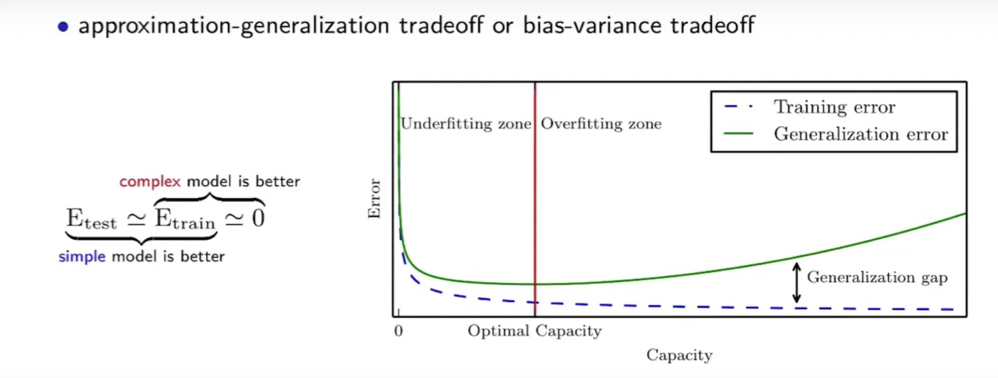
make = E_train , t는 test며 학습은 너무 잘될때 일반화 능력이 잘 안나오는것은 오버 피팅이 되었다고 한다. 모델이 high variance, 그래서 실제 정답과 안맞을수 있다.
해결방식은 regularization과 more data이다.
make = 0 이때의 t는 train 이고 잘 안될때가 언더피팅이라고 하며 high bias이다. 모델의 정답과 큰 편차. 실제 정답과 안맞는 이유. optimization과 more complex model 하는게 해결방식이다.
예로 sequence to sequence 에서 attention 한것은 잘 안되었던게 잘되었으니까 underfitting 되었다는걸 해결했다고 보면 되는것 같다.
loss가 너무 높을때. 그러면 지도학습할때 지도학습은 데이터와 정답이 정해져 있어서 그러는데 비지도 학습은 정답이 정해져 있지 않는데 어떻게 학습시키나?? 에러를 정의 할수 없는데? 그때 강제 클러스터링으로 한면 좋겠다.
따라서 그 2개를 합친 반지도 학습으로 하거나 비지도 학습에서 임의의 정답을 지도 학습에서 정의한 같은 정답으로 묶는다. 예를들면 방안에서 넘어진 행동과 밖에서 넘어진 행동은 같은 넘어진 핻동이라고 묶는다.
이런식으로 이게 지도학습과 비지도학습의 중간인 반지도 학습으로 상용화가 가능한것 같다.
VC generalization bound 관점
Generalization gap이 입실론보다 크다는 것은 학습 알고리즘이 학습 데이터에 대해서는 잘 작동하지만, 새로운 데이터에 대해서는 잘 작동하지 않는 경우를 말합니다. 이는 일반화 오류가 입실론 이상인 경우를 의미합니다.
Bad event는 일반화 오류가 입실론 이상인 경우와 관련이 있습니다. 일반화 오류가 입실론 이상인 경우, 학습 알고리즘이 새로운 데이터에 대해서는 부정확한 예측을 할 가능성이 크기 때문에, 이는 나쁜 사건(bad event)로 간주될 수 있습니다. 따라서, 입실론보다 큰 일반화 오류를 가진 모델은 bad event가 발생할 가능성이 높다고 볼 수 있습니다.
일반적으로, 좋은 모델은 일반화 오류를 최소화하고, generalization gap을 최대한 줄이는 것이 중요합니다. 이를 위해 모델의 복잡도를 적절히 조절하고, 적절한 규제나 모델 선택 기법을 사용하여 일반화 성능을 개선해야 합니다.
모델의 복잡도를 줄이면 VC 차원이 작아지고, 이에 따라 VC bound도 작아집니다. 작은 VC bound는 일반화 오류의 상한을 더욱 제한하기 때문에, 일반적으로 모델의 복잡도를 줄이면 일반화 오류가 날 확률이 감소합니다.
모델의 복잡도를 줄이는 방법에는 여러 가지가 있습니다. 예를 들어, 모델의 파라미터 수를 줄이거나, 규제 기법을 사용하거나, feature engineering을 통해 불필요한 특성을 제거하거나, 모델의 구조를 단순화하는 등이 있습니다. 이러한 방법들은 모델의 일반화 성능을 개선하고, overfitting을 방지하기 위한 중요한 전략입니다.
하지만, 일반화 오류와 복잡도 간의 관계는 항상 일정하지 않을 수 있습니다. 모델의 구조나 데이터의 분포 등에 따라서는 복잡한 모델이 더 좋은 일반화 성능을 가질 수도 있습니다. 따라서, 모델의 복잡도를 줄이는 것이 일반화 오류를 항상 개선시키는 것은 아니며, 적절한 모델 선택 기법이나 규제 기법을 사용하여 최적의 모델을 선택하는 것이 중요합니다.
trade off:
분산과 편차의 trade off
- overfitting 관점. generaliztion, 분산, test error == train error
- underfitting 관점. approximate, bias , train Error = 0
