
데이터 중심 애플리케이션 설계, 마틴 클레프만 지음. OREILLY.
Partitioning 파티셔닝
용어 정리
파티션, 샤딩, 샤드, ... 왠지 비슷해보이면서도 다른 것 같고, 뭔지 모를 용어가 많다. 책에서는 용어 정리부터 짚고 넘어간다. 역시 이 책.. 마음에 든다.😎
- 파티션: 대용량 데이터를 작은 단위로 쪼갠 것. 즉, 데이터 덩어리(혹은 이를 관리하는 DB).
- 데이터베이스별로 서로 다른 용어를 사용한다. 이로 인해 용어 혼동이 올 수 있다.
- 몽고DB, 엘라스틱서치, 솔라클라우드: 샤드(shard)
- HBase: 리전(region) / 빅테이블: 태블릿(tablet) / 카산드라, 리악: 브이노드(vnode) / 카우치베이스: 브이버켓(vBucket)
- (... 첫줄 빼고는 모두 처음 들어보는 데이터베이스들이다.)
- 하지만 파티션이 가장 널리 쓰이기 때문에 책에서도 이 용어를 계속 사용한다.
- 데이터베이스별로 서로 다른 용어를 사용한다. 이로 인해 용어 혼동이 올 수 있다.
- 샤딩(= 파티셔닝): 대용량 데이터를 작은 단위로 쪼개는 작업. 즉, 파티션을 생성하는 작업.
최종 목적 & 방법
파티셔닝의 목적 3가지
- 한쪽 파티션으로만 질의 요청이 몰리는 핫스팟 현상 피하기.
- 저장해야 하는 데이터 분산하기.
- 질의 요청 분산하기.
2, 3번을 따로 적은 이유는 서로 다른 일이기 때문이다. 데이터를 분산 저장한다고 해서 질의 요청도 분산된다는 보장은 없다.
예를 들어보자. 좋아하는 노래를 저장하는 폴더가 있다. 몇년동안 쓰다보니 노래가 너무 많이 쌓여서 지금보다 작은 폴더로 쪼개어 관리하고 싶어졌다. 장르별로 하위 폴더를 만들었다. 락발라드, 팝, 크리스마스 캐롤, 재즈 등으로 나눴다. 그런데 락발라드를 너무 좋아한 나머지 폴더 정리를 한 다음부터는 락발라드 폴더에만 들어가게 되었다.
이게 그냥 폴더일 때는 문제가 되지 않는다. 그런데 각 폴더가 데이터베이스라면? 질의 요청이 모두 DB 한개에만 집중되는 현상은 결코 좋지 않다. 이렇게 불균형하게 부하가 높은 부분을 핫스팟이라고 한다.
그래서 어떤식으로 데이터를 분산 시킬 것인지도 잘 고민해야한다. 잘 고민해서 미래에 들어올 질의 요청도 분산 시킬 수 있어야 한다. 이런 측면에서 위의 예시에서 사용한 분산 방식은 파티셔닝의 목적을 모두 달성하지 못했다고 볼 수 있다. (물론 위의 상황은 비유를 위한 가상의 상황이고 나는 저런식으로 폴더 정리를 한다.🙃)
목적을 달성하기 위한 방법
- 적합한 파티셔닝 방식 선택
- 재균형화
위 2가지 방법 중 택 1을 하는게 아니라, 2가지 방법을 모두 사용해야 한다. 자세한 내용은 이후에 나온다.
큰 그림: 복제와 파티셔닝
5장에서는 복제를 다뤘다. 복제와 파티셔닝은 서로 독립적인 개념이다.
- 복제: 기존 데이터와 같은 내용의 복사본을 만드는 것.
- 파티셔닝: 기존 데이터를 여러 부분으로 쪼개는 것.
복제와 파티셔닝 중 하나만 할 수도 있고, 둘 다 선택할 수도 있다. 대규모 데이터를 다루기엔 둘 다 선택하는 편이 안전하고 효율적이다.
보통 복제와 파티셔닝을 함께 적용해 각 파티션의 복사본을 여러 노드에 저장한다.
