
도커
선수 지식
하이퍼바이저
물리적인 리소스를 분리하여 가상 환경을 만들어 내는 기술이다. 하나의 물리적인 하드웨어에 VM(virtual machine) 을 여러개 생성하여 다양한 운영체제를 사용할 수 있게 된다.
하이퍼바이저는 노트북 등의 운영 체제에 배포하거나, 서버 등의 하드웨어에 직접 설치한다.
결과적으로는 하이퍼바이저위에 새로운 OS가 각 환경별로 설치가 되고 그 위에 애플리케이션이 동작하는 그림으로 볼 수 있다.
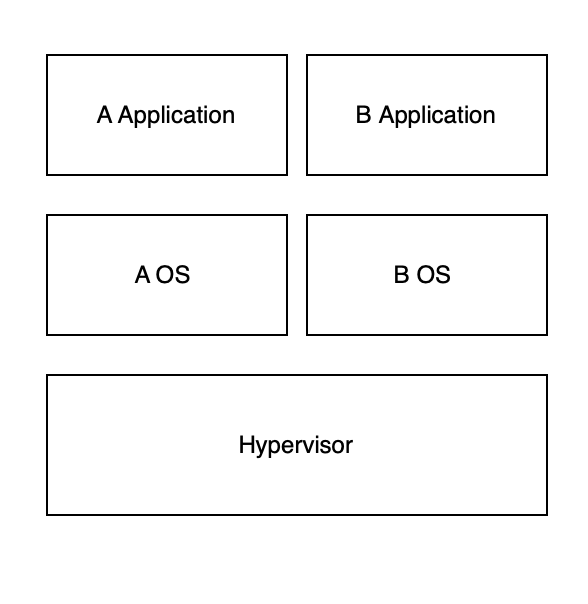
ex) mac 에서 페러럴즈를 통해서 윈도우를 사용하는것, 학생때 윈도우 pc에서 VM을 생성해서 리눅스 서버를 설치하고 수행하는것
컨테이너
컨테이너는 가상환경을 사용해 각 마이크로서비스를 격리 하는 기술 이다.
어플리케이션 코드가 해당 라이브러리 및 종속 항목과 패키징 되어 하나의 격리 구조를 만들어 낸다
해당하는 컨테이너는 OS위에서 독립적으로 실행 될 수 있게 된다
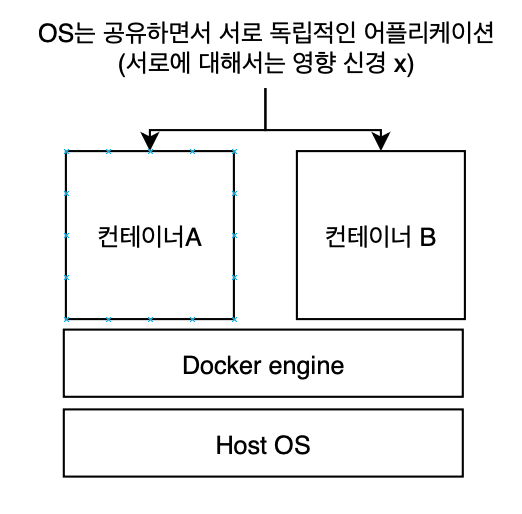
하이퍼바이저는 불필요한 레이어가 많아서 오버헤드가 발생할 가능서이 높다.
컨테이너 방식은 OS/하이퍼파이저를 각각 설치할필요가 없기 때문에 사용성이 좋다.
장점
- 디렉토리, IP 주소등과 같은 시스템 자원을 마치 각 어플리케이션이 점유하고 있는 것 처럼 보인다.
- 컨테이너들 끼리는 독립적이다.(각각이 별도의 운영환경 가진다)
- 운영 체재 하나를 공유해서 사용하기 때문에 업데이트 패치 작업도 한번만 수행
도커
컨테이너 기술은 리눅스 네임 스페이스로 오래전부터 존재해왔던 기술이다. 하지만 도커로 인해서 이러한 컨테이너 기술을 사용자들이 쉽고 간편하게 사용가능해졌고 현재로서는 컨테이너 기술의 표준으로 볼 수 있다.
다야한 운영체제에서 사용이 가능하며(리눅스, 윈도우, Mac OS), 애플리케이션에 국한되지 않고 의존성 및 파일 시스템까지 패키징하여 빌드, 배포, 실행을 단순화 했다.
도커의 간단한 명령어
도커를 설치하여 실행하고 난뒤에는 아래와 같은 명령어를 콩해서
도커를 활용할 수 있다.
