의료 상담 요약에 RAG를 적용해봤습니다 (with Gemma 3 1B)
최근에 데이터사이언스 수업에서, Gemma 3 1B-it 모델을 활용해서 마취통증의학과의 진료 상담 내용을 요약하는 프로젝트를 진행했습니다. 단순 요약이 아니라, 의료 상담 대화에서 키워드를 뽑고, 해당 키워드에 기반한 관련 정보 검색, 그리고 이를 바탕으로 LLM이 문맥 있게 요약하도록 만드는 Retrieval-Augmented Generation(RAG) 방식을 적용해봤습니다.
프로젝트 개요
목표
의료 상담 내용을 다음과 같은 양식으로 자동 요약하는 것이 목표였습니다:
- 증상
- 진단
- 치료
- 특이사항
- 환자 반응
주요 흐름
- Whisper를 이용해 음성 진료 대화를 텍스트로 전사
- 키워드 추출 → 오타 교정 → 관련 문서 검색
- 검색된 문서 기반으로 LLM이 구조화된 요약 생성
RAG란?
RAG는 Retrieval-Augmented Generation의 줄임말로, LLM이 외부 지식(문서, 데이터 등)을 검색하고 이를 기반으로 응답을 생성하도록 돕는 프레임워크입니다. 단순히 프롬프트에 다 넣기엔 LLM의 context window가 제한되어 있기 때문에, 관련 있는 정보만 찾아서 넣어주는 방식입니다.
사용 기술
- LLM:
google/gemma-3-1b-it- 로컬에서 돌리기 위해서 작은 모델을 사용했습니다.
- Embedding Model:
nlpai-lab/KURE-v1- 의료 ai 특성상 보안문제 때문에 임베딩 모델을 불러와 사용했습니다.
- openai 모델을 사용하면 성능이 더 좋을 것 같습니다.
- 검색 인덱스: FAISS
- PDF 텍스트 추출: PyMuPDF
- PDF에서 의료 문서 추출
- FastAPI + Ngrok: API 서버 및 외부 접속용
전체 구조
-
PDF 문서에서 텍스트 추출 (온누리 마취통증의학과의원 관련 내용)
-
텍스트를 청크로 분할 → 임베딩 생성
-
FAISS 인덱스에 벡터 저장
-
사용자가 입력한 진료 내용을 기반으로:
- 키워드 추출 (LLM 기반)
- 키워드 오타 교정 (Jamo + Levenshtein)
- 각 키워드로 관련 문서 검색 (FAISS)
- 검색된 문맥을 기반으로 요약 생성 (Gemma 3 LLM)

주요 코드 스니펫 예시
PDF에서 텍스트 추출 후 청크 분할
import fitz
def extract_text_from_pdf(path):
doc = fitz.open(path)
texts = [page.get_text().strip() for page in doc if page.get_text().strip()]
return "\n".join(texts)
def split_chunks(text, max_len=200):
paras = text.split("\n")
chunks, current = [], ""
for para in paras:
if len(current) + len(para) < max_len:
current += " " + para
else:
chunks.append(current.strip())
current = para
if current:
chunks.append(current.strip())
return chunksFAISS 인덱스 생성
def build_faiss_index(pdf_path, save_path):
raw_text = extract_text_from_pdf(pdf_path)
chunks = split_chunks(raw_text)
vectors = embed_model.encode(chunks)
index = faiss.IndexFlatL2(vectors.shape[1])
index.add(np.array(vectors))
if not os.path.exists(save_path): os.makedirs(save_path)
faiss.write_index(index, os.path.join(save_path, "index.faiss"))
with open(os.path.join(save_path, "texts.txt"), "w", encoding="utf-8") as f:
for c in chunks:
f.write(c + "\n")
print(f"완료: {len(chunks)} chunks 저장됨.")검색 함수
def search_faiss(query, top_k=3):
index = faiss.read_index(os.path.join(INDEX_PATH, "index.faiss"))
with open(os.path.join(INDEX_PATH, "texts.txt"), encoding="utf-8") as f:
texts = f.readlines()
query_vec = embed_model.encode([query])
D, I = index.search(np.array(query_vec), top_k)
return [texts[i].strip() for i in I[0]]
LLM 모델
키워드 추출
전문적인 의료 키워드를 오타까지 감안해서 추출합니다. 프롬프트를 세심하게 설계하고, 모델이 너무 일반적인 단어를 포함하지 않도록 제어했습니다.
import torch._dynamo
import re
torch._dynamo.disable()
def extract_keywords(text):
prompt = f"""마취통증의학과의원의 진료 내용을 이해하지 못하겠는 전문 용어 키워드(진단, 치료, 분석 용어) 알려줘 중요한 키워드지만 오타가 난 듯한 키워드도 뽑아줘 없다면 '없음'이라고 해 다른 말은 하지마.
