자료구조
자료구조란 무엇일까 ? → 메모리를 어떻게 관리해야 가장 효율적인가
- 프로그램에서 사용할 많은 데이터를 메모리 상에서 관리하는 여러 구현방법들
-> 옷장을 어떻게 정리해야지 가장 깔끔하고 공간활용을 잘 할까 ? 라고 생각해도 될 것 같다 ㅎ - 효율적인 자료구조가 성능 좋은 알고리즘의 기반이 됨 → 각각 상황에 맞는 것들을 활용해야 한다. (효율적인 로직의 기반이 된다.)
- 자료의 효율적인 관리는 프로그램의 수행속도와 시스템의 유지보수와도 밀접한 관련이 있다.
실질적으로 자료구조를 직접 구현할 일은 없다. 👁💀
선형 자료구조
배열 연결리스트 스텍 큐 → 선형 자료구조 (한 줄 (선형)로 자료를 관리한다.)
선형 자료구조 : 앞뒤 요소가 1:1 의 관계 를 갖고 있어서 선의 구조를 갖고있는 자료구조
배열
배열은 선형으로 자료를 관리, 정해진 크기의 메모리를 먼저 할당 받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같다.
배열은 중간이 비어있으면 안된다. (Null Pointer Exception 예외가 발생함) 메모리 상에 각각의 자리에 요소가 있어야한다. (중간에 삭제가 발생하면 뒤의 요소들을 앞으로 당겨와야 한다.)
링크드 리스트
처음 사이즈를 미리 설정할 필요가 없다. 요소가 추가될 때마다 메모리를 할당받는다. 전글에 설명했듯이 체인으로 연결되어있다고 생각하면 된다.
배열과 다르게 중간에 삽입이 필요하다면 체인을 끊고 요소를 추가한뒤에 체인을 다시 연결한다.
배열과 다르게 논리적 위치와 물리적 위치가 다를 수 있다.
논리적 주소와 물리적 주소의 차이점 -LIVING-IN-BELGIUM 블로그
배열보다 속도가 빠르다 (불필요한 행동들을 줄여줌) 대신 검색 속도가 느리다 .
스택
스택은 가장 나중에 입력된 자료가 가장 먼저 출력되는 자료구조이다.
Last In First Out (LIFO) 스택 메모리 의 스택과 같은 의미이다.
예를 든다면, 세로로 쌓아둔 책을 꺼낼때 가장 밑에 있는 책을 꺼내면 우르르.. 무너져버린다. 당연히 가장 위에 두어진 책을 꺼내야한다. 이것을 스택 자료구조 라고 한다.

이것이 바로 스택 자료구조이다..
큐
가장 먼저 입력된 자료가 가장 먼저 출력되는 자료구조이다.
(스택에서 요소를 추가할땐 push, 제거할땐 pop 이라면 큐에선 enqueue, 제거할땐 dequeue 라고 표현한다.)
First in First Out (FIFO)
메모리의 낭비를 예방하기 위해 서큘라 큐로 구현하기도 한다.


이것이 바로 큐 그 잡채
스택/큐는 배열로 구현할 수도 있고, 링크드 리스트로 구현할 수도 있다.
비선형 자료구조
트리
트리는 비선형 자료구조이다.
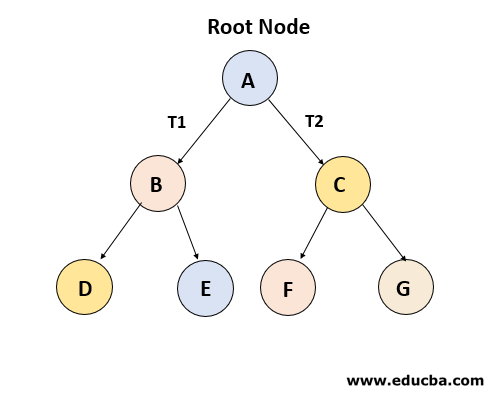
노드 (요소) 는 여러개일 수도 있고, 없을 수도 있다.
child가 몇개인가를 나타낼때 디그리(차수) 라고도 한다.
보통 사진과 같이 child(하위 노드)가 2개보다 작거나 같은 이진 트리 를 많이 사용한다.
힙 (Heap)
Priority Queue 에 heap 을 사용한다.
위 사진 처럼 꽉 찬 트리를 컴플리트 바이너리 트리(완전한 이진트리) 라고 한다.
꽉 차진 않았지만, 루트 노드의 값이 가장 크고, 서브 트리들은 작거나 같은 것을 Max heap 이라고 한다.
