
LLM 파인튜닝
유튜브 홍정모 교수님 강의 영상을 참고하여 진행했습니다.
허깅페이스에서 LLM 모델을 불러와 파인튜닝하는 실습입니다.
카카오에서 제공하는 한국어 모델 카나나
카카오 나노 2.1b 베이스 모델을 사용해봤습니다.
모델 준비
사용환경은 아래와 같습니다.
transformers 4.51.0
accelerate 1.6.0
pytorch 2.6.0transformer 를 통해 허깅페이스로부터 카나나 모델을 불어오겠습니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model_name = "kakaocorp/kanana-nano-2.1b-base"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=device,
attn_implementation="eager" # FlashAttention 비활성화
)
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
- 연구실 서버에서 gpu 를 사용해주었기 때문에 cuda:0 으로 gpu를 지정하여 설정해주었습니다.
- model name 과 torch type 을 지정해주고
- device_map 설정으로 위에서 지정한 gpu 에 올려준다.
- attn_implementation="eager" 로 설정해주었는데, 호환성 문제가 자꾸 발생하길래 FlashAttention(고속 Attention 최적화) 를 비활성호 하고 일반 방식을 사용했더니 호환성 문제를 피할 수 있었습니다.
- 오류 발생 시
rm -rf ~/.cache/huggingface/*를 통해 계속 캐시를 삭제하고 재실행 해보면서 진행했습니다.
데이터셋 준비
insurance_data.txt
자동차 보험이란?|자동차 보험은 차량 운행 중 발생할 수 있는 사고에 대비하여 손해를 보장받기 위한 보험입니다.
실손의료보험이란?|실손의료보험은 병원 진료비 중 본인이 부담하는 금액을 보장해주는 보험입니다.
운전자 보험은 어떤 보장을 하나요?|운전자 보험은 교통사고로 인한 형사적 책임, 벌금, 변호사 비용 등을 보장해줍니다.
종신보험과 정기보험의 차이는?|종신보험은 사망 시 보장하며 평생 유지되며, 정기보험은 일정 기간 동안만 보장됩니다.
...
- 추가로 학습시켜줄 정보를 txt로 저장해줍니다.
- 간단하게 실습만 진행할 예정이므로 많은 문장을 준비하진 않고 보험관련 정보를 20문장 정도 추가해주었습니다.
강의에서는 학습시켜야만 알 수 있는 정보("홍정모가 좋아하는 과일은?"...)를 제공하였는데 따로 보험 질의데이터를 만들어서 학습시켜보려고 이렇게 구성해봤습니다..
학습 준비
fine tunning 을 진행하기 전에 기존 모델의 응답을 확인해보는 과정입니다.
입력 준비
# 파인튜닝 전에 어떻게 응답하는지 확인
questions = [ qna['q'] for qna in qna_list]
questions.append("너에 대해서 설명해봐.")
questions.append("이처럼 인간처럼 생각하고 행동하는 AI 모델은 ")
questions.append("인공지능의 장점은")
questions.append("생명보험에 대해서 얘기해봐.")
questions.append("자동차보험에 대해서 얘기해봐.")
questions.append("암보험 지급기준은?.")
questions.append("손해보험.")
questions.append("보험은 어떻게 가입해?")
보험 질문에 대해서 좀 더 추가해주었습니다.
모델 입력 만들기 (tokenizer 활용)
# 모델 입력 만들기
input_ids = tokenizer(
questions,
padding=True,
return_tensors="pt",
)["input_ids"].to(device)
# print(type(model))transformers 라이브러리의 tokenizer를 사용하여 입력 시퀀스를 준비합니다.
패딩을 추가하고, GPU에 올릴 준비도 합니다.
모델 생성 및 출력
model.eval()
with torch.no_grad():
output = model.generate(
input_ids,
max_new_tokens=64, #64토큰으로 수정
do_sample=False,
)
output_list = output.tolist()
for i, output in enumerate(output_list):
print(f"Q{i}: {tokenizer.decode(output, skip_special_tokens=True)}\n")model.generate()를 통해 각 질문에 대한 응답을 생성합니다.