※ 단, 순번(1. 2. (1), (2), 같은 순서)은 절대 매기면 안되고, 너무 일반적인 단어(예: 운동, 걷기, 계단 등)는 제외하고 전문의만 알 수 있는 RAG를 통해 문서검색이 필요한 키워드를 반드시 알려줘.
진료 내용:
{text}
키워드 목록:
"""
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.inference_mode():
output = llm.generate(**inputs, max_new_tokens=256)
result = tokenizer.decode(output[0], skip_special_tokens=True)
# 후처리
keywords = []
for line in result.splitlines():
line = line.strip()
if not line or len(line) > 30 or "진료" in line or ":" in line:
continue
# 순번 제거 (예: 1. 키워드 → 키워드)
keyword = re.sub(r"^[\d]+[.\)]\s*", "", line) # 1. 키워드 / 1) 키워드
keyword = keyword.lstrip("-*•").strip()
if keyword and keyword not in keywords:
keywords.append(keyword)
return keywords요약
키워드 기반 내용을 바탕으로 요약을 진행합니다
def base_summary(treatment_text):
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "당신은 마취통증의학과 전문의입니다. 아래 상담 내용을 요약해 주세요. 형식은 다음과 같습니다:\n\n- 증상:\n- 진단:\n- 치료:\n- 특이사항:\n- 환자 반응:\n\n반드시 이 형식만 지켜서 출력하세요. 참고정보는 반드시 등장한 키워드가 어떤 용어인지 이해하는 용도로만 사용하고, 특히 증상은 통증부위, 지속기간, 동반 증상 등이고, 진단은 해부학적 문제, 검사 결과 요약을 넣어주고, 치료는 병행 치료 계획이나 치료관련 요약해주세요. 진료내용에 등장하지 않은 내용에 대한 참고자료는 요약 생성에 절대 사용하지 말아주세요. 추출한 키워드는 오타가 날 수 있으니 참고자료를 이용해 수정해주세요"}]
},
{
"role": "user",
"content": [{"type": "text", "text": f"[진료 내용]\n{treatment_text}"}]
}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True
).to(DEVICE)
with torch.inference_mode():
output = llm.generate(
**inputs,
max_new_tokens=1024,
temperature=0.2,
top_p=1.0,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
result = tokenizer.decode(output[0], skip_special_tokens=True)
return extract_model_response(result)
FastAPI + ngrok 적용
FastAPI로 API 서버를 구성하고, ngrok으로 외부에서 접근할 수 있게 만들었습니다.
API 서버 코드
from fastapi import FastAPI
from pydantic import BaseModel
from fastapi.responses import JSONResponse
from pyngrok import ngrok
import torch
app = FastAPI()
class InputText(BaseModel):
script: str
@app.post("/summarize")
async def summarize(request: InputText):
text = request.script
raw_keywords = extract_keywords(text)
summary = generate_summary(text, raw_keywords)
return {"summary": summary}
@app.get("/")
def read_root():
return JSONResponse(content={"message": "Gemma 3 의료 요약 API입니다"})ngrok 설정
ngrok.set_auth_token("<your_token>")
public_url = ngrok.connect(addr=8000, domain ="<your_static_domain>")
print("ngrok URL:", public_url)이렇게 하면 스태틱 도메인으로 설정할 수 있다.