- docker pull consol/tomcat-7.0:latest
- 이미지 다운 - docker images
- 설치된 이미지들 확인 가능 - docker run -d -p 80:8080 --name tc consol/tomcat-7.0:latest
- 80으로 들어오면 내부 애플리케이션의 8080으로 보내준다
- name을 통해서 뒤에 구동중인 컨테이너의 이름을 지정할 수 있다.- e 옵션을 주면 환경변수를 줄 수 있다.
- docker ps -a
- 실행중인 컨테이너를 확인하고 a 옵션을주면 중지된것까지 확인 가능하다 - docker stop tc
- 특정 컨테이너를 중지할때 사용한다 - docker rm tc
- 특정 컨테이너를 삭제할때 - docker logs tc
- 컨테이너의 로그 확인
- /var/lib/docker/containers/<컨테이너ID>/<컨테이너ID>-log.json 위치에 로그파일은 저장 되어있다.- 해당 프로세스의 stdout,stderr을 저장한 내용
컨테이너 저장 공간
컨테이너에 저장한 데이터는 컨테이너 종료시에 삭제가 되기 때문에 별도의 볼륨을 구성하거나 호스트의 파일시스템을 공유하게 할 수 있다.
docker run 명령을 사용할때 아래와 같은 옵션을 통해서 저장공간을 마운트하여 사용 할 수 있다.
docker run -v <호스트 경로>:<컨테이너 내 경로>:<권한>
ex) sudo docker run -d -p 80:80 -v /var/www:/usr/nginx:ro nginx 위와 같은 방법을 사용하면 컨테이너에서 저장되는 해당 공간에 파일이 저장되면 호스트의 경로에서도 해당 파일을 확인할 수 있다. (반대의 경우도 마찬가지)
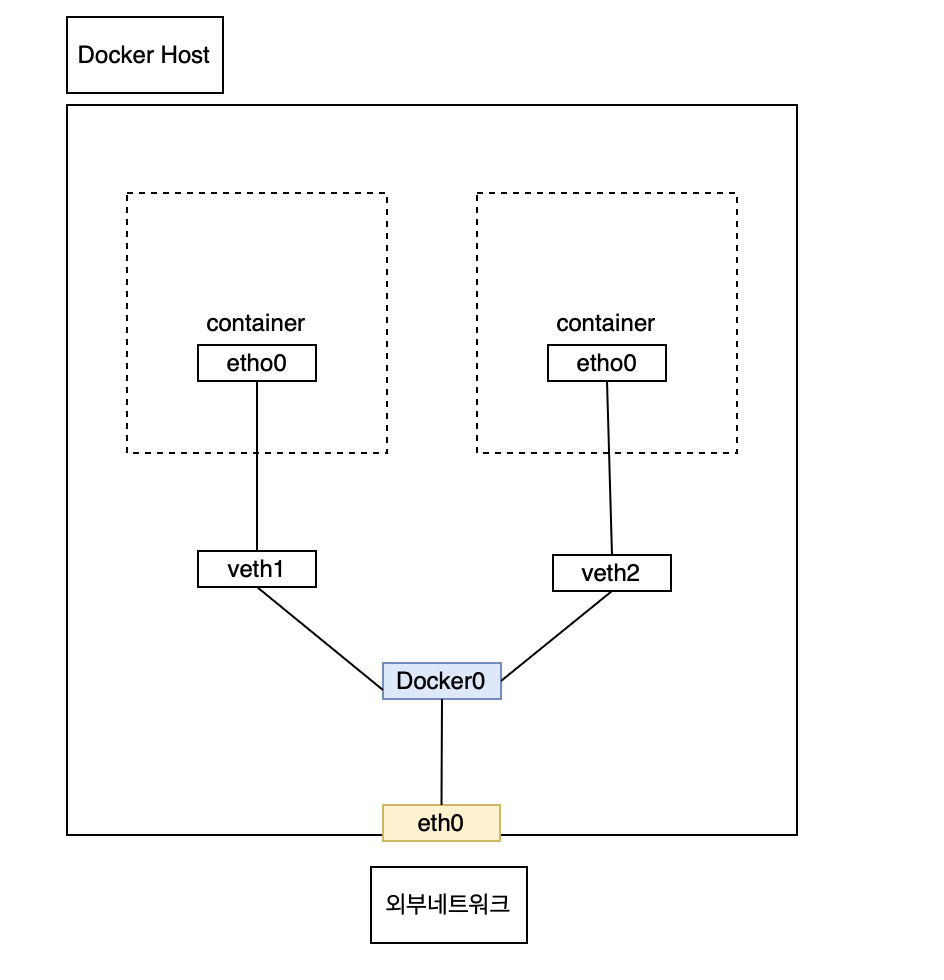
도커의 네트워크 환경
컨테이너가 서로 통신하고 외부 네트워크와 통신할 수 있도록 도커는 기본 적으로 브릿지 네트워크를 제공한다.
