단지번호붙이기
thanks to 재연님!!
(엄청난 풀이 자료 준비와 상세한 설명에 그저 리스펙..)
문제 안내
문제
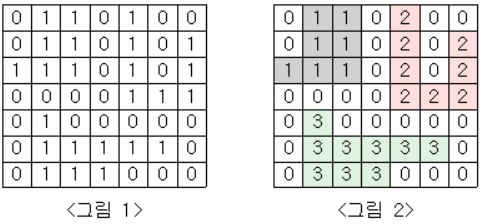
- <그림 1>과 같이 정사각형 모양의 지도가 있다.
1은 집이 있는 곳을,0은 집이 없는 곳을 나타낸다.- 철수는 이 지도를 가지고 연결된 집의 모임인 단지를 정의하고, 단지에 번호를 붙이려 한다.
- 여기서 연결되었다는 것은 어떤 집이 좌우, 혹은 아래위로 다른 집이 있는 경우를 말한다.
- 대각선상에 집이 있는 경우는 연결된 것이 아니다.
- <그림 2>는 <그림 1>을 단지별로 번호를 붙인 것이다.
- 지도를 입력하여 단지수를 출력하고, 각 단지에 속하는 집의 수를 오름차순으로 정렬하여 출력하는 프로그램을 작성하시오.
입력
- 첫 번째 줄에는 지도의 크기
N(정사각형이므로 가로와 세로의 크기는 같으며5≤N≤25)이 입력되고, 그 다음N줄에는 각각N개의 자료(0혹은1)가 입력된다.
출력
- 첫 번째 줄에는 총 단지수를 출력하시오.
- 그리고 각 단지내 집의 수를 오름차순으로 정렬하여 한 줄에 하나씩 출력하시오.
예제 입력1
7
0110100
0110101
1110101
0000111
0100000
0111110
0111000예제 출력1
3
7
8
9풀이 1 : DFS 사용
Logic 구조
-
N개 줄의 자료를 입력받아2차원 리스트로 변환 -
2차원 리스트의i번째 행j번째 열의 값을(i,j)의 좌표 값으로 인식 -
dfs라는 함수를 구현- 내 위치가 단지를 벗어나게 된다면
False를 반환 - 현재 내 위치 기준으로 상/하/좌/우를 탐색하고, 조건이 맞다면 탐색한 위치로 이동하여 동일한 작업을 계속해서 반복하는 형태로 구현
→stack개념이 포함된재귀용법을 이용 - 현재 내 위치의 값이
1이라면- 단지 내의 집의 수를
+1 - 주변으로 탐색을 갔다가 돌아오지 않기 위해 내 위치 값을
0으로 변경
- 단지 내의 집의 수를
- 그 다음
4방향을 서칭하여 값이1인 위치로 이동 후 2.의 작업을 진행 - 재귀를 이용하여 위의 두 줄의 작업을 계속해서 반복
- 단지 내의 집의 수를 카운트하는데 사용할 변수는 전역변수를 사용해야 함.
- 재귀용법 사용 시, 함수 내에 변수를 지정하게 되면 재귀로 호출되면서 해당 변수가 초기화되기 때문
- 더이상 탐색할 수 있는 단지 내의 집이 없다면 탐색을 정상적으로 종료한다는 뜻으로
True를 반환 - 만약 내 위치 값이
1이 아닌0이었다면?False를 반환
- 내 위치가 단지를 벗어나게 된다면
-
단지 내 모든 좌표에 대해
dfs함수를 실행시켜 단지 수를 계산
→ 먼저 각 단지 내 집의 수 계산하고 그 결과를 리스트에 담는 작업을 진행- 각 단지 내 집의 수를 담을 빈 리스트 생성
dfs함수 호출 시, 각 단지 내 집의 수를 집계하는데 사용할 전역 변수를0으로 설정- 이중
for문을 실행시켜 모든(i,j)의 좌표에 대한dfs(i,j)값을 계산 후,0이 아닌 경우에는 위에서 지정한 리스트에 값을 추가
-
단지 내 집의 수를 담은 리스트를 오름차순으로 정렬 후,
for문을 이용하여 순서대로 한 줄에 하나씩 출력
Code
# dfs
N = int(input()) # 첫번째 줄에는 지도의 크기가 입력됩니다.
