데이터 중심 애플리케이션 설계, 마틴 클레프만 지음. OREILLY.
3부에서는
서로 다른 데이터 모델과 데이터 접근 방식 등을 하나의 시스템으로 통합하는 방법을 알아본다. 10장에서는 일괄 처리 방식 데이터 플로 시스템, 11장에서는 데이터 스트림, 그리고 마지막 12장에서는 이 책의 결론이 나올 예정이다.
시스템의 종류
3가지로 분류할 수 있다.
- 서비스(온라인): 그동안 많이 접했던 일반적인 서버가 여기에 해당한다. 클라이언트의 요청을 기다렸다가 응답을 보낸다. 중요 지표는 응답 시간, 가용성이 있다.
- 일괄 처리 시스템(오프라인): 매우 큰 입력 데이터를 받아서 데이터를 처리하는 작업을 수행하고, 결과 데이터를 생산한다. 중요 지표는 처리량이 있다.
- 예) 전국 모의고사 답안지를 ORM 판독기를 통해 입력한 후 성적 처리하기
- 스트림 처리(준실시간): 위 두 시스템의 중간 단계. 일괄 처리 시스템처럼 요청과 응답 개념이 없고, 입력 데이터로부터 출력 데이터를 만들어낸다. 일괄 처리 시스템과 다른 점은 입력 데이터의 크기가 정해지지 않은 시점, 즉 입력 이벤트 하나가 발생하자마자 바로 작동한다는 것이다.
일괄 처리 시스템은 이번 장에서 다루고, 스트림 처리는 다음 장인 11장에서 다룬다.
유닉스 철학
10장은 유닉스 도구와 그의 철학에 대해 알아보는 것부터 시작한다. 유닉스는 1970년대에 만들어진 운영체제다. 갑자기 웬 유닉스?라고 할 수도 있지만, 오래된 시스템이 지금까지 쓰인다는건 그만큼 유닉스가 주는 아이디어와 교훈이 강력하다는 의미기도 하다. 오늘날 사용되는 대규모 분산 시스템에서도 유닉스 철학이 이어지는 도구들이 많다.
유닉스 철학에서 배울 점
- 동일 인터페이스 원칙: 유닉스 시스템의 모든 것은 파일이다. 파일은 파일이고, 폴더도 파일이다.
- 로직과 연결의 분리: 어떤 로직이든, 표준 입출력만 지키면 계속 연결해서 사용할 수 있다.
- 투명성과 실험: 동작이 행해지는 중간 단계를 보고 조작할 수 있다. 디버깅이 용이해지고 그러면 사용자가 여러가지 실험을 하기 편한 환경이 만들어진다.
이외에도 자동화, 빠른 프로토타이핑, 큰 프로젝트를 작은 덩어리로 나눠서 정복하기 등 CS 이론이나 개발 방법론에서 한번쯤 들어봤을법한 단어가 몇가지 등장한다.
유닉스 도구의 가장 큰 제약 사항
유닉스 도구의 가장 큰 제약사항은 컴퓨터 하나에서만 실행할 수 있다는 점이다. 유닉스 운영체제에서 쓸 수 있는 도구를 유닉스 도구라고 하기 때문에 당연한 일이다. 컴퓨터 2대가 되면 2개(혹은 그 이상)의 운영체제를 실행하는게 되는거지, 그 2대가 운영체제 1개를 나눠서 쓸 수는 없으니까! 이런 제약 사항을 극복할 수 있는 도구로 맵리듀스를 소개한다.
맵리듀스
맵리듀스는 유닉스 도구와 유사한 점이 많다. 사용 방법도 그렇고 부수 효과를 일으키지 않는다는 철학도 비슷하다. 다른점은 맵리듀스는 분산 실행이 가능하다는 점이다.
분산 컴퓨팅 환경에서 실행할 수 있어야 한다는건 곧, 여러 컴퓨터 간 데이터 전달이 가능해야 한다는 뜻이다. 따라서 유닉스에서는 stdin, stdout으로 주고 받던 입출력을 맵 리듀스에서는 파일 형태로 다루게 된다.
맵 리듀스의 큰 그림을 그려보면 2가지 키워드가 나온다. 데몬 프로세스(demon process)는 각 장비에 저장된 파일에 다른 노드가 접근할 수 있는 네트워크 서비스를 제공한다. 중앙 서버는 네임 노드(name node)라고 부르며, 어떤 데이터가 어디에 저장되어있는지 다 알고 있다. 중앙 서버에 메타데이터를 저장해놓고 각 장비에 저장된 데이터를 빼오는 형태다.
맵리듀스의 장점 중 하나는 '동일 비용의 전용 저장소보다 싸다'는 점이다. 이렇게 만들 수 있었던 이유는 하드웨어와 소프트웨어를 적절히 선택했기 때문이다. 범용 하드웨어 + 오픈소스 소프트웨어 조합으로 이런 장점을 갖출 수 있었다.
맵리듀스 연산
이름에서 예측할 수 있겠지만 맵리듀스 연산에는 실제로 우리가 아는 그 map(), reduce() 연산이 실행된다. 하둡의 맵리듀스 관련 문서에 들어가보면 이런 그림이 나온다.
