집합 연산자 (Set Operator)
-> 두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법
-> 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식
-> 각 테이블의 조회 결과를 하나의 테이블에 합쳐서 반환
-> 조건
- SELECT 절의 "컬럼 수가 동일"
- SELECT 절의 동일 위치에 존재하는 컬럼의 "데이터 타입이 상호 호환 가능"
-> UNION, UNION ALL, INTERSECT, MINUS
1) UNION
-> UNION과 UNION ALL은 여러 개의 쿼리 결과를 하나로 합치는 연산자
-> UNION은 중복된 영역을 제외하고 하나로 합치는 연산자
A = {1,5,3,4,2};
B = {7,6,3,8,5,9,10};
A UNION B => {1,2,3,4,5,6,7,8,9,10};
중복된 데이터를 제외하고 출력됨 (첫번째 컬럼을 기준으로 오름차순으로 보여준다)2) UNION ALL
-> UNION ALL 은 UNION과 같이 여러 쿼리 결과물에 대한 합집합을 의미하며, UNION과 다르게 중복된 영역도 포함하는 연산자
A = {1,5,3,4,2};
B = {7,6,3,8,5,9,10};
A UNION ALL B => {1,2,3,3,4,5,5,6,7,8,9,10};
-> 중복된 데이터 제거 작업 없이 모두 출력
-> 정렬 없이 데이터 그대로 합해서 출력
3) INTERSECT
-> 여러 개의 SELECT 결과에서 공통된 부분만 결과로 추출
-> 즉, 수행 결과에 대한 교집합
A = {1,5,3,4,2};
B = {7,6,3,8,5,9,10};
A INTERSECT B => {3,5};
-> 공통된 요소만 보여준다 (교집합)
4) MINUS
-> 선행 SELECT 결과에서 다음 SELECT 결과와 겹치는 부분을 제외한 나머지 부분만
추출
-> 즉, 두 쿼리 결과물의 차집합
A = {1,5,3,4,2};
B = {7,6,3,8,5,9,10};
A MINUS B => {1,2,4};
-> A를 중점으로 B와 공통된 요소를 뺀 A
B MINUS A => {6,7,8,9,10};
-> B를 중점으로 A와 공통된 요소를 뺀 B
예제)
select department_id, count (*),1
from employees
where department_id >100
group by department_id
union
select manager_id, count (*),2
from employees
where department_id > 100
group by manager_id;
-- employees 테이블에 department_id가 100이상인 부서를 대상으로 department_id 별로 인원수 출력
-- manager_id 별로 인원수 출력해서 결과 합친 내용을 출력결과)
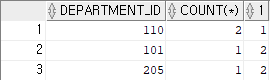
예제 2)
select department_id, manager_id, count (*)
from employees
where department_id >100
group by grouping sets (department_id, manager_id);
-- 하나의 테이블에 다양한 집계 함수를 사용해야 할 경우, union보다는 grouping sets 함수를 사용하면 편하다.결과 2)
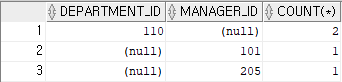
예제 3)
select department_id, listagg(first_name,'>>') within group (order by hire_date)"Listagg Result"
from employees
where department_id > 80
group by department_id;
-- within group 사이에 가로로 나열하고 싶은 규칙을 order by로 적어주면 된다.결과 3)