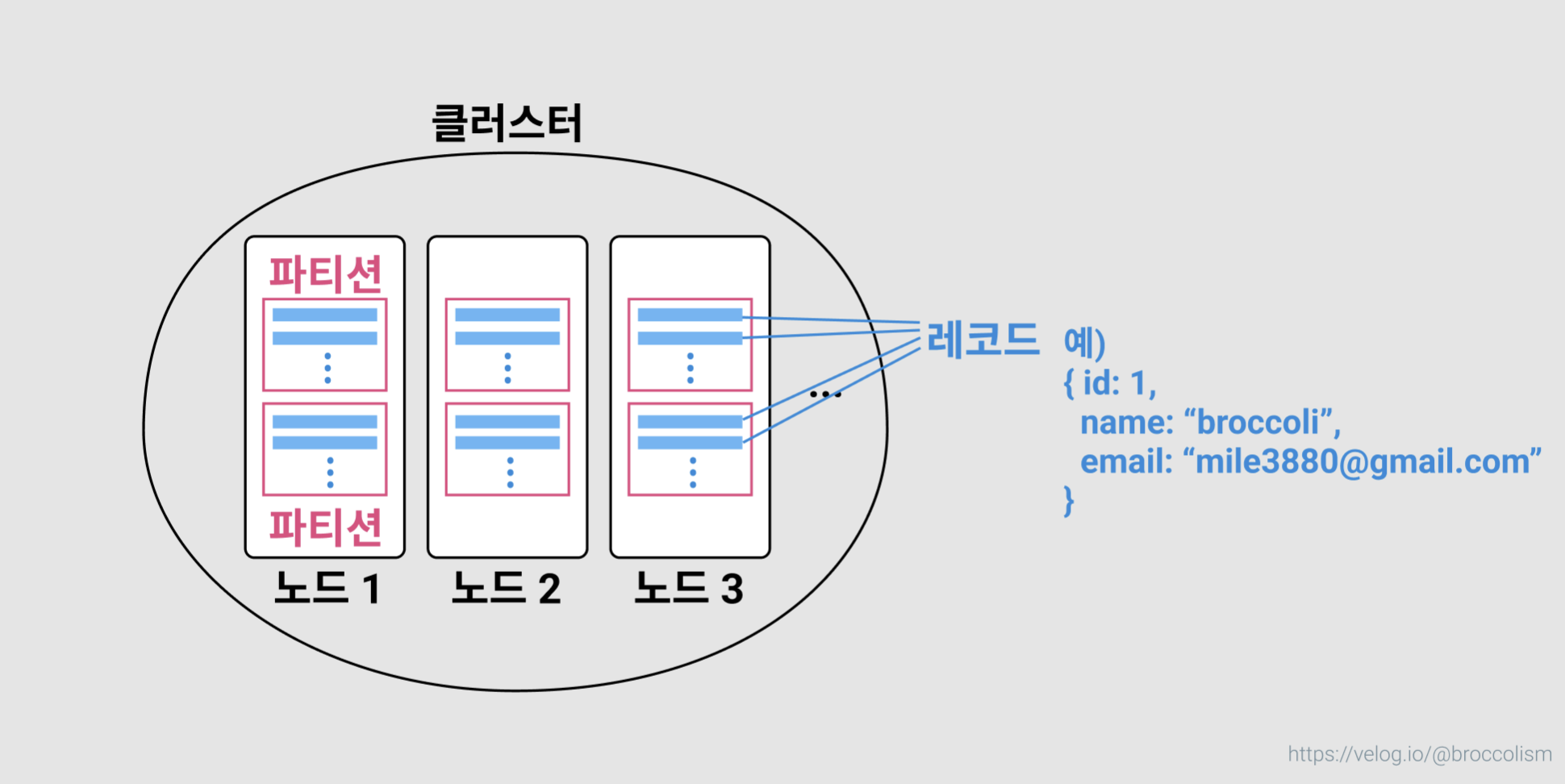
- 다음 두 작업은 독립적이다.
- 파티션은 파티셔닝(샤딩)의 결과로 생긴다.
- 여러개의 노드는 복제의 결과로 생긴다.