여기서는 샘플링 없이 단순 greedy decoding을 사용하며, 최대 64 토큰까지만 생성합니다.
do sample = False로 설정해서 샘플링을 일단 비활성화 해줍니다.
- false로 설정하면 확률이 가장 높은 토큰만 매번 고르는 방식이 되고
가장 확신 있는 단어만 골라서 출력하게 됩니다.- 만약 True 로 설정하면 창의적인 답변이 나올 수 있습니다..
출력
Q0: 자동차 보험이란? 자동차보험은 자동차 사고로 인한 피해를 보상하기 위해 가입하는 보험입니다. 자동차보험은 자동차 소유자와 운전자, 그리고 제3자(타인)에게 발생하는 사고에 대해 보상해주는 보험입니다. 자동차보험은 크게 자기차량손
Q1: 실손의료보험이란? 1. 실손의료보험의 정의 실손의료보험은 의료비를 보장하는 보험으로, 환자가 병원에서 치료를 받을 때 발생하는 의료비를 보상해주는 보험입니다. 실손의료보험은 보험 가입자가 병
Q2: 운전자 보험은 어떤 보장을 하나요? 1. 자동차보험과 자동차보험의 차이점은 무엇인가요? 자동차보험은 자동차를 소유하고 있는 사람이나 자동차를 운전하는 사람을 대상으로 하는 보험입니다. 자동차보험은 자동차의 손해를 보상하는 보험으로, 자동차의 손해를 보상
Q3: 종신보험과 정기보험의 차이는? 1. 보험기간의 차이 보험기간은 보험계약이 유효한 기간을 말합니다. 보험기간은 보험계약의 종류에 따라 다르며, 보험기간이 길수록 보험료가 비싸집니다. 2.
Q4: 치아보험은 어떤 경우 보장되나요? 치아보험은 치아의 손상이나 질병으로 인한 치료비를 보장하는 보험입니다. 치아보험은 치아의 손상이나 질병으로 인한 치료비를 보장하는 보험입니다. 치아보험은 치아의 손상이나 질
Q5: 보험을 가입할 때 유의할 점은? 1. 보험료가 저렴한 상품을 선택한다. 2. 보험료가 저렴한 상품을 선택한다. 3. 보험료가 저렴한 상품을 선택한다. 4. 보험료가 저렴한 상품을 선택한다. 5. 보
Q6: 보험금 청구는 어떻게 하나요? 1. 청구권자 : 채권자(채무자) 2. 청구방법 : 채권자가 채무자에게 직접 청구 3. 청구기간 : 채권자가 채무자에게 청구하는 경우에는 채권자가 채무자에게 청구하는 날로부터
Q7: 면책기간이란? 1. 법률상으로는 3년, 2. 행정상으로는 5년, 3. 민사상으로는 10년 4. 형사상으로는 7년 5. 행정상으로는 5년 6. 민사상으로는
Q8: 암 진단 시 보험금은 바로 지급되나요? 암 진단 시 보험금은 바로 지급되나요? 암 진단 시 보험금은 바로 지급되나요? 암 진단 시 보험금은 바로 지급되나요? 암 진단 시 보험금은 바로 지급되나요? 암 진단 시 보험금은
Q9: 중도 해지 시 환급금은 얼마인가요? 중도 해지 시 환급금은 얼마인가요? 중도 해지 시 환급금은 얼마인가요? 중도 해지 시 환급금은 얼마인가요? 중도 해지 시 환급금은 얼마인가요? 중도 해지 시 환급금은 얼마인가요
Q10: 태아보험이란? 1. 보험의 정의 보험은 위험을 분산시키고, 위험에 대한 대비를 하기 위해 보험료를 지불하고, 보험사로부터 보험금을 받는 제도입니다. 보험은 개인, 기업, 국가 등 다양한 주체가
Q11: 보험료는 어떤 기준으로 산정되나요? 1. 자동차보험료는 보험사마다 다르지만, 일반적으로 다음과 같은 기준으로 산정됩니다. 1) 차량의 종류: 차량의 종류에 따라 보험료가 다르게 책정됩니다. 예를 들어, 승용차, SUV, 트럭 등
Q12: 계약 전 알릴 의무란 무엇인가요? 계약 전 알릴 의무는 계약 당사자 중 한쪽이 상대방에게 계약 체결 전에 알릴 의무를 가지는 것을 말합니다. 이는 계약 체결 전에 상대방에게 중요한 정보를 제공하여 계약의 공정성을 확보하고, 계약 체결 후 발생할 수 있는 분
