4장. 커넥션 관리
이제 슬슬 뇌에 힘을 주고 읽기 시작했다. 그렇지 않으면 이해할 수가 없거든 😇
모든 HTTP 통신은 TCP로 이루어진다. 그래서 이번 장에서는 HTTP 통신에 영향을 미치는 TCP 통신의 특징도 짚고 넘어갈 것이다.
TCP 커넥션의 특징
- HTTP 메세지는 (네트워크만 정상적이라면) 손실, 손상되지 않고 순서가 바뀌지 않는다.
- 세그먼트 단위로 데이터 스트림을 쪼개고, 세그먼트를 IP 패킷 안에 넣어서 데이터를 전달한다. → 이 과정은 HTTP 프로그래머한테는 보이지 않는다. HTTP 가 TCP/IP 보다 상위 레이어이기 때문이다.
- 서로 다른 TCP 커넥션은 아래 4가지 요소 중 적어도 1개가 달라야 한다. 그렇지 않으면 동일한 커넥션이다.
- 발신지 IP 주소
- 발신지 포트
- 수신지 IP 주소
- 수신지 포트
소켓을 연다는게 도대체 뭔소리?
냐고 생각하고 학부 네트워크 수업을 얼렁뚱땅 넘어간 적이 있었다. 이번에 또 그럴 순 없어서 한번 찾아봤다.
A network socket is a software structure within a network node of a computer network that serves as an endpoint for sending and receiving data across the network. … The application programming interface (API) for the network protocol stack creates a handle for each socket created by an application, commonly referred to as a socket descriptor. In Unix-like operating systems, this descriptor is a type of file descriptor.
네트워크 소켓은 네트워크를 통해 엔드포인트로 데이터를 주고받기 위해 컴퓨터 네트워크의 네트워크 노드에 존재하는 소프트웨어 구조입니다. … 네트워크 프로토콜 스택용 API(응용 프로그래밍 인터페이스)는 일반적으로 소켓 설명자 라고 하는 응용 프로그램에서 만든 각 소켓에 대한 핸들을 만듭니다. Unix 계열 운영 체제 에서 이 설명자는 일종의 파일 설명자 입니다 .
- What is a Socket? a way to speak to other programs using standard Unix file descriptors.
- 소켓이란? 유닉스 file descriptor를 사용해 다른 프로그램과 통신하는 방법을 말합니다.
음. 그러니까 소켓을 연다는건 file descriptor 를 사용해 통신할 통로를 여는 것과 같다. 왜 file descriptor 를 쓰냐면 유닉스의 모든 것은 파일이기 때문이다. 그래서 ‘다른 컴퓨터와의 통신’ 도 파일로 표현한다.
File descriptor 는 프로세스가 연 파일을 식별하기 위한 정수값이다. 어떤 프로세스가 파일 100개를 열었다면 100개의 file descriptor 가 생겨날 것이다. File descriptor API를 사용해서 데이터를 읽고, 쓰고, 프린트하고, 주고받을 수 있다. 터미널창에서 파일을 열고 편집하는 그 과정이 file descriptor 를 통해 이루어지는 것이다.
소켓을 연다는건 file descriptor 를 하나 만들고 파일에다가 데이터를 적음으로써 데이터를 교환할 준비를 하는 것이라고 이해하면 될 것 같다. 파일에 데이터를 적기만 하는데 이게 어떻게 다른 컴퓨터로 전송이 되나? 하는건 OS 레벨에서 이루어진다. OS에서 특정 포트로 들어오는 네트워크 연결을 받아들이고 file descriptor 에 바인딩 할 것이다. (C의 네트워크 API 목록과 설명 을 참고하자.)
