이전 포스팅에서 쿠폰 발급 로직을 개선 하였고, 이번에는 DB에 요청되는 쿼리를 개선하는 과정을 포스팅해보고자 합니다.
개요
K6를 활용한 부하테스트 중 많은 데이터가 있다는 가정하에 쿠폰 발급 요청을 날렸을 때 타임아웃이 나는 것을 확인할 수 있었습니다.
org.springframework.transaction.CannotCreateTransactionException: Could not open JPA EntityManager for transaction
Unable to acquire JDBC Connection
HikariPool-1 - Connection is not available, request timed out after 3005ms.쿠폰 발급의 트랜잭션을 시작하며 커넥션을 얻고 HikariCP에 커넥션을 반납하지 못해 나타나는 문제로 생각했습니다. 그렇다면 어디가 병목지점인지 알 필요가 있었는데요. DB에 많은 데이터를 넣기 전에는 문제가 발생하지 않았기에, DB가 병목지점이라고 판단했습니다. DB의 어떤 지점이 문제를 일으키고 있는지 확인하기 위해 AWS CloudWatch 를 이용했습니다.
슬로우 쿼리로 인해 문제가 발생한 것을 확인할 수 있었는데요, 이를 개선하기 위해 슬로우 쿼리 분석해보기로 결정했습니다.
슬로우쿼리 모니터링 설정
저희 프로젝트에서는 데이터베이스로 AWS RDS를 사용하고 있는데, AWS 에서 기본적으로 CloudWatch 모니터링을 제공합니다. 기본적인 지표들은 손쉽게 확인할 수 있지만 슬로우 쿼리나 DB 로그들을 확인하기 위해서는 몇 가지 추가 설정이 필요합니다.
먼저 RDS 설정에서 로그 내보내기 설정에서 느린 쿼리 로그를 선택합니다.

그리고 슬로우 쿼리를 파일로 내보내기 위한 몇 가지 설정을 위해 파라미터를 설정해줘야 하는데요. RDS 파라미터 그룹에서 파라미터 그룹을 생성하고 아래 파라미터를 검색해 값을 편집해야 합니다.
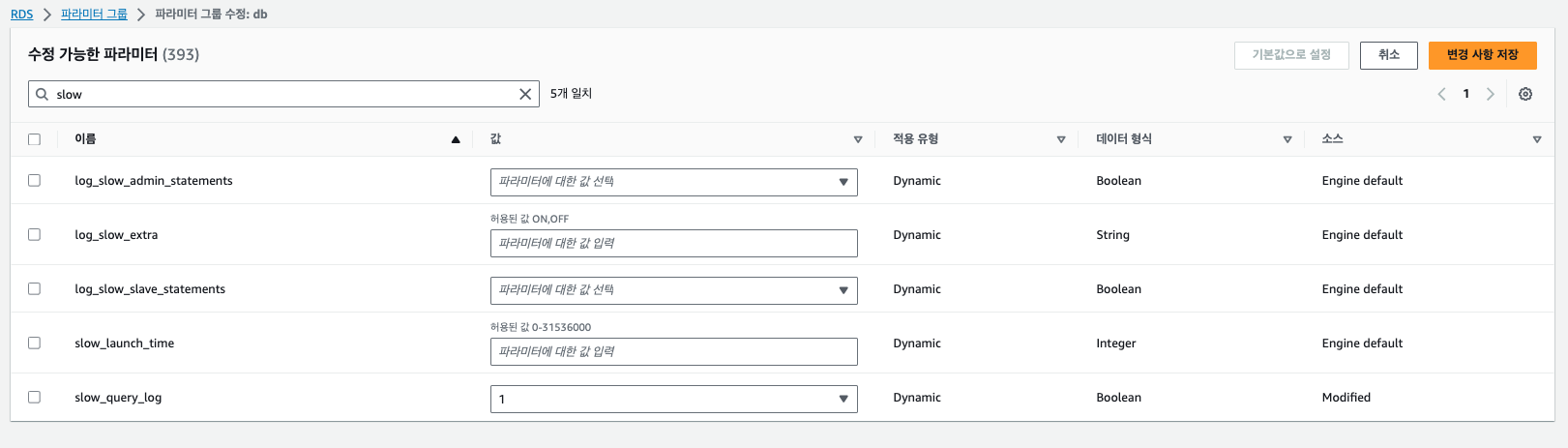
- slow_query_log = 1 (기본값 0)
- long_query_time = 1
- 몇 초 이상 실행된 쿼리에 대해 로그를 남길 것인지 결정합니다.
