DDL
-> 데이터 정의 언어
-> 객체(Object)를 만들고(CREATE), 수정하고(ALTER), 삭제(DROP) 하는 구문
오라클 객체의 종류
-> 테이블(Table), 뷰(View), 시퀀스(Sequence), 인덱스(index),
패키지(Package), 프로시져(Procedure), 함수(Function), 트리거(Trigger),
동의어(Synonym), 사용자(User)가 있다.
표현식
CREATE TABLE 테이블명(컬럼명 자료형(크기), 컬럼명 자료형(크기), ....);주석
COMMENT ON COLUMN 테이블명.컬럼명 IS '주석내용';제약 조건 (CONSTRAINTS)
-> 테이블 작성시(생성시) 각 컬럼에 대한 제약조건을 설정할 수 있다.
-> 데이터 무결성을 지키기 위해 제한된 조건
- 데이터 무결성 : 데이터의 정확성과 일관성을 유지하기 위한 것
NOT NULL : 데이터에 NULL을 허용하지 않는다.
UNIQUE : 중복된 값을 허용하지 않는다.
PRIMARY KEY (기본키) : NULL을 허용하지 않고, 중복 값을 허용하지 않는다.
컬럼의 고유 식별자로 사용 목적
FOREIGN KEY (외래키) : 두 테이블의 데이터간 연결을 설정하고 강제 적용하여 외래키 테이블에 저장될 수 있는 데이터를 제어
CHECK : 저장 가능한 데이터 값의 범위나 조건을 지정하여 설정한 값만 허용
제약 조건 정보 확인
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE FROM USER_CONSTRAINTS
WHERE TABLE_NAME='테이블명';
※ CONSTRAINT_TYPE
P : PRIMARY KEY
R : FOREIGN KEY
C : CHECK 또는 NOT NULL
U : UNIQUE
NOT NULL
-> 해당 컬럼에 반드시 값이 기록되어야 하는 경우, 특정 컬럼에 값을 저장하거나 수정할 때 null 값을 허용하지 않도록 컬럼 레벨에서 제한
-> 아무런 제약조건이 명시 되지 않으면 제한 없는 데이터 혹은 데이터를 넣지 않고도 INSERT가 가능
UNIQUE
-> 컬럼 입력 값에 대해 중복을 제한하는 제약조건
-> 컬럼 레벨과 테이블레벨에 설정 가능
PRIMARY KEY (기본키)
-> 테이블에서 한 행의 정보를 구별하기 위해 사용하는 고유 식별자 (Identifier)
-> NOT NULL 제약조건과 UNIQUE 제약 조건의 의미를 둘다 가지고 있으며, 한 테이블당 한개만 설정 가능
-> 컬럼 레벨, 테이블 레벨에서 지정 가능
CHECK
-> 해당 컬럼에 입력되거나 수정되는 값을 체크하여, 설정된 값 이외의 값이면 에러 발생
-> 비교 연산자를 이용하여 조건을 설정할 수 있으며, 비교값은 리터럴만 사용가능하고 값이 변하는 형태는 사용이 불가능
FOREIGN KEY (외래키)
-> 참조 무결성을 유지하기 위한 제약 조건
-> 참조된 다른 테이블이 제공하는 값만 사용할 수 있도록 제한을 거는 것
-> 참조되는 컬럼과 참조된 컬럼을 통해 테이블간의 관계가 형성된다.
-> 해당 컬럼 값은 참조되는 테이블의 컬럼 값 중의 하나와 일치하거나 NULL을 가질 수 있다.
-> 일반적으로 참조되는 테이블에서 고유 식별할 수 있는 기본키를 외래키로 사용할 수 있다.
CASCADE
-> 연쇄 삭제
-> 참조하는 값이 없을시 같이 삭제
-> 참조하고 있는 부모 테이블(USER_NOTCONS) 에서 데이터 삭제 시 해당 데이터를 참조하고 있는 테이블(BUY)의 해당 데이터가 같이 삭제된다.
DEFAULT
-> 테이블 생성시 DEFAULT 값을 줄 수 있다.
-> DEFAULT로 설정된 컬럼에 데이터를 삽입할때에는 DEFAULT로 주면 설정된 기본값으로 적용 된다.
DML (Data Manipulation Language)
-> Data를 조작하기 위해 사용하는 언어
-> Data의 삽입,수정,삭제,조회 등의 동작을 제어
-> Data를 이용하려는 사용자와 시스템 간의 인터페이스를 직접적으로 제공하는 언어
INSERT
-> 새로운 데이터(행)를 테이블에 추가하는 구문
-> 추가할때마다 테이블의 행 개수가 증가
※ 사용 구문
INSERT INTO <테이블명> VALUES (입력데이터1,입력데이터2,...);INSERT ALL
-> INSERT시 사용하는 서브쿼리가 테이블이 같은 경우, 두 개 이상의 테이블에 INSERT ALL을 이용하여 한 번에 삽입 가능
-> 단, 각 서브쿼리의 조건절이 같아야 한다는 조건이 있다.