HTTP 성능에 영향을 주는 TCP 성능
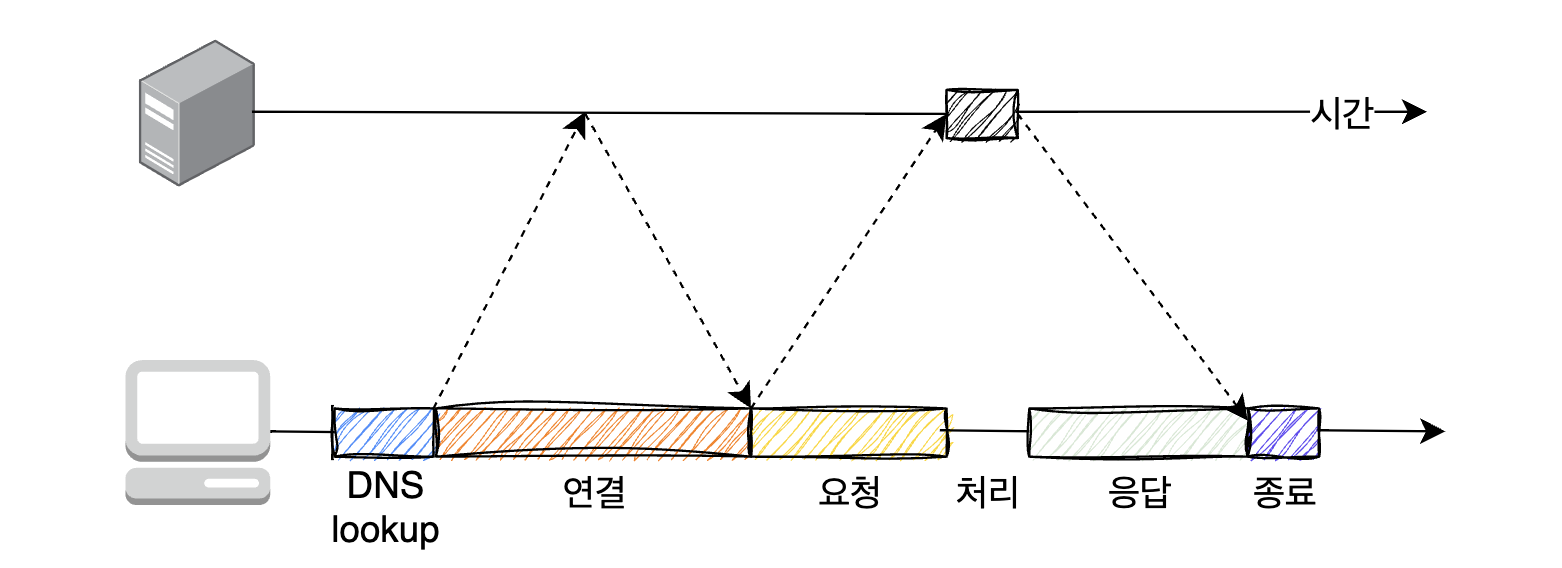
서버가 HTTP 트랜잭션을 처리하는데 걸리는 시간은 TCP 커넥션을 설정하고, 요청을 전송하고, 응답 메세지를 보내는 것에 비하면 상당히 짧다. 대부분 HTTP 지연의 원인은 서버의 처리 지연보다는 이러한 TCP 네트워크 지연에 있다.
… 라는 예전 이야기가 책에 적혀있다. 책 번역본은 2022년 판인데, 옮긴이가 이렇게 각주를 달아 놓았다.
(본문) DNS 이름 분석 인프라를 사용하여 URI에 있는 호스트 명을 IP 주소로 변환하는데 수십 초의 시간이 걸릴 것이다.
(각주) (옮긴이) 현재는 인터넷 인프라의 발전으로 대부분 밀리초 단위로 DNS 분석이 끝난다. host 명령어로 얼마나 걸리는지 체감해볼 수 있다. 예> host google.com
(본문) 커넥션 설정 시간은 새로운 TCP 커넥션에서 항상 발생한다. 이는 보통 1~2초의 시간이 소요되지만, …
(각주) (옮긴이) 이 역시 인터넷 인프라의 발전으로 대부분 1초 미만으로 끝난다.
