브라우저 내에서 사용되는 알고리즘
이전에 브라우저가 리소스를 가져와서 파서를 이용해서 파싱트리를 구성하고, 파싱트리를 컴파일러를 통해서 기계어로 번역하는 과정까지 살펴봤다. 그 과정에서 HTML이라는 마크업 언어는 유연하기 때문에 파싱이 어렵다는 사실까지 알았다. 그렇다면 내부에서 파싱이 일어날때 어떤 알고리즘을 이용해서 이것들을 파싱하게 되는지, 중간에는 어떤 알고리즘을 이용해서 토큰화하는지, 최종적으로는 이런 트리를 어떻게 구성하는지에 대한 알고리즘들을 간단하게 살펴보도록 하겠다.
파싱 알고리즘
HTML은 일반적인 하향식, 상향식 파싱이 안되는데 이전 글에서 살펴본 것과 마찬가지로 문법에 예외 사항이 많이 있다는 이유로 하나로 퉁치기에는 조금 성의가 부족한 것 같아 몇 가지를 살펴보자.
- 언어의 너그러운 속성, 간혹 태그가 생략되는 경우가 존재한다.
- 잘 알려져 있는 HTML 오류에 대해서 브라우저에서 미리 필터링을 한다.
- 변경에 의한 재파싱, 일반적으로 소스는 파싱하는 동안 변하지 않지만 HTMl에서 document.write를 포함하고 있는 스크립트태그는 토큰을 추가할 수 있기 때문에 실제로는 입력과정에서 파싱이 수정된다.
일반적인 파싱 기술을 사용할 수 없기 때문에 브라우저는 HTML 파싱을 위해 별도의 파서를 생성한다. 파싱 알고리즘은 HTML Documentation에 자세히 설명되어 있다. 알고리즘은 토큰화(어휘 나누기)와 트리 구축(구조로 만들기) 이렇게 두 단계로 되어 있다.
토큰화는 어휘 분석으로서 입력 값을 토큰으로 파싱한다. HTML에서 토큰은 시작 태그, 종료 태그, 속성 이름과 속성 값이다.
토큰화는 토큰을 인지해서 트리 생성자로 넘기고 다름 토큰을 확인하기 위해 다음 문자를 확인한다. 그리고 입력의 마지막까지 이 과정을 반복한다.
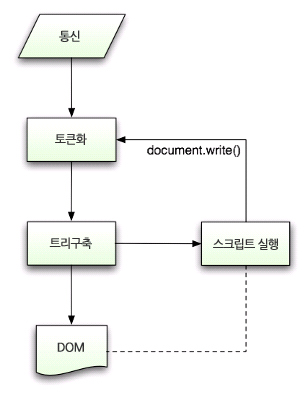
HTML 공식 문서에 나와있는 파싱 과정이다.(HTML5 명세에 나와있음)
토큰화 알고리즘
알고리즘을 돌고 난후 문서 리소스는 HTML 토큰이 된다. 알고리즘은 상태 기계(State Machine)이라고 볼 수 있다. 각 상태는 하나 이상의 연속된 문자를 입력받아 이 문자에 따라 다음 상태를 갱신한다. 그러나 결과는 현재의 토큰화 상태와 트리 구축 상태의 영향을 받는데. 이것은 같은 문자를 읽어 들여도 현재 상태에 따라 다음 상태의 결과가 다르게 나온다는 것을 의미한다. 알고리즘은 전체를 설명하기에 너무 복잡하니 원리 이해를 도울만한 간단한 예제를 한번 보자.
<html>
<body>
Hello world
</body>
</html>초기 상태는 "resource state"다. <이 문자를 만나면 '태그 열림 상태'가 된다. a부터 z까지의 문자를 만나면 '시작 태그 토큰'을 생성하고 상태는 태그 이름 상태로 변하는데 이 상태는 >문자를 만날 때까지 유지한다. 각 문자에는 새로운 토큰 이름이 붙는데 이 경우 생성된 토큰은 html토큰이 된다. (일종의 flag 상태 방식을 이용한 알고리즘인 것 같다.)
> 문자에 도달하면 현재 토큰이 발행되고 상태는 다시 자료 상태로 바뀐다. 자료 상태는 토큰화 디폴트 상태값인 것 같다. 태그는 동일한 절차에 따라 처리된다. html과 body 태그를 발행하고 다시 디폴트 상태가 됐다. Hello World의 H 문자를 만나면 문자 토큰이 생성되고 발행된다. 이것은 종료 태그의 <문자를 만날때까지 진행한다. Hello World의 각 문자에 대한 문자 토큰이 발행된다.
이후 진행은 똑같다.
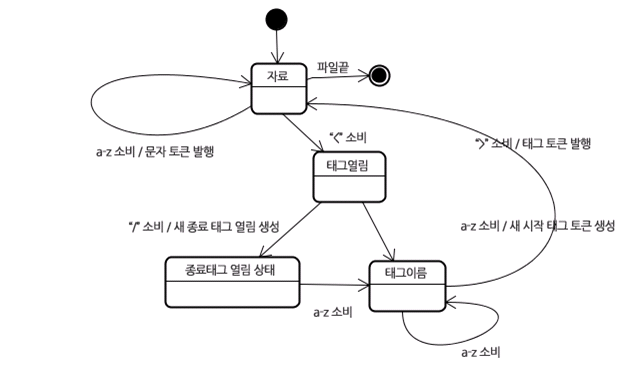
일종의 문자 번역 방식인데, 시작태그(<)와 종료태그(>)를 가지고 토큰 대상에 대한 속성을 정의내리는 방식인 것 같다.
