💰 고득점 Kit : 스택/큐
🌞 같은 숫자는 싫어
🚊 문제 설명
- 배열
arr가 주어집니다. 배열arr의 각 원소는 숫자0부터9까지로 이루어져 있습니다.- 이때, 배열
arr에서 연속적으로 나타나는 숫자는 하나만 남기고 전부 제거하려고 합니다.- 단, 제거된 후 남은 수들을 반환할 때는 배열
arr의 원소들의 순서를 유지해야 합니다. 예를 들면,
arr=[1, 1, 3, 3, 0, 1, 1]이면[1, 3, 0, 1]을return합니다.arr=[4, 4, 4, 3, 3]이면[4, 3]을return합니다.
📢 배열 arr에서 연속적으로 나타나는 숫자는 제거하고 남은 수들을 return 하는 solution 함수를 완성해 주세요.
🚊 제한사항
- 배열
arr의 크기 :1,000,000이하의 자연수- 배열
arr의 원소의 크기 :0보다 크거나 같고9보다 작거나 같은 정수
🚊 입출력 예
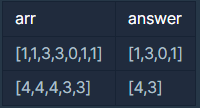
입출력 예 #1, 2
- 문제의 예시와 같습니다.
📑 Code : 내꺼
📌 Logic 설명
- 중복을 제거한 요소를 담을 새로운 리스트
answer를 빈 리스트로 지정하고, 문제에서 주어진array의 0 번째 요소를 담음- 주어진
array의 1 번째 요소부터 마지막 요소까지 반복문을 돌면서answer의 마지막 요소와 현재array의 요소를 비교하여 동일하지 않은 경우에만array의 요소를answer에 담음- 반복문 종료 후
answer를return
> code
def solution(arr):
answer = [arr[0]]
length = len(arr)
for i in range(1,length):
if answer[-1] != arr[i]:
answer.append(arr[i])
return answer📑 Code : 다른 사람꺼
정용님 코드
- 변수 지정도 깔끔하고, 초기 비교 대상을 -1로 지정함으로써 첫 번째 요소에 대해 예외적으로 코드를 작성해야 했던 내 코드보다
클-린한듯하여 좋았음.
> code
def solution(arr):
# 중복을 제거한 요소를 담을 빈 리스트 생성
answer = []
# 기존 array의 요소와 비교할 대상을 front라는 변수로 지정 후 -1을 할당
# 왜 -1인가?에 대해 반드시 기억해야 함!! 자주 쓰이는 기법
# 문제의 '제한사항'에서 「 0 ≤ 배열 arr의 원소의 크기 ≤ 9 」라는 조건을 주었기 때문
# array의 어떤 요소와도 겹치지 않는 값이기 때문에 비교 대상으로 적절함
front = -1
# 반복문을 돌면서
for item in arr:
# 만약 array 내의 요소(item)가 비교 대상(front)와 다른 경우에만
if front != item:
# answer에 해당 요소를 추가
answer.append(item)
# 비교 대상을 answer의 마지막 요소인 item으로 갱신
front = item
return answer프로그래머스 코드
- 반복문을 돌면서 현재 요소와 그 뒷 요소를 비교하며 값이 다른 경우에만 새로운 리스트에 담는 방식으로 작성한 코드
> code
def solution(arr):
return [arr[i] for i in range(len(arr)) if [arr[i]] != arr[i+1:i+2]]💡 새롭게 알게된 점
📌 마지막 요소를 확인할 때, 리스트의 indexing이 아닌, slicing으로 코드를 작성함으로써 에러 발생을 방지하였다는 점에 대해 감탄했음.
- 리스트는 존재하지 않는 범위에 대해
slicing하는 경우, 빈 리스트[]를 반환- 반면에, 존재하지 않는 범위의
index에 대해indexing하는 경우,IndexError발생
> code
array = [1,2,3,4,5]
print(array[6]) # IndexError: list index out of range
print(array[6:]) # []🌞 올바른 괄호
🚊 문제 설명
- 괄호가 바르게 짝지어졌다는 것은 '(' 문자로 열렸으면 반드시 짝지어서 ')' 문자로 닫혀야 한다는 뜻입니다.
- 예를 들어
()()또는(())()는 올바른 괄호입니다.
)()(또는(()(는 올바르지 않은 괄호입니다.
📢 ( 또는 ) 로만 이루어진 문자열 s가 주어졌을 때, 문자열 s가 올바른 괄호이면 True를 return 하고, 올바르지 않은 괄호이면 False를 return 하는 solution 함수를 완성해 주세요.
🚊 제한사항
- 문자열
s의 길이 :100,000이하의 자연수- 문자열
s는(또는)로만 이루어져 있습니다.
🚊 입출력 예

입출력 예 #1, 2, 3, 4
- 문제의 예시와 같습니다.
📑 Code : 내꺼
Code 1
📌 Logic 설명
stack으로 활용할 빈 리스트 생성- 주어진 배열
s의 요소에 대해 반복문을 돌면서- 열린 괄호'
('인 경우에는stack에 담고- 그렇지 않는 경우(닫힌 괄호'
)')에는stack의 상황을 보고 판단
4-1.stack이 비어 있는 경우에는 짝을 맞출 열린 괄호'('가 없는 것이기 때문에False를 반환하고 종료
4-2.stack이 비어 있지 않은 경우에는stack의 마지막 요소가 열린 괄호'('일 때 stack의 마지막 요소를 추출
- 왜냐하면,
stack의 마지막 요소인 열린 괄호'('와 주어진 배열에서 현재 요소인 닫힌 괄호')'가 짝을 맞춰 사라지기 때문
> code 1
def solution(s):
stack = []
for i in s:
if i == "(":
stack .append(i)
else:
if not stack:
return False
elif stack[-1] == "(":
stack.pop()
# stack이 비어 있지 않은지의 유무를 참/거짓으로 return
# stack이 비었다면 True, 비어있지 않다면 False를 반환
return not stack Code 2
📌 Logic 설명
- 열린 괄호 '
('에는+1, 닫힌 괄호 ')'에는-1에 해당하는 점수를 부여- 열린 괄호와 닫힌 괄호가 순서대로 짝을 맞추면 점수는
+1되었다가-1되어서 결과적으로0점으로 종료- 만약 점수가
음수로 가게 된다면, 열린 괄호 없이 닫힌 괄호가 나왔다는 말이기 때문에 무조건 짝을 맞추지 못하였다는 것을 의미하므로False를 반환해야 함.