original_map = []
for i in range(N): # 그 다음 N줄에는 각각 N개의 자료 (0혹은 1)가 입력된다.
original_map.append(list(map(int, input()))) # 2중 리스트 형태로 지도를 입력받습니다.
dx = [1, -1, 0, 0] # 우 좌 하 상, dfs함수에 사용할 예정입니다.
dy = [0, 0, 1, -1]
def dfs(i,j):
if i < 0 or i >= N or j < 0 or j >= N: # 종료조건: 지도 범위를 벗어나면 종료합니다.
return False
if original_map[i][j] == 1:
global count # 함수 밖의 변수에 영향을 미칩니다.
count += 1 # 단지의 집의 개수를 세기 위해서 count 전역변수로 설정합니다.
original_map[i][j] = 0 # 방문하고 값을 0으로 바꿔줍니다. 중복으로 세는 것, 방문하는 것을 막을 수 있습니다.
for _ in range(4): # 우 좌 하 상을 모두 돌기 위해서 for문을 사용합니다.
dfs(i + dx[_], j + dy[_]) # count가 global이기 때문에 누적해서 합을 계산할 수 있습니다.
return True# 갈 수 있는 우 좌 하 상를 재귀로 호출하고 return으로 함수를 끝냅니다. 최종적으로 같은 단지의 집을 모두 탐사하면 가장 먼저 호출한 dfs 실행이 종료됩니다.
return False # 방문한 정사각형에 집이 없으면 함수 종료합니다. (if orginal_map[i][j] == 0)
ans = [] # 각 단지 내 집의 수를 담을 리스트
count = 0 # dfs를 통해 각 단지내 집의 수를 누적시킬 때 dfs 내에서 전역변수로 사용할 변수
for i in range(N): # 0 ~ N-1, 좌표 i
for j in range(N): # 좌표 j
if dfs(i,j):
ans.append(count)
count = 0 # count 초기화
ans.sort() # 오름차순 정렬
complex_count = len(ans) # 총 단지수 계산
print(complex_count)
for i,v in enumerate(ans): # 캬..이 방법 조쿠나~!!
print(v)풀이 2 : BFS 이용
BFS개념 내에queue자료구조가 사용됨.- 해당 자료구조를 쉽게 이용하기 위해
collections모듈 내의deque함수를 가져와 사용
Logic 구조
-
N개 줄의 자료를 입력받아2차원 리스트로 변환 -
2차원 리스트의i번째 행j번째 열의 값을(i,j)의 좌표 값으로 인식 -
bfs라는 함수를 구현queue로 사용할 객체를deque함수를 사용하여 생성queue객체의 역할 : 우리가 탐색해야 하는 집의 목록을 담는 데 사용- 탐색할 집이 없어질 때까지 서칭을 해야 하기 때문에 코드 구현 시,
while문을 사용할 예정
- 초기 좌표를
queue에 추가 - 단지 내 집의 수를 카운트할 때 사용할 변수를
0으로 설정- 재귀용법을 사용하는
dfs와는 다르게, 함수 내 반복문을 통해 단지 내 집의 수를 집계하게 되기 때문에 전역변수가 아닌 함수 내 지역변수로 지정하는 것이 가능
- 재귀용법을 사용하는
- 탐색할 집의 목록이 없어질 때까지, 다시 말해 'queue' 객체에 아무 것도 남지 않을 때까지 아래의 과정을 계속해서 반복
- 'queue' 객체에서 제일 먼저 들어갔던 좌표를 꺼내서 현재 탐색해야 하는 집의 좌표로 지정
- 현재 위치가 단지를 벗어나게 된다면
False를 반환 - 현재 위치의 좌표의 값이 1인지 판단
- 맞다면? 단지 내의 집의 수를
+1 - 다음 위치로 넘어가서 함수를 실행하게 될 경우를 생각하면, 현재 위치를 다시 카운트하면 안되기 때문에 현재 위치 값을
0으로 변경 - 이제, 현재 위치를 기준으로 상하좌우
4방향의 좌표를 체크
ㆍ해당 좌표들이 단지를 벗어나게 되면 아무 작업도 하지 않고 그냥 지나침
ㆍ해당 좌표들이 단지 내에 있다면, 다음에 탐색해야 할 집으로 간주하여queue에 추가
- 맞다면? 단지 내의 집의 수를
-
단지 내 모든 좌표에 대해
bfs함수를 실행시켜 단지 수를 계산
→ 먼저 각 단지 내 집의 수 계산하고 그 결과를 리스트에 담는 작업을 진행- 각 단지 내 집의 수를 담을 빈 리스트 생성
- 이중
for문을 실행시켜 모든(i,j)의 좌표에 대한dfs(i,j)값을 계산 후,0이 아닌 경우에는 위에서 지정한 리스트에 값을 추가
-
단지 내 집의 수를 담은 리스트를 오름차순으로 정렬 후,
for문을 이용하여 순서대로 한 줄에 하나씩 출력
Code
# bfs
from collections import deque
# deque(양쪽 큐) 호출
N = int(input()) # 첫번째 줄에는 지도의 크기가 입력됩니다.