브릿지 네트워크 : 동일한 호스트의 컨테이너가 서로 통신 할 수 있도록하며, 가상 브릿지를 사용하여 컨테이너를 호스트 네트워크에 연결
특정한 네트워크 드라이버 설정 없이 도커를 생성하면 디폴트로 Docker0라는 Virtual interface가 생성된다.
Docker0는 Container의 veth인터페이스와 바인딩되며 호스트의 eth0 인터페이스와 이어주는 역할을 한다.
docker network ls 명령어를 통해 현재 docker의 network정보를 확인해볼 수 있다.
쿠버네티스
몇개의 호스트 컨테이너의 경우 관리가 쉽지만
수백 수천개의 호스트와 컨테이너를 유지하는것은 쉽지 않다
그러한 관리를 더 편하게 해주기 위해서 컨테이너 오케이스트레이션 도구가 나오게 되었고, 그 도구중에서 가장 대중적으로 사용되는게 쿠버네티스 이다.
컨테이너 오케스트레이션은 가용성, 복원력등 성능을 극대화 하기 위해서
클러스터 안에있는 모든 노드들의 상태를 알고 제어 할 수 있다.
클러스터 : 하나의 시스템으로 함께 작동하는 여러개의 서버나 인스턴스의 집합
(즉 하나의 목적을 가지는 서버들의 집합을 의미한다)
노드 : 클러스터 내 가상서버
호스트 : 네트워크에 연결되어있는 컴퓨터
제공기능
- 클러스터에 있는 모든 컨테이너 관리
- 컨테이너의 예약 및 배치
- 비정상 컨테이너 제거 후 새 컨테이너 생성
- 컨테이너를 어떤 호스트에 배치해야하는지 관리
- 로드밸런싱 기능 제공
쿠버네티스와 도커가 통신하는것이 아니라 ContainerD를 통해서 쿠버네티스는 컨테이너들을 관리한다
쿠버네티스 구조
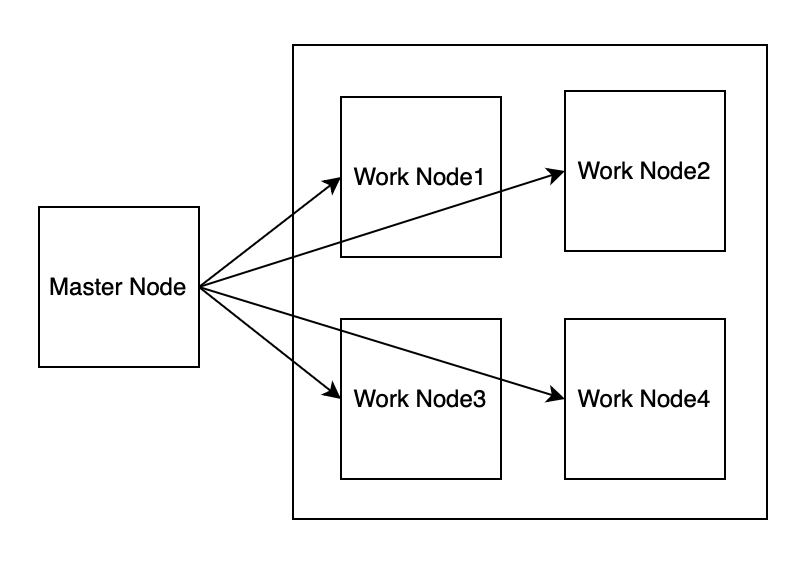
쿠버네티스의 클러스터는 많은 노드들로 구성이되며 크게 두 가지 유형으로 나뉜다.
마스터 노드 (컨트롤 플레인)
- 전체 쿠버네티스 시스템을 관리하고 통제한다
- 내가 어떠한 요청을 한다면 마스터 노드를 통해서 수행이 진행된다.