- 각 파티션의 복사본은 여러 노드에 저장할 수 있다: 파티셔닝 + 복제 모두 실행.
- 같은 내용의 레코드가 여러 파티션에 존재한다면 해당 파티션은 복제의 결과물이다.
- 노드 하나당 파티션을 1개, 2개, ..., N개 가질 수 있다.
파티셔닝 방식 - 누가 어디로 갈지 어떻게 정하지?
파티셔닝이 데이터를 쪼갠다는 것까지는 알겠다. 그러면 어떤 데이터가 어떤 조각으로 들어가면 좋을까? 이 결정을 내리는 곳은 2군데가 있다.
- 데이터베이스
- 애플리케이션
데이터베이스의 처리만으로 모두 해결할 수 없는 부분을 애플리케이션 수준에서 처리할 수 있다.
DB에서 처리하기
Naïve한 방식: 랜덤
- 장점: 데이터나 질의 요청이 쏠리는(skewed) 현상이나 핫스팟 발생을 회피할 수 있다.
- 단점: 말 그대로 '랜덤'이다. 어떤 데이터가 어떤 파티션에 들어가는지 모른다.
- 그래서 특정 데이터를 찾으려면 모든 파티션에 같은 질의 요청을 보내야 한다. 즉, 읽기 연산이
느려터졌느리다.
- 그래서 특정 데이터를 찾으려면 모든 파티션에 같은 질의 요청을 보내야 한다. 즉, 읽기 연산이
키 범위 파티셔닝
각 데이터 row(혹은 레코드)마다 키를 부여한다. 그리고 키를 기준으로 정렬한 다음 데이터를 쪼갠다. 결과물은 마치 백과사전처럼, 키가 특정 범위에 속하는 데이터들이 하나의 파티션에 모이게 된다. 각 파티션별 크기는 관계없다.
- 장점: 특정 범위를 읽는 작업이 쉽다.
- 단점: 쏠림 현상이 발생할 수 있다.
해시 파티셔닝
키 범위 파티셔닝의 단점인 쏠림 현상을 보완하기 위한 방법이다. 키를 해시함수에 집어넣고 그 결과를 사용해서 백과사전을 만든다. 키 범위 파티셔닝에 무작위성을 약간 더한 방식이다. 여기서도 각 파티션별 크기는 상관없다.
- 장점: 쏠림 현상을 방지할 수 있다. 해시함수를 썼기 때문이다.
- 단점: 범위 스캔이 어려워진다. 해시함수를 썼기 때문이다.
이렇게 보면 DB에서 누가 어디로 갈지 정하는 방식에 trade-off가 존재함을 알 수 있다. 쏠림이나 핫스팟을 인정하는 것 vs. 범위 검색 연산을 포기하는 것.
앱에서 처리하기
DB 혼자서 도저히 쏠림 현상을 해결할 수 없는 상황일 때에는 애플리케이션 수준에서 처리해야 한다. 예를 들어보자. 트위터처럼 팔로우 관계가 있는 소셜 앱을 만들고 싶다. 파티셔닝의 키로 사용자의 아이디를 쓸 것이다. 이렇게 되면 팔로우 100만명 유명인이 등장했을 때, DB 혼자서는 키 범위/해시 파티셔닝 중 어떤 방식을 써도 쏠림 현상을 막을 수 없다. 이럴 때 앱 수준에서 사용자 아이디가 아닌 다른 조건을 걸어서 데이터/질의 요청을 분산시켜야 한다.
데이터 찾기 - 누가 어디에 있는지 어떻게 알지?
쓰기 작업을 어떻게 할 지 알아본 다음에는 읽기 작업을 어떻게 할지가 나온다.
요청 라우팅
= 요청을 받았을 때, 어떤 요청이 어느 파티션으로 갈지 결정하는 작업.
보통 어떤 데이터가 어디에 있는지를 담은 메타데이터를 따로 저장한다. 몽고DB의 경우, config server라고 부르는 곳에 누가 어디에 들어가있는지를 저장한다.
그동안 자주 만났던 오랜 친구.. 인덱스도 사용한다.