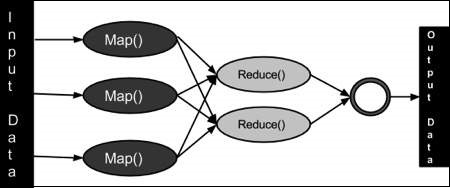
그림을 보면 map 연산의 결과를 다시 reduce 연산의 input으로 주고 있다. 즉, 앞선 작업이 완료되어야 다음 연산을 할 수 있다는게 맵리듀스의 특징이다. 그래서 이런 작업 간 수행 의존성을 관리하는 스케줄러도 많이 개발되었다고 한다.
하둡의 맵리듀스와 예시에 대해 설명하는 글에서는 이런 그림으로 맵리듀스를 설명한다. 좀 더 직관적으로 어떤 일이 일어나는지 알 수 있다.
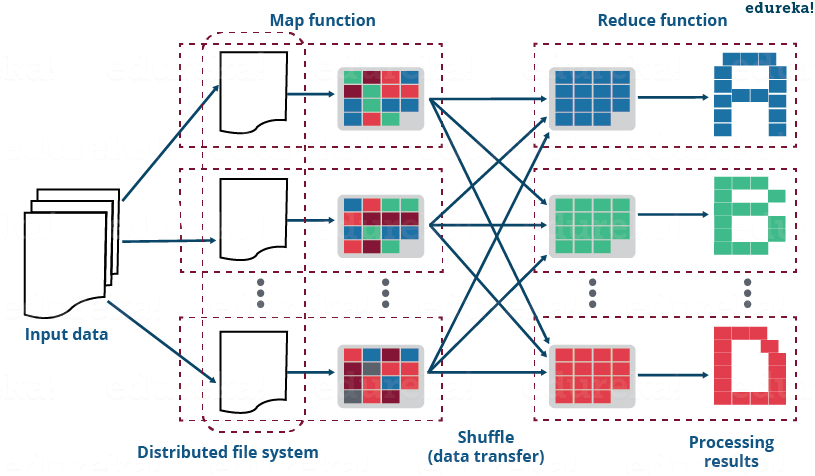
조인과 그룹화, 쏠림 현상
책에서는 일괄 처리에서의 join 작업이 단일 장비 데이터베이스에서의 join과 어떻게 다른지도 보여준다. 특정 데이터끼리의 조인이 아니라 모든 데이터끼리의 조인이 일어난다. 즉, 특정 사용자에 대한 row끼리 조인이 일어나는게 아니라 전체 사용자에 대한 조인이 한번에 같이 일어나는 것이다.
앞서 일괄처리 시스템의 주요 평가 지표로 처리량이 있다고 언급했다. 이렇게 광범위한 연산의 처리량을 높이기 위해서는 가능한 한 장비 내에서 연산을 수행하는게 유리하다. 즉, 서로 연관된 레코드는 파티션 1개에 저장하는 것이다. 예를 들어 사용자 A가 남긴 모든 로그는 같은 파티션 1개에 몰아넣는다.
책에서는 맵리듀스의 조인과 그룹화 연산이 서로 비슷하게 구현되어있다는 내용도 나온다. 그룹화의 대표적인 사용 예시로는 세션화를 해서 사용자별로 행동을 분석하는 작업이 있다.
한편 하나의 객체에 걸리는 부하가 다른 객체보다 월등히 높을 때 이를 린치핀 객체(linchpin object) 혹은 핫 키(hot key)라고 한다. 이를 완화하기 위한 방법인 쏠린 조인(skewed join), 공유 조인(shared join) 등의 방법도 나온다.
맵 사이드 조인(map-side join)
맵리듀스 축소판
맵리듀스는 1. map phase 2. reduce phase 2단계가 있었다. 맵 사이드 조인은 단계가 하나밖에 없다. 리듀서가 따로 없고 맵 연산만 나오는데, 각 매퍼의 역할은 파일 1개를 읽고 새로운 결과물 파일을 쓰는게 끝이다. 맵리듀스의 축소판이다.
맵 사이드 조인은 연산 과정과 시간이 훨씬 단축된다는 장점이 있다. 하지만 맵 사이드 조인을 언제나 적용할 수 있는건 아니다. input 데이터의 크기, 정렬, 파티셔닝 등의 제약 사항이 있고 책에서 이를 자세히 다룬다.
다양한 조인 방법
맵 사이드 조인에서도 여러가지 방법이 있다. 브로드캐스트 해시 조인, 파티션 해시 조인(혹은 버킷 맵 조인), 맵 사이드 병합 조인 등 다양한 방법이 등장한다. 맵 사이드 조인이 필요한 대표적인 경우로 검색 색인 구축, 머신러닝, 추천 시스템 구축 등이 있다.
맵리듀스라고 항상 잘 하는건 아니다
Materialization 구체화
맵리듀스 연산은 여러가지 세부 연산으로 이루어져있다. 그리고 맵리듀스를 진행하면서 중간 단계, 즉 작은 연산 하나하나를 실행한 결과물의 스냅샷을 찍어서 저장한다. 이를 구체화라고 한다. 작업 하나를 끝낸 다음에 ctrl+S를 누르는 것이다. 구체화 덕분에 생기는 장단점이 있다.
장점은 내결함성이다. 맵리듀스를 실행하다가 중간에 작업이 중단되어도 크게 걱정하지 않아도 된다. 직전 연산을 마치고나서 저장해놓은 임시 저장 파일이 있기 때문이다.
단점은 아무래도 속도와 성능이다. 작은 연산 하나하나가 모든 데이터에 대해 완벽히 끝나고나서야 그 다음 연산을 실행할 수 있기 때문이다. 이런 단점을 완화하기 위해 스파크 같은 데이터 플로 엔진이 개발되었다고 한다.