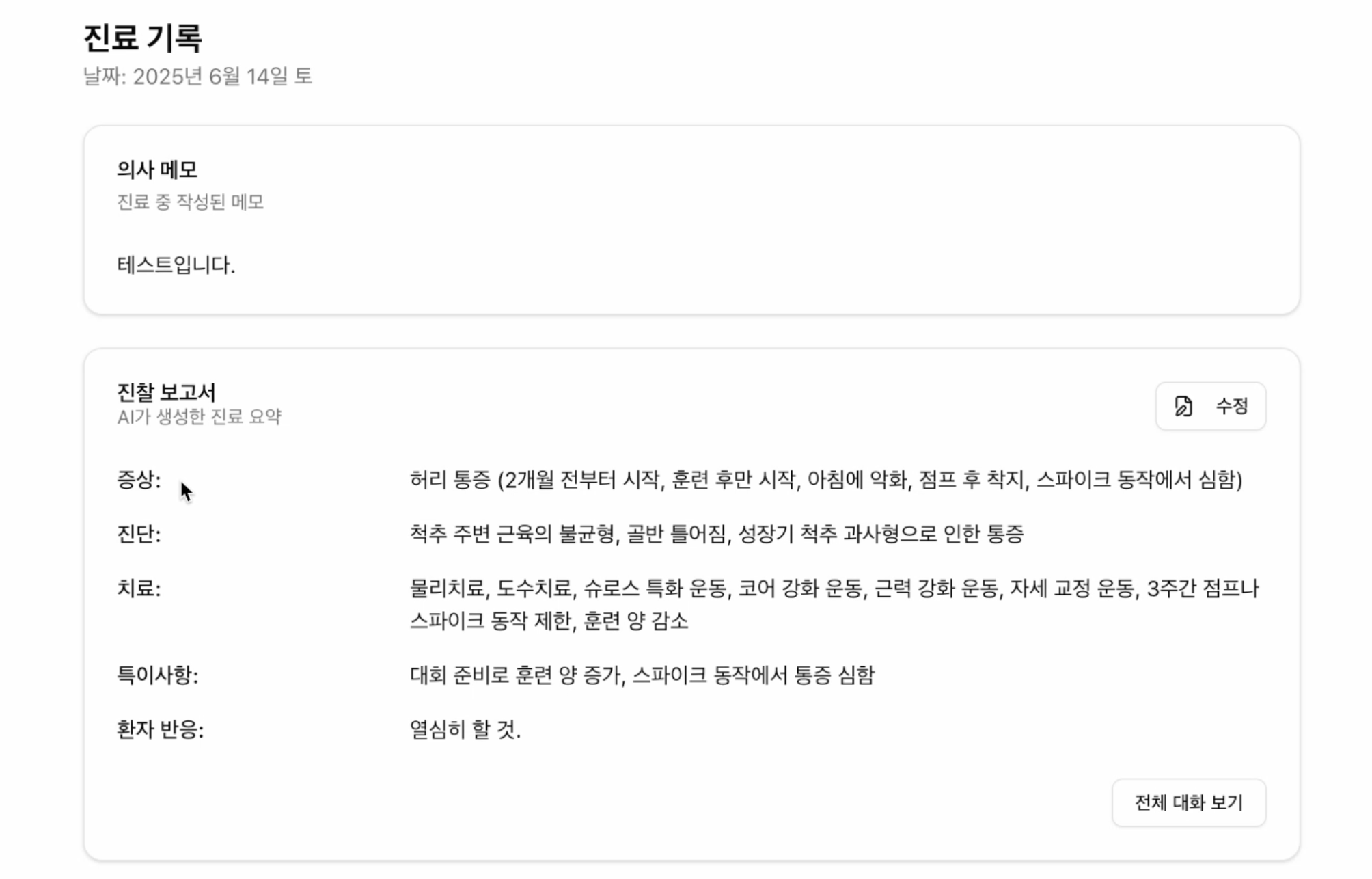
결과 예시
{
"summary": "- 증상: 무릎 관절 통증, 계단을 오르내릴 때 통증, 소리, 불편함.\n- 진단: 무릎 관절의 증식통증 가능성.\n- 치료: 프롤로테라피 (포도당, 증식제 주입) 적용.\n- 특이사항: 자가 혈액을 이용한 치료 가능.\n- 환자 반응: 2-3주 간격으로 4-6회 치료를 통해 호전 효과를 보임."
}결론
의료 도메인처럼 전문성이 필요한 분야에서는 hallucination을 줄이기 위해 RAG가 매우 필요합니다. 특히 키워드 기반 검색과 오타 교정을 통해 실제 문맥과 의미를 보존하면서 요약 품질을 높일 수 있었습니다.
다만 Gemma 3 1B는 다소 작은 모델이라 더 큰 모델을 사용하거나 LLM api를 이용하면 더 좋은 성능을 기대할 수 있을 것 같습니다.
