멀티 스레드 환경에서 java.util.Random 대신 ThreadLocalRandom을 사용하는 것이 좋다고 합니다. 이에 대한 이유가 궁금해 글을 작성하고자 합니다.
ThreadLocal
ThreadLocalRandom에 대해 얘기하기 전 ThreadLocal 클래스에 대해 먼저 얘기하고자 합니다. ThreadLocal은 스레드 지역변수를 이용할 때 사용하는 클래스입니다.
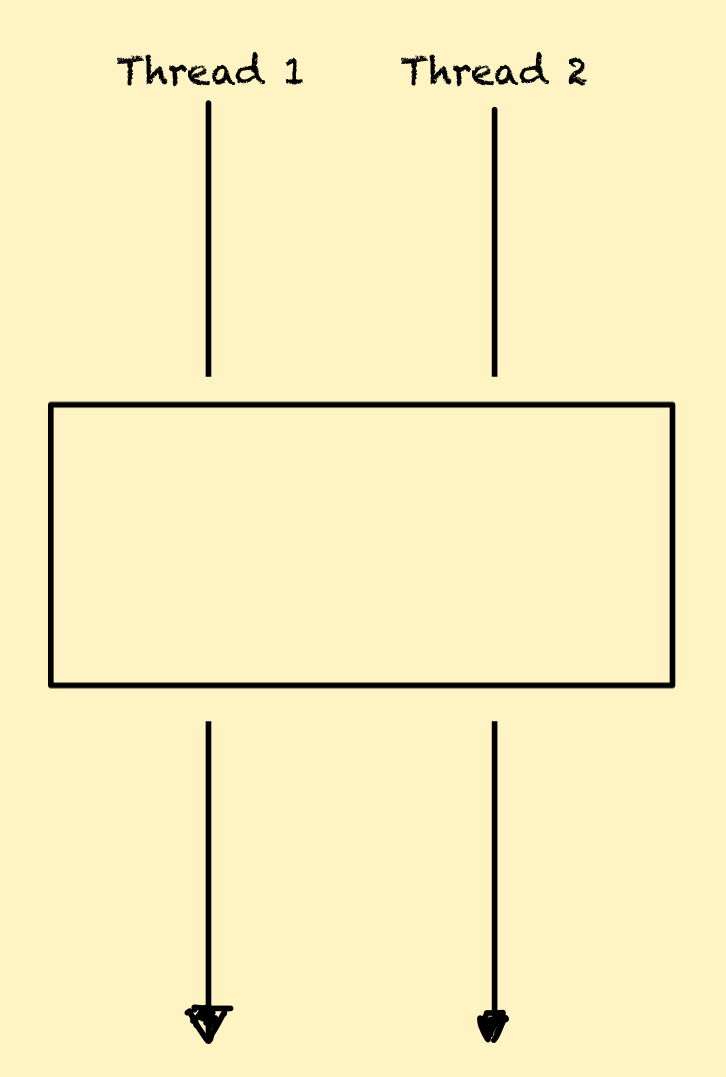
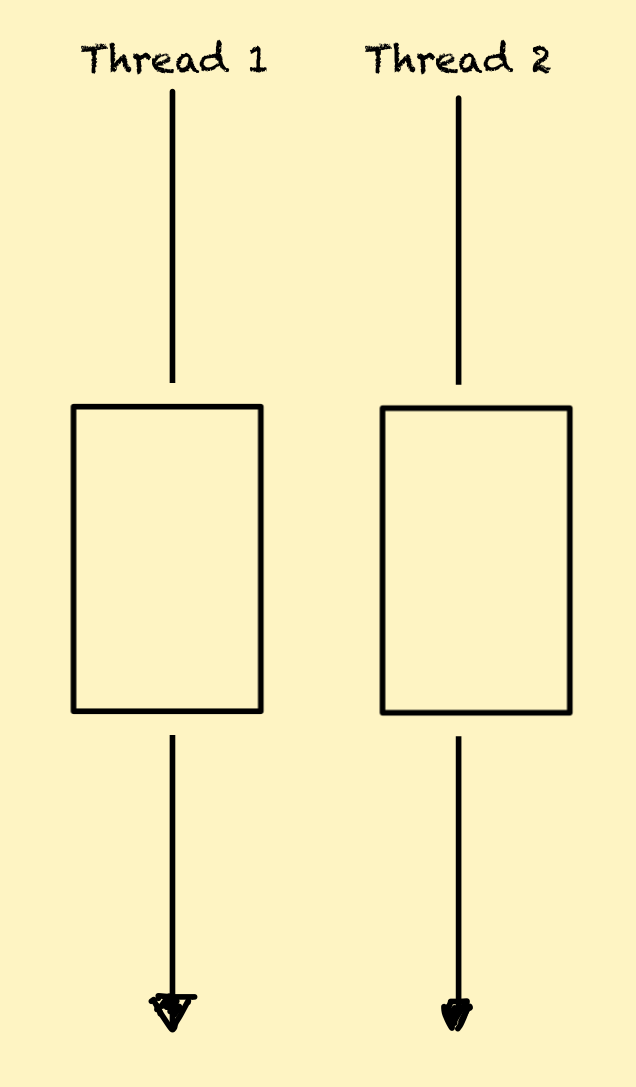
멀티 스레드 환경에서 모든 멤버 변수는 기본적으로 여러 스레드에서 공유해서 쓰일 수 있습니다. 이런 상황에서 스레드 안정성과 관련된 다음과 같은 문제가 발생할 수 있습니다.
- race condition
- 공유자원에 대한 두 스레드의 접근 순서에 따라 결과가 달라지는 현상
- deadlock
- 서로에 의해 만족될 수 있는 자원을 무한히 기다리는 현상
- livelock
- 두 스레드가 락의 획득과 해제를 무한히 반복하는 현상
이때 스레드 지역변수를 사용하면 동기화를 하지 않아도 한 스레드에서만 접근 가능한 값이기 때문에 안전하게 사용할 수 있게 됩니다.
또한 ThreadLocal 은 한 스레드 내에서 공유하는 데이터로, 메서드 매개변수에 매번 전달하지 않고 전역변수 처럼 사용할 수 있습니다.
public class ThreadLocalExample implements Runnable {
private List<Integer> data = Arrays.asList(1, 2, 3);
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample2 obj = new ThreadLocalExample2();
for (int i = 0; i < 10; i++) {
Thread t = new Thread(obj, "[Thread] " + i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread name = " + Thread.currentThread().getName() + " default value = " + data);
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
data = Arrays.asList(4, 5, 6);
System.out.println("Thread name = " + Thread.currentThread().getName() + " value = " + data);