- ex) a 기능 pod 2개 배포, b 기능 pod 1개 배포
워커 노드
실제 배포하고자 하는 애플리케이션의 실행을 담당
명령 흐름 예시
deployment.yaml 를 통해서 요청 전달
-> 마스터 노드가 해당 명령을 받는다
-> kubelet에게 해당 명령 전달 (kubelet이 데몬 서비스)
-> kubelet이 containderD와 통신한다
-> caoniainderD를 통해서 pod에 명령
EKS를 활용한 쿠버네티스 사용
AWS에서 제공하는 쿠버네티스 클러스터를 쉽게 배포, 확장, 관리할 수 있는 완전관리형 서비스이다.
EKS를 사용하게 된다면 아래와 같은 장점이 있다.
- 컨트롤 플레인의 가용성과 확장성을 자동으로 관리를 해준다.
- 컨트롤 플레인에 대한 자동 업데이트 및 패치를 제공하여 클러스터를 안전하고 최신상태로 유지하기가 쉽다.
- 워커 노드를 쉽게 확장하는 것도 가능하다.
쿠버네티스 명령 흐름
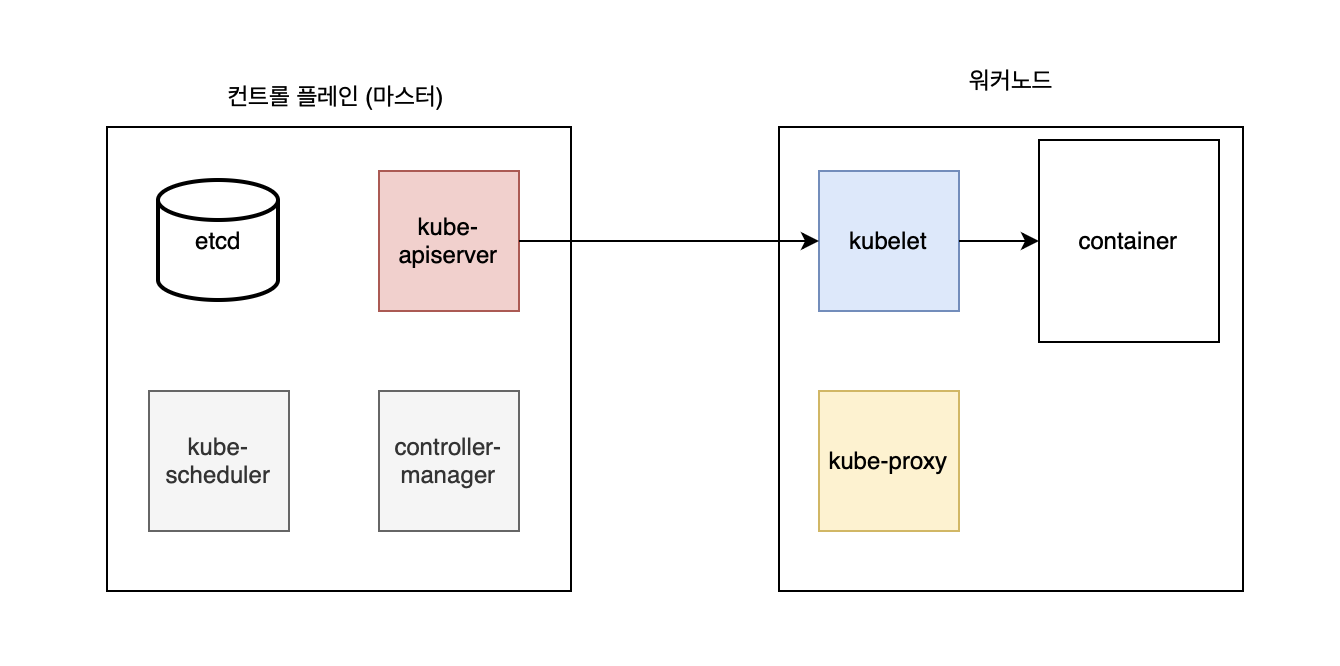
쿠버네티스를 관리할때는 kubectl이라는 명령어를 사용한다.
쿠버네티스는 마스터 노드에 있는 kube-apiserver에서 중앙 집중적으로 이러한 명령어를 처리해준다.
명령어 요청 -> kube api server -> 해당 노드의 kubelet으로 명령 전달
그리고 kubelet이 컨테이너를 직접 컨트롤 하게 된다.
요약
- kube-api-server : 대장
- contorller-manger: 실제 실무 처리하는 매니져
- kube-scheduler : 스케줄링 처리 ex 컨테이너 파드 어디에 다가 배치 할지등
- etcd : api server만 접근 간능한 각종 정보 들어있는 db 역할
- kube-proxy : 통신병
- kubelet : 노드에서 api server와 통신을 하면서 컨테이너 컨트롤한다.