Q13: 실손보험에서 비급여 항목이란? 실손보험에서 비급여 항목이란? 실손보험에서 비급여 항목은 보험사가 보장하지 않는 항목을 말합니다. 비급여 항목은 보험사가 보장하지 않기 때문에 보험 가입자가 직접 부담해야 합니다. 비급여 항
Q14: 운전자 보험과 자동차 보험의 차이는? 운전자 보험과 자동차 보험은 모두 운전자와 자동차를 보호하기 위한 보험입니다. 그러나 이 두 보험은 목적과 범위에서 차이가 있습니다. 운전자 보험은 운전자의 신체적 손해를 보상하는 보험입니다. 운전 중 발생하는
Q15: 보험계약 갱신은 자동으로 되나요? 보험계약 갱신은 자동으로 되나요? 보험계약 갱신은 자동으로 되나요? 보험계약 갱신은 자동으로 되나요? 보험계약 갱신은 자동으로 되나요? 보험계약 갱신은 자동으로 되나요
Q16: 가입한 보험을 다른 사람에게 양도할 수 있나요? 보험은 가입한 사람의 신분을 확인하고 보험료를 납부하는 것이 원칙입니다. 따라서 보험을 다른 사람에게 양도하는 것은 불법입니다. 보험을 양도하는 경우에는 보험료를 납부하지 않아도 되지만, 보
Q17: 가입 후 바로 보험 혜택을 받을 수 있나요? 보험 가입 후 바로 보험 혜택을 받을 수 있는 경우도 있지만, 일부 보험 상품은 일정 기간이 지난 후에 혜택을 받을 수 있는 경우도 있습니다. 보험 상품의 약관을 자세히 살펴보고, 보험 혜택을
Q18: 환급형 보험이란? 보험은 크게 보장형과 저축형으로 나뉩니다. 보장형 보험은 보험료를 내고 보험사로부터 보험금을 받는 형태로, 보험사에서 정한 보험금을 받을 수 있는 권리를 보장받
Q19: 보험 청약 철회는 언제까지 가능한가요? 보험 청약 철회는 보험 계약 체결 후 15일 이내에 가능합니다. 이 기간 동안에는 보험료를 환불받을 수 있으며, 보험 계약을 철회할 수 있습니다. 3. 보험 청약 철회 시 주의사항
Q20: 너에 대해서 설명해봐. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21.
Q21: 이처럼 인간처럼 생각하고 행동하는 AI 모델은 2016년 알파고가 등장하면서 본격적으로 주목받기 시작했다. 알파고는 딥러닝을 기반으로 한 인공지능 바둑 프로그램으로, 구글 딥마인드가 개발했다. 알파고는 2016년 3월 이세돌
Q22: 인공지능의 장점은 무엇인가요? 1. 인공지능은 인간의 지능을 모방하여 다양한 작업을 수행할 수 있습니다. 예를 들어, 인공지능은 자연어 처리, 이미지 인식, 음성 인식, 게임 플레이 등 다양한 작업을 수행할 수 있습니다. 2. 인공지
Q23: 생명보험에 대해서 얘기해봐. 1. 생명보험의 개념과 종류 2. 생명보험의 특징 3. 생명보험의 장점 4. 생명보험의 단점 5. 생명보험의 종류 6. 생명보험의 가입방법 7. 생명보험의
Q24: 자동차보험에 대해서 얘기해봐. 1. 자동차보험은 자동차를 소유하고 있는 사람이라면 누구나 가입해야 하는 의무보험입니다. 2. 자동차보험은 자동차 사고가 발생했을 때 피해자에게 보상을 해주는 보험입니다. 3. 자동차보험은 자동차 사고가 발생했을 때
Q25: 암보험 지급기준은?. 1. 보험료를 납입한 날로부터 1년이 경과한 날 2. 보험료를 납입한 날로부터 1년이 경과한 날부터 3년이 되는 날 3. 보험료를 납입한 날로부터 1
Q26: 손해보험. 3. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20.
