AWS Glue는 여러 소스에서 데이터를 쉽게 탐색/준비/이동/통합할 수 있도록 하는 서버리스 데이터 통합 ETL 서비스입니다.
ETL이란 Extract, Transform, Load의 약자로 Source의 데이터를 일관성 있는 단일 데이터로 통합한 뒤 Target 시스템에 로딩하는 데이터 통합 프로세스를 의미합니다.
AWS Glue가 바로 이 ETL 기능을 제공하는 서비스이며 지원하는 데이터 Source에는 S3, RDS, DynamoDB, Redshift, Kinesis 등이 있고 Target에는 S3, Redshift 등이 있습니다.
AWS Glue를 활용한 ETL 예시
DynamoDB(Source) → S3(Target)
요구사항
- 현재 DynamoDB에 애플리케이션 로그를 쌓고 있습니다. S3의 보관 비용이 더 저렴하므로 매월 DynamoDB에 있는 로그 데이터를 S3로 백업하고 DynamoDB의 로그는 일정 기간이 지나면 삭제하려 합니다.
- DynamoDB에는 'log_create_date'라는 컬럼이 있으며 '2023-08-04'와 같은 형식으로 저장되고 있습니다. 매월 초에 EventBridge는 Glue의 ETL job을 트리거하여 직전 달에 생성된 데이터만 S3에 백업합니다.
- S3에 백업된 데이터를 추후 Athena로 쿼리하기 위해 객체를 year > month > day 구조로 파티셔닝 하여 저장합니다.
위 요구사항을 모두 만족하는 ETL job을 생성해 보겠습니다.
AWS Glue 설정
ETL job 생성
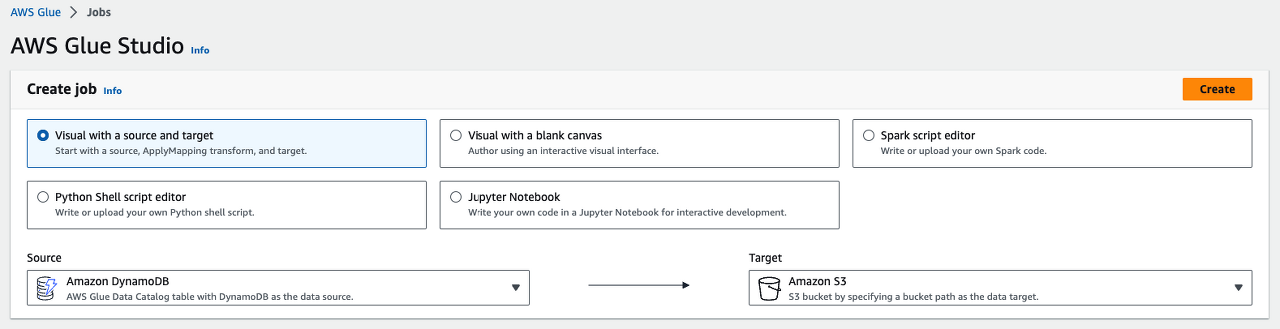
위 캡처와 같이 'Source'를 DynamoDB, 'Target'을 S3로 설정한 뒤 ETL job을 생성합니다.
Script 작성 (pyspark)
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# node1
# node2
# node3
# node4
# node5
job.commit()위 코드는 'Edit script' 클릭 시 자동으로 생성되는 부분이며 그대로 둔 상태에서 제가 원하는 기능을 수행할 수 있도록 총 5개의 node를 생성했습니다. 각 node들의 기능은 다음과 같습니다.
node1: Source인 DynamoDB로부터 dynamic frame 생성node2: 'log_create-date' 컬럼 값('년-월-일')에서 '년-월'이 job 실행 시점 기준으로 '지난 달'인 것만 필터링node3: 'log_create-date' 컬럼 값에서 'year', 'month', 'day' 값 추출 ☞ S3 파티셔닝을 위함node4: DynamoDB의 컬럼 값과 S3에 저장할 컬럼 값을 매핑 ☞ node3에서 추출한 'year', 'month', 'day' 추가node5: Target 정보 설정 ☞ S3에 저장할 format(.csv)과 partitionKey('year', 'month', 'day') 등
node1
DynamoDBtable_node1 = glueContext.create_dynamic_frame.from_options(
connection_type="dynamodb",
connection_options={
"dynamodb.export": "ddb",
"dynamodb.s3.bucket": "<GLUE_ASSET_STORE_S3_NAME>",
"dynamodb.s3.prefix": "glue-assets/temporary/ddbexport/",
"dynamodb.tableArn": "arn:aws:dynamodb:<REGION>:<ACCOUNT_ID>:table/<DDB_NAME>",
"dynamodb.unnestDDBJson": True,
},
transformation_ctx="DynamoDBtable_node1",
)node2
lastmonth = (datetime.datetime.now(pytz.timezone('Etc/GMT-9')) - datetime.timedelta(days = 5)).strftime("%Y-%m")
Filter_node2 = Filter.apply(
frame=DynamoDBtable_node1,
f = lambda x: x["log_create_date"][0:7] == lastmonth,
transformation_ctx="Filter_node2",
)node3
def map_function(dynamicRecord):
date = dynamicRecord["log_create_date"]
date_arr = date.split("-")
dynamicRecord["year"] = date_arr[0]
dynamicRecord["month"] = date_arr[1]
dynamicRecord["day"]= date_arr[2]
return dynamicRecord
DateParse_node3 = Map.apply(
frame = Filter_node2,
f = map_function,
transformation_ctx = "DateParse_node3"
)node4
ApplyMapping_node4 = ApplyMapping.apply(
frame=DateParse_node3,
mappings=[
("<COLUMN_VALUE_1>", "string", "<COLUMN_VALUE_1>", "string"),
("<COLUMN_VALUE_2>", "string", "<COLUMN_VALUE_2>", "string"),
("<COLUMN_VALUE_N>", "string", "<COLUMN_VALUE_N>", "string"),
("log_create_date", "string", "log_create_date", "string"),
("year", "string", "year", "string"),
("month", "string", "month", "string"),
("day", "string", "day", "string"),
],
transformation_ctx="ApplyMapping_node4",
)node5
s3_name = "s3://<TARGET_S3_NAME>"
S3bucket_node5 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node4,
connection_type="s3",
format="csv",
connection_options={
"path": s3_name,
"partitionKeys": ["year", "month", "day"],
},
transformation_ctx="S3bucket_node5",
)S3 적재 결과 (Partitioning for Athena)
year