}
}(예제가 다소 어색하지만 ThreadLocal을 사용하기 위한 예제 정도로 생각해주시면 감사하겠습니다.)
우리는 [1, 2, 3] 이라는 값을 출력한 후, [4, 5, 6]으로 바꾸고 그 값을 출력하려고 합니다. 이때 각 스레드들은 [1, 2, 3] 을 출력 후, [4, 5, 6] 을 출력할 것이라 기대되지만 실제로는 그렇지 않습니다.
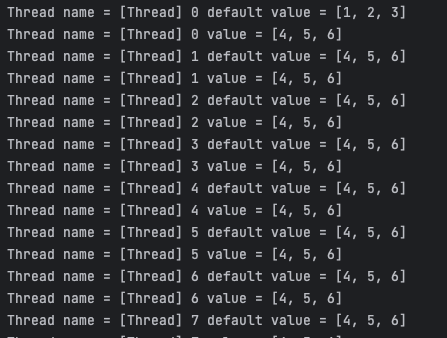
0번 스레드가 data의 값을 [4, 5, 6]으로 바꾸어버려 나머지 스레드들도 영향을 받게 됩니다. 이 문제를 해결하기 위해 ThreadLocal을 사용할 수 있습니다.
public class ThreadLocalExample implements Runnable {
private static final ThreadLocal<List<Integer>> data = ThreadLocal.withInitial(() -> Arrays.asList(1, 2, 3));
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample2 obj = new ThreadLocalExample2();
for (int i = 0; i < 10; i++) {
Thread t = new Thread(obj, "[Thread] " + i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread name = " + Thread.currentThread().getName() + " default value = " + data.get());
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
data.set(Arrays.asList(4, 5, 6));
System.out.println("Thread name = " + Thread.currentThread().getName() + " value = " + data.get());
}
}
ThreadLocal을 사용해 스레드마다 각자의 저장소를 만들어 문제를 해결했습니다.
java.util.Random
이제 ThreadLocal이 뭔지 알았으니 Random이 뭔지도 알아보려고 합니다. java.util.Random은 멀티 스레드 환경에서 CAS(Compare And Set 혹은 Compare And Swap)으로 인해 실패할 가능성이 있기 때문에 성능이 좋지는 않습니다.