Q27: 보험은 어떻게 가입해? 1. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20.
어느 정도는 결과가 잘 나오는데
- 중간에 1.2.3. 이런식으로 제대로 생성되지 않는 경우
- 답변의 무의미한 중복, 반복이 일어나는 경우가 있습니다.
그럼 학습 이후의 결과와 비교해보면 좋을 것 같습니다.
데이터셋 클래스 및 로더 정의
import torch
from torch.utils.data import Dataset, DataLoader
EOT = 128001 # instruct 모델과 다름
class MyDataset(Dataset):
def __init__(self, qna_list, max_length):
self.input_ids = []
self.target_ids = []
for qa in qna_list:
token_ids = qa['input_ids']
input_chunk = token_ids
target_chunk = token_ids[1:]
input_chunk += [EOT]* (max_length - len(input_chunk))
target_chunk += [EOT]* (max_length - len(target_chunk))
len_ignore = len(qa['q_ids']) - 1 # target은 한 글자가 짧기 때문
target_chunk[:len_ignore] = [-100] * len_ignore
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
dataset = MyDataset(qna_list, max_length=max_length)
train_loader = DataLoader(dataset, batch_size=2, shuffle=True, drop_last=False)
- EOT 토큰이 128001 이므로 설정해줍니다.
(현재는 base 모델이므로 base 모델에 맞는 토큰 ID 값을 사용합니다.)- PyTorch의 Dataset 클래스를 상속받아 사용자 정의 데이터셋을 만듭니다.
- qna_list (질문-답변 쌍 리스트)와 max_length(최대 시퀀스 길이)를 입력받습니다.
- MyDataset 객체를 이용해 DataLoader를 생성합니다.
- DataLoader는 데이터를 지정된 batch_size만큼 묶어주고, 학습 시 데이터를 무작위로 섞어주며(shuffle=True), 병렬 처리 등을 통해 효율적인 데이터 로딩을 돕습니다.
- 여기서 batch_size 는 2입니다.
- drop_last=False는 마지막 배치의 크기가 batch_size보다 작더라도 해당 배치를 사용하여 학습을 진행하도록 합니다.
데이터 로더 확인 (Verifying the DataLoader)
본격적인 학습 전에
DataLoader가 의도한 대로 데이터를 잘 만들어서 반환하는지 첫 번째 배치를 뽑아 확인해보는 과정입니다.
특히,MyDataset에서 구현한 입력(input_ids)과 타겟(target_ids), 그리고 타겟에서의 마스킹(-100) 처리가 잘 되었는지 확인합니다.
i = iter(train_loader)
x, y = next(i)
y_temp = y[0].tolist()
y_temp = [x for x in y_temp if x != -100] # -100은 제외하고 디코딩
print(tokenizer.decode(x[0].tolist()))
print(tokenizer.decode(y_temp))
-
i = iter(train_loader):
DataLoader 객체는 이터러블(iterable)이므로, iter() 함수를 사용해 이터레이터(iterator)를 만듭니다. 이터레이터를 사용하면 next() 함수를 호출하여 데이터를 배치 단위로 순차적으로 가져올 수 있습니다. -
x, y = next(i):
이터레이터i에서 다음(첫 번째) 배치(batch) 데이터를 가져옵니다.MyDataset의__getitem__이(input_ids, target_ids)튜플을 반환하도록 정의했으므로,x에는 입력 ID들의 배치(텐서)가,y에는 타겟 ID들의 배치(텐서)가 할당됩니다. -
y_temp = y[0].tolist():
배치y에서 첫 번째 샘플(y[0])을 선택하고, 이를 PyTorch 텐서에서 파이썬 리스트로 변환합니다. 이 리스트에는 질문 부분에 해당하는-100값과 답변 부분의 실제 토큰 ID, 그리고 패딩 토큰 ID(EOT)가 포함되어 있습니다. -
y_temp = [token_id for token_id in y_temp if token_id != -100]:
리스트 컴프리헨션(list comprehension)을 사용하여y_temp리스트에서 값이-100이 아닌 요소들만 포함하는 새로운 리스트를 만듭니다. 이는MyDataset에서 설정한 손실 마스킹(loss masking)이 제대로 적용되었는지 확인하고, 실제 모델이 학습해야 할 목표(답변) 부분만 분리하기 위함입니다. -
print(tokenizer.decode(x[0].tolist())):
첫 번째 입력 샘플(x[0])을 다시 텍스트로 디코딩(decoding)하여 출력합니다. 이 출력은 모델이 입력으로 받는 전체 시퀀스 (질문 + 답변 + 패딩)를 보여주므로, 토큰화와 패딩이 예상대로 되었는지 확인할 수 있습니다. -
print(tokenizer.decode(y_temp)):
-100이 제거된 타겟 시퀀스(y_temp)를 텍스트로 디코딩(decoding)하여 출력합니다. 이 출력은 모델이 최종적으로 생성하도록 학습되는 순수 답변 부분만을 보여주어야 합니다. 만약 이 부분에 질문 내용이 포함되어 있거나 예상과 다른 결과가 나온다면MyDataset의 로직, 특히 마스킹 부분을 다시 확인해야 합니다.
