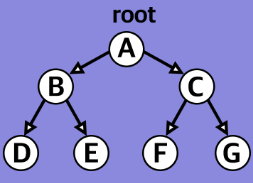
모든 노드가 2개의 자식노드로 채워져 있다. 마지막 레벨은 무조건 자식이 없고, 그 외의 모든 노드들은 두갈래의 노드를 갖는다. 마지막 Depth를 제외하곤 모두가 자식을 가지고 있다고 생각하는 것이 좋다.
완전 이진 트리(Complete binary Tree)
포화 이진트리와 비슷한데, 마지막 레벨을 제외한 모든 레벨이 완전히 채워져 있다. 차이점은 마지막 레벨의 모든 노드는 가능한 한 가장 왼쪽에 있다.라는 사실이다. 왼쪽으 치우쳐진 포화 이진트리라고 이해한다.
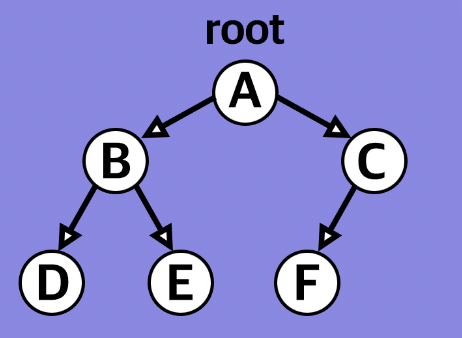
Binary Search Tree 마지막 정리
모든 왼쪽 자식들은 루트(최상단 노드)나 부모보다 작은 값이고,
모든 오른쪽 자식들은 루트나 부모보다 큰 값인 특징을 가지고 있는 이진트리를
이진 탐색 트리 라고 부른다.
마치며
원래는 BS알고리즘과 같이 다루려고했으나, BS알고리즘의 내용이 훨씬 길 것으로 예상되어 나눠서 블로깅하는 것으로 결정했다. 아무래도 알고리즘 이야기가 자료구조와 섞이면 내용도 분명해보이지 않을 뿐더러 차후에 내가 두 가지를 헷갈릴 가능성도 있기 때문이다. 일단 이건 여기에서 정리하는 것으로 하자.
이어서... 기록