서브트리 값이 루트 노드의 값보다 크거나 같은것을 Min heap 이라고 한다.
루트 노드의 요소를 밖으로 꺼내면, 트리가 리 오더링을 하여 서브 트리에서 가장 큰 요소가 위로 올라가는 구조를 가지고 있다.
루트를 계속 꺼내게 되면, 큰 수부터 꺼내게 된다. 이것을 Heap sort 라고 한다. (Heap tree 를 이용해서 하는 정렬/ min heap, max heap 에 따라 정렬 방법이 바뀐다.)
이진 검색 트리(binary search tree)
검색을 위해서 만들어진 트리이다. 그렇기 때문에 값이 중복되지 않는다.
루트 노드를 중심으로 왼쪽 트리는 루트보다 작은 값, 오른쪽 트리는 루트보다 큰 값을 가진다.
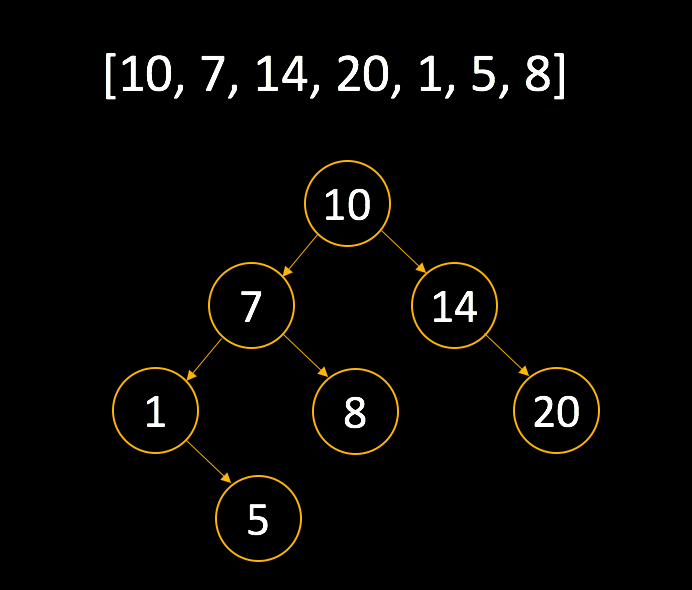
-배열로 이진 검색 트리 만들기-
값을 찾는데 걸리는 평균 시간이 log2의 n 승 이다. (?) 범위가 절반씩 줄기 때문이다.
편향된 트리를 만들지 않기 위해 AVL 트리나 레드블랙 트리로 구현한다.
(TreeSet, TreeMap)
그래프
정점과 간선들의 유한 집합 (구글맵, 네비게이션 같은 것들도 그래프를 기반으로 구현이 된다.)
트리에서는 Node 라는 표현을 쓰고 그래프에서는 Vertex 라는 표현을 사용한다.
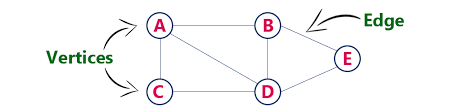
그래프를 구현하는 방법은 크게 2가지가 있다.
- 행렬로 나타내기 (인접 행렬) 각 노드를 행렬로 나타내고 값에는 연결되어있는 선의 갯수를 넣으면 되는것같다.
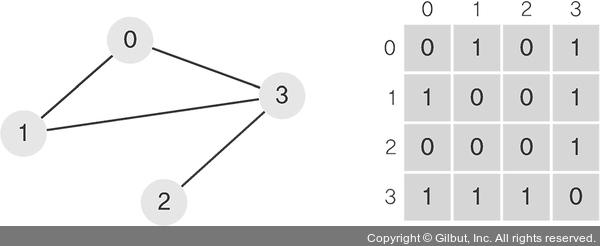
- 인접 리스트 (각 노드와 연결된 노드들을 표현한다)
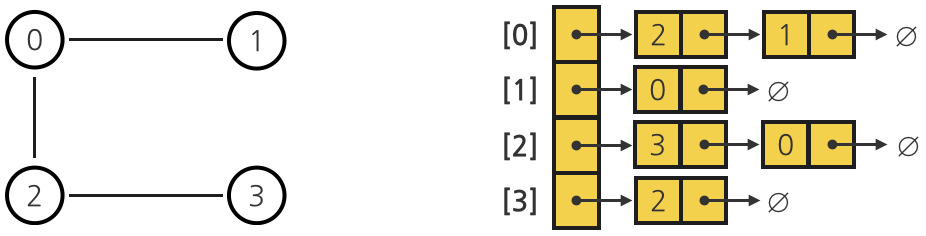
해싱 Hashing
자료를 검색하기 위한 자료 구조이다.