그럼에도 불구하고 TCP 자체의 특징으로 인해 약간의 지연은 발생할 수 있다.
- 확인 응답 지연: 데이터 전송이 성공적으로 이루어졌음을 의미하는 ACK를 보내야 할 때, piggyback 할만한 패킷을 찾지 못하는동안 발생하는 대기 시간.
- 물론 무한정 대기하지는 않는다. 일정 시간이 지나면 별도 패킷을 만들어서 ACK를 보낸다.
- TCP 느린 시작: TCP는 한번에 전송할 수 있는 패킷의 수를 제한한다. 1개로 시작해서 확인 응답을 받을 때마다 2개씩 늘어난다.
- 그래서 새로운 커넥션은 이미 어느 정도 데이터를 주고받은 커넥션보다 느리다.
- 네이글 알고리즘: TCP 세그먼트는 무겁다. 여러 플래그와 헤더를 포함하기 때문이다. 스트리밍 상황에서 크기가 작은 데이터를 보내는 다수의 세그먼트를 하나의 덩어리로 합치는 알고리즘이 네이글 알고리즘이다. 세그먼트가 최대 크기가 될 때까지 전송을 하지 않고, 데이터를 버퍼에 저장해놓고 기다린다. 이게 왜 문제가 되냐면…
- 첫째) 크기가 작은 HTTP 메시지는 패킷 최대 크기를 못 채우기 때문에 앞으로 오지 않을 추가적인 데이터를 계속 기다리게 될 수도 있다.
- 물론 이전에 보냈던 모든 패킷이 확인 응답을 받았을 때는 최대 크기를 덜 채워도 패킷 전송을 할 수 있다. 덕분에 무한정 기다리지는 않아도 되지만, 이전에 보낸 모든 패킷에 대한 ACK를 받을 때까지는 기다려야 한다.
- 둘째) 확인 응답 지연과 상성이 아주 나쁘다. 네이글 알고리즘은 확인 응답이 도착할 때까지 데이터 전송을 멈춘다. 그런데 확인 응답 지연 알고리즘은 확인 응답을 100~200 밀리초 지연시킨다.
TCP_NODELAY파라미터값을 설정하면 네이글 알고리즘을 비활성화 할 수 있다. 대신 그렇게 했다면 작은 크기의 패킷이 너무 많이 생기지 않게 만들어야 한다.
- 첫째) 크기가 작은 HTTP 메시지는 패킷 최대 크기를 못 채우기 때문에 앞으로 오지 않을 추가적인 데이터를 계속 기다리게 될 수도 있다.
HTTP 커넥션 생성하고 최적화하기
이제 다시 HTTP 로 돌아와보자.
흔히 잘못 이해하는 Connection 헤더
HTTP 메세지가 클라이언트에서 목적지 서버까지 도달하기 위해 게이트웨이나 프록시 등 다른 서버를 거칠 수 있다. 만약 어떤 헤더가 특정 홉에서만 전달되어야 한다면 HTTP Connection 헤더 필드를 사용하면 된다. 단, 아래 3가지 토큰이 전달될 수 있어서 다소 혼란스러울 수 있다.
- HTTP 헤더 필드 명: 이 커넥션에만 해당되는 헤더 목록
- 임시적인 토큰 값: 커넥션에 대한 비표준 옵션
- close 값: 커넥션이 완료되면 종료되어야 함을 의미.
아래는 meter 헤더를 다른 커넥션으로 전달하면 안되고 bill-my-credit-card 옵션을 적용할 것이며 이 트랜잭션이 끝나면 커넥션이 끊길 것이라고 알려주는 메세지다.
