
llama-cpp 설치 가이드
nvidia gpu를 사용하는 리눅스 환경에서 llama cpp 를 빌드하고 사용하는 과정을 정리해보겠습니다.
직접 마주한 오류도 해결한 내용도 포함했습니다.
1. llama.cpp 빌드
- 우분투 환경 기준 빌드 과정입니다.
- sudo 로 진행해도 되지만, 중간 중간 경로 권한 문제가 생길 수 있어
root 계정에서 진행하는 것을 추천합니다.
1-1. 의존성 패키지 설치
$ sudo apt install git build-essential cmake1-2. llama.cpp 저장소 클론
$ git clone https://github.com/ggerganov/llama.cpp.git1-3. build 디렉토리 생성
- 클론받은 llama.cpp 디렉터리에 build 디렉토리를 생성합니다.
$ cd llama.cpp
$ mkdir build
$ cd build- /llama.cpp/build 으로 이동하여 다음 단계를 진행하면 됩니다.
1-4. 빌드
-
cmake를 통한 빌드- 우리는 NVIDIA GPU를 사용하므로 아래 명령어를 사용합니다.
$ cmake -DGGML_CUDA=ON ..nvcc관련 에러가 발생했다면1-4-1로 갑니다.curl관련 에러가 발생했다면1-4-2로 갑니다.- 실행 결과
root@gm-ai-server:/llama.cpp/build# cmake -DGGML_CUDA=ON .. -- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF -- CMAKE_SYSTEM_PROCESSOR: x86_6 ... -- Configuring done (0.3s) -- Generating done (0.1s) -- Build files have been written to: /llama.cpp/build
-
다음
make를 실행해서 빌드를 진행- make 명령어로 진행합니다.
root@gm-ai-server:/llama.cpp/build# make -j$(nproc) - 실행결과
[ 0%] Building CXX object common/CMakeFiles/build_info.dir/build-info.cpp.o [ 1%] Building C object ggml/src/CMakeFiles/ggml-base.dir/ggml.c.o ... [100%] Built target test-backend-ops [100%] Linking CXX executable ../../bin/llama-server [100%] Built target llama-server
- make 명령어로 진행합니다.
1-4-1. nvcc 오류
$ root@gm-ai-server:/# nvcc --version
Command 'nvcc' not found, but can be installed with: apt install nvidia-cuda-toolkit- nvcc —version 이 안된다면 nvcc 오류입니다.
- nvcc 설치가 안되어있다면 설치 후 진행하면 됩니다.
- 지금 상황은 설치되어 있으나, 인식을 못 하는 상황이므로 아래와 같이 환경변수 설정을 해줍니다.
root@gm-ai-server:/# echo 'export PATH=/usr/local/cuda/bin:$PATH' >> /root/.bashrc echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> /root/.bashrc root@gm-ai-server:/# source /root/.bashrc root@gm-ai-server:/# nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Wed_Jul_16_07:30:01_PM_PDT_2025 Cuda compilation tools, release 13.0, V13.0.48 Build cuda_13.0.r13.0/compiler.36260728_0 - nvcc —version 명령어가 제대로 실행된다면 다시 기존 단계를 이어서 수행합니다.
1-4-2. CURL 오류
-- Could NOT find CURL (missing: CURL_LIBRARY CURL_INCLUDE_DIR)
CMake Error at common/CMakeLists.txt:85 (message):
Could NOT find CURL. Hint: to disable this feature, set -DLLAMA_CURL=OFF
CURL(libcurl)은 웹(HTTP/HTTPS 등) 통신을 위한 라이브러리입니다. Llama.cpp는 이 라이브러리를 사용하여 모델을 다운로드하거나 다른 웹 기능을 구현할 때 사용합니다. 지금 시스템에CURL개발용 라이브러리가 설치되어 있지 않아서 발생하는 문제입니다.
근데 조금 알아보니
CURL 이 꼭 필요 없는 경우(단순 로컬 실행만 한다면) CURL 기능을 끄는 것도 선택지라고 합니다.
-DLLAMA_CURL=OFF💡 libcurl 개발 라이브러리 설치
터미널에 다음 명령어를 입력하여 설치하세요:
# apt 패키지 목록을 업데이트합니다.
apt update
# libcurl 개발 라이브러리를 설치합니다.
apt install -y libcurl4-openssl-dev
libcurl4-openssl-dev:libcurl의 개발용 헤더 파일과 라이브러리가 포함된 패키지입니다. (배포판에 따라 이름이libcurl-devel일 수도 있습니다.)- 실행 예시
설치가 완료되면, 이전 빌드 과정 을 다시 진행하면 됩니다.
2. 모델 다운로드 (GGUF)
llama.cpp로 LLM을 실행하기 위해서는 직접 LLM 모델을 준비해야합니다.
llama.cpp가 지원하는 여러 포멧 중에GGUF로 진행하도록 하겠습니다.
2-1. huggingface
huggingface 에서는 다양한 버전과 포멧의 모델들을 다운받을 수 있습니다.
저는 엑사원4.0 32B gguf 를 다운받아보았습니다.