UPDATE
-> 테이블에 기록된 컬럼의 값을 수정하는 구문
-> 테이블의 전체 행 개수에는 변화 X (기존 데이터 수정)
기본 형식
UPDATE 테이블명
SET 컬럼명 = '변경될 값'
WHERE 조건MERGE
-> 구조가 같은 두 개의 테이블을 하나의 테이블로 합치는 기능
-> 두 테이블에서 지정하는 조건의 값이 존재하면 UPDATE가 되고, 조건의 값이 없으면 INSERT 되도록 하는 기능
DELETE
-> 테이블의 행을 삭제하는 구문
-> 테이블 행 개수가 줄어든다
-> DELETE 시에 조건문을 사용하지 않게 되면 Table의 모든 데이터가 삭제 될 수 있다.
-> 외래키 제약조건이 설정되어 있는 경우 참조되고 있는 값은 삭제 할 수 없다.
형식
DELETE FROM 테이블명
WHERE 조건※ 조건 미기재 시 모든 행 제거
-> 삭제시 외래키(FOREIGN KEY) 제약 조건으로 컬럼 삭제가 불가능 한 경우
제약조건을 비활성화 할 수 있다.
TRUNCATE
-> 테이블의 전체 행을 삭제 시 사용
-> DELETE 문보다 수행 속도가 빠르지만, ROLLBACK을 통해 복구를 할 수 없다.
-> DELETE와 마찬가지로 FOREIGN KEY 제약조건일 때는 적용 불가능하기 때문에
제약조건을 비활성화 해야 삭제 할 수 있다.
형식
TRUNCATE TABLE 테이블명;ALTER
-> 테이블에 정의된 내용을 수정 할 때 사용하는 데이터 정의어
-> 컬럼의 추가, 삭제, 제약 조건의 추가/삭제, 컬럼의 자료형 변경, DEFAULT값 변경(옵션), 테이블명/컬럼명/제약조건의 이름 변경 가능
컬럼명 수정
-> 이미 만들어진 테이블의 컬럼명을 수정할 수 있다.
-- 컬럼명 수정
-- USER_ID -> ID
ex)
ALTER TABLE BOARD_TEST
RENAME COLUMN USER_ID TO ID;컬럼 삭제
-> 해당 테이블에 생성되어 있는 컬럼 삭제 가능
ex)
ALTER TABLE BOARD_TEST
DROP COLUMN USER_ID;DCL (Data Control Language)
-> 데이터 제어어
-> DB에 대한 보안, 무결성, 복구 등 DBMS를 제어하기 위한 언어
-> GRANT(권한 할당), REVOKE (권한해제), COMMIT(실행), ROLLBACK(복구)
-> COMMIT, ROLLBACK은 트랜잭션에 관련된 언어로 TCL로 구분
GRANT
-> 사용자 또는 ROLE에 대하여 권한을 부여 가능
사용법
GRANT [System_Privilege|role] TO [user|role|PUBLIC][WITH ADMIN OPTION]
- System_privilege : 부여할 시스템 권한의 이름
- role : 부여할 데이터베이스 역할의 이름
- user,role : 부여할 사용자 이름과 데이터 베이스 역할 이름
- PUBLIC : 시스템 권한 또는 데이터 베이스 역할을 모든 사용자에게 부여
- WITH ADMIN OPTION : 권한을 부여받은 사용자도 부여 받은 권한을
다른 사용자 또는 역할로 부여 가능
REVOKE
-> 사용자 또는 ROLE에 대하여 부여된 권한 회수
REVOKE 권한 FROM 계정 또는 ROLE;예제 1)
create table test
(no number (3),
name varchar2(10),
birth date default sysdate);
-- test라는 table을 생성
-- no라는 컬럼에 숫자 데이터만 들어갈 수 있고 최대 3자리까지 가능
-- name 컬럼에는 가변형 문자가 들어갈 수 있고 최대 10byte까지 입력 가능
-- birth 컬럼은 날짜 데이터만 들어갈 수 있고, 사용자가 아무런 값을 입력 안할 경우에는 default로 현재 날짜가 입력테이블을 생성하고 조회를 한번 해본다.
select * from test;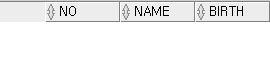
예제 2)
create table 한글테이블
(컬럼1 number,
컬럼2 varchar2(10),
컬럼3 date);
-- 테이블을 한글로 설정하는 방법이다.
-- 테이블 이름은 반드시 문자로 시작해야하며 숫자가 중도에 포함되는 것은 가능하다.