> code 1
def solution(s):
score = 0
for w in s:
if score < 0:
return 0
else:
if w == "(":
score += 1
elif w == ")":
score -= 1
# score이 0점과 동일한지 유무를 참/거짓으로 반환
# score가 0점이면 참이므로 True를 반환
return score == 0📑 Code : 다른 사람꺼
- s 내의 요소가 닫힌 괄호'
)'인 경우,stack으로 사용하는 리스트st의 마지막에 어떤 요소가 있는 지와 무관하게pop메서드를 실행
💡 단,pop메서드를 실행하였는데 에러가 발생했다면,st가 빈 리스트라는 뜻이기 때문에 닫힌 괄호와 짝을 맞출 요소가 남아있지 않다는 뜻이 되어False를 반환
> code
def is_pair(s):
st = list()
for c in s:
if c == '(':
st.append(c)
if c == ')':
try:
st.pop()
except IndexError:
return False
return len(st) == 프로그래머스 코드
- 반복문을 돌면서 현재 요소와 그 뒷 요소를 비교하며 값이 다른 경우에만 새로운 리스트에 담는 방식으로 작성한 코드
> code
def solution(arr):
return [arr[i] for i in range(len(arr)) if [arr[i]] != arr[i+1:i+2]]🌞 기능개발
🚊 문제 설명
- 프로그래머스 팀에서는 기능 개선 작업을 수행 중입니다.
- 각 기능은 진도가
100%일 때 서비스에 반영할 수 있습니다.- 또, 각 기능의 개발속도는 모두 다르기 때문에 뒤에 있는 기능이 앞에 있는 기능보다 먼저 개발될 수 있고, 이때 뒤에 있는 기능은 앞에 있는 기능이 배포될 때 함께 배포됩니다.
📢 먼저 배포되어야 하는 순서대로 작업의 진도가 적힌 정수 배열 progresses와 각 작업의 개발 속도가 적힌 정수 배열 speeds가 주어질 때 각 배포마다 몇 개의 기능이 배포되는지를 return 하도록 solution 함수를 완성하세요.
🚊 제한사항
- 작업의 개수(
progresses,speeds배열의 길이)는100개 이하입니다.- 작업 진도는
100미만의 자연수입니다.- 작업 속도는
100이하의 자연수입니다.- 배포는 하루에 한 번만 할 수 있으며, 하루의 끝에 이루어진다고 가정합니다.
- 예를 들어 진도율이
95%인 작업의 개발 속도가 하루에4%라면 배포는2일 뒤에 이루어집니다.
🚊 입출력 예

입출력 예 #1
- 첫 번째 기능은
93%완료되어 있고 하루에1%씩 작업이 가능하므로7일간 작업 후 배포가 가능합니다.- 두 번째 기능은
30%가 완료되어 있고 하루에30%씩 작업이 가능하므로3일간 작업 후 배포가 가능합니다.- 하지만 이전 첫 번째 기능이 아직 완성된 상태가 아니기 때문에 첫 번째 기능이 배포되는
7일째 배포됩니다.- 세 번째 기능은
55%가 완료되어 있고 하루에5%씩 작업이 가능하므로9일간 작업 후 배포가 가능합니다.
- 따라서
7일째에2개의 기능,9일째에1개의 기능이 배포됩니다.
입출력 예 #2
- 모든 기능이 하루에
1%씩 작업이 가능하므로, 작업이 끝나기까지 남은 일수는 각각5일,10일,1일,1일,20일,1일입니다.- 어떤 기능이 먼저 완성되었더라도 앞에 있는 모든 기능이 완성되지 않으면 배포가 불가능합니다.
- 따라서
5일째에1개의 기능,10일째에3개의 기능,20일째에2개의 기능이 배포됩니다.
📑 Code : 내꺼
📌 Logic 설명
코드에 직접 적음
> code
# 올림 함수 계산을 위해 math 모듈 사용
from math import ceil
def solution(progresses, speeds):
# 작업 별 필요한 요일을 계산하여 그 수치를 담을 빈 리스트 생성
day_required = []
# 작업의 진척율, 개발 속도를 zip 함수로 묶어서 각각의 요소들에 대해 반복문을 실행
for p, s in zip(progresses, speeds):
# 잔여 작업 일수 : 남은 진척율을 개발 속도로 나누어 올림 계산한 결과
# 그 결과를 day_required 리스트에 추가
day_required.append(ceil((100-p)/s))
# 마지막 요소까지 계산을 해야 하기 때문에, 해당 리스트의 최대값보다 하나 더 큰 값을 다시 day_required 리스트에 추가
day_required.append(max(day_required)+1)
# 아래 반복문을 통해 한꺼번에 배포가 되어야 하는 작업들을 담을 빈 리스트 temp 생성
temp = []
# 정답을 담을 빈 리스트 answer 생성
answer = []
# 위에서 day_required 리스트의 마지막 요소에 내가 지정한 값을 추가해두었기 때문에
# 반복문을 실행할 범위를 day_required의 전체 요소의 개수에서 1만큼을 제외시킴.
for i in range(len(day_required)-1):
# day_required 리스트에서 0번째부터 i번째 요소까지의 최대값이 (i+1)요소보다 작을 때에만
if max(day_required[:i+1]) < day_required[i+1]:
# temp 리스트에 day_required의 현재 요소를 추가
temp.append(day_required[i])
# answer 리스트에는 temp 리스트의 개수(이번 배포 시 배포될 기능의 총 개수)를 추가
answer.append(len(temp))
# 다음 순서를 실행하기 위해, temp 리스트 초기화
temp.clear()
# day_required 리스트에서 0번째부터 i번째 요소까지의 최대값이 (i+1)요소보다 크거나 같다면
else:
# temp 리스트에 day_required의 현재 요소를 추가
temp.append(day_required[i])
return answer📑 Code : 다른 사람꺼
상봉님 코드
defaultdict함수 사용이 아주 탁월했음.key : value형태의 요소를 담은dictionary자료형을 생성 시, 기존key값이 없는 요소에 대해 자료형에 추가하는 경우 사용하면 좋음.- 일반적인
dict자료형은 기존에 보유하고 있지 않은key값에 대해key:value를 넣어주려고 하면error가 발생.