Key는 유일하고 이에 대한 Value 를 쌍으로 저장한다. (HashMap, Properties 클래스가 이에대한 인터페이스를 제공한다.)
해싱의 구조
만약 어떤 회사의 직원이 100명이라면 직원들은 0에서 99까지의 아이디를 부여받는다. 탐색을 하려면 단순히 크기가 100인 배열을 만들면 된다. 자료를 저장하거나 탐색하려면 직원의 아이디를 키(배열의 인덱스)로 생각하고 단지 배열의 특정 요소를 일거나 쓰면 된다. 이런 연산의 시간 복잡도는 O(1)이다.
그러나 현실적으로는 탐색 키들이 문자열이거나 매우 큰 숫자이기 때문에 탐색 키를 직접 배열의 인덱스로 사용하기에는 무리가 있으므로 각 탐색 키를 작은 정수로 사상(mapping)시키는 어떤 함수가 필요하다. 해싱에서는 자료를 저장하는데 배열을 사용한다. 배열은 단점도 있지만 만약 원하는 항목이 들어 있는 위치를 알고 있다면 매우 빠르게 자료를 삽입하거나 꺼낼 수 있다.
해싱 : 어떤 항목의 키만을 가지고 바로 항목이 들어 있는 배열의 인덱스를 결정하는 기법
해시 함수 : 키를 입력으로 받아 해시 주소(hash address)를 생성하고 이 해시 주소를 해시 테이블(hash table)의 인덱스로 사용
이 배열의 인덱스 위치에 자료를 저장할 수도 있고 거기에 저장된 자료를 꺼낼수도 있다.
해싱에 대해 좋은 설명이 있어서 가져와봤다.
말그대로 해시함수에 넣었을때 나온 인덱스 값에 결과를 저장하고, 그 인덱스에 값을 찾는 구조가 해싱 구조이다.
(해싱을 다른말로 Dictionary 라고 한다. 파이썬의 Dictionary가 자바의 Map 과 비슷한 구조로 되어있다.)
해시 알고리즘을 사용하는 가장 큰 이유는 검색의 속도가 산술적(더하기, 빼기와 같은 산술적인 계산만으로도 풀이가 가능하다)으로 가능하기 떄문이다.
해시 함수를 어떻게 만드느냐가 가장 중요하다. (키 값을 어떤 방법으로 나눴을때 가장 분산되어서 탐색에 소요되는 시간을 줄일지를 잘 정해야한다.)
아무리 해시 함수를 잘 만들었다고 해도 해시 충돌 (콜리전: 서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황) 이 일어날 수 있다.
콜리전이 발생 했을때 어떻게 처리해야 할까 ?
[자료구조]해싱, 해시 테이블 그리고 Java HashMap - adam2
이 글을 참고해보자 .
참고로 콜리전을 사진으로 예를 들어보자면 이렇다.
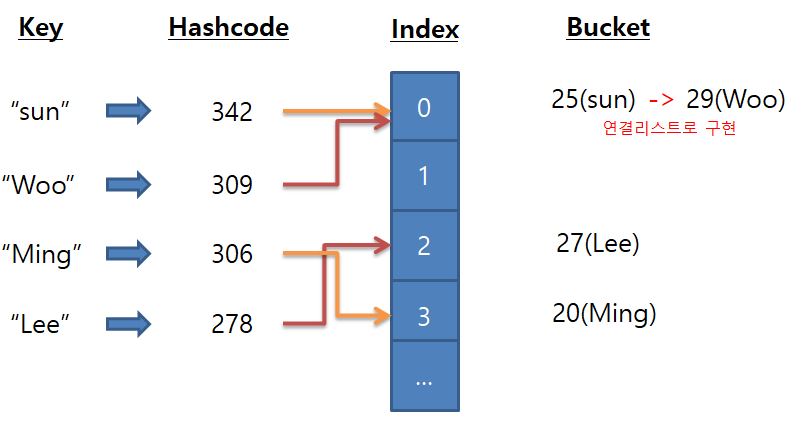
출처 : https://wodonggun.github.io/algorithm/%ED%95%B4%EC%8B%9C-%EC%A0%95%EB%A6%AC.html
이렇게 한 인덱스에 하나의 값이 와야하지만 중복되어 값이 들어온다면 해시 충돌이 일어나게 된다.
다음 자료구조에 관련된 글에는 각 자료구조를 직접 구현해볼 예정이다~ 💃