-- 테이블 이름은 한 명의 사용자가 다른 오브젝트 이름과 중복으로 사용이 불가능하다.한글명의 테이블도 생성은 가능하나, 가급적 영문으로 하는걸 권장한다.
다시 조회를 해보면 정상적으로 생성된 것을 확인할 수 있다.
select * from 한글테이블;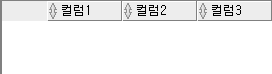
예제 3)
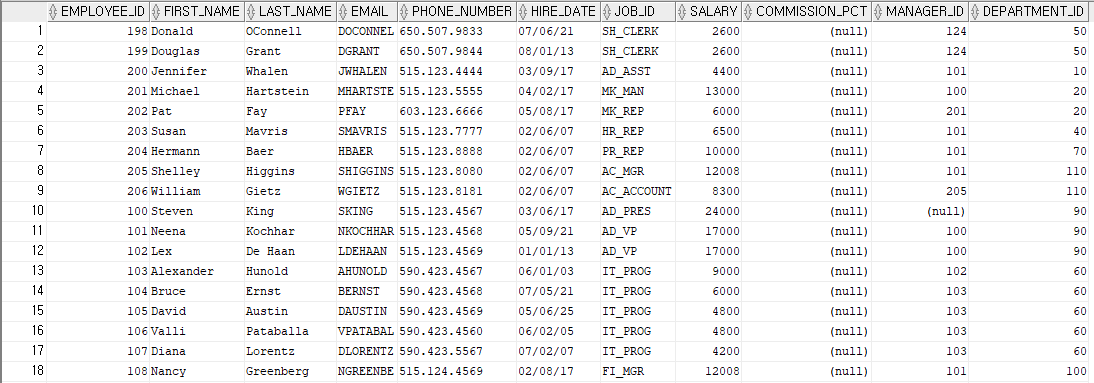
create table employees_copy
as
select * from employees;
-- employees_copy 테이블을 만들고 employees에 있던 데이터를 모두 복사결과 3)
예제 4)
만약 전부가 아닌 일부의 데이터만 복사하고 싶을 경우 아래와 같이 한다.
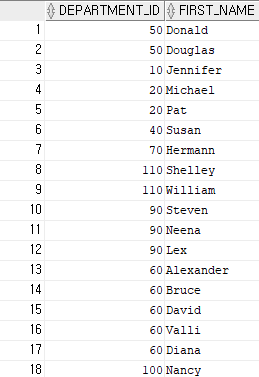
create table employees_copy2
as
select department_id, first_name
from employees;
-- employees_copy2 테이블을 만들어서 employees 테이블에 있는 department_id와 first_name 칼럼을 복사결과 4)
예제 5)
데이터를 복사해오지 않고,구조만 복사하고 싶을 경우 where 절을 활용한다.
create table employees_copy3
as
select *
from employees
where 1=2;
-- employees_copy3 테이블을 만들어서 구조만 그대로 본 따오고 데이터는 가져오지 않는 코드결과 5)
이와 같이 정상적으로 구조만 가져온 걸 확인할 수 있다.
예제 6)
테이블을 생성할 때 특정 컬럼을 추가하고, 특정 데이터만 가져오게끔 하고 싶을 경우
create table employees_copy4
as
select department_id, first_name
from employees
where department_id >100;
-- employees_copy4 테이블을 추가하되 employees에 있는 department_id와 first_name 컬럼을 추가하고 department_id의 값이 100 초과인 데이터를 가지고 employees_copy4 테이블을 만든다.결과 6)
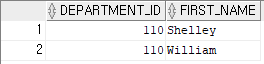
예제 7)
기존에 생성한 테이블에 열을 추가하고 싶을 경우
alter table employees_copy4
add(loc2 varchar2(10) default '서울');
-- loc2라는 열을 추가하고 크기는 10byte로 제한하며 default의 값들은 '서울'로 입력결과 7)

예제 8)
컬럼명 변경하고 싶을 경우
alter table employees_copy4 rename column loc2 to area;
-- employees_copy4 테이블에서 loc2 컬럼 명을 area로 변경결과 8)

예제 9)
테이블명을 변경하고자 할 경우
rename employees_copy4 to seoulemp;
-- employees_copy4라는 테이블을 seoulemp으로 이름 변경.
-- rename은 테이블 명을 변경할 때 사용한다.결과 9)
select *
from seoulemp;예제 10)
기존 컬럼의 크기를 변경하고자 할 경우
alter table seoulemp
modify (area varchar2(20));
-- 기존 seoulemp 테이블에 있던 area컬럼의 varchar2의 크기를 20byte로 변경예제 11)
기존 컬럼을 제거할 경우
alter table seoulemp drop column area;
-- seoulemp 테이블에 있는 area 컬럼을 삭제하는 명령어결과 11)
간헐적으로 컬럼이 삭제되지 않을 경우가 존재한다.