optimizer 설정
import torch
print(device)
torch.manual_seed(42)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001, weight_decay=0.01)
- adam 사용, lr = 0.00001
일반적으로 머신러닝 모델, 특히 딥러닝 모델을 학습시킬 때는 준비된 데이터를 훈련(Train) 세트와 검증(Validation) 세트(그리고 때로는 테스트(Test) 세트)로 나누어 진행하지만
하지만 이번 실습에서 사용한
insurance_data.txt데이터는 약 20개의 질문-답변 쌍이므로 validation 없이 진행했습니다.
학습 루프 구현 (Implementing the Training Loop)
이제 모든 준비가 끝났으니, 모델 파인튜닝을 위한 실제 학습 루프를 작성합니다. 이 루프는 여러 에포크(epoch)에 걸쳐 실행되며, 각 에포크마다 전체 훈련 데이터를 사용하여 모델 파라미터를 업데이트합니다.
tokens_seen, global_step = 0, -1
losses = []
for epoch in range(10):
model.train() # Set model to training mode
epoch_loss = 0
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch).logits # 뒤에 .logits를 붙여서 tensor만 가져옴
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
epoch_loss += loss.item()
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
tokens_seen += input_batch.numel()
global_step += 1
print(f"{global_step} Tokens seen: {tokens_seen}")
avg_loss = epoch_loss / len(train_loader)
losses.append(avg_loss)
print(f"Epoch: {epoch}, Loss: {avg_loss}")
torch.save(model.state_dict(), "model_" + str(epoch).zfill(3) + ".pth")
optimizer.zero_grad(): 이전 계산에 사용된 기울기 정보를 없앱니다- loss 계산:
cross_entropy를 통해 모델 예측과 실제 정답 사이의 오차(손실)를 계산합니다- 기울기 계산:
loss.backward()사용- 모델 업데이트:
optimizer.step()
import matplotlib.pyplot as plt
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.show()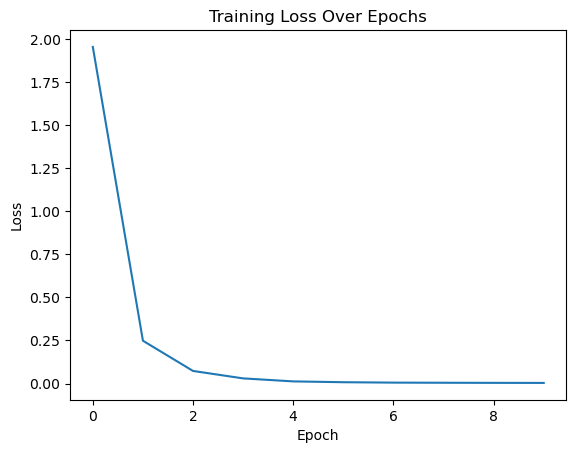
validation은 없지만 loss가 줄어드는 것을 통해 훈련이 잘 되었다고 확인할 수 있습니다.