year > month

year > month > day
EventBridge Schedule 설정
Target 설정
- Service:
AWS Glue - API:
StartJobRun - Payload:
{"JobName": "<GLUE_ETL_JOB_NAME>"}
Execution role 설정
IAM Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "glue:StartJobRun",
"Resource": "arn:aws:glue:<REGION>:<ACCOUNT_ID>:job/<GLUE_ETL_JOB_NAME>"
}
]
}Trust relationship
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"scheduler.amazonaws.com",
"events.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}Athena 설정
Table 생성
CREATE EXTERNAL TABLE ch_int_stg_nci_etl (
`<COLUMN_VALUE_1>` string,
`<COLUMN_VALUE_2>` string,
`<COLUMN_VALUE_N>` string,
`log_create_date` string
)
PARTITIONED BY (
`year` string,
`month` string,
`day` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
LOCATION 's3://<TARGET_S3_NAME>/';Auto Partitioning
MSCK REPAIR TABLE <ATHENA_TABLE_NAME>;쿼리 테스트
SELECT uid FROM <ATHENA_TABLE_NAME> WHERE year='2023' and month='07' and day='25' limit 10;
Reference
개인적으로 공부하며 작성한 글로, 내용에 오류가 있을 수 있습니다.

2개의 댓글

안녕하세요! 글 잘 봤습니다! 다만 첫 시작부터 오류가 있어서요 ㅠ..
AWS glue를 DynamoDB에 연결하려고 하는데 제 IAM 계정에 AmazonDynamoDBFullAccess, AmazonS3FullAccess, AWSGlueServiceRole 이렇게 세 권한 정책을 했는데도 AWSGlueServiceRole-createRole/GlueJobRunnerSession is not authorized to perform: dynamodb:ExportTableToPointInTime on resource: 이렇게 오류가 나서요...
혹시 따로 IAM Role 권한 설정을 해주셨나 궁금합니다..
유익한 글이었습니다.