
elasticsearch를 설치해서 검색엔진 기능을 구현하려고 한다. 그 전에 환경설치부터 진행해보자
ℹ️ 설치환경
ubuntu20.04ealsticsearch@7.12.1: Distributed RESTful search engine built for the cloudlogstash@1:7.12.1-1: An extensible logging pipelineopenjdk@11.0.11: java development kit (java 개발키트, 내부에 자바 런타임이 있음)mysql-connector-java@8.0.25: MySQL connector (MySQL의 JDBC를 위한 드라이버)logstash-integration-jdbc: Logstash Integration Plugin for JDBC, including Logstash Input and Filter Plugins (자바에서 db연결하는 API)analysis-nori@7.12.1: 한글형태소 분석기
1. elasticsearch
한글 형태로 단위로 효율적인 검색을 하기 위한 db
1-1. install elasticsearch
# Download and install the public signing key:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# install apt-transport-https:
sudo apt-get install apt-transport-https
# Save the repository definition to /etc/apt/sources.list.d/elastic-7.x.list:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
# install elasticsearch
sudo apt-get update && sudo apt-get install elasticsearch1-2. elasticsearch 실행
elasticsearch는 자동으로 실행되지 않는다.
여러실행방식이 있지만 systemctl로 실행해보자.
# 실행
sudo systemctl start elasticsearch.service
# 중단
sudo systemctl stop elasticsearch.service
# 실행확인방법
curl -X GET "localhost:9200/?pretty"1-3. logs 및 설정파일
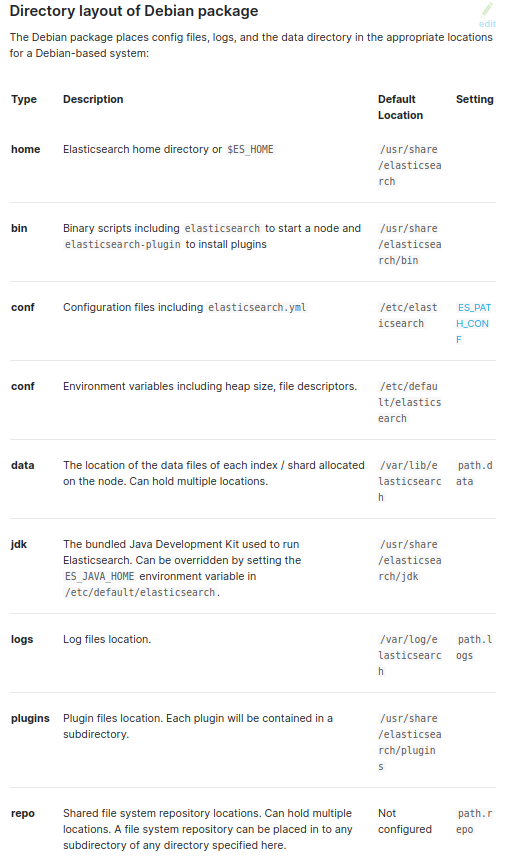
2. JDK
logstash나 elasticsearch의 최신버전(7.12)은 모두 내장된 jre를 가지고 있지만 JAVA_HOME을 설정하여 명시적인 환경변수를 선택해서 활용하는것이 더 낫다고 여김.
Elasticsearch and JVM Matrix를 보면 openjdk-11-jdk가 가장 범용성이 있어보여 그것으로 진행할 예정.
# search
apt search openjdk-11
# install
sudo apt-get install openjdk-11-jdk
# 설치확인
java --version
# 설치된 자바 패키지 리스트 확인
update-java-alternatives -l
#/usr/lib/jvm/java-1.11.0-openjdk-amd64 이 리스트업됨.
# 환경설정하기
export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
# 환경설정확인
echo $PATHubuntu man_for update_java_alternatives
3. logstash
mysql의 데이터를 사용해서 elasticsearch에서 검색을 하기위해서는 elasticsearch db에 데이터를 담아야한다. 이를위한 도구로서 logstash를 사용함.
3-1. install logstash
#### 위에서 이미 했으면 반복할 필요 없음
# download and install the public signing key:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
#### 위에서 이미 했으면 반복할 필요 없음
# install apt-transport-https:
sudo apt-get install apt-transport-https
#### 위에서 이미 했으면 반복할 필요 없음
# Save the repository definition to /etc/apt/sources.list.d/elastic-7.x.list:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
# install logstash
sudo apt-get update && sudo apt-get install logstash
# stashing first event
# `Pipelines running` 이라고 뜨면 아무 글이나 치고 `enter`를 치면 message가 뜸. 종료는 ctrl-d
sudo bin/logstash -e 'input { stdin { } } output { stdout {} }'3-2. logstash 실행
elasticsearch는 자동으로 실행되지 않는다.