> code
from collections import defaultdict
def solution(progresses, speeds):
# 역순으로 바꿔서 가장앞의 작업이 스택상 맨 위로 오도록 설정
progresses = progresses[::-1]
speeds = speeds[::-1]
# [(55, 5), (30, 30), (93, 1)] 식으로 현재진행량과 작업속도를 묶어줌
suc = list(zip(progresses,speeds))
print(suc)
# 키값이 없을때 해당 키값으로 value를 추가하면 오류가 발생하지않는 defaultdict() 함수 이용
dic = defaultdict(int)
print(dic)
# 몇일이 경과했는지 저장할 day 선언
day = 1
# 모든 작업이 스택을 빠져나갈때까지 반복(작업완료)
while len(suc) != 0:
# 날짜 x 속도가 100프로를 넘는다면 맨위의 작업을 완료처리
if suc[-1][0] + suc[-1][1]*day >= 100:
print(suc[-1][0] + suc[-1][1]*day)
print(day)
suc.pop()
print(suc)
dic[day] += 1
# 작업이 완료되지 않았다면 그냥 day만 1증가
else:
day += 1
print(dic)
return list(dic.values())프로그래머스 코드
- 반복문을 돌면서 현재 요소와 그 뒷 요소를 비교하며 값이 다른 경우에만 새로운 리스트에 담는 방식으로 작성한 코드
> code
def solution(progresses, speeds):
# [현재 작업, 누적 배포 예정 기능 수] 를 리스트 형태의 요소로 담을 빈 리스트 Q를 생성
# Q는 결과적으로 2차원 리스트 형태가 됨.
Q=[]
# 작업의 진척율, 개발 속도를 zip 함수로 묶어서 각각의 요소들에 대해 반복문을 실행
for p, s in zip(progresses, speeds):
# Q가 비었거나, 가장 마지막 배포 예정 작업의 소요 일수가 이번 순서 작업의 소요 일수보다 작다면
if len(Q)==0 or Q[-1][0] < -((p-100)//s):
# Q에 이번 순서의 작업의 소요 일수를 누적 배포 예정 기능 수는 1개(본인꺼)로 지정하여 담음.
Q.append([-((p-100)//s),1])
# Q에 어떤 요소가 있고, 가장 마지막 배포 예정 작업의 소요 일수가 이번 순서 작업의 소요 일수보다 크거나 같다면
else:
# 가장 마지막 배포 예정의 작업 배포 시, 해당 기능을 함께 배포해야 하므로
# 누적 배포 예정 기능 수에 +1 해줌.
Q[-1][1]+=1
# 배포 예정 작업은 Q의 각 요소 내의 1번째 요소에 해당하므로 아래와 같이 list Comprehension을 이용하여 리스트에 담아 반환
return [q[1] for q in Q]💡 새롭게 알게된 점
📌 올림 계산을 위해 math 모듈의 ceil 함수를 사용하지 않고, -((p-100)//s) 의 형태로 계산한 점.
- 파이썬에서
//연산자의 의미 : 나누기 연산 후 소수점 버림p-100은 음수가 됨.(p-100)//s는 음수에서 내림을 한 결과이며, 이는(100-p)/s를 올림한 결과와 절대값이 동일함.-(p-100)//s는 작업의 진척율을 개발 속도로 나눈 후 올림한 결과와 동일
🌞 프린터
🚊 문제 설명
- 일반적인 프린터는 인쇄 요청이 들어온 순서대로 인쇄합니다.
- 그렇기 때문에 중요한 문서가 나중에 인쇄될 수 있습니다.
- 이런 문제를 보완하기 위해 중요도가 높은 문서를 먼저 인쇄하는 프린터를 개발했습니다.
- 이 새롭게 개발한 프린터는 아래와 같은 방식으로 인쇄 작업을 수행합니다.
1. 인쇄 대기목록의 가장 앞에 있는 문서(J)를 대기목록에서 꺼냅니다.
2. 나머지 인쇄 대기목록에서 J보다 중요도가 높은 문서가 한 개라도 존재하면 J를 대기목록의 가장 마지막에 넣습니다.
3. 그렇지 않으면 J를 인쇄합니다.
- 예를 들어,
4개의 문서(A, B, C, D)가 순서대로 인쇄 대기목록에 있고 중요도가2 1 3 2라면C D A B순으로 인쇄하게 됩니다.- 내가 인쇄를 요청한 문서가
몇 번째로 인쇄되는지 알고 싶습니다. 위의 예에서C는1번째로,A는3번째로 인쇄됩니다.
📢 현재 대기목록에 있는 문서의 중요도가 순서대로 담긴 배열 priorities와 내가 인쇄를 요청한 문서가 현재 대기목록의 어떤 위치에 있는지를 알려주는 location이 매개변수로 주어질 때, 내가 인쇄를 요청한 문서가 몇 번째로 인쇄되는지 return 하도록 solution 함수를 작성해주세요.
🚊 제한사항
- 현재 대기목록에는
1개 이상100개 이하의 문서가 있습니다.- 인쇄 작업의 중요도는
1~9로 표현하며 숫자가 클수록 중요하다는 뜻입니다.location은0이상 (현재 대기목록에 있는 작업 수 - 1) 이하의 값을 가지며 대기목록의 가장 앞에 있으면0, 두 번째에 있으면1로 표현합니다.
🚊 입출력 예
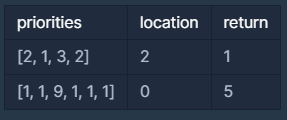
입출력 예 #2
- 문제의 예시와 같습니다.