그럴 경우에는 cascade constraints를 활용한다.
※ cascade constraints
- 종속된 제약 조건 삭제
- 모든 데이터를 제거(Index도 제거)
- 자동 commit
예제 12)
테이블을 읽기 전용으로 할 경우
create table table_read
(no number,
name varchar2(10));
-- table_read 테이블 생성, no라는 숫자 타입과 name이라는 문자 10byte이하 테이블 생성
alter table table_read read only;
-- 읽기전용으로 테이블 변경
select *
from table_read;
insert into table_read values(1,'홍길동');결과 12)

이와 같이 읽기전용으로 바꾸게 될 경우 테이블에 데이터를 추가하는게 허용이 되지 않는다는 것을 알 수 있다..
예제 13)
다시 읽기 쓰기가 가능하게 할 경우
alter table table_read read write;위와 같이 변경한 후
insert into table_read values(1,'홍길동');위 쿼리문을 실행하면 정상적으로 데이터 삽입이 되는 것을 확인할 수 있다.
결과 13)
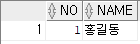
예제 14)
테이블에 있는 모든 "데이터"를 삭제할 경우
truncate table table_read;테이블 자체를 삭제하고 싶다면 drop 함수를 사용한다.
drop table table_read;※ 여기서 한가지 차이점을 설명한다.
삭제하는 명령어에는 3가지가 존재한다.
1. delete
2. truncate
3. drop3가지 명령어의 차이는 무엇일까?
delete : 열과 행을 남기고 데이터 삭제
truncate : 잔여 행을 모두 삭제
drop : 테이블 자체를 삭제
예제 15)
다시 기존의 seoulemp를 생성하고 insert 작업을 시작한다.
특정 컬럼에만 값을 넣을 경우와 모든 컬럼에 값을 넣을 경우를 본다.
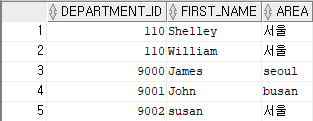
insert into seoulemp(department_id, first_name, area)
values (9000, 'James','seoul');
-- seoulemp 테이블에 department_id의 값에 9000을 입력, first_name의 값에 James를 입력, area값에 seoul을 입력
insert into seoulemp
values(9001,'John','busan');
-- 모든 컬럼에 값을 넣을 경우에는 컬럼 명 생략이 가능하다.
insert into seoulemp(department_id, first_name)
values (9002, 'susan');
-- 테이블에서 특정 컬럼에만 데이터를 입력할 경우에는 컬럼 명을 따로 써주면 된다.결과 15)
예제 16)
insert로 한 행이 아닌 여러 행을 넣을 경우
create table employees_copy5
as
select department_id, first_name, hire_date
from employees
where 1=1;
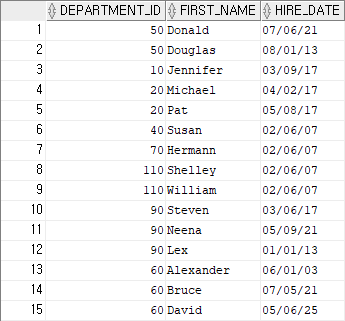
-- employees_copy5 테이블을 만들어서 department_id와 first_name, hire_date를 employees에서 데이터를 가져온다.
insert into employees_copy5
select department_id, first_name, hire_date
from employees
where department_id >=100;
-- insert로 여러 행을 한꺼번에 입력이 가능하다.
우선 employees_copy5 테이블을 생성한다.
기존의 데이터는 연/월/일 형태다.
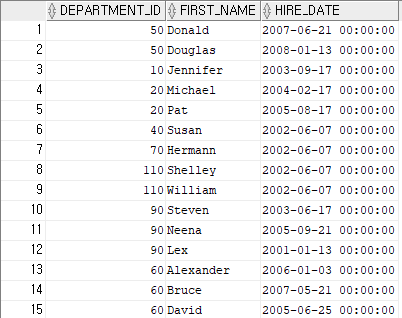
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';위와 같이 타입을 변경하게 되면 아래와 같은 결과가 나온다.
예제 17)
2개의 테이블을 하나의 테이블에 병합하고자 하는 경우
merge를 사용한다.
merge into Table1
using Table2
on 병합 조건절
when matched then
update set 업데이트 내용
delete where 조건
when not matched then
insert values(컬럼명);
-- 위와 같은 형식으로 사용하면 Table1과 Table2의 내용을 하나로 합칠 수 있다.
-- 합쳐진 내용은 Table1로 모이게 된다.
-- 기준은 3행 조건이 되고 조건이 만족할 시 Table2의 내용으로 update나 delete가 수행되고,
-- 조건이 만족하지 않으면 Table2 내용이 Table1에 신규로 insert된다.