- 저희 프로젝트에서는 1초 이상의 쿼리에 대해 로그를 남기기로 결정했습니다.
- log_output = FILE
이렇게 편집된 파라미터 그룹을 DB 인스턴스에 적용해주도록 합니다.

여기까지 완료되면 DB가 수정되며 파라미터 그룹이 적용됩니다. 그러면 이제 RDS 대시보드에서 다음과 같은 화면을 확인할 수 있습니다.

슬로우 쿼리가 파일 형태로 남아있는 것을 확인할 수 있는데요. 어떤 쿼리들이 문제를 일으키는지 확인해보겠습니다.
# Time: 2023-11-21T15:40:54.099470Z
# User@Host: admin[admin] @ [10.1.1.152] Id: 300
# Query_time: 3.309853 Lock_time: 0.000003 Rows_sent: 3 Rows_examined: 2999787
use promotion;
SET timestamp=1700581250;
select promotiono0_.id as id1_8_, promotiono0_.last_order_at as last_ord2_8_, promotiono0_.last_order_before as last_ord3_8_, promotiono0_.member_type as member_t4_8_, promotiono0_.promotion_id as promotio5_8_ from promotion_option promotiono0_ left outer join promotion promotion1_ on promotiono0_.promotion_id=promotion1_.id where promotion1_.id=1;
# Time: 2023-11-21T15:40:55.795175Z
# User@Host: admin[admin] @ [10.1.1.152] Id: 300
# Query_time: 1.685002 Lock_time: 0.000002 Rows_sent: 1 Rows_examined: 2999603
SET timestamp=1700581254;
select promotiono0_.id as id1_9_0_, coupongrou1_.id as id1_2_1_, promotiono0_.coupon_group_id as coupon_g2_9_0_, promotiono0_.promotion_option_id as promotio3_9_0_, coupongrou1_.admin_nickname as admin_ni2_2_1_, coupongrou1_.finished_at as finished3_2_1_, coupongrou1_.is_random as is_rando4_2_1_, coupongrou1_.promotion_id as promotio8_2_1_, coupongrou1_.started_at as started_5_2_1_, coupongrou1_.title as title6_2_1_, coupongrou1_.type as type7_2_1_ from promotion_option_coupon_group promotiono0_ inner join coupon_group coupongrou1_ on promotiono0_.coupon_group_id=coupongrou1_.id where promotiono0_.promotion_option_id=1;
# Time: 2023-11-21T15:41:08.433419Z
# User@Host: admin[admin] @ [10.1.1.152] Id: 300
# Query_time: 12.632252 Lock_time: 0.000003 Rows_sent: 4 Rows_examined: 9999772
SET timestamp=1700581255;
select coupon0_.id as id1_1_, coupon0_.created_at as created_2_1_, coupon0_.coupon_group_id as coupon_g8_1_, coupon0_.discount as discount3_1_, coupon0_.initial_quantity as initial_4_1_, coupon0_.remain_quantity as remain_q5_1_, coupon0_.title as title6_1_, coupon0_.type as type7_1_ from coupon coupon0_ left outer join coupon_group coupongrou1_ on coupon0_.coupon_group_id=coupongrou1_.id where coupongrou1_.id=1;
# Time: 2023-11-21T15:41:18.232504Z
# User@Host: admin[admin] @ [10.1.1.152] Id: 300
# Query_time: 9.791262 Lock_time: 0.000003 Rows_sent: 4 Rows_examined: 9999772
SET timestamp=1700581268;
select coupon0_.id as col_0_0_ from coupon coupon0_ where coupon0_.coupon_group_id=1;현재 프로젝트에는 어떠한 인덱스도 걸려있지 않기 때문에 풀 테이블 스캔을 통해 레코드를 읽어와 느린 것으로 파악이 되는데요. 이제 이를 개선해보겠습니다.