입출력 예 #1
6개의 문서(A, B, C, D, E, F)가 인쇄 대기목록에 있고 중요도가1 1 9 1 1 1이므로C D E F A B순으로 인쇄합니다.
📑 Code : 내꺼
사실 프로그래머스 다른 사람 풀이 보고 공부한 후, 숙지된 내용을 정리하였음.
📌 Logic 설명
- 중복을 제거한 요소를 담을 새로운 리스트
answer를 빈 리스트로 지정하고, 문제에서 주어진array의 0 번째 요소를 담음- 주어진
array의 1 번째 요소부터 마지막 요소까지 반복문을 돌면서answer의 마지막 요소와 현재array의 요소를 비교하여 동일하지 않은 경우에만array의 요소를answer에 담음- 반복문 종료 후
answer를return
> code
from collections import deque
def solution(priorities, location):
# 기존 배열에서 순서와 요소값을 tuple 형태의 요소로 갖는 새로운 리스트를 생성
# deque 함수를 이용하여 리스트를 덱으로 변환
# 명칭을 queue라고 지은 이유는, 선입선출의 방식으로 사용할 예정이기 때문
# 아래 while문을 보면, 제일 앞에 있는 요소를 뽑은 후 조건 충족 시 다시 맨 뒤로 넣음.
queue = deque([(idx, priority) for idx, priority in enumerate(priorities)])
# 문제의 규칙대로 주어진 자료형을 정렬 후,
# 인쇄를 요청한 문서의 인쇄 순서를 확인할 변수를 answer로 지정하여 0을 할당.
answer = 0
# 조건을 만족할 때까지 반복
while True:
# queue의 제일 처음 요소를 뽑아서 target_data로 지정
# popleft 함수를 사용했기 때문에, queue에서 해당 요소는 제거된 상태
target_data = queue.popleft()
# target_data의 중요도가 queue 내의 중요도보다 하나라도 작다면
if any(target_data[1] < current_data[1] for current_data in queue):
# 현재 데이터를 다시 queue 에 추가
queue.append(target_data)
# target_data의 중요도가 나머지 모든 data의 중요도보다 높다면
else:
# 인쇄 순서를 하나 늘려줌.
answer += 1
# 「priorities에서 target_data의 중요도의 idx」가 「priorities에서 우리가 찾는 중요도의 idx」와 같다면
if target_data[0] == location :
# 인쇄 순서를 출력
return answer🔎 내가 못 푼 이유
1번째
> code
priorities = [2,3,3,2,9,3,3]
location = 3위의 코드의 세부 작업 순서를 정리한 것이 다음과 같음.
priorities의 변화 및 인쇄 작업을 서술
(우리가 찾는 "location = 3"에 해당하는 2는 "2"로 표시)
2,3,3,"2",9,3,3
3,3,"2",9,3,3,2
3,"2",9,3,3,2,3
"2",9,3,3,2,3,3
9,3,3,2,3,3,"2"
9 인쇄 - 1번째 인쇄
3 인쇄 - 2번째 인쇄
3 인쇄 - 3번째 인쇄
2,3,3,"2"
3,3,"2",2
3 인쇄 - 4번째 인쇄
3 인쇄 - 5번째 인쇄
"2" 인쇄 - 6번째 인쇄
2 인쇄 - 7번째 인쇄
따라서, return 값은 6이 됨.그런데 나는 일단, 최대값이 맨 앞으로 오면 거기서 더이상의 정렬이 없을 것이라 생각하였음.
나의 잘못된 생각
priorities의 변화 및 인쇄 작업을 서술
(우리가 찾는 "location = 3"에 해당하는 2는 "2"로 표시)
2,3,3,"2",9,3,3
3,3,"2",9,3,3,2
3,"2",9,3,3,2,3
"2",9,3,3,2,3,3
9,3,3,2,3,3,"2"
9 인쇄 - 1번째 인쇄
3 인쇄 - 2번째 인쇄
3 인쇄 - 3번째 인쇄
3 인쇄 - 4번째 인쇄
3 인쇄 - 5번째 인쇄
2 인쇄 - 6번째 인쇄
"2" 인쇄 - 7번째 인쇄
따라서, return 값은 7이 됨.
Logic흐름 정리
1. 최대값이 맨 앞에 올때까지rotate를 반복한 다음 그 값을 인쇄한 후에
2. 나머지 값들에 대해 또다시 최대값이 맨 앞에 올때까지rotate를 반복 후 그 값을 인쇄.
3. 모든 요청이 인쇄된 후에 작업은 종료됨.
2번째
문제 조건 중, 아래 내용을 max 함수로 써서 작성하는 경우, 시간 초과의 문제와 ValueError가 발생.
- 나머지 인쇄 대기목록에서 J보다 중요도가 높은 문서가 한 개라도 존재하면 J를 대기 목록의 가장 마지막에 넣습니다.
> 코드 구현
(... 중간 생략 ...)
while priorities:
target = priorities.popleft()
# 틀린 코드
if target[1] < max(priority[1] for priority in priorities):
# 바른 코드
if any(target[1] < priority[1] for priority in priorities):
(... 중간 생략 ...)
max함수로 최대값을 구하는 경우에는priorities의 모든 요소를 다 서칭해야 하기 때문에 시간이 오래 걸림.popleft를 통해priorities가 빈 리스트가 되게 되면,ValueError발생
❗❗❗ any 함수에 대해 아래에 정리해두었으니 잊지 말고 다음에는 꼭 써먹자...
💡 새롭게 알게된 점
📌 all 함수와 any 함수
all
- 인자로 반복 가능한 (iterable) 자료형을 받음.
- 인자로 받은 데이터의 모든 요소가 True인 경우, True를 반환
- 인자로 받은 요소 중 하나라도 False이면 False를 반환
- 인자로 받은 요소가 비어있으면 True
def all(iterable):
for element in iterable:
if not element:
return False
return Trueany
- 인자로 반복 가능한 (iterable) 자료형을 받음.