실제로 Random 클래스의 next 메서드를 보면 다음과 같습니다.
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}눈에 띄는 건 compareAndSet 입니다. 이에 대해 알아보겠습니다.
CAS (Compare And Set(Swap))
compareAndSet의 결과 값이 true 가 나올 때까지 반복하는 것을 볼 수 있습니다. compareAndSet은 native 메서드라 직접 확인할 수 없지만 다음과 같은 과정으로 이루어집니다.
- 메서드의 인자로 기댓값과 변경값을 전달합니다.
- 값을 비교한 뒤 true 혹은 false를 반환합니다.
2-1. 기댓값과 현재 메모리가 가지고 있는 값이 같다면 변경할 값으로 바꾼 뒤, true를 반환합니다.
2-2. 기댓값과 현재 메모리가 가지고 있는 값이 다르면 값을 바꾸지 않고, false를 반환합니다.
간단하게 자바 코드로 나타내보면 다음과 같습니다. (실제와 다르다는 것을 주의해주세요. 이해를 돕기 위해 작성했습니다.)
public synchronized boolean comparedAndSet(int expectedValue, int updatedValue) {
int readValue = value;
if (readValue == expectedValue) {
value = updatedValue;
return true;
}
return false;
}이런 CAS 알고리즘은
Optimistic locking을 사용하고 있다고 볼 수 있습니다. 왜냐하면 락을 걸지 않고 일단 자원에 대해 변경을 시도한 후, 실패한다면 성공할 때까지 반복하는 과정을 거치기 때문입니다.
Atomic
AtomicLong 클래스도 내부적으로 CAS 알고리즘을 이용하고 있습니다.
getAndIncrement 메서드를 살펴보겠습니다.
public final long getAndIncrement() {
return U.getAndAddLong(this, VALUE, 1L);
}
@IntrinsicCandidate
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
v = getLongVolatile(o, offset);
} while (!weakCompareAndSetLong(o, offset, v, v + delta));
return v;
} public final long get() {
return value;
}
public final void set(long newValue) {
U.putLongVolatile(this, VALUE, newValue);
}눈여겨 볼 점은 volatile 키워드가 붙은 것입니다.
CAS 알고리즘은 원자적 연산(하드웨어의 도움을 받아 한 번에 동작하는 연산)이지만 메모리 일관성 오류가 발생할 수 있습니다. volatile 키워드를 붙여 메모리까지 값을 read-write 하여 일관성 오류를 제거한 것으로 생각됩니다.
ThreadLocalRandom
Random 까지 알아봤으니 이제 왜 멀티스레드 환경에서는 ThreadLocalRandom을 쓰는게 더 나은지 알 것 같습니다. Ramdom 같은 경우 CAS 알고리즘을 이용하고, 다른 스레드에 의해 간섭을 받게 될 수 있습니다. 그러면 계속 값을 비교하는 시도가 계속 될 수 있기 때문입니다.
이때 ThreadLocalRandom을 사용하면 스레드 전용 Random 이 생성되어 다른 스레드에 간섭을 받지 않아 성능이 더 좋습니다.
결론
java.util.Random 자체도 스레드 세이프한 것을 확인할 수 있었습니다. 하지만 멀티스레드 환경에서 ThreadLocalRandom을 사용하는 이유는 Random이 CAS로 인해 실패할 가능성이 존재하기 때문에 성능상 불리할 수 있기 때문입니다.
그래서 멀티스레드 환경에서는 각 스레드마다 Random 이 할당되는 ThreadLocalRandom을 사용하는 것이 좋다는 것이었습니다.
참고 자료
https://docs.oracle.com/javase/8/docs/api/java/lang/ThreadLocal.html
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/atomic/package-summary.html
https://docs.oracle.com/javase/tutorial/essential/concurrency/atomic.html