쿠버네티스 오브젝트
오브젝트는 쿠버네티스 시스템에서 영속성을 가지면서 클러스터의 상태를 나타내기 위하여 이용된다. 이를 통하여 클러스터의 워크로드를 어떤 형태로 보이고자 하는지에 대해 효과적으로 쿠버네티스에 전달 할 수 있다.
쿠버네티스 오브젝트 yaml 작성은 공식 홈페이지를 참고해서 작성하면 된다. https://kubernetes.io
- 어떤 컨테이너화된 어플리케이션이 어느 노드에서 동작 중인지
- 그 어플리케이션이 어떤 리로스를 이용할 수 있는지
- 그 어플리케이션의 재구동 정책, 업그레이드등에 대한 정보
Pod
쿠버네티스에서 생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨팅 단위로 하나이상의 컨테이너로 구성되어 있다
- pod 내에 구성된 컨테이너는 스토리지를 공유
- pod 내에 구성된 컨테이너는 localhost를 통해서서로 접근 가능
- 일반적으로 파드는 단일 컨테이터만 포함하지만 다수의 컨테이너를 포함 할 수 있음 (파드안에 컨테이너가 들어간다)
- 파드의 컨테이너들은 동일한 host를 가진다 - 파드는 다수의 노드에 생성되지 않도 단일 노드에서만 실행된다(한개의 파드는 하나의 노드에 속해있다)
apiVersion: v1 # 쿠버네티스 api를 의미한다 (형식:그룹/버전)
kind: Pod # 리소스의 종류 (어떤걸 쿠버네티스에 배포하고 싶은지)
metadata: # 일반 정보(이름, 주석, 레이블 등) 실행과 직접적인 관련은 없다
name: nginx
spec: # 실행정보(컨테이너 이름, 이미지, 포트 볼륨 등등)
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# 이런식으로 작성된것 이외에 클러스터가 status라는것도 알아서 작성을 해준다 쿠버네티스 명령어를 통해서 생성하는 방법은
kubectl apply -f xxx.yaml
혹은 create를 사용해도 괜찮다 Service
파드는 영구적이지 않다. 생성이후 사라지고 생성되는게 가변적이기 때문에 IP 주소가 계속해서 변하게된다. 이러한 상황에서 외부에서 해당 파드로의 접근을 일관적으로 처리하기 위해서 서비스라는 리소스가 존재한다.
- 대상으로 하는 파드 집합은 셀렉터를 통해서 선언
- 해당 파드들을 지속적으로 검색하고 업데이트 한다
- 로드 밸런싱과 비슷 한 역할을 해준다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376Service 의 종류 및 특징
- ClusterIP
- Service 리소스의 기본 타입
- 자체 IP와 포트 번호를 가진 객체
- 클러스터 내부용 - NodePort
- ClusterIP의 모든 기능을 가지고 있음
- 노드에 포트를 오픈한다 (30000~32767 포트, 외부로 서비스 가능)- 노드에 eip가 설정 안되있다면 접근 안된다
- LoadBalancer
- NodePort의 기능을 모두 가지고 있다
- 외부에 로드밸런서를 배포하고 연결하는 역할을 수행
- 기존의 L4 와 같은 역할을 대체 할 수 있다
기능의 크기 : clusterIP < Nodeport < LoadBalancer
서비스는 어디에 위치하는가?
- 운영체제의 기능에 의해서 가상화 되어있다. (추상적 개념)
ps. 서비스를 만들때 특정 파드로 호출이 지속적으로 전달 되게 할 수 있다 (sessionAffinity 기능 사용, not 영구적 최대 3시간)
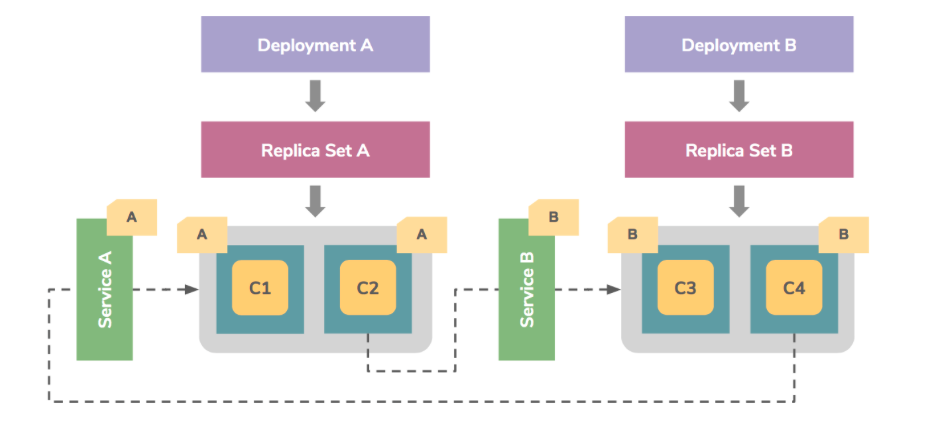
Deployment
Pod와 ReplicaSet에 대한 선언적 업데이트를 제공 한다.