- 인자로 받은 데이터의 요소 중 하나라도 True인 경우, True를 반환
- 인자로 받은 요소 중 모두 False이면 False를 반환
- 인자로 받은 요소가 비어있으면 False
def any(iterable):
for element in iterable:
if element:
return True
return False📑 Code : 다른 사람꺼
강사님 코드
queue자료형을 활용하지 않고,while문과for문을 활용한 풀이
> code
def solution(priorities, location):
# answer는 인쇄 순서를 의미
answer = 1
# 대기 목록에 원래 순서를 포함시켜서 살펴보기 위해 enumerate 함수 사용
queue = [[i,v] for i,v in enumerate(priorities)]
# print(queue)
while True:
# 대기 목록에서 제일 앞에 있는 문서를 뽑음
check = queue.pop(0)
# 뽑은 문서가 중요도가 가장 높은지 확인
# -> 나머지 인쇄 대기 목록에서 중요도가 높은 문서가 한 개라도 있는지 여부를 확인
if check[1] == max(priorities):
# 그 문서가 우리가 찾는 문서인지?
if check[0] == location:
맞으면 인쇄 순서를 반환
return answer
# 그 문서가 우리가 찾는 문서가 아니라면
else:
# 현재 중요도가 가장 높은 문서가 인쇄되고 없어지므로 대기 목록에서 제거
priorities.remove(max(priorities))
# 인쇄 순서가 하나 뒤로 밀리기 때문에 (+1)처리
answer += 1
# 뽑은 문서가 중요도가 가장 높지 않다면
else:
# 다시 대기 목록에 넣어줌.
queue.append(check)
return answer📑 Code : 다른 사람꺼
정용님 코드
queue자료형을 활용하지 않고,while문과for문을 활용한 풀이
> code
def solution(priorities, location):
answer = 0
while True:
# 최대값
max_num = max(priorities)
print(f"max_num : {max_num}")
for i in range(len(priorities)):
# 최대값이 일치하면
if max_num == priorities[i]:
# 해당 답에 대한 순위 +1
answer += 1
# 최대값을 찾는 순위에서 제외
priorities[i] = 0
print(f"priorities : {priorities}")
# 최대값을 다시 구함
max_num = max(priorities)
print(f"max_num : {max_num}")
print(f"answer : {answer}")
# i의 위치와 일치하면 answer 반환
if i == location:
return answer🔎 예시를 통한 확인
예시를 통한 출력 내용 확인
priorities = [2,3,3,2,9,3,3] location = 3 solution(priorities, location) --- 출력 결과 --- (while문 시작) max_num : 9 (for문 시작) priorities : [2, 3, 3, 2, 0, 3, 3] max_num : 3 answer : 1 priorities : [2, 3, 3, 2, 0, 0, 3] max_num : 3 answer : 2 priorities : [2, 3, 3, 2, 0, 0, 0] max_num : 3 answer : 3 (while문 다시 시작) max_num : 3 (for문 시작) priorities : [2, 0, 3, 2, 0, 0, 0] max_num : 3 answer : 4 priorities : [2, 0, 0, 2, 0, 0, 0] max_num : 2 answer : 5 priorities : [2, 0, 0, 0, 0, 0, 0] max_num : 2 answer : 6 --- return 값 --- 6
프로그래머스 코드
> code
🌞 다리를 지나는 트럭
🚊 문제 설명
- 트럭 여러 대가 강을 가로지르는 일차선 다리를 정해진 순으로 건너려 합니다.
- 모든 트럭이 다리를 건너려면 최소 몇 초가 걸리는지 알아내야 합니다.
- 다리에는 트럭이 최대
bridge_length대 올라갈 수 있으며, 다리는weight이하까지의 무게를 견딜 수 있습니다.- 단, 다리에 완전히 오르지 않은 트럭의 무게는 무시합니다.
- 예를 들어, 트럭
2대가 올라갈 수 있고 무게를10kg까지 견디는 다리가 있습니다. 무게가[7, 4, 5, 6]kg인 트럭이 순서대로 최단 시간 안에 다리를 건너려면 다음과 같이 건너야 합니다.

- 따라서, 모든 트럭이 다리를 지나려면 최소 8초가 걸립니다.
📢 solution 함수의 매개변수로 다리에 올라갈 수 있는 트럭 수 bridge_length, 다리가 견딜 수 있는 무게 weight, 트럭 별 무게 truck_weights가 주어집니다. 이때 모든 트럭이 다리를 건너려면 최소 몇 초가 걸리는지 return 하도록 solution 함수를 완성하세요.
🚊 제한사항
bridge_length는1이상10,000이하입니다.weight는1이상10,000이하입니다.truck_weights의 길이는1이상10,000이하입니다.- 모든 트럭의 무게는
1이상weight이하입니다.
🚊 입출력 예
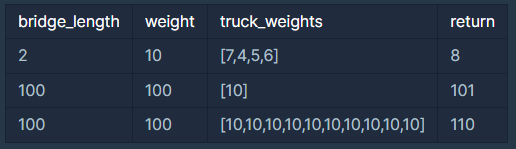
📑 Code : 내꺼
📌 Logic 설명
내가 직접 푼 것은 아니고, 다른 사람 풀이 보고 학습 후 해당 풀이를 보지 않고 풀었음.