HTTP/1.1 200 OK
Cache-control: max-age=3600
Connection: meter, close, bill-my-credit-card
Meter: max-uses=3, max-refuses=6, dont-reportHTTP 커넥션
HTTP 커넥션의 성능을 향상시킬 수 있는 기술 3가지
병렬 커넥션
클라이언트는 동시에 HTTP 커넥션 여러개를 맺을 수 있다. 즉, 앞서 보낸 HTTP 트랜잭션의 응답을 받기 전에 새로운 요청을 보낼 수 있으며 서로 다른 호스트에게 보낼 수도 있다. 병렬 커넥션이 항상 단일 커넥션보다 빠르지는 않다. 네트워크 대역폭이 좁을 때는 여러개의 커넥션을 생성하면서 생기는 부하 때문에 순차적으로 데이터를 받는 것보다 오래 걸릴 수도 있다. 메모리도 많이 소모하게 된다.
브라우저는 실제로 병렬 커넥션을 사용하지만 적은 수의 병렬 커넥션만을 허용한다. 원문에는 “대부분 4개”라고 되어있으나 옮긴이는 “현재 최신 브라우저들은 대부분 6~8개의 병렬 커넥션을 지원한다.”고 한다.
지속 커넥션
사이트 지역성(site locality)을 활용하기 위해 한번 맺어진 TCP 커넥션을 유지하여 트랜잭션 여러개를 만들 수 있다. 클라이언트나 서버가 커넥션을 끊기 전까지는 계속 유지된다.
지속 커넥션과 병렬 커넥션을 활용하면 시너지 효과가 난다. 적은 수의 병렬 커넥션을 맺고 이걸 계속 유지하는 것이다. HTTP 버전별로 이를 위한 커넥션이 마련되어있다.
지속 커넥션을 인식하지 못하는 이전 버전의 프락시 서버를 ‘dumb proxy’ 라고 부른다. 클라이언트 입장에서는 계속 유지되고 있는 커넥션으로 요청을 보내지만 프락시 서버는 그 요청을 무시해버리기 때문에, 브라우저는 자신이나 서버가 타임아웃이 나서 커넥션이 끊길 때까지 기다리게 된다. 즉, 프락시 서버에서 keep-alive 을 명확히 구현하는 것이 중요하다.
파이프라이닝 커넥션
HTTP/1.1 은 지속 커넥션을 통해 요청을 파이프라이닝, 그러니까 병렬 처리 할 수 있다. 덕분에 keep-alive 커넥션의 성능이 더 높아질 수 있다. 하나의 트랜잭션이 끝날 때까지 기다릴 필요 없이 곧바로 다음 트랜잭션을 시작할 수 있기 때문이다. 병렬 커넥션과의 차이점은 지속 커넥션이기 때문에 매 트랜잭션마다 HTTP 커넥션 open, close 단계가 없다는 것이다.
이렇게 말하면 파이프라이닝 커넥션을 사용하는게 만능 해결책 같아보이지만 몇가지 고려사항이 있다.
- 클라이언트는 커넥션이 끊어지는 상황을 대비해야 한다. 완료되지 않은 요청이 있는데 커넥션이 끊겼다면 다시 커넥션을 맺고 남은 요청을 보낼 수 있어야 한다.
- 파이프라인을 통해 보낸 요청 중 일부만 실패했을 때 클라이언트는 어떤 요청이 실패했는지 알 수 없다. 재시도를 위해 멱등성이 없는 POST 요청을 재차 보내면 문제가 생길 수 있기 때문에 이런 요청을 보내지 말아야 한다.
HTTP 커넥션 끊기
이 부분에서는 크게 건질만한 내용이 없었다. 책에서 이렇게 말하고 있기 때문이다.
커넥션 관리(특히 언제 어떻게 커넥션을 끊는가)에는 명확한 기준이 없다. 이 이슈는 수많은 개발자가 알고 있는 것보다 더 미묘하며, 그에 관한 기술 문서도 별로 없다. (115p.)