Pod 메니페스트를 통해서 애플리케이션을 배포할 수 있지만 Deployment를 통해서 ReplicaSet등을 설정하면서 한번에 Pod를 배포할 수 있다.
기본적인 배포방법으로 사용되며, ReplicaSet을 관리하면서 앱의 배포를 세밀하게 관리 할 수 있다
- 실행시켜야 하는 Pod 개수 유지
- 롤링 업데이트
- 배포 도중 멈췄다 배포 가능
- 배포 후 이전버전으로 롤백 가능
Replicaset : 파드의 개수를 유지하는 역할을 한다. 즉 Deployment는 Replicaset을 만드는것이고 이 Replicaset이 Pod를 관리한다
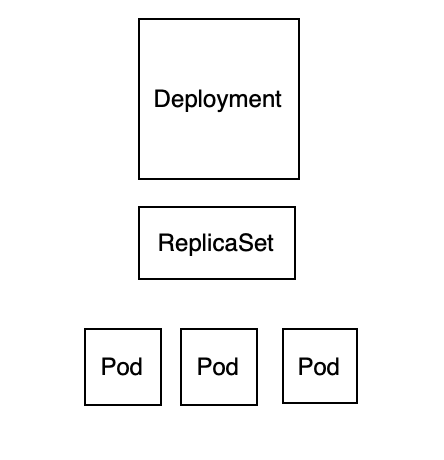
Deployment는 배포관리자로 업데이트를 관리한다. 즉 업데이트를 한다면 새로운 Replicaset으르 만들면서 새롭게 파드를 만든다.
기존의 Replicaset는 바로 사라지지 않으며 남아있는다 대신 관리하는 pod를 0으로 만들어서 유지가 된다. (기본 설정으로는 replicaset은 10개가 유지된다)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
annotations:
kubernetes.io/change-cause: "image updaet" #변경사유 기록가능
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80파드를 업데이트 하는 방법.
- Recreate : 파드를 일괄 삭제하고 다시 생성, 잠깐의 다운 타임 발생
- Rollingupdate: 파드를 추가 배포하고 준비되면 오래된 파드를 삭제하는 방식(Default)
배포했는데 업데이트를 실패하는 경우
- 부족한 할당량
- Readiness probe 실패
- 이미지 가져오기 실패 오류
- 권한 부족
- 응용 프로그램 런타임 구성 오류
--> 업데이트를 실패하는 경우 기본적으로 600초 후 업데이트 중지
롤링 업데이트 : Pod 인스턴스를 점진적으로 새로운 것으로 업데이트 하여 서비스 중단 없이 업데이트가 이루어질 수 있도록 해준다.
ReplicaSet : Pod를 정해진 수만큼 복제하고 관리하는 것 (참고로 이때 pod를 관리하는 거는 레이블을 보고서 선택한다. 실행 파드 레이블 바꾸면 다른 파드를 새로만듬)
레이블 : 모든 리소스를 구성하는 매우 간단한 쿠버네티스 기능으로 임의의 키/값 쌍으로 이루어 진다.
ConfigMap
configMap은 데이터를 key-value 형태로 저장하는 API 오브젝트로
pod와 같은 다른 쿠버네티스 오브젝트가 해당 값을 사용할 수 있다.
