공부한 부분 ⭕️
- JPA (Java Persistence API)
- 객체와 관계형 데이터베이스의 패러다임 불일치
- 이를 해결해줄 자바 Object Relational Mapping 표준 JPA
- 객체 맵핑 & 영속성 관리 (영속성 컨텍스트와 영속/비영속/준영속)
- 이펙티브 자바
- 올바른 객체 생성과 불필요한 생성을 피하는 방법
- 정적 팩토리 메서드 (팩토리 메소드 패턴과 다르다.)
- 빌더 패턴과 점층적 생성자 패턴(생성자에 매개변수가 많다면 ?)
- 싱글톤을 보장하는 클래스 설계
각 파트별 정리
JPA란??
JPA가 뭘까 ?
Java Persistence API 로 자바 Object Relational Mapping 기술의 표준이다.
엔티티는 뭘까?
비즈니스 요구사항을 모델링한 객체이다.
객체와 관계형 데이터베이스의 패러다임 불일치 문제?? (구조가 다르고 지향하는 부분이 다르기 때문에 발생하는 문제들)
객체와 관계형 데이터베이스의 구조 차이 💁🏻
객체와 관계형 데이터베이스 이 둘이 지향하는 목적이 서로 다르므로 둘의 기능과 표현 방법이 다르다.
객체구조를 테이블 구조에 저장하는 데에는 한계가 있다.
테이블에는 상속이라는 기능이 없고 해당 기능을 모방하려면 외래키(FK)로 참조하는 수 밖에 없다. 그리고 객체는 참조가 있는 방향으로만 조회가 가능하다. 하지만 테이블은 외래키 하나로 조회가 가능하다.
구조 차이로인한 불편한 점 🤦🏻♂️
A객체에 상속된 B 객체를 조회하려면 A객체 테이블에 조인해서 조회 후, 그 결과로 B 객체를 생성해야 한다.
이런 과정이 모두 패러다임의 불일치를 해결하기 위해 소모하는 비용이다.
기존에 A 객체와 연결된 다른 객체 방향으로 객체 그래프를 탐색 할 수 있을지는 데이터 접근 레이어인 DAO (Data Access Object) 를 직접 열어 확인해야한다.
그리고 해당 문제는 SQL에 엔티티가 논리적으로 종속되어서 발생하는 문제이기 때문에 의존성이 커지게 된다.
해당 문제를 해결해주는 JPA 의 역할
JPA 의 객체 그래프 탐색 💡
JPA는 연관된 객체를 사용하는 시점에 SQL을 실행한다.
따라서 연관된 객체를 마음껏 조회할 수 있다.
이러한 행동은 실제 객체를 사용하는 시점까지 데이터베이스 조회를 미룬다고 해서 지연로딩 이라고 한다.
(JPA는 지연 로딩을 투명하게 처리한다. 해당 부분에대한 코드를 직접 작성하지 않는다.)
기존의 SQL을 통한 객체 조회와 JPA 를 통한 객체 조회의 차이 💁🏻
기존의 Dao 를 통한 객체 조회는 같은 객체를 조회해도 조회된 객체들은 다른 인스턴스가 된다. (동일성 검사에서 실패한다. 다른 인스턴스이기 때문에 인스턴스 주소값이 다르다.)
하지만 JPA는 같은 트랜잭션 일때 같은 객체가 조회된다. (같은 인스턴스 주소값을 가진다.)
패러다임 불일치에 대한 정리 🙏🏻
정교한 객체 모델링을 할수록 패러다임의 불일치 문제가 더 커진다.
결국 객체 모델링은 힘을 잃고 점점 데이터 중심의 모델로 변해간다.
이를 JPA가 해결해주며 정교한 객체 모델링을 유지하게 도와준다.
JPA를 사용해야 하는 이유💁🏻
- 생산성 : 데이터베이스 설계 중심에서 객체 설계 중심으로 역전시킬 수 있다.
- 유지보수 : JPA를 이용하면 SQL과 JDBC API 코드를 JPA가 대신 처리해주기 때문에 유지보수해야 하는 코드 수가 훨씬 줄어든다.
- 성능 : JPA를 사용하면 같은 트랜잭션 안에서 SQL을 한번만 데이터베이스에 전달하고 두번째는 조회한 회원 객체를 재사용한다. (영속성 컨텍스트)
- 데이터 접근 추상화 : 데이터베이스를 변경하면 단순히 JPA에게 다른 데이터베이스를 사용한다고 알려주기만 하면 된다. (각각 SQL기술에 따른 문법도 지원해준다.)
영속성 관리
해당 부분은 개인적으로 스프링의 어플리케이션 컨텍스트로 빈을 관리하는 부분과 비슷하다고 느껴졌다.