HTTP 명세에서는 클라이언트나 서버가 예기치 않게 커넥션을 끊어야 한다면, “우아하게 커넥션을 끊어야 한다”라고 하지만, 정작 그 방법은 설명하지 않고 있다. (119p.)
커넥션 절반만 끊기
다만 한가지 새로운 사실은 HTTP 커넥션(TCP 커넥션)을 절반만 끊을 수 있다는 것이다. TCP 커넥션의 양쪽에는 데이터를 읽거나 쓰기 위한 queue가 있는데 이 둘 중 하나만 끊는 것이다. 아래는 서버가 입/출력을 모두 끊거나, 출력만 끊거나, 입력만 끊는 모습을 나타낸 것이다.
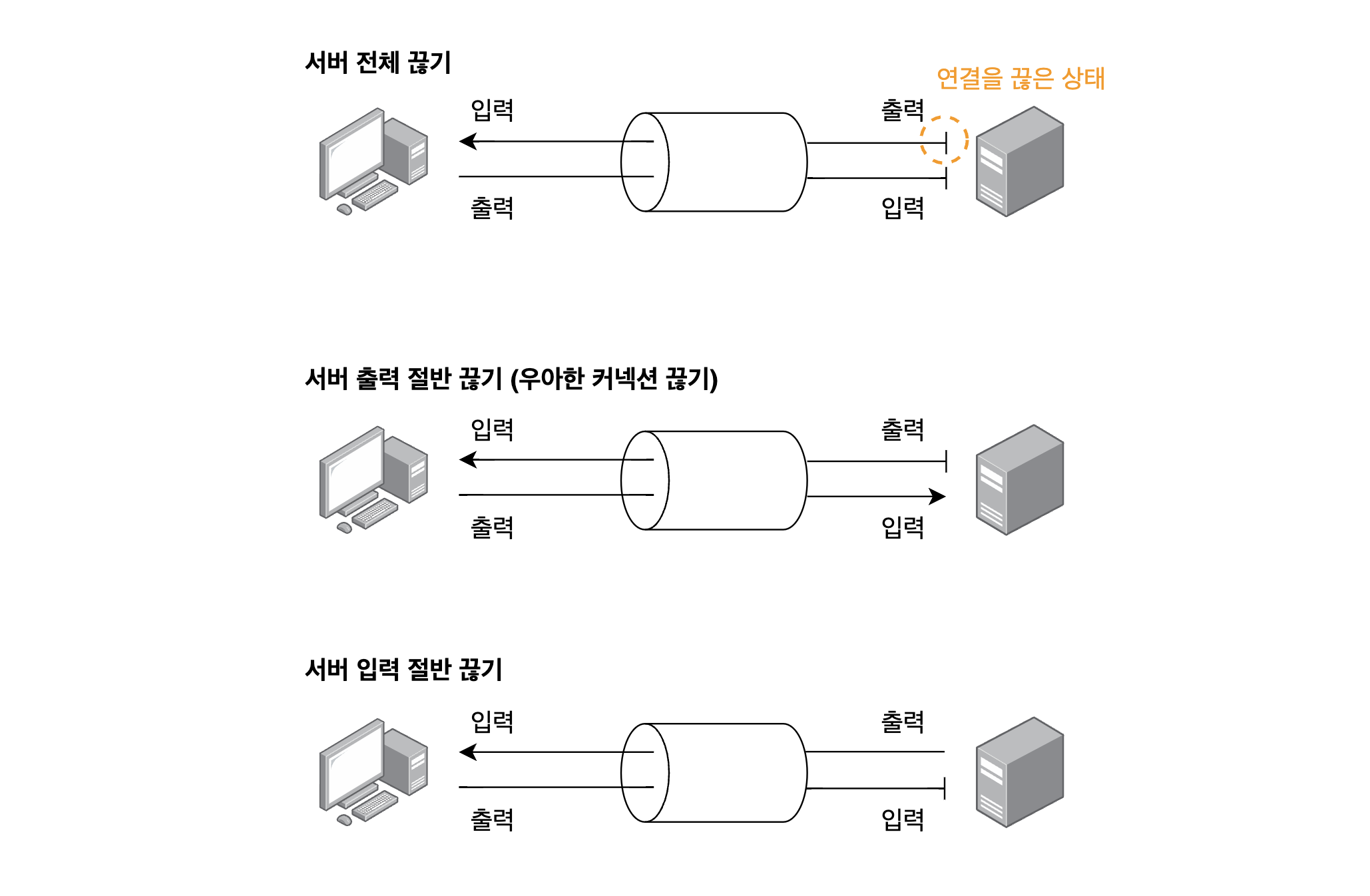
TCP connection reset by peer
첫번째 그림은 서버가 입출력을 모두 끊은 상태, 즉 TCP 커넥션 전체를 끊은 것이다. 일반적인 HTTP 애플리케이션은 서버 전체 끊기만 사용할 수 있다. 만약 클라이언트가 이미 연결이 끊긴 서버의 입력 채널로 데이터를 보낸다면 서버는 TCP connection reset by peer 메세지를 클라이언트한테 보낸다. 이 메세지를 잘 기억해두자. 언젠가 이런 메세지를 마주친다면 ‘음 서버가 이미 연결을 끊었는데 클라이언트는 그걸 모르고 요청을 보내버렸군’ 이라고 이해하면 된다.
주의할 점은 이 메세지를 받았다면 클라이언트 애플리케이션은 응답 데이터를 절대 읽을 수 없다는 것이다. 어찌보면 당연한 소리긴 한데, 이런 경우가 발생할 수 있다: 요청 10개를 파이프라인 지속 커넥션을 통해 전송했고, 응답이 OS의 버퍼에 있지만 애플리케이션은 아직 이를 읽지 않은 상태에서 요청 1개를 더 보낸 뒤 connection reset by peer 메세지를 받은 경우. 