여러실행방식이 있지만 systemctl로 실행해보자.
# 실행
sudo systemctl start logstash.service
# 중단
sudo systemctl stop logstash.service3-3. logs 및 설정파일
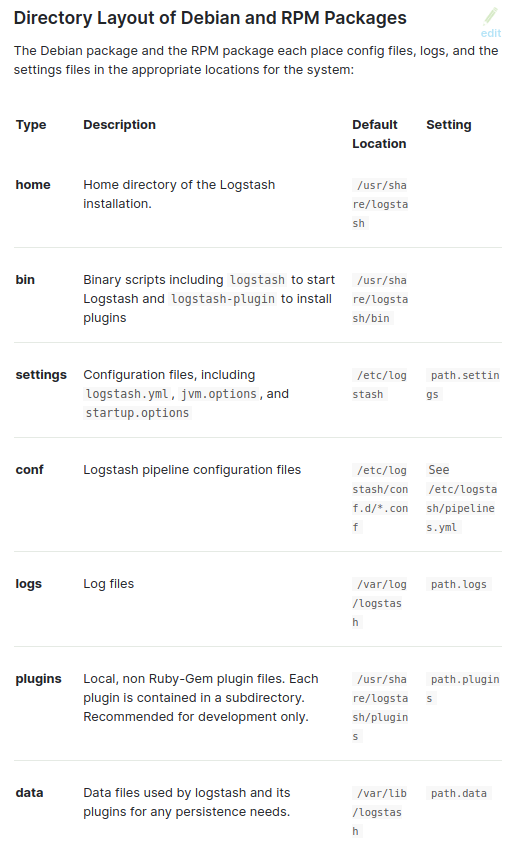
4. mysql과 logstash input과 연결하기
logstash의 input에 mysql의 데이터를 담기위해서는 jdbc와 jdbc를 위한 mysql 드라이버가 필요하다.
4-1. DB-connector
일단 jdbc를 위한 mysql 드라이버를 설치하자.
db와 연결하기 위해서 db-connector를 설치한다. DB-connector 공식사이트에서 파일을 직접 다운받아 수동으로 설치할 수 있겠지만(수동설치 참고링크) apt search mysql-connector-java를 해본결과 최신버전이 있기에 나는 apt-get 으로 설치 진행함.
apt-get을 통한 설치는 종속패키지도 자동으로 설치해주고 설치이력도 남겨주고 추후 삭제도 편리하기 때문에 애용함.
install mysql-connector-java 설치
# 검색
# mysql-connector-java 검색됨.
apt search mysql-connector-java
# install mysql-connector-java
# 설치하면 mysql-connector-java-8.0.25.jar 가 /usr/share/java 에 위치함.
sudo apt-get install mysql-connector-java
4-2. logstash-integration-jdbc
두번째로
logstash에 db를 연결해줄 jdbc를 설치하자.
mysql의 데이터를 logstash의 input으로 연결할 것이기 때문에 logstash-integration-jdbc를 설치한다.
logstash-integration-jdbc는 Logstash Integration Plugin for JDBC, including Logstash Input and Filter Plugins 이다.
logstash-integration-jdbc
├── logstash-input-jdbc
├── logstash-filter-jdbc_streaming
└── logstash-filter-jdbc_staticinstall logstash-integration-jdbc 설치
# /usr/share/logstash
bin/logstash-plugin install logstash-integration-jdbc
# 설치확인
bin/logstash-plugin list | grep logstash-integration4-3. *.conf 파일 만들기
/usr/share/logstash에 임의의 logstash conf파일을 만든다.
아래 *.conf는 mysql 데이터가 logstash에 input이 잘 되는지 확인을 위한 임시conf 파일임
#broccoli.conf
input {
jdbc {
jdbc_driver_library => "/usr/share/java/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/<db명>"
jdbc_user => "<db 접근 user>"
jdbc_password => "<db 접근 비밀번호>"
statement => "SELECT * from posts"
schedule => "* * * * *" # Query주기 설정
}
}
# 필터가 필요하다면 아래 설정
filter {
}
# 테스트를 위해 터미널에 output 설정
output {
stdout{}
}logstash 실행해보기
sudo bin/logstash -f broccoli.conf 😍😍😍 잘된다.
ℹ️ 이제 본격적으로 *.conf 파일을 수정해야하는데 체크해야하는 점이 있다.
- 스케쥴마다 조회된 쿼리가 계속 input에 중복적으로 담기는 것을 해결해야한다.