3. llama-cpp cli 실행
cli 기반에서 llama-cpp를 실행해보도록 하겠습니다.
3.1 llama-cli 버전 확인
- 실행 전에 먼저 정상적으로 설치되었는지 버전을 확인해봅니다.
root@gm-ai-server:/llama.cpp/build# ./bin/llama-cli --version ggml_cuda_init: failed to initialize CUDA: CUDA driver version is insufficient for CUDA runtime version version: 6152 (29c8fbe4) built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu - CUDA 드라이버 버전이 CUDA 런타임 버전이 맞지 않다면 실행이 되지 않습니다.
- 버전을 맞춰주는 과정이 필요합니다.
- 3.1.1로 이동합니다.
- 정상적인 실행결과
(venv) dev2@gm-ai-server:/llama.cpp/build$ ./bin/llama-cli --version ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA RTX 5000 Ada Generation, compute capability 8.9, VMM: yes version: 6152 (29c8fbe4) built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
3.1.1. NVIDIA 드라이버 업데이트
이 문제를 해결할 수 있는 유일하고 가장 확실한 방법은 시스템의 NVIDIA 드라이버를 최신 버전으로 업데이트하는 것입니다.
-
현재 설치된 드라이버 버전 확인
먼저 현재 드라이버 버전을 확인해 봅시다. 터미널에 다음 명령어를 입력하세요.
nvidia-smi
출력된 정보의 오른쪽 상단에 Driver Version: xxx.xx 와 같이 표시됩니다. 아마도 5xx 버전대 초반이거나 그 이전 버전일 것으로 예상됩니다. CUDA Version도 함께 표시되는데, 이것은 해당 드라이버가 지원하는 최대 CUDA 런타임 버전일 뿐, 현재 설치된 런타임과는 다를 수 있습니다.
- 실행결과
root@gm-ai-server:/llama.cpp/build# nvidia-smi Thu Aug 14 03:18:19 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 575.64.03 Driver Version: 575.64.03 CUDA Version: 12.9 | ...
-
최신 드라이버 설치
Ubuntu에서 NVIDIA 드라이버를 설치하는 가장 안정적인 방법은 ubuntu-drivers 유틸리티를 사용하는 것입니다.
먼저, 추천 드라이버 버전을 확인합니다.
ubuntu-drivers devices이 명령어는 현재 GPU에 맞는 추천 드라이버 목록을 보여줍니다. 보통 ... -recommended 라고 표시된 버전이 가장 안정적입니다.
- 실행결과
ubuntu-drivers devices udevadm hwdb is deprecated. Use systemd-hwdb instead. udevadm hwdb is deprecated. Use systemd-hwdb instead. ... ERROR:root:aplay command not found == /sys/devices/pci0000:20/0000:20:01.1/0000:21:00.0 == modalias : pci:v000010DEd000026B2sv000010DEsd000017FAbc03sc00i00 vendor : NVIDIA Corporation model : AD102GL [RTX 5000 Ada Generation] driver : nvidia-driver-580-open - third-party non-free **recommended** driver : nvidia-driver-575-open - distro non-free driver : nvidia-driver-570-open - distro non-free ... driver : nvidia-driver-550 - distro non-free driver : nvidia-driver-535-server-open - distro non-free driver : xserver-xorg-video-nouveau - distro free builtin기존 driver 는 575버전이었고, 580 open 이 recommeded version
- 실행결과
-
추천 드라이버를 자동으로 설치합니다.
# apt 패키지 목록 업데이트 apt update # 추천 드라이버 자동 설치 ubuntu-drivers autoinstallubuntu-drivers devices 명령어가 아주 친절하게도 nvidia-driver-580-open 버전을 recommended 라고 알려주고 있습니다.
이 버전은 현재 드라이버(575)보다 높으므로, CUDA 13.0을 지원할 가능성이 매우 높습니다.이제 이 추천 드라이버를 설치해서 문제를 해결하겠습니다.
추천 드라이버 설치
터미널에 다음 명령어를 입력하여 nvidia-driver-580-open 드라이버를 설치합니다.
# apt 패키지 목록을 최신화합니다. apt update # 추천된 'nvidia-driver-580-open'을 설치합니다. apt install -y nvidia-driver-580-open- open 버전은 오픈소스 커널 모듈을 사용하는 버전이므로 이후에 안전부팅을 해제해줘야 할 수도 있습니다.
- 그냥 580으로 하면 안전부팅 해제가 필요없을 수 있지만, 저는 recommend 버전을 사용했습니다.
시스템 재부팅 (필수)
설치가 완료되면, 새로운 드라이버를 시스템에 완전히 적용하기 위해 반드시 재부팅해야 합니다.
codeBash
reboot재부팅 후 확인 및 최종 테스트
재부팅 후 다시 root로 로그인하거나 터미널을 열고 다음을 순서대로 진행합니다.