MySQL 쿼리 최적화
쿼리를 차례대로 분석해 나가보도록 하겠습니다.
select * from promotion_option po left join promotion p on po.promotion_id = p.id where p.id = 1;
mysql> explain select * from promotion_option po left join promotion p on po.promotion_id = p.id where p.id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
| 1 | SIMPLE | p | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | po | NULL | ALL | NULL | NULL | NULL | NULL | 2959992 | 10.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
mysql> explain analyze select * from promotion_option po left join promotion p on po.promotion_id = p.id where p.id = 1;
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Filter: (po.promotion_id = 1) (cost=305637 rows=295999) (actual time=2.53..6118 rows=3 loops=1)
-> Table scan on po (cost=305637 rows=2.96e+6) (actual time=2.52..3840 rows=3e+6 loops=1)
|
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (6.17 sec)먼저 EXPLAIN ANALYZE 기능을 이용해 쿼리의 실행 계획과 단계별 소요된 시간 정보를 분석하겠습니다.
- promotion_option 테이블을 Table scan
- 조건(promotion_id가 1)에 일치하는 건 하나를 가져옴
promotion_option 테이블에는 PK를 제외한 나머지 컬럼에는 어떠한 인덱스도 걸려있지 않기 때문에 LEFT JOIN시에 promtion_id 컬럼을 가지고 풀 테이블 스캔을 수행합니다. 이후 조건에 맞는 로우를 필터링 합니다.
EXPLAIN 기능을 이용해 분석한 쿼리를 확인해 보면
- type
- const
- 테이블의 레코드 건수에 관계없이 쿼리가 PK 혹은 UK 컬럼을 이용하는 WHERE 조건 절을 가지고 있으며 반드시 1건을 반환하는 경우의 처리 방식입니다.
- ALL
- 풀 테이블 스캔을 의미하는 접근 방법입니다.
- const
- key
- PRIMARY
- 최종 선택된 실행 계획에서 사용하는 인덱스를 의미합니다.
- PRIMARY
- key_len
- 인덱스의 각 레코드에서 몇 바이트까지 사용했는지 알려주는 값입니다.
- id의 타입은 BIGINT이기 때문에 8byte를 사용 하고 있습니다.
- rows
- 옵티마이저는 얼마나 많은 레코드를 읽고 비교해야 하는지 예측해서 비용을 산정하는데, 대상 테이블에 얼마나 많은 레코드가 포함되어 있는지 혹은 각 인덱스의 분포도가 어떤지를 통계 정보를 기준으로 조사해서 예측합니다.
- 이때 rows 칼럼 값은 실행 계획의 효율성 판단을 위해 예측했던 레코드 건수를 보여줍니다.
두 결과의 정보를 종합해보면
- 풀 테이블 스캔을 통해
promotion_option테이블을 스캔하고 (약 300만 건의 레코드) - 대상 테이블의
promotion_id컬럼 값을 기준으로 LEFT JOIN을 수행한 뒤 promotion테이블의 PK를 기준으로 한 건의 결과를 반환
이때 개선할 수 있는 사항은 promotion_option 테이블의 promotion_id 컬럼에 인덱스를 거는 것이라고 판단했습니다.
CREATE INDEX promotion_id_idx ON promtion_option (promotion_id);인덱스를 적용한 후 다시 결과를 살펴보면 다음과 같습니다.
mysql> explain select * from promotion_option po left join promotion p on po.promotion_id = p.id where p.id = 1;
+----+-------------+-------+------------+-------+------------------+------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+------------------+------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | p | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | po | NULL | ref | promotion_id_idx | promotion_id_idx | 8 | const | 3 | 100.00 | NULL |
+----+-------------+-------+------------+-------+------------------+------------------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
mysql> explain analyze select * from promotion_option po left join promotion p on po.promotion_id = p.id where p.id = 1;
+----------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+----------------------------------------------------------------------------------------------------------------------------+
| -> Index lookup on po using promotion_id_idx (promotion_id=1) (cost=2.72 rows=3) (actual time=2.96..2.96 rows=3 loops=1)
|
+----------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.02 sec)promotion_id_idx 인덱스를 이용해 index lookup을 수행합니다. 이때 ref 접근 방법을 사용하는데 동등(Equal) 조건으로 검색할 때 사용되는 접근방법입니다.