- 기존 코드를 개선
> code
def solution(bridge_length, weight, truck_weights):
# truck이 지나갈 bridge를 리스트로 생성.
# bridge의 각 요소는 해당 위치의 무게를 의미함.
bridge = [0] * bridge_length
# bridge의 무게의 총 합을 미리 계산
# 아래에서 계산이 필요할 경우에 sum(bridge)로 계산해도 되지만, 그렇게 할 경우에는 시간 초과가 발생.
# sum 함수는 시간 복잡도가 O(N)이기 때문.
bridge_weight_sum = 0
# 총 소요 시간을 계산할 변수를 sec이라 지정하고 0을 할당.
# second의 약자
sec = 0
# bridge가 남아 있으면 계속해서 반복
while bridge:
# 1초가 지나감.
sec += 1
# bridge의 제일 앞에 있는 무게는 다리를 빠져 나감.
bridge_weight_sum -= bridge.pop(0)
# print(f"1번째 bridge : {bridge}")
# 만약 다리를 건너야 할 트럭이 아직 존재하는 경우에
if truck_weights:
# 현재 다리 위의 총 무게와 대기 중인 첫 번째 트럭의 무게의 합이 다리가 견딜 수 있는 무게보다 작거나 같다면
if bridge_weight_sum + truck_weights[0] <= weight:
# 다리의 마지막 위치에 대기 중인 첫 번째 트럭을 추가
bridge_weight_sum += truck_weights[0]
# 다리의 총 무게는 그 트럭의 무게만큼 늘려줌
bridge.append(truck_weights.pop(0))
# print(f"2번째 bridge : {bridge}")
# 만약, 그 트럭이 다리에 올라오게 되었을 때 다리가 견디지 못한다면
else:
# 다리의 마지막 자리를 빈 무게로 채운다.
bridge.append(0)
# print(f"3번째 bridge : {bridge}")
return sec🔎 예시를 통한 확인
- 위의 코드에는
예시를 통한 출력 내용 확인
bridge_length = 5 weight = 5 truck_weights = [2,2,2,2,1,1,1,1] solution(bridge_length, weight, truck_weights) --- 출력 결과 --- sec : 1 1번째 bridge : [0, 0, 0, 0] 2번째 bridge : [0, 0, 0, 0, 2] sec : 2 1번째 bridge : [0, 0, 0, 2] 2번째 bridge : [0, 0, 0, 2, 2] sec : 3 1번째 bridge : [0, 0, 2, 2] 3번째 bridge : [0, 0, 2, 2, 0] sec : 4 1번째 bridge : [0, 2, 2, 0] 3번째 bridge : [0, 2, 2, 0, 0] sec : 5 1번째 bridge : [2, 2, 0, 0] 3번째 bridge : [2, 2, 0, 0, 0] sec : 6 1번째 bridge : [2, 0, 0, 0] 2번째 bridge : [2, 0, 0, 0, 2] sec : 7 1번째 bridge : [0, 0, 0, 2] 2번째 bridge : [0, 0, 0, 2, 2] sec : 8 1번째 bridge : [0, 0, 2, 2] 2번째 bridge : [0, 0, 2, 2, 1] sec : 9 1번째 bridge : [0, 2, 2, 1] 3번째 bridge : [0, 2, 2, 1, 0] sec : 10 1번째 bridge : [2, 2, 1, 0] 3번째 bridge : [2, 2, 1, 0, 0] sec : 11 1번째 bridge : [2, 1, 0, 0] 2번째 bridge : [2, 1, 0, 0, 1] sec : 12 1번째 bridge : [1, 0, 0, 1] 2번째 bridge : [1, 0, 0, 1, 1] sec : 13 1번째 bridge : [0, 0, 1, 1] 2번째 bridge : [0, 0, 1, 1, 1] sec : 14 1번째 bridge : [0, 1, 1, 1] sec : 15 1번째 bridge : [1, 1, 1] sec : 16 1번째 bridge : [1, 1] sec : 17 1번째 bridge : [1] sec : 18 1번째 bridge : [] --- return 값 --- 18
📑 Code : 다른 사람꺼
상봉님 코드
- ..
> code
def solution(bridge_length, weight, truck_weights):
count = 0 # 경과 시간
weight_sum = 0 # 다리 위의 트럭들의 무게의 합
bridge = [] # 다리 위에 있는 트럭들
while truck_weights:
count += 1
# 트럭이 다리 위로 올라갈 수 있는 조건
if ((weight_sum + truck_weight[0]) <= weight and len(bridge) <= bridge_length):
# 트럭을 다리 위에 올리고
bridge.append(truck_weights.pop())
# 올린 트럭의 무게를 총 무게에 더한다.
weight_sum += bridge[-1]
else:
# 다리 위로 올라갈 수 없다면 빈 공간으로 채운다.
bridge.append(0)
# 경과한 시간이 다리 길이보다 크면, 다리에서 나온 트럭들의 무게를 빼준다.
if count >= bridge_length:
weight_sum -= bridge.pop(0)
# 총 경과 시간 + 다리 위에 있는 트럭들이 지나갈 시간
return count + bridge_length프로그래머스 코드
- 아직 이 코드는 정확히 이해를 하지 못함.