결과 확인
파인튜닝 전후 결과 비교 및 분석
model.load_state_dict(torch.load("model_009.pth", map_location=device, weights_only=True))
model.eval()questions = [ qna['q'] for qna in qna_list]
questions.append("너에 대해서 설명해봐.")
questions.append("이처럼 인간처럼 생각하고 행동하는 AI 모델은 ")
questions.append("인공지능의 장점은")
questions.append("생명보험에 대해서 얘기해봐.")
questions.append("자동차보험에 대해서 얘기해봐.")
questions.append("암보험 지급기준은?.")
questions.append("손해보험.")
questions.append("보험은 어떻게 가입해?")
for i, q in enumerate(questions):
input_ids = tokenizer(
q,
padding=True,
return_tensors="pt",
)["input_ids"].to(device)
# print(type(model))
model.eval()
with torch.no_grad():
output = model.generate(
input_ids,
max_new_tokens=32,
attention_mask = (input_ids != 0).long(),
pad_token_id=tokenizer.eos_token_id,
do_sample=False,
# temperature=1.2,
# top_k=5
)
output_list = output.tolist()
print(f"Q{i}: {tokenizer.decode(output[0], skip_special_tokens=True)}")
위에서 처럼 qna set에서 questions를 가져오고 추가로 테스트할 질문을 추가해준다.
결과를 확인해보자
Q0: 자동차 보험이란? 자동차 보험은 차량 운행 중 발생할 수 있는 사고에 대비하여 손해를 보장받기 위한 보험입니다.
Q1: 실손의료보험이란? 실손의료보험은 병원 진료비 중 본인이 부담하는 금액을 보장해주는 보험입니다.
Q2: 운전자 보험은 어떤 보장을 하나요? 운전자 보험은 교통사고로 인한 형사적 책임, 벌금, 변호사 비용 등을 보장해줍니다.
Q3: 종신보험과 정기보험의 차이는? 종신보험은 사망 시 보장하며 평생 유지되며, 정기보험은 일정 기간 동안만 보장됩니다.
Q4: 치아보험은 어떤 경우 보장되나요? 치아보험은 충치 치료, 보철, 임플란트 등에 대한 비용을 보장해줍니다.
Q5: 보험을 가입할 때 유의할 점은? 보장 내용, 면책 사항, 납입 기간, 해지 환급금 등을 반드시 확인해야 합니다.
Q6: 보험금 청구는 어떻게 하나요? 병원 진료 후 필요한 서류를 보험사에 제출하면 보험금을 청구할 수 있습니다.
Q7: 면책기간이란? 면책기간은 보험 가입 후 일정 기간 동안 보장이 적용되지 않는 기간입니다.
Q8: 암 진단 시 보험금은 바로 지급되나요? 약관에 따라 진단 확정일 기준으로 보험금이 지급되며, 면책기간 경과 후 지급됩니다.
Q9: 중도 해지 시 환급금은 얼마인가요? 해지 시점에 따라 다르며, 초기 해지의 경우 환급금이 없을 수 있습니다.
Q10: 태아보험이란? 태아보험은 임신 중에 가입하여 출산 및 출생 후 아이의 질병과 사고를 보장하는 보험입니다.
Q11: 보험료는 어떤 기준으로 산정되나요? 연령, 성별, 건강 상태, 보험 상품 유형 등에 따라 보험료가 결정됩니다.
Q12: 계약 전 알릴 의무란 무엇인가요? 보험 가입자는 자신의 건강 상태나 병력 등을 사실대로 알려야 할 의무가 있습니다.
Q13: 실손보험에서 비급여 항목이란? 국민건강보험에서 보장하지 않는 진료 항목으로, 일부는 실손보험에서도 제외됩니다.
Q14: 운전자 보험과 자동차 보험의 차이는? 자동차 보험은 차량 사고 보장, 운전자 보험은 운전자 본인의 법적 책임 보장입니다.
Q15: 보험계약 갱신은 자동으로 되나요? 일부 갱신형 보험은 자동 갱신되며, 약관에 따라 다릅니다.
Q16: 가입한 보험을 다른 사람에게 양도할 수 있나요? 일반적으로 보험 계약은 타인에게 양도할 수 없습니다.
Q17: 가입 후 바로 보험 혜택을 받을 수 있나요? 보통 면책기간이 있으며, 해당 기간 경과 후 보장이 시작됩니다.