결과적으로 처음 6초 걸리던 쿼리를 0.02초로 개선할 수 있었습니다.
select * from promotion_option_coupon_group pocg inner join coupon_group cg on pocg.coupon_group_id = cg.id where pocg.promotion_option_id = 1;
mysql> explain select * from promotion_option_coupon_group pocg inner join coupon_group cg on pocg.coupon_group_id = cg.id where pocg.promotion_option_id = 1;
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------+---------+----------+-------------+
| 1 | SIMPLE | pocg | NULL | ALL | NULL | NULL | NULL | NULL | 2715699 | 10.00 | Using where |
| 1 | SIMPLE | cg | NULL | eq_ref | PRIMARY | PRIMARY | 8 | promotion.pocg.coupon_group_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------+---------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
mysql> explain analyze select * from promotion_option_coupon_group pocg inner join coupon_group cg on pocg.coupon_group_id = cg.id where pocg.promotion_option_id = 1;
+-------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-------------------------------------------------------------------------------------------------------------------------------------+
| -> Nested loop inner join (cost=572211 rows=271570) (actual time=2.68..5959 rows=1 loops=1)
-> Filter: (pocg.promotion_option_id = 1) (cost=273484 rows=271570) (actual time=1.22..5958 rows=1 loops=1)
-> Table scan on pocg (cost=273484 rows=2.72e+6) (actual time=1.22..3757 rows=3e+6 loops=1)
-> Single-row index lookup on cg using PRIMARY (id=pocg.coupon_group_id) (cost=1 rows=1) (actual time=1.45..1.45 rows=1 loops=1)
|
+-------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (6.01 sec)쿼리를 분석해보면 다음과 같습니다.
promotion_option_coupon_group테이블을 풀 테이블 스캔을 한 후- promotion_option_id가 1인 컬럼을 필터링 합니다.
coupon_group테이블의 PK를 가지고 index lookup을 수행합니다.- 두 테이블 결과를 조인합니다.
전에 분석했던 쿼리와 다른 점은 coupon_group 테이블의 type 컬럼 값인데요. eq_ref 접근 방법을 사용하고 있습니다.
- eq_ref
- 조인에서 처음 읽은 테이블의 컬럼 값을, 그 다음에 읽어야 할 테이블의 PK나 UK 컬럼의 검색 조건에 사용할 때 사용하는 접근방법입니다.
- 이때 두 번째 이후에 읽는 테이블의 type 컬럼에 eq_ref가 표시됩니다.
promotion_option_coupon_group 테이블의 covering index를 두어 성능의 개선을 기대할 수 있을 것 같습니다. 현재 저희 프로젝트에서는 coupon_group_id를 가지고 쿼리를 수행하는 로직이 없고 WHERE절에 promotion_option_id를 가지고 쿼리를 수행하는 로직이 존재하기 때문에 다음과 같이 covering index를 두도록 합니다.
CREATE INDEX po_cg_idx ON promotion_option_coupon_group (promotion_option_id, coupon_group_id);이제 달라진 결과를 보도록 하겠습니다.
