서론
@Entity어노테이션으로 테이블과 매핑할것을 명시해줍니다.@Table어노테이션으로 매핑할 테이블을 지정합니다.- 여러 부가 어노테이션으로 필드와 컬럼을 매핑합니다.
- DDL에 제약조건을 추가할 수 있습니다.
- 기본 키 전략을 통해 식별자를 지정할 수 있습니다.
본론
테이블과 엔티티 맵핑에 사용되는 어노테이션을 알아보자 👀
@Entity
JPA를 사용하는데 가장 중요한 것은 엔티티와 테이블을 정확히 매핑하는 것이다.
- 객체와 테이블 매핑 :
@Entity,@Table(따로 Table을 지정해주지 않으면 자동으로 생성합니다.) - 기본 키 매핑 :
@Id(다양한 전략을 통해 기본키를 부여할 수 있습니다.) - 필드 컬럼 매핑 :
@Column(역시나 여러가지 설정을 어노테이션을 통해 할 수 있습니다.) - 연관관계 매핑 :
@ManyToOne,@JoinColumn~ (다대다 관계도 있지만 실무에서 사용하지 않습니다.)
Entity 어노테이션 적용시 주의사항은 다음과 같다.
- 기본 생성자는 필수다. (파라미터가 없는 public / protected 생성자)
- final 클래스, enum, interface, inner 클래스에는 사용 불가
- 저장할 필드에 final 을 사용하면 안된다.
👁️ JPA는 엔티티 객체를 생성할때 기본 생성자를 사용하기 때문에 생성자가 반드시 존재해야 한다.
@Table
@Table은 엔티티와 매핑할 테이블을 지정한다.
속성 정리 =>
- name : 매핑할 테이블 이름을 지정한다. (기본값으론 엔티티 이름을 사용한다.)
- catalog : catalog 기능이 있는 데이터베이스에서 catalog 를 매핑한다.
- schema : schema 기능이 있는 데이터베이스에서 schema 를 매핑한다.
데이터베이스 스키마 자동 생성
JPA는 데이터베이스 스키마를 자동으로 생성하는 기능을 지원한다. 👁클래스의 매핑정보를 참고하면 어떤 테이블에 어떤 컬럼을 사용하는지 알 수 있다.
jpa:
open-in-view: false
defer-datasource-initialization: true
hibernate.ddl-auto: create
show-sql: trueSpring Data Jpa 를 사용하면 yaml 파일에 해당 설정 정보를 저장할 수 있다.
create 를 입력하면 애플리케이션 실행 시점에 데이터베이스 테이블을 자동으로 생성한다.
show-sql 을 true로 설정하면 콘솔에 실행되는 테이블 생성 DDL(Data Definition Language)을 출력할 수 있다.
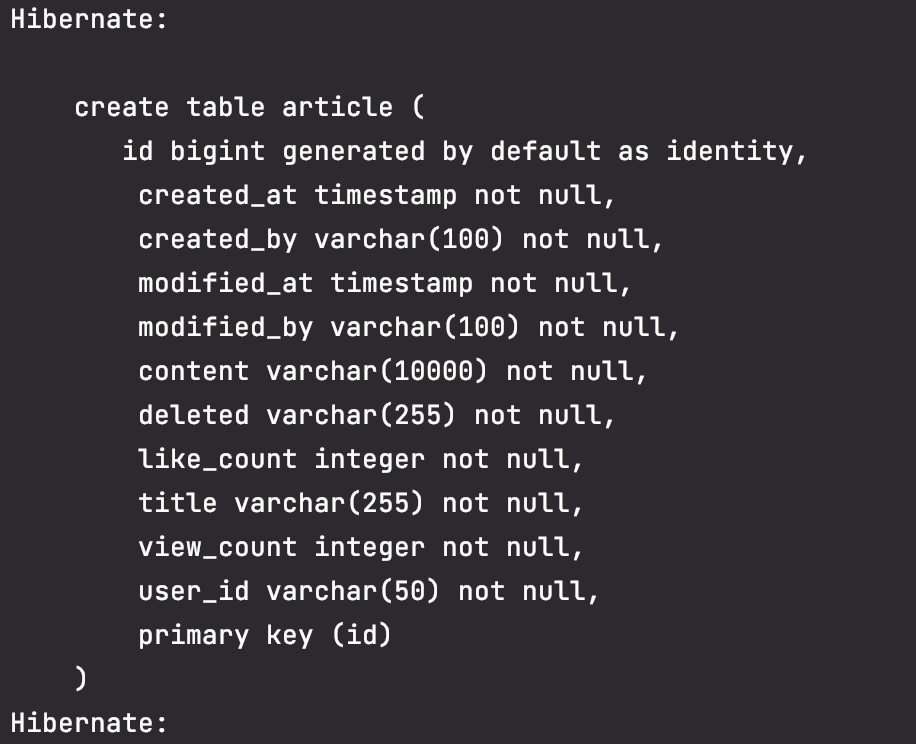
이렇게 콘솔에서 설정된 매핑정보로 DDL을 출력 시켜준다. (해당 정보를 참고해서 추후에 데이터 조회를 위한 쿼리문을 작성해도 좋다.)