환경변수, 명령줄 인수, 볼륨의 구성파일등
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# 속성과 비슷한 키; 각 키는 간단한 값으로 매핑됨
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
Secrets
configMap은 기밀데이터 이외의 데이터만 저장한다. Secrets는 암호, 토큰과 같은 기밀 정보를 포함하는 오브젝트이다.
apiVersion: v1
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: { ... }
creationTimestamp: 2020-01-22T18:41:56Z
name: mysecret
namespace: default
resourceVersion: "164619"
uid: cfee02d6-c137-11e5-8d73-42010af00002
type: OpaqueNamespace
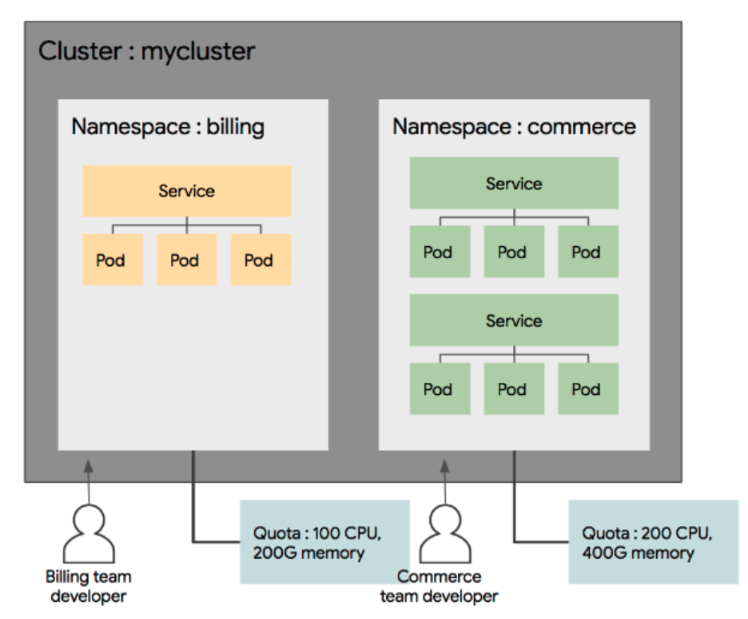
단일 클러스터 내에서의 리소스 그룹 격리를 제공한다.
즉 동일한 물러적 클러스터가 지원하는 가상 클러스터들을 생성할 수 있다.
서로다른 네임스페이스에 위치
(작업공간을 나누는 역할을 한다고 보면된다)
kubectl get po --namespace ns #이런식으로 특정 네임스페이스 확인가능 -n으로도 사용 가능 - 여러팀이나 프로젝트에서 동일한 클러스터를 사용하는 경우에 유용하다
- pod가 어떤 노드에서 실행되는지에 영향을 주지는 않는다
메니페스트파일 팁
apiVersion: v1
kind: Pod
metadata:
name: http-go
labels:
creation: manual
env: prod
spec:
containers:
- image: http-go
name: http-go
prot:
- continerPort:8080
protocol: TC위의 labels 와같이 s가 붙는거 뒤에는 보통은 리스트 형태로 따라온다
즉 여러개의 값이 들어갈 수 있다
containers에서 '-'가 사용되었는데 이거 - 가 하나의 구조체라고 볼 수 있다 다름 - 가 나오기 전까지
추가로 라벨을 조회하고 싶을때는 아래와 같은 명령어를 사용할 수 있다.
kubectl get pod --show-labels # 전체 조회
kubectl get pod -L env #env라는 특정 라벨 조회 (소문자 l하면 필요한것선택한것만) Yaml 파일에 --- 를 하면 하나의 파일에 여러개의 내용으로 나눠서 사용할 수 있다.
...
kind: Namespace
...
---
...
Kind: Pod
...쿠버네티스 Health Check 방법
Liveness Probe
- 컨테이너가 살아있는지 판단하고 다시 시작하는 기능.(즉 문제가 있으면 재시작을 해준다는 뜻)
- 컨테이너의 상태를 스스로 판단하여 교착상태에 빠진 컨테이너를 재시작
- 버그가 생겨도 높은 가용성을 보인다.
Readiness Probe
- 파드가 준비된 상태에 있는지 확인하고 정상 서비스를 시작하는 기능 (위와 비슷해보이지만 응답이 없을때 재시작을 하는게 아니라 서비스와 파드사이의 연결을 끊어내면서 해당 파드로 요청이 안가게 해주는것)
- 파드가 적절하게 준비되지 않은 경우 로드밸런싱을 하지 않는다.
Startup Probe
- 애플리케이션의 시작시기를 확인하여 가용성을 높이는 기능
- Liveness와 Readiness의 기능을 비활성화(초기에 구동시점에는 당연히 health check가 안되기때문이 특정시간동안은 유예를 해주는것) 텍스트
쿠버네티스 스케줄링
쿠버네티스 스케줄러를 활용하여 Pod를 스케줄링 할 수 있다.