original_map = []
for i in range(N): # 그 다음 N줄에는 각각 N개의 자료 (0혹은 1)가 입력된다.
original_map.append(list(map(int, input()))) # 2중 리스트 형태로 지도를 입력받습니다.
def bfs(i, j): # 초기 좌표
queue_ = deque() # deque 객체를 생성합니다.
queue_.append((i, j)) # 좌표를 deque에 넣어줍니다.
count = 0 # 개수 세기용 변수를 초기화합니다.
while queue_: # deque가 빌 때 까지 loop를 돕니다.
current_i, current_j = queue_.popleft() # queue의 가장 우선순위, 맨 왼쪽을 대기열에서 뽑습니다.
if original_map[current_i][current_j] == 1: # 1인 경우 즉 집이 있는경우 graph traversal을 시작합니다.
original_map[current_i][current_j] = 0 # 방문을 하고 다시 방문하지 않기 위해서 0으로 바꿔줍니다.
count += 1 # 집 개수를 더해줍니다.
for _ in range(4):
ni, nj = current_i + dx[_], current_j + dy[_]
if ni < 0 or ni >= N or nj < 0 or nj >= N: # 좌표가 지도 범위 밖을 벗어나면 다시 반복문의 처음으로 돌아갑니다. 즉 이 좌표는 큐에 넣지 않습니다.
continue
queue_.append((ni, nj)) # 좌표가 지도 범위 밖이 아니라면 큐 대기열에 넣습니다.
return count
ans = []
for i in range(N): # 0 ~ N-1, 좌표 i
for j in range(N): # 좌표 j
temp = bfs(i, j) # i, j 좌표(인덱스)값은 변하지 않지만 실제 지도에서 i,j 좌표에 해당하는 값은 바뀝니다. 따라서 temp라는 변수를 정의하여 기존의 값을 가리키게 합니다.
if temp > 0:
ans.append(temp)
# if bfs(i, j) > 0: # 여기서 bfs가 호출되면서 기존 지도의 값이 바뀌어버림
# temp = bfs(i, j) # 바뀌고 난 후 값이 temp에 할당됩니다.
# ans.append(temp)
ans.sort()
complex_count = len(ans) # 총 단지수 계산
print(complex_count)
for i,v in enumerate(ans):
print(v)유의 사항
풀이 1과풀이 2에는 차이가 있다.
-
풀이 1의 경우- (
DFS특성) 단지가 형성된 곳이 아니라면 탐색 자체를 하지 않음. - 함수의 반환 값이 각 단지의 수가 아니라 단지가 형성되었는지 아닌지를 의미한다는 것.
dfs함수 호출 후 값이 변경된 전역변수count를 리스트에 추가 후 다시0으로 초기화.
- (
-
풀이 2의 경우- (
BFS특성) 해당 위치에 단지가 형성되었는지 유무는 고려하지 않고 모든 집을 다 거치면서 탐색을 진행. bfs함수 호출 결과 자체가 단지 내 집의 수가 되기 때문에, bfs 함수 호출 결과를 반드시 하나의 변수의 값으로 지정하여 저장해놓아야 함.- 단지 내 집의 수가 0보다 큰지 조건문을 통해 확인 후, 리스트에 담아야 하기 때문임.
- (