트리 구축 알고리즘
파서가 생성되면 문서 객체가 생성된다.
트리 구축이 진행되는 동안 문서 최상단에서는 DOM트리가 수정되고 요소가 추가된다. 토큰화에 의해 생긴 노드는 트리 생성자에 의해 처리된다. 각 토큰을 위한 DOM 요소의 명세는 정의되어 있다. DOM 트리에 요소를 추가하는 것이 아니라면 열린 요소는 스택(Stack, 임시 버퍼)에 추가된다. 이 스택은 부정확한 중첩과 종료되지 않은 태그를 교정한다. 알고리즘은 상태기계라고 설명할 수 있고, 상태는 삽입모드라고 부른다.
토큰 알고리즘과 마찬가지로 동일한 예제를 통해 살펴보자.
<html>
<body>
Hello world
</body>
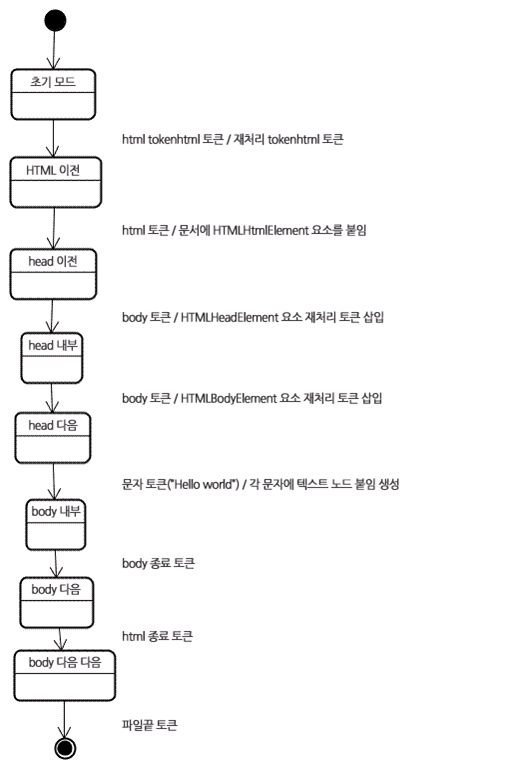
</html> 트리 구축 단계에서 입력 값은 토큰화 단계에서 만들어진 토큰들이다. 받아온 html 토큰은 html 태그 전 상태에서 읽게 되고, 토큰은 이 모드에서 처리한다. 이것은 HTMLHtmlElement 요소를 생성하고 문서 객체의 최상단에 추가된다.
상태는 head 태그 이전 모드로 바뀌고 body토큰을 받는다. head 토큰이 없어도 HTMLHeadElement는 무조건 생성되어 트리에 추가된다.
이후 head 내부 모드가 되고, 다음은 head 다음으로 바뀐다. body 토큰이 처리되고, HTMLBodyElement가 생서되어 추가되고, body 안쪽 모드가 된다.
Hello World의 문자열의 모든 문자 토큰을 받는데, 첫 번째 토큰이 생성되면 본문 노드가 추가되면서 다른 문자들이 그 노드에 추가된다. body 종료토큰을 받으면 body 다음상태가 된다. 이후 html 종료토큰을 받으면 body 다음 다음모드로 바뀐다. 마지막 파일 토큰을 모두 받으면 파싱이 종료된다.
브라우저의 오류 처리
HTML 페이지에서 "유효하지 않은 구문"이라는 오류를 본 적이 없다. 이는 브라우저가 모든 오류 구문을 교정하기 때문이다. 아래 오류가 포함된 예시를 살펴보자.
<html>
<mytag></mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
- mytag라는 존재하지 않는 태그명을 사용했다.
- p태그와 div태그는 중첩되어 있다.
그럼에도 불구하고 정상적으로 파싱이 가능한데, 그 이유는 파서가 HTML 오류를 일부 자동적으로 수정하기 때문이다.
북마크와 이전/다음 버튼 처럼 수 년간 브라우저 안에서 구현되어있는 것이다. 잘 알려진 HTML 오류를 찾을 수 있지만, 브라우저는 다른 브라우저들처럼 관습적으로 오류를 수정한다. 이는 명세에 잘 정리 되어있지만 몇 가지만 짚어보도록 하겠다.
- 어떤 태그의 안쪽에 추가하려는 태그가 금지된 것일 때 일단 허용된 태그를 먼저 닫고 금지된 태그는 외부에 추가한다.
.- 파서가 직접 요소를 추가해서는 안된다.
HTML, BODY, TBODY, TR, TD, LI같은 태그들은 생략해도 가능하다.
.- 인라인 요소 안쪽에 블록 요소가 있는 경우 부모 블록 요소를 만날 때까지 모든 인라인 태그를 닫는다.
.- 이런 방법으로 해결되지 않으면 태그를 추가하거나 무시할 수 있는 상태가 될때까지 요소를 닫는다.
<br> 대신 </br>
인터넷 익스플로러, 파이어폭스의 호환성을 위해서 이것을 대체해서 이해한다. 오류는 내부적으로 처리되고, 사용자에게 보여지지 않는다.
추가내용 기술 예정..
마치며
이번에는 브라우저 내부의 파싱 알고리즘, 토큰화 알고리즘, 마지막으로 트리 구축 알고리즘이 어떤 방식으로 작동하는지에 대해 알아봤다. 기본적으로 모든 파싱과정에서 사용되는 알고리즘들은 특정 문자 혹은 토큰을 flag 현재 상태를 구분하는 구분자 역할로 사용한다.
References