mysql> explain select * from promotion_option_coupon_group pocg inner join coupon_group cg on pocg.coupon_group_id = cg.id where pocg.promotion_option_id = 1;
+----+-------------+-------+------------+--------+---------------+-----------+---------+--------------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+-----------+---------+--------------------------------+------+----------+-------------+
| 1 | SIMPLE | pocg | NULL | ref | po_cg_idx | po_cg_idx | 8 | const | 1 | 100.00 | Using index |
| 1 | SIMPLE | cg | NULL | eq_ref | PRIMARY | PRIMARY | 8 | promotion.pocg.coupon_group_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+-----------+---------+--------------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
mysql> explain analyze select * from promotion_option_coupon_group pocg inner join coupon_group cg on pocg.coupon_group_id = cg.id where pocg.promotion_option_id = 1;
+--------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------------------------------------+
| -> Nested loop inner join (cost=2.2 rows=1) (actual time=0.0946..0.109 rows=1 loops=1)
-> Covering index lookup on pocg using po_cg_idx (promotion_option_id=1) (cost=1.1 rows=1) (actual time=0.0412..0.0493 rows=1 loops=1)
-> Single-row index lookup on cg using PRIMARY (id=pocg.coupon_group_id) (cost=1.1 rows=1) (actual time=0.036..0.0376 rows=1 loops=1)
|
+--------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.02 sec)promotion_option_coupon_group 테이블의 covering index lookup을 통해 promotion_option_id 가 1인 값을 탐색하고 coupon_group 테이블의 PK index lookup을 통해 id가 1인 값을 탐색합니다.
결과적으로 처음 6초 정도 걸리는 쿼리를 0.02초로 개선할 수 있었습니다.
select * from coupon c left join coupon_group cg on c.coupon_group_id = cg.id where cg.id = 1;
mysql> explain select * from coupon c left join coupon_group cg on c.coupon_group_id = cg.id where cg.id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
| 1 | SIMPLE | cg | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | c | NULL | ALL | NULL | NULL | NULL | NULL | 9556578 | 10.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
mysql> explain analyze select * from coupon c left join coupon_group cg on c.coupon_group_id = cg.id where cg.id = 1;
+--------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------------------+
| -> Filter: (c.coupon_group_id = 1) (cost=995629 rows=955658) (actual time=1.96..21308 rows=4 loops=1)
-> Table scan on c (cost=995629 rows=9.56e+6) (actual time=1.96..13914 rows=10e+6 loops=1)
|
+--------------------------------------------------------------------------------------------------------------------------+
1 row in set (21.34 sec)쿼리를 분석해보면 coupon 테이블에 대해 풀 테이블 스캔을 수행한 후 coupon_group_id가 1인 값을 필터링하는 것을 확인할 수 있습니다.
coupon 테이블의 coupon_group_id 컬럼에 인덱스를 적용하면 성능의 개선을 기대할 수 있을 것 같습니다.
CREATE INDEX coupon_group_idx ON coupon (coupon_group_id);이제 결과를 확인해 보겠습니다.
mysql> explain select * from coupon c left join coupon_group cg on c.coupon_group_id = cg.id where cg.id = 1;
+----+-------------+-------+------------+-------+------------------+------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+------------------+------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | cg | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | c | NULL | ref | coupon_group_idx | coupon_group_idx | 8 | const | 4 | 100.00 | NULL |
+----+-------------+-------+------------+-------+------------------+------------------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.04 sec)
mysql> explain analyze select * from coupon c left join coupon_group cg on c.coupon_group_id = cg.id where cg.id = 1;
+------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------------------+
| -> Index lookup on c using coupon_group_idx (coupon_group_id=1) (cost=4.29 rows=4) (actual time=6.19..6.19 rows=4 loops=1)
|
+------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.04 sec)coupon 테이블에서 index lookup을 통해 조건에 해당하는 결과를 찾아 결과를 반환하는 것을 확인할 수 있습니다. 결과적으로 21초 정도 걸리는 쿼리를 0.04초로 개선할 수 있었습니다.
select * from coupon where coupon_group_id = 1;
해당 쿼리는 바로 전 단계에서 coupon 테이블의 coupon_group_id에 인덱스를 적용함으로써 해결할 수 있었습니다.
결론
AWS의 CloudWatch를 통해 슬로우 쿼리를 분석 및 개선하는 과정을 거쳤습니다.
개선 작업을 수행하기 전 백만 건 이상의 데이터가 있을 때 생각보다 시간이 오래 걸리는 것에 놀랐는데, 개선을 통해 이렇게 까지 시간이 줄어드는 것에 또 놀라게 되었네요.
이상입니다!
잘봤습니당 :)