> code
def solution(bridge_length, weight, truck_weights):
t = 0
on = [] # (weight, stayed)
while truck_weights or on:
for i, e in enumerate(on):
on[i] = (e[0], e[1] + 1)
print(f"1번째 on : {on}")
on = list(filter(lambda x: x[1] < bridge_length + 1, on))
print(f"2번째 on : {on}")
weight_sum = 0
for e in on:
weight_sum += e[0]
print(weight_sum)
if truck_weights:
if weight_sum + truck_weights[0] <= weight:
on.append((truck_weights.pop(0), 1))
print(f"3번째 on : {on}")
t += 1
print(f"t : {t}")
# print(str(t)+":"+str(on))
return t🔎 예시를 통한 확인
- 위의 코드에는
예시를 통한 출력 내용 확인bridge_length = 5 weight = 5 truck_weights = [2,2,2,2,1,1,1,1] solution(bridge_length, weight, truck_weights) --- 출력 결과 --- 2번째 on : [] 3번째 on : [(2, 1)] t : 1 1번째 on : [(2, 2)] 2번째 on : [(2, 2)] weight_sum : 2 3번째 on : [(2, 2), (2, 1)] t : 2 1번째 on : [(2, 3), (2, 1)] 1번째 on : [(2, 3), (2, 2)] 2번째 on : [(2, 3), (2, 2)] weight_sum : 2 weight_sum : 4 t : 3 1번째 on : [(2, 4), (2, 2)] 1번째 on : [(2, 4), (2, 3)] 2번째 on : [(2, 4), (2, 3)] weight_sum : 2 weight_sum : 4 t : 4 1번째 on : [(2, 5), (2, 3)] 1번째 on : [(2, 5), (2, 4)] 2번째 on : [(2, 5), (2, 4)] weight_sum : 2 weight_sum : 4 t : 5 1번째 on : [(2, 6), (2, 4)] 1번째 on : [(2, 6), (2, 5)] 2번째 on : [(2, 5)] weight_sum : 2 3번째 on : [(2, 5), (2, 1)] t : 6 1번째 on : [(2, 6), (2, 1)] 1번째 on : [(2, 6), (2, 2)] 2번째 on : [(2, 2)] weight_sum : 2 3번째 on : [(2, 2), (2, 1)] t : 7 1번째 on : [(2, 3), (2, 1)] 1번째 on : [(2, 3), (2, 2)] 2번째 on : [(2, 3), (2, 2)] weight_sum : 2 weight_sum : 4 3번째 on : [(2, 3), (2, 2), (1, 1)] t : 8 1번째 on : [(2, 4), (2, 2), (1, 1)] 1번째 on : [(2, 4), (2, 3), (1, 1)] 1번째 on : [(2, 4), (2, 3), (1, 2)] 2번째 on : [(2, 4), (2, 3), (1, 2)] weight_sum : 2 weight_sum : 4 weight_sum : 5 t : 9 1번째 on : [(2, 5), (2, 3), (1, 2)] 1번째 on : [(2, 5), (2, 4), (1, 2)] 1번째 on : [(2, 5), (2, 4), (1, 3)] 2번째 on : [(2, 5), (2, 4), (1, 3)] weight_sum : 2 weight_sum : 4 weight_sum : 5 t : 10 1번째 on : [(2, 6), (2, 4), (1, 3)] 1번째 on : [(2, 6), (2, 5), (1, 3)] 1번째 on : [(2, 6), (2, 5), (1, 4)] 2번째 on : [(2, 5), (1, 4)] weight_sum : 2 weight_sum : 3 3번째 on : [(2, 5), (1, 4), (1, 1)] t : 11 1번째 on : [(2, 6), (1, 4), (1, 1)] 1번째 on : [(2, 6), (1, 5), (1, 1)] 1번째 on : [(2, 6), (1, 5), (1, 2)] 2번째 on : [(1, 5), (1, 2)] weight_sum : 1 weight_sum : 2 3번째 on : [(1, 5), (1, 2), (1, 1)] t : 12 1번째 on : [(1, 6), (1, 2), (1, 1)] 1번째 on : [(1, 6), (1, 3), (1, 1)] 1번째 on : [(1, 6), (1, 3), (1, 2)] 2번째 on : [(1, 3), (1, 2)] weight_sum : 1 weight_sum : 2 3번째 on : [(1, 3), (1, 2), (1, 1)] t : 13 1번째 on : [(1, 4), (1, 2), (1, 1)] 1번째 on : [(1, 4), (1, 3), (1, 1)] 1번째 on : [(1, 4), (1, 3), (1, 2)] 2번째 on : [(1, 4), (1, 3), (1, 2)] weight_sum : 1 weight_sum : 2 weight_sum : 3 t : 14 1번째 on : [(1, 5), (1, 3), (1, 2)] 1번째 on : [(1, 5), (1, 4), (1, 2)] 1번째 on : [(1, 5), (1, 4), (1, 3)] 2번째 on : [(1, 5), (1, 4), (1, 3)] weight_sum : 1 weight_sum : 2 weight_sum : 3 t : 15 1번째 on : [(1, 6), (1, 4), (1, 3)] 1번째 on : [(1, 6), (1, 5), (1, 3)] 1번째 on : [(1, 6), (1, 5), (1, 4)] 2번째 on : [(1, 5), (1, 4)] weight_sum : 1 weight_sum : 2 t : 16 1번째 on : [(1, 6), (1, 4)] 1번째 on : [(1, 6), (1, 5)] 2번째 on : [(1, 5)] weight_sum : 1 t : 17 1번째 on : [(1, 6)] 2번째 on : [] t : 18 --- return 값 --- 18
💡 새롭게 알게된 점
📌
🌞 주식가격
🚊 문제 설명
📢 초 단위로 기록된 주식가격이 담긴 배열 prices가 매개변수로 주어질 때, 가격이 떨어지지 않은 기간은 몇 초인지를 return 하도록 solution 함수를 완성하세요.
🚊 제한사항
- prices의 각 가격은 1 이상 10,000 이하인 자연수입니다.
- prices의 길이는 2 이상 100,000 이하입니다.
🚊 입출력 예

입출력 예 설명
- 1초 시점의 ₩1은 끝까지 가격이 떨어지지 않았습니다.
- 2초 시점의 ₩2은 끝까지 가격이 떨어지지 않았습니다.
- 3초 시점의 ₩3은 1초뒤에 가격이 떨어집니다.
따라서 1초간 가격이 떨어지지 않은 것으로 봅니다.- 4초 시점의 ₩2은 1초간 가격이 떨어지지 않았습니다.
- 5초 시점의 ₩3은 0초간 가격이 떨어지지 않았습니다.
📑 Code : 내꺼
📌 Logic 설명
코드에 직접 적음
> code
from collections import deque
def solution(prices):
length = len(prices)
# 가격이 떨어지지 않은 기간은 몇 초인지를 기록할 리스트를 생성
# 초기 값은 모두 0으로 셋팅
answer = [0] * length
# 리스트 전체를 반복하면서
for i in range(length):
# i번째 요소의 다음부터 끝에 있는 모든 요소들을 탐색
for j in range(i+1, length):