그냥 생각하기로는 ‘앞에서 받은 응답 10개는 읽고 마지막 요청에 대한 데이터만 못 받겠군’ 이라는 생각이 들지만, 애플리케이션은 OS의 버퍼에 있는 응답 10개마저 읽을 수 없다. 대부분의 OS 에서는 저 메세지를 심각한 에러로 취급해서 버퍼에 있는 데이터를 모두 삭제해버리기 때문이다.
우아한 커넥션 끊기
두번째 그림의 서버의 출력을 절반만 끊는 것을 ‘우아한 커넥션 끊기’ 라고 한다. 위 인용구에서 나온 ‘우아하게 커넥션을 끊는’ 방식인데, 일반적으로 이를 구현하는 것은 그림에서 보듯이 자신의 출력 채널을 먼저 끊고 반대쪽이 출력 채널을 끊기를 기다리는 식으로 만들어진다. 생각해보면 세번째 그림보다 이게 좀 더 우아해 보인다.
하지만 클라이언트 입장에서 어떤 서버가 절반 끊기를 구현했다는 사실을 명확히 알 수 있는 방법은 없다. (클라이언트와 서버 개발자가 한 몸이라면 알 수 있겠지만 말이다.) 따라서 애플리케이션은 자신의 입력 채널에 대한 상태 검사를 주기적으로 하고 타임아웃 시간을 설정해 특정 시간이 지나면 강제로 연결을 끊는 방법을 택할 수 있다.
이번 장에서는 TCP 커넥션 특징을 바탕으로 HTTP 커넥션을 생성하고, 최적화하고, 연결을 끊는 방법에 대해 살펴봤다.
다음 장부터는 웹서버, 프락시 등 HTTP 커넥션을 실제로 써먹는 사례를 만날 수 있을 것 같다. 두근두근 🤗

오늘도 제 북마크에 추가되셨습니다