- mysql데이터가 계속 수정될수 있기 때문에 수정된 데이터를 watch하여 logstash 담긴정보도 수정되야한다.
- 효율적인 sync를 해야함(수정된부분만 input에 변경적용되야함.)
- elasticsearch에 출력해야함.
이 4가지는 아래 수정한 conf파일에 적용되있는데 링크를 참조해서 만들어보자.
Logstash와 JDBC를 사용해 Elasticsearch와 관계형 데이터베이스의 동기화를 유지하는 방법
4-4. *.conf 파일 수정하여 mysql 데이터와 sync 맞추기
위에 임시 conf를 활용해 logstash를 실행해본결과 1분마다 해당 쿼리가 input에 계속 입력됨을 확인할 수 있다. 따라서 위에 임시로 만든 broccoli.conf를 수정하자.
아래 *.conf파일의 모르는 부분은 위 링크: Logstash와 JDBC를 사용해 Elasticsearch와 관계형 데이터베이스의 동기화를 유지하는 방법을 참고하자.
input {
jdbc {
jdbc_driver_library => "/usr/share/java/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/<db명>"
jdbc_user => "<db 접근 user>"
jdbc_password => "<db 접근 비밀번호>"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
statement => "SELECT *, UNIX_TIMESTAMP(updatedAt) AS unix_ts_in_secs FROM posts WHERE (UNIX_TIMESTAMP(updatedAt) > :sql_last_value AND updatedAt < NOW()) ORDER BY updatedAt ASC"
schedule => "*/5 * * * * *" # Query주기 설정
last_run_metadata_path => "/usr/share/logstash/.logstash_jdbc_last_run"
}
}
# 필터가 필요하다면 아래 설정
filter {
mutate {
copy => {"id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
# Elasticsearch로 output 설정
output {
# stdout {}
elasticsearch {
hosts => "http://localhost:9200"
index => "broccolisearch"
document_id => "%{[@metadata][_id]}"
}
}
이렇게 하면 localhost:9200/broccolisearch라는 경로를 통해 broccolisearch라는 elasticsearch인덱스가 생성됨을 확인 할 수 있다.
5. elasticsearch 검색
ℹ️ curl로 해도되고 브라우저 url을 직접 쳐도 되지만 브라우저에서 한다면 미리 JSON Formatter를 설치하자. json을 자동으로 pretty해준다.
# index 구조
curl localhost:9200/<생성한 index>위에 curl을 치면 json 형태로 alias, mappings, settins 로 구분된 정보가 보인다.
- settings은 index의 설정관련 부분이다.
- mappings는 index에 담긴 정보의 프로퍼티부분이다. 자세히 보면 mysql에서 가져온 데이터의 컬럼속성이 mapping된 부분인것을 확인 할 수 있다.
# index 에서 전체 search시
curl localhost:9200/<생성한 index>/_search
# index 에서 특정단어 search시
curl localhost:9200/<생성한 index>/_search?q=<검색하고자하는단어>전체검색에서 보인 단어를 통해 특정단어를 검색했는데.... 안나옴. 😢😢 이유는 두가지인데
- 한글을 url로 보낼때 encoding이 필요한데 curl로 할때는 옵션을 설정해줘야함.
- 한글은 영어와 달라서 특정한 형태소 분석기를 index field에 설정하지 않으면 원하는대로 한글검색이 되지 않음.
일단 형태소 분석기 설치하자.
5-1. nori 설치
nori는 elasticsearch에서 공식적으로 사용하는 한글 형태소 분석기이다.
install nori
# /usr/share/elasticsearch 에서
# nori 설치
sudo bin/elasticsearch-plugin install analysis-nori
# nori 제거
sudo bin/elasticsearch-plugin remove analysis-noriindex에 설정하기
아래 예와 같이 index의 mappings 부분에
analyzer가 있어야 하는데 이 부분을 추가해주려면 기존의 index 설정 값을 변경해야한다. 하지만 기존에 있는 properties의 mapping값은 수정이 안된다. 수정을 하고 싶다면_reindex를 통해 설정해주어야한다.
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "broccoli_nori_discard"
},
"text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "broccoli_nori_discard"
}
}
},_reindex해보기는 링크를 통해서 참조하기 바람.
검색하기
_reindex를 통해 index에 analyzer를 설정했다면 이제 한글검색을 해보자!!
curl -G --data-urlencode "q=((가을)AND(낭만))OR(세잔)" localhost:9200/test/_search?prettycurl의 url을 encode할때는 위와 같은 방식으로 하면 된다.
elasticsearch의 검색 방법은 FULL TEXT QUERY 링크를 참조하자
참고링크