-
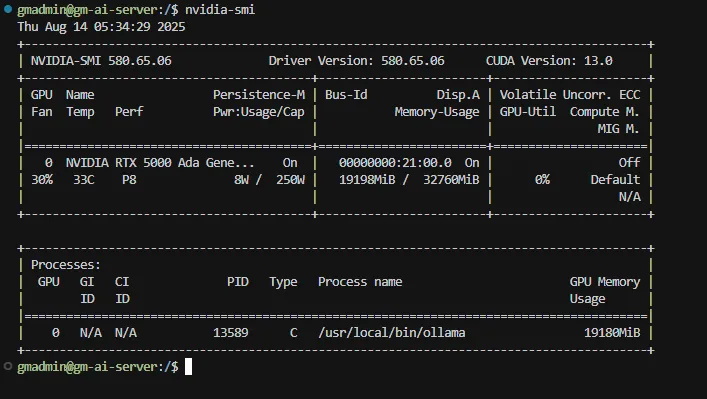
드라이버 버전 확인:
nvidia-smi이제 출력 상단의 Driver Version이 580.xx.xx 와 같이 변경되었는지 확인합니다.
-
에러가 뜬다면?
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
→ 안전 부팅 해제(secure boot disabled) 해야합니다.
3.1.2. 안전부팅 해제
ASUS 기반 bios 부팅 설정입니다.
- secure boot mode 를 custom으로 선택
- clear secure boot key 이후 secure boot disabled하고 부팅합니다.
3.2. 모델 실행
gguf 타입의 모델을 huggingface로부터 다운받았다면 cli 명령어를 통해 모델을 직접 실행해볼 수 있습니다.
- exaone 32b 모델을 예시로 들어보겠습니다.
a. 작업 디렉토리로 이동
먼저, 우리가 빌드한 실행 파일이 있는 곳으로 이동합니다.
# root 사용자로 로그인한 상태에서 진행
cd /llama.cpp/buildb. 실행 명령어 입력
아래 명령어를 복사해서 터미널에 붙여넣으세요. 몇 가지 중요한 옵션을 추가하고 설명해 드리겠습니다.
./bin/llama-cli -m /dev/models/llm/LG/EXAONE-4.0-32B-GGUF/EXAONE-4.0-32B-Q4_K_M.gguf -c 4096 -n 512 --color -i -ngl 999 -p "안녕하세요, 엑사원. 당신은 어떤 언어 모델인가요?"명령어 옵션 상세 설명:
-
m /dev/.../EXAONE-4.0-32B-Q4_K_M.gguf
: 모델 파일의 절대 경로를 정확하게 지정했습니다.
- 만약 gguf 파일이 분할되어있다면 첫번재 gguf 파일의 경로만 지정해주면 됩니다. -
c 4096
: 컨텍스트 크기(Context Size)를 4096 토큰으로 설정합니다. 모델이 한 번에 기억하고 처리할 수 있는 대화의 양입니다. 숫자가 클수록 더 긴 대화나 문서를 잘 이해합니다. 4096은 아주 넉넉한 크기입니다. -
n 512
: 답변으로 생성할 최대 토큰 수를 512개로 설정합니다. -
ngl 999(-1)
: GPU에 올릴 레이어 수. 여기에999처럼 아주 큰 숫자를 넣으면 Llama.cpp가 "가능한 모든 레이어를 GPU에 올려라" 라고 알아서 해석합니다. 32B 모델의 모든 레이어가 VRAM에 올라가게 될 겁니다. 이것이 최고의 성능을 내는 방법입니다. (16 부터 시도하는 걸 추천) -
p "..."
: 모델에게 던지는 첫 번째 질문입니다. "안녕하세요, 엑사원. 당신은 어떤 언어 모델인가요?" -
실행결과(오류)
./bin/llama-cli -m /dev/models/llm/LG/EXAONE-4.0-32B-GGUF/EXAONE-4.0-32B-Q4_K_M.gguf -c 4096 -n 512 --color -i -ngl 999 -p "안녕하세요, 엑사원. 당신은 어떤 언어 모델인가요?"
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA RTX 5000 Ada Generation, compute capability 8.9, VMM: yes
build: 6152 (29c8fbe4) with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_load_from_file_impl: using device CUDA0 (NVIDIA RTX 5000 Ada Generation) - 12707 MiB free
ggml_backend_cuda_buffer_type_alloc_buffer: allocating 18162.44 MiB on device 0: cudaMalloc failed: out of memory
alloc_tensor_range: failed to allocate CUDA0 buffer of size 19044700416
llama_model_load: error loading model: unable to allocate CUDA0 buffer
out of memory
너무 많은 layer를 gpu에 올리려고 하면 out of memory 오류가 발생할 수 있습니다. 적절한 vram 을 사용하는 layer 수를 찾아야 합니다.
./bin/llama-cli -m /dev/models/llm/LG/EXAONE-4.0-32B-GGUF/EXAONE-4.0-32B-Q4_K_M.gguf -c 4096 -n -1 --color -i -ngl 999 -p "안녕하세요, 엑사원. 당신은 어떤 언어 모델인가요?”적절한 vram 을 사용하도록 하는 layer 를 설정해주면 잘 실행되는 걸 확인할 수 있습니다.