👁👁스키마 자동 생성하기는 엔티티와 테이블을 어떻게 매핑해야 하는지 알려주는 가장 훌륭한 학습 도구이다.
<주의사항💁🏻>
- ❌운영 서버에서 create, create-drop, update 처럼 DDL을 수정하는 옵션은 절대 사용하면 안된다. 오직 개발서버나 개발 단계에서만 사용해야 한다. -> 스테이징과 운영 서버는 validate 또는 none 을 사용한다.
- 자바 언어는 관례상 카멜 표기법을 주로 사용하고, 데이터베이스는 관례상 언더스코어를 주로 사용한다.
@Column.name속성을 명시적으로 사용해서 이름을 지어주어야 한다.
기본키 매핑 (primary key)
데이터베이스마다 기본 키를 생성하는 방식이 서로 다르므로 JPA가 제공하는 데이터베이스 기본 키 생성 전략을 각 데이터베이스에 맞게 이용해야한다.
-
직접 할당 : 기본키를 애플리케이션에서 직접 할당한다.
- 엔티티를 저장하기 전에 애플리케이션에서 기본 키를 직접 할당하는 방법
-
자동 생성 : 대리 키 사용 방식
-
IDENTITY: 기본 키 생성을 데이터베이스에 위임한다.-
MySQL, PostgreSQL, SQL Server, DB2 에서 사용한다.
-
데이터베이스에 값을 저장하고 나서야 기본 키 값을 구할 수 있을때 사용한다.
-
strategy속성 값을GenerationType.IDENTITY로 지정하면 된다. ( 해당 정략을 사용하면 JPA는 기본 키 값을 얻어오기 위해 데이터베잇르르 추가로 조회한다. ) => 해당 전략은 트랜잭션을 지원하는 쓰기 지연이 동작하지 않는다.
-
-
SEQUENCE: 데이터베이스 시퀀스를 사용해서 기본 키를 할당한다.-
시퀀스를 사용해서 기본 키를 생성한다.
-
@SequenceGenerator를 사용해서 시퀀스 생성기를 등록한다. (먼저 데이터베이스 시퀀스를 사용해서 식별자를 조회하고 영속성 컨텍스트에 영속시킨다.)
-
-
TABLE: 키 생성 테이블을 사용한다.-
이름과 값으로 사용할 컬럼을 만들어 시퀀스를 흉내내는 전략이다.
-
테이블 전략은 SELECT 쿼리를 사용하고 다음 값으로 증가시키기 위해 UPDATE 쿼리를 사용하기 떄문에 한번 더 통신한다는 단점이 있다.
-
-
👁각 전략은 사용하는 데이터베이스에 의존한다.
<참고👀>
권장하는 식별자 선택 전략
- null값은 허용하지 않는다.
- 👁👁👁유일해야 한다.
- 👁👁👁변해선 안된다.
기본키를 선택하는 전략은 크게 2가지가 있다.
- 자연 키
- 비즈니스에 의미가 있는 키 : (주민등록 번호, 이메일, 전화번호 등등)
- 대리 키
- 비즈니스와 관련 없는 임의로 만들어진 키 (auto_increment 같은)
👁JPA는 모든 엔티티에 일관된 방식으로 대리 키 사용을 권장한다.
마무리
- 해당 파트로 인하여 데이터베이스마다 어떠한 식별키 전략이 존재하는지 알 수 있게 되었습니다. ⭕️
- 어떻게 매핑해야지 JPA를 100퍼센트는 아니더라도 더 잘 활용할 수 있을지 알게 되었습니다. 👀
- 각각 컬럼별로 어떠한 속성값을 이용해야지 테이블 구조에 맞게 매핑할 수 있을지 팁을 얻었습니다. 😎