Q18: 환급형 보험이란? 보험 기간 종료 시 납입한 보험료의 일부 또는 전부를 환급해주는 보험입니다.
Q19: 보험 청약 철회는 언제까지 가능한가요? 일반적으로 계약일로부터 15일 이내에는 청약 철회가 가능합니다.
Q20: 너에 대해서 설명해봐.
Q21: 이처럼 인간처럼 생각하고 행동하는 AI 모델은 2023년 현재에도 계속 발전하고 있으며, 앞으로 더 많은 분야에서 활용될 것으로 예상됩니다.
Q22: 인공지능의 장점은 무엇인가요? 인공지능은 대량의 데이터를 분석하고 패턴을 파악하여 정확한 예측을 할 수 있습니다.
Q23: 생명보험에 대해서 얘기해봐. 생명보험은 사망 시 보장하며, 사망보험, 질병보험, 연금보험 등이 있습니다.
Q24: 자동차보험에 대해서 얘기해봐. 자동차 보험에 대해서 얘기해 보겠습니다. 자동차 보험은 차량 운행 중 발생할 수 있는 사고에 대비하여 손해를 보장받기 위한 보
Q25: 암보험 지급기준은?. 암 진단 확정일 기준으로 보장되며, 면책기간 경과 후 지급됩니다.
Q26: 손해보험은 사고 발생 시 보장해주는 보험으로, 자동차 보험, 건강보험 등이 있습니다.
Q27: 보험은 어떻게 가입해? 보통 은행이나 보험사에서 가입할 수 있습니다.
- 이번 파인튜닝은 매우 작은 데이터셋(20개 Q&A)만 사용했음에도 불구하고 목표했던 보험 관련 질문에 대한 답변 성능이 향상됨을 확인했습니다.
- 모델은 주어진 데이터의 스타일과 내용을 정확히 학습했으며, 무의미한 반복이나 부적절한 형식의 답변을 생성하던 문제점을 해결했습니다. 또한, 관련 도메인 내의 새로운 질문에 대해서도 향상된 답변 능력을 보여주었습니다.
- 물론 학습하지 못한 부분에 대해서는 여전히 답을 하지 못하는 결과가 있습니다.
모델과 직접 대화하기 (Interactive Session with the Model)
이제 미리 준비된 질문 리스트 대신, 사용자가 직접 질문을 입력하고 파인튜닝된 모델이 어떻게 답변하는지 실시간으로 확인해 볼 수 있는 코드를 살펴보겠습니다.
input_ids = tokenizer(
input(),
padding=True,
return_tensors="pt",
)["input_ids"].to(device)
# print(type(model))
model.eval()
with torch.no_grad():
output = model.generate(
input_ids,
max_new_tokens=32,
attention_mask = (input_ids != 0).long(),
pad_token_id=tokenizer.eos_token_id,
do_sample=False,
# temperature=1.2,
# top_k=5
)
output_list = output.tolist()
print(f"Q{i}: {tokenizer.decode(output[0], skip_special_tokens=True)}")이렇게 직접 테스트 해볼 수 있습니다.
결론
결론적으로, 제한된 자원과 데이터로도 특정 목적에 맞게 LLM을 효과적으로 파인튜닝할 수 있음을 배웠습니다.
비록 매우 작은 데이터셋을 사용한 실습이었지만, LLM 파인튜닝이 특정 도메인이나 작업 스타일에 모델을 효과적으로 적응시키는 강력한 방법임을 확인할 수 있었습니다. 적은 데이터로도 목표했던 보험 Q&A 성능을 눈에 띄게 개선할 수 있었으며, 모델의 문제점을 해결하는 효과도 보았습니다.
또한, 이번 실습에서는 데이터셋 크기의 한계와 검증 세트의 부재로 인해 모델의 일반화 성능이나 과적합 여부를 정량적으로 평가하기는 어려웠습니다.
향후 더 많은 데이터 확보, 검증 및 테스트 세트 도입 등을 통해 모델 성능을 더욱 개선하보는 실습도 진행해보면 좋을 것 같습니다.
참고한 자료입니다.
https://youtu.be/NrDZmSDvXXw?si=Vx7QZO0s_bqth4AK
https://github.com/HongLabInc/HongLabLLM