도와주세요: 보조 색인
그냥 색인이 아닌 보조 색인을 사용하는 이유는 검색을 해야 하기 때문이다. 저장할 때에는 키를 부여해서 색인을 만들었을 것이다. 읽을 때에는 키가 아닌 검색어 기준으로 데이터를 찾을 일이 많다. 키로는 부족하다. 보조 색인의 도움이 필요하다.
예시로는 자동차 데이터 검색이 나온다.
사용자들이 차를 검색할 때 색상과 제조사로 필터링 할 수 있게 하려면 color와 make에 보조 색인을 만들어야 한다.
책에 나온 보조 색인은 2종류가 있다. 문서 보조 색인과 용어 보조 색인이다. 서로 거의 반대되는 성질을 띈다.
문서 보조 색인
- 지역 색인(local index)를 사용한다.
- 즉, 각 파티션별로 locally 데이터를 읽은 다음
- 파티션별 검색 결과를 모으는 작업이 필요하다.
- 이 작업을 스캐터/개더(scatter/gather) 작업이라고 한다.
용어 보조 색인
- 전역 색인(global index)를 사용한다.
- 읽기 속도는 빠르지만 쓰기 속도가 느리다.
- 그래서 보통 쓰기 작업을 비동기로 처리한다.
- 읽기 속도는 빠르지만 쓰기 속도가 느리다.
Rebalancing 재균형화
= 한쪽 노드의 부하를 다른 노드로 이동시키는 작업.
서비스가 성장하면서 데이터가 점점 쌓이고, 마침내 부하가 너무 많이 걸려서 파티셔닝 효과가 미미해질 지경이 되면 재균형화가 필요하다. (표현이 그런거지, 이렇게 극단적인 상황이 될 때까지 기다리는게 일반적인 일은 아닐 것이다.)
비추하는 방식
해시값에 모듈러 연산을 때리는 것. 예를 들어, 파티션을 3개에서 6개로 늘리고 싶을 때 단순히 각 레코드별로 다음 연산을 수행하는 것이다.
- (레코드의 키 값) % 6 을 구한다.
- 구한 결과가 0, 1, 2, 3, ... 일 때 해당 레코드를 파티션 0, 1, 2, 3, ... 번으로 이동시킨다.
비추하는 이유는 불필요한 이동이 너무 많이 일어나기 때문이다. 데이터를 이동시키는 시간과 리소스도 비용이다. 분명 이것보다 비용을 줄일 방법이 있을 것이다.
추천하는 방식 3가지
책 그림을 보면 이해가 팍팍 된다. 누가 이렇게 똑똑한 방법을 고안했는지 신기할 따름이다.
- 파티션 개수 고정하기: 파티션을 노드 대수보다 많이 만들고 각 노드에 파티션을 여러개 할당한다. 데이터 이동이 현저히 줄어든다.
- 노드 비례 파티셔닝: 노드 당 할당되는 파티션 개수를 고정한다.
- 동적 파티셔닝: B-tree처럼 점점 child를 늘려간다. 키/해시 기준 파티셔닝 방식 모두에 적용 할 수 있다.
사람의 개입이 들어가는게 좋을까?
재균형화 작업을 완전 자동이 아닌 수동으로 하는게 좋을까? 여기서 '자동'이라 함은 재균형화를 할 타이밍을 잡고 실제 재균형화를 진행하는 것까지 자동으로 한다는 것이다.
지금까지 발달된 기술 상황을 고려한 대답은 '그렇다' 이다. 완전 자동/수동 뿐만 아니라 관리자의 승인이 필요한다던지 하는 중도적 방법도 있다. 이런 방식을 사용했을 때 좋은건 재균형화를 위한 시간을 확보할 수 있다는 점이다. 내가 잠자는 사이에 DB가 마음대로 재균형화를 시작했고, 데이터가 이동하는 동안 중요한 이벤트가 발생했거나 서버가 다운되었다면? 상상만 해도 아찔하다. 😇
다음 장은...
문제가 좀 더 복잡해진다. 여러 파티션에 쓰기를 시도했을 때, 한 쪽은 성공했는데 나머지는 실패했다면? 이런걸 상상하고 해결책까지 내놓은 학자들에게 박수를... 생각만해도 두근거린다.😇