엔티티 매니저 팩토리와 엔티티 매니저 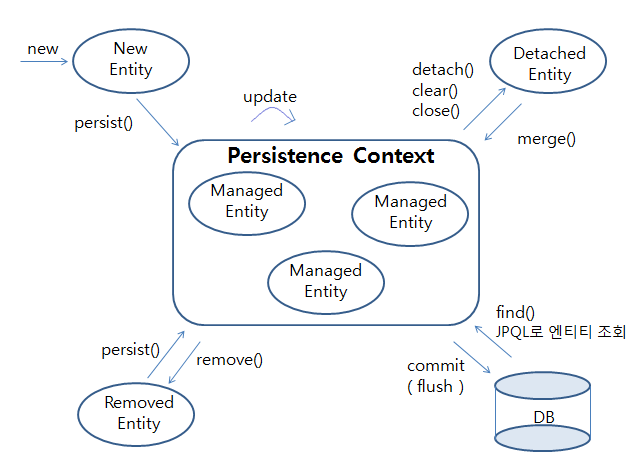
데이터베이스를 하나만 사용하는 애플리케이션은 일반적으로 엔티티 매니저 팩토리를 하나만 생성한다. (공장을 하나 건설한다 생각하면 쉽다.)
엔티티 매니저 팩토리는 해당 객체를 만드는 비용이 상당히 크기 때문에 싱글톤으로 관리한다. (하나만 만들어서 어플리케이션 전체에서 공유한다.)
엔티티 매니저 팩토리는 엔티티 매니저를 생성해주고, 엔티티 매니저는 여러 스레드가 동시에 접근하면 동시성 문제가 발생하므로 스레드간에 공유하면 안된다.
엔티티 매니저는 데이터베이스의 연결이 꼭 필요한 시점까지 커넥션을 얻지 않는다.
(트랜잭션을 시작할 때 커넥션을 획득한다.)
쉽게 말하면 엔티티 매니저 팩토리는 말그대로 공장이고 엔티티 매니저는 공장이 찍어내는 관리로봇 이라고 생각하면 된다. 그리고 영속성 컨텍스트는 해당 엔티티 매니저가 관리하는 창고 정도로 생각하자.
영속성 컨텍스트 (임시 물류 창고)
엔티티를 영구 저장하는 환경이다. 엔티티 매니저로 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.
Article article =articleRepository.save(dto.toEntity());이렇게 저장을 한다면 해당 Article 엔티티는 영속성 컨텍스트에 의해 관리된다.
영속성 컨텍스트의 생명주기 💁🏻 (어떻게 관리가 되고 관리가 안되나요?)
- 비영속 : 영속성 컨텍스트와 전혀 관계가 없는 상태 (단순히 엔티티 객체를 생성후 저장이라던가 아무런 작업을 하지 않은 상태)
Article article = Article.of("title","content");
//아무런 작업을 하지 않았기 때문에 해당 엔티티는 비영속 상태이다.- 영속 : 영속성 컨텍스트에 저장되며 영속성 컨텍스트에 의해 관리된다.
Article article =articleRepository.save(dto.toEntity());
//JPA에 의해 영속성 컨텍스트에 관리가 된다.
//JPArepository 는 엔티티 매니저가 포함되어있어 persist 를 해주지 않아도 자동으로 처리해준다.- 준영속 : 영속성 컨텍스트에 저장되었다가 분리된 상태 (영속성 컨텍스트를 닫거나 clear()를 호출하면 영속상태의 엔티티는 준영속 상태가 된다.
- 삭제 : 삭제된 상태 (remove()를 통해서 컨텍스트와 데이터베이스에서 삭제한다.)
영속성 컨텍스트의 특징 💁🏻
-
식별자 값 : 영속 상태는 식별자 값이 반드시 있어야 한다. (없으면 예외가 발생한다. 데이터베이스의 pk와 같다.)
-
영속성 컨텍스트와 데이터베이스 저장 : 단순히 영속상태로 만들면 바로 저장되는게 아닌 트랜잭션을 커밋하는 순간 영속성 컨텍스트에 새로 저장된 엔티티를 데이터베이스에 반영하고, 이것을 flush 라고 한다.
-
영속성 컨텍스트가 엔티티를 관리하면 생기는 장점
-
1차 캐시 (매번 데이터베이스에서 불러와 작업을 할 필요가 없이 영속성 컨텍스트에 저장된 엔티티를 기반으로 반환,조회,수정,삭제 작업을 거친 후 데이터베이스에 해당 sql 을 처리한다.)
-
동일성 보장 (조회할때마다 매번 새로 인스턴스화 하는것이 아닌 기존에 컨텍스트에 저장된 엔티티를 반환해주기 때문에 동일성 검사에서 true 가 나온다.)
-
트랜잭션을 지원하는 쓰기 지원(해당 쿼리가 실행되는 타이밍에만 쿼리가 호출된다.)
-
변경 감지 (따로 update메소드나 수정후 save 를 해줄 필요가 없이 영속성 컨텍스트는 기존의 최초로 저장된 엔티티를 갖고있다가 setter 같은 메소드로 값이 변경되면 최초 엔티티와 비교해 변경된 부분을 쿼리한다.)
-
알게된점
-
기존의 JPA를 사용할때 해당 기능이 동작하는 구조를 전혀 몰랐었는데 , 어느정도 사용방법을 터득했다. (영속성 컨텍스트에 대한 정의를 정확히 이해했다.)
-
해당 부분을 공부함으로써 객체 맵핑 실력이 한층 더 성장 할 것 같다.
-
JPA가 제공하는 강점들을 확실하게 알게되었고 좀 더 효율적인 개발이 가능할 것 같다.