# 다음 요소로 넘어가서 조건을 만족하는 경우에 answer의 i번째 요소에 1초를 추가
# 이 코드가 if문보다 위에 있는 이유는 본인보다 뒤에 어떤 비교대상이 있는 경우에
# 그 대상이 나보다 크든 작든 간에 1초동안은 가격이 떨어지지 않은 것으로 간주할 것이기 때문임.
answer[i] +=1
# 만약 나보다 가격이 떨어진 요소를 발견하게 되면
if prices[i] > prices[j]:
# 반복문을 멈추고 빠져나감
break
return answer📑 Code : 다른 사람꺼
강사님 코드
- '오큰수' 문제 풀이 방식 활용
stack을 활용- 주어진 요소를 차례대로 하나씩 뽑아서
stack에 담았다가 조건을 만족하면 제거 - 주식 가격이 떨어졌으면 그 떨어진 시간을 계산 후
stack에서 제거
- 주어진 요소를 차례대로 하나씩 뽑아서
> code
def solution(prices):
# 각각의 주식가격마다 가격이 떨어지지 않은 기간을 담을 리스트를 생성
# 기초 시간은 모두 0초로 셋팅
answer = [0]*len(prices)
# 비교의 기준이 될 요소의 index를 담을 빈 리스트를 stack으로 활용
stack = []
# 주식가격 리스트에 대해 반복문을 돌면서 아래 내용을 확인
for i in range(len(prices)):
# 비교 기준이 아직 남아 있고, 그런데 어딘가에서 주식 가격이 떨어졌다면
while stack and prices[stack[-1]] > prices[i]:
# stack에서 현재 비교 기준 주식가격의 위치를 뽑아옴
# 주식이 떨어진 시각을 갱신하기 위함
s = stack.pop()
# 주식 가격이 떨어진 위치와 현재 비교 기준의 주식가격의 위치의 차이를 구함
# 가격이 떨어지지 않은 기간을 담은 리스트에서 비교 기준의 위치의 시간을 갱신
answer[s] = i-s
# 비교 기준이 남아있지 않거나, 비교 기준이 있더라도 그 다음 요소보다 가격이 떨어지지 않았다면
# 그 다음 요소를 비교 기준 리스트에 대기시킴
stack.append(i)
# 주식 가격이 떨어지지 않은 요소들만 stack에 남아있는 상황이므로
# 각각의 요소들에 대해 주식 가격이 떨어지지 않은 시간을 계산하면 됨.
while stack:
# stack에서 제일 앞에 있는 요소(index 값임)들을 꺼내서
s = stack.pop()
# 그 위치의 주식가격이 떨어지지 않은 시간을 계산
# 전체 리스트의 요소의 개수에서 나를 포함하여 나보다 왼쪽에 있는 요소의 개수만큼을 뺄셈
# s는 index이고, index가 의미하는 바가 나보다 왼쪽에 있는 요소의 개수이므로
# 자기 자신인 1개만큼을 포함시킨 (s+1)이 바로 '나를 포함하여 나보다 왼쪽에 있는 요소'의 개수를 의미
answer[s] = len(prices)-(s+1)
return answer📑 Code : 다른 사람꺼
프로그래머스 코드
> code
def solution(prices):
# stack으로 활용할 빈 리스트 생성
# stack에 들어가는 요소: [본인의 index, 본인의 price]
# 즉, stack은 2차원 리스트 형태로 구성될 예정
stack = []
# 가격이 떨어지지 않은 기간은 몇 초인지를 기록할 리스트를 생성
# 초기 값은 모두 0으로 셋팅
answer = [0] * len(prices)
# 리스트 전체에 대해 반복문을 돌면서
for i in range(len(prices)):
# print(f"i : {i}")
# stack에 어떤 요소가 있고,
# stack내의 마지막 요소(기준 요소)의 price가 현재 i번째 대상의 price보다 크다면
# └ 이말 인즉, 주식 가격이 떨어진 것을 의미함
while stack and stack[-1][1] > prices[i]:
# stack의 마지막 요소(기준 요소)를 추출
# 기준 요소의 index를 past에 할당
# 기준 요소의 price는 이미 바로 위의 while문에서 써먹었기 때문에 더이상 쓸일이 없어서 _ 에 할당
past, _ = stack.pop()
# print(f"past : {past}")
# print(f"_ : {_}")
# 기준 요소의 주식 가격이 떨어지지 않은 기간을 갱신
# i - past의 의미 : i번째 대상의 위치(주식 가격이 떨어진 위치) - 기준 요소의 위치
answer[past] = i - past
# print(f"answer : {answer}")
# stack에 빈 요소가 없거나
# stack의 마지막 요소의 price보다 i번째 대상의 price가 더 크거나 같다면
# i번째 대상의 요소를 [요소의 index, 요소의 주식 가격] 의 형태로 stack에 추가
stack.append([i, prices[i]])
# print(f"stack : {stack}")
# 위의 과정까지 거치면, 주식 가격이 떨어지지 않은 요소들은 stack에 남아 있음
# 이제 stack에 남은 요소들에 대해 반복문을 돌면서
for i, s in stack:
# i번째 요소의 주식 가격이 떨어지지 않은 기간을 계산하여 갱신
# 주식 가격이 떨어지지 않은 기간 = 배열의 전체 길이 - 본인의 index
# `본인의 index` 가 '나보다 앞에 있는 요소의 개수'를 뜻한다는 점을 이용
answer[i] = len(prices) - 1 - i
# print(f"answer : {answer}")
return answer🔎 예시를 통한 확인
- 위의 코드에는
예시를 통한 출력 내용 확인
prices = [1,2,3,2,3] solution(prices) --- 출력 결과 --- (for문 시작) i : 0 stack : [[0, 1]] i : 1 stack : [[0, 1], [1, 2]] i : 2 stack : [[0, 1], [1, 2], [2, 3]] i : 3 (while문 시작) past : 2 _ : 3 answer : [0, 0, 1, 0, 0] (while문 끝) stack : [[0, 1], [1, 2], [3, 2]] i : 4 stack : [[0, 1], [1, 2], [3, 2], [4, 3]] (2번째 for문 시작) answer : [4, 0, 1, 0, 0] answer : [4, 3, 1, 0, 0] answer : [4, 3, 1, 1, 0] answer : [4, 3, 1, 1, 0] --- return 값 --- [4, 3, 1, 1, 0]
💡 새롭게 알게된 점
📌 리스트에서 해당 요소의 index가 의미하는 것이 리스트 내에서 본인보다 앞에 있는 요소의 개수 를 뜻하기도 한다는 점!!