스케줄러는 필터를 사용하여 Pod 배치에 사용 불가능한 노드를 제외한 다음 점수 시스템을 기반으로 최종 노드를 결정 한다.
조건자 : 어떤 노드가 사용 불가능한지 결정
- 볼륨
- 리소스
- 토풀로지
토플로지(제약조건)
Taint : Pod의 배치를 막는 속성으로, Taint된 노드는 그 taint를 허용하는 Pod만 수락한다
Tolerations : Pod가 Taint된 노드에서 실행될 수 있도록 지정해주는 Pod의 속성
Affinity : Pod가 특정 노드나 인스턴스 유형에서 실행되게 하기 위해 선호도를 설정할 수 있다
DaemonSet : 모든 노드가 요청된 Pod의 복사본을 갖도록 해준다 (예: 보안,로깅등에서 활용)
우선순위 : 필터링되지 않은 각 노드의 점수를 계산하고 가장 점수가 높은 노드에 Pod를 배치 한다
쿠버네티스 구조
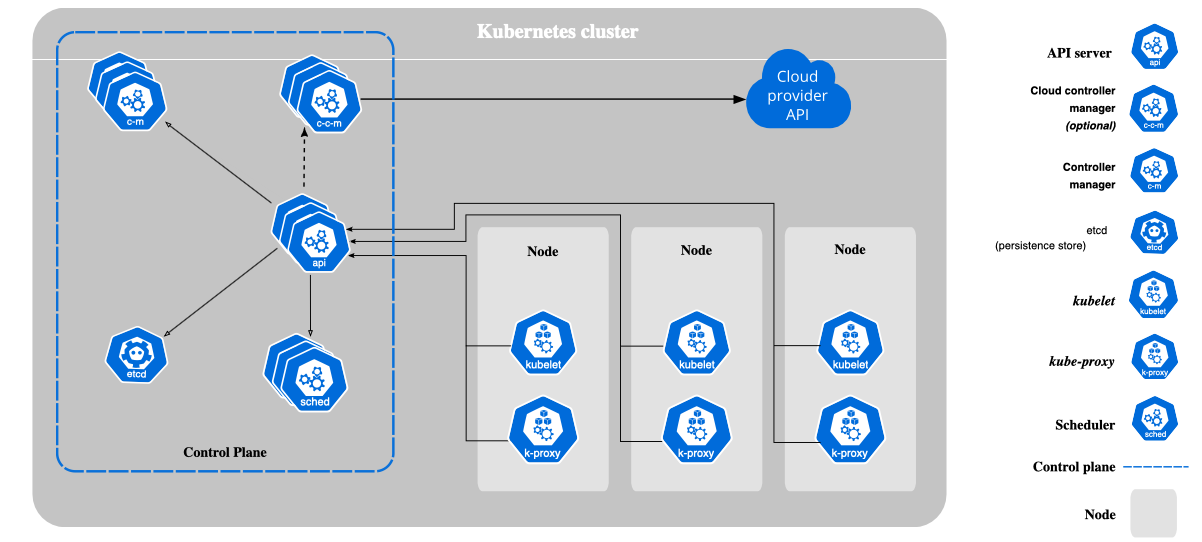
쿠버네티스에서 실행되는 노드는 컨트롤 플레인과 노드 컴포넌트로 구성된다.
컨트롤 플레인
클러스터의 주 제어점으로, 클러스터의 이벤트를 감지하고 이에 대응 하는 컨트롤러(Deployment,Daemonset등) 관리 하며
클러스터에 관한 전반적인 결정(스케줄링 등)을 수행한다.
- kube-apiserver : 쿠버네티스 API 노출
- kube-scheduler : 새로 생성된 pod 실행 노드 선택
- kube-controller-manager : 제어루프를 실행하여 클러스터 상태 감시
- etcd : 중요한 클러스터 데이터와 상태가 저장된다.
제어루프 : 현재 상태가 컨트롤러에(deployment, daemonset등) 정의된 상태와 같아지도록 해주는것
노드 컴포넌트
동작중인 Pod를 유지시키고 쿠버네티스 런타임 환경을 제공하며
모든 노드 상에서 동작한다.
- kubelet : Pod에서 컨테이너가 확실하게 동작하게 관리,
컨트롤 플레인과 API를 통해서 통신한다 - kube-proxy : 각 노드에서 실행되는 네트워크 프록시, 서비스 개념의 구현부로 노드의
네트워크 규칙을 관리한다 - 컨테이너 런타임 : 컨테이너
실행을 담당하는 소프트웨어
