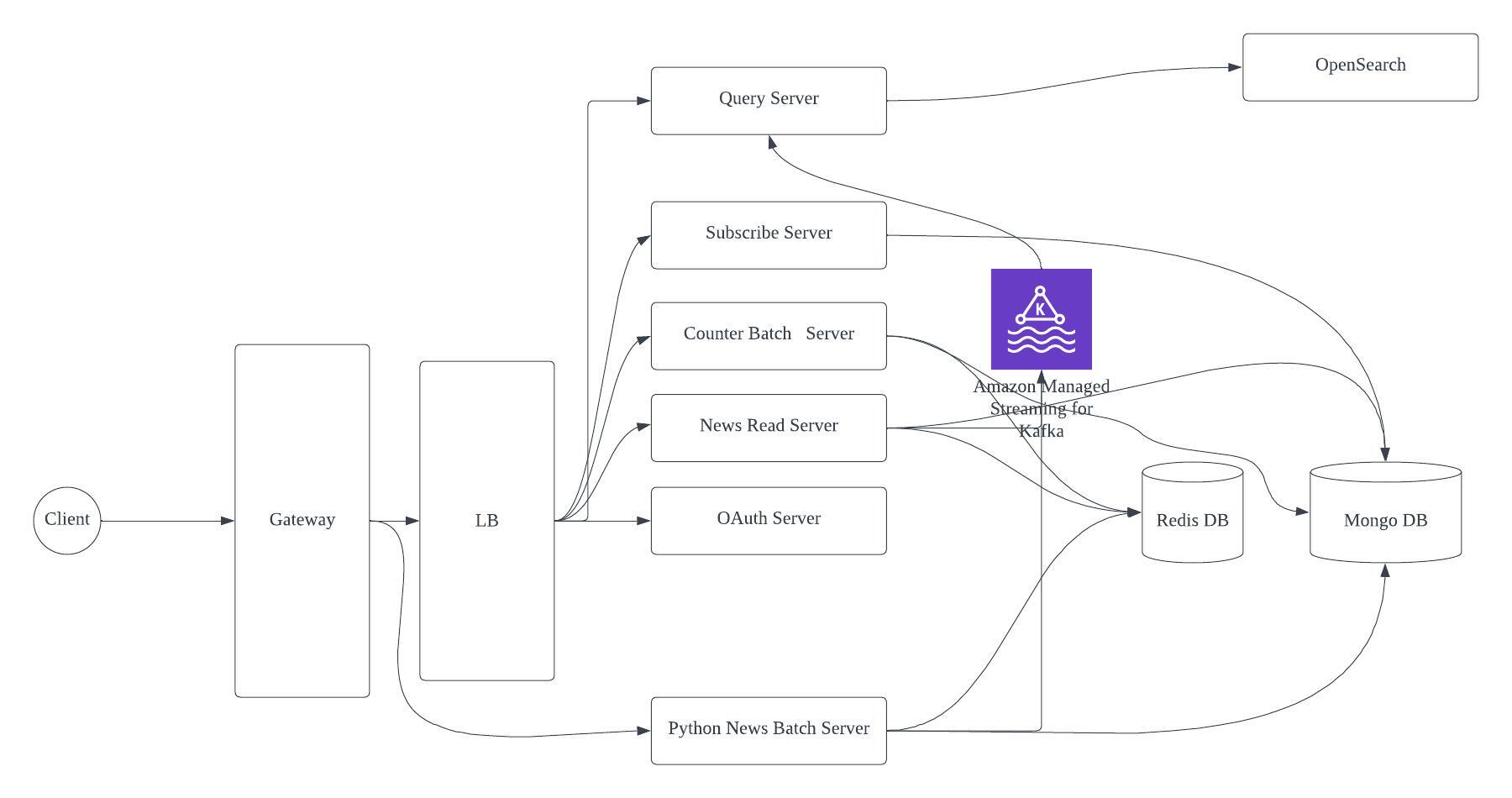
토이 프로젝트를 진행하며 로깅 파이프 라인을 짜는 파트를 맞게 되었습니다. 이번 프로젝트는 MSA로 개발하기로 하였고 분산화된 시스템에서 로그 분석 및 시각화를 위해선 중앙화된 로깅 시스템이 필요했습니다.
logstash 서버에서 많은 트래픽이 있을 떄 유실 없이 로그를 잘 수집할 수 있을까? 더 결함 없이 만들 수 있을까? 하는 생각에 실험을 해보게 되었습니다.
실험 환경
kafka server --> aws EC2 t3.small
Spring server --> Local
Logstash server from spring --> EC2 t3.medium
Logstash server from kafka --> EC2 t3.medium
1만건에서 비교
spring -> logstash -> opensearch
@Test
void insertBulkLog_1만() {
List<String> list = new ArrayList<>();
Integer _1만 = 1 * 10000;
for (Integer i = 0; i < _1만; i++) {
list.add("log-test" + i);
}
list.stream().parallel().forEach(Logstash::pushLog);
}
GET spring/_count

- 기대와는 다르게 데이터의 유실이 있다.
spring -> kafka -> logstash -> opensearch
@Test
void insertBulkLog_1만() {
List<String> list = new ArrayList<>();
Integer _1만 = 1 * 10000;
for (Integer i = 0; i < _1만; i++) {
list.add("log-test" + i);
}
list.stream().parallel().forEach(x -> kafkaStringTemplate.send(TOPIC_NAME, x));
}
GET kafka/_count

- 데이터의 유실 없이 1만건이 들어와 있다.
100만건에서 비교
spring -> logstash -> opensearch
@Test
void insertBulkLog_100만() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<String> list = new ArrayList<>();
Integer _100만 = 100 * 10000;
for (Integer i = 0; i < _100만; i++) {
list.add("log-test" + i);
}
list.stream().parallel().forEach(Logstash::pushLog);
stopWatch.stop();
long totalTimeMillis = stopWatch.getTotalTimeMillis();
System.out.println("100만 로그에 걸린 시간: " + totalTimeMillis + "ms");
}
GET spring/_count

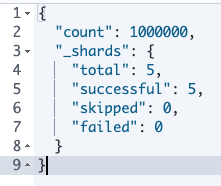
음... 이상하다... 100만건을 넣었는데 만 8천 건 정도밖에 없다...
동시 요청에 처리할 수 있는 한계가 있는건가 해서 연속으로 10만건씩 순차적으로 몇번 넣어 봤는데 각각 1x000건 씩만 처리가 되었다. 그리고 생각과 다르게 parallel()로 로그를 보내는게 순차적으로 보내는 것보다 느렸다.
그러면 이제 메시지 큐 서버를 통해 처리하면 100만건의 동시 로깅을 잘 처리하나 확인해 보겠습니다.
spring -> kafka -> logstash -> opensearch
@Test
void insertBulkLog_100만() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<String> list = new ArrayList<>();
Integer _100만 = 100 * 10000;
for (Integer i = 0; i < _100만; i++) {
list.add("log-test" + i);
}
list.stream().parallel().forEach(x -> kafkaStringTemplate.send(TOPIC_NAME, x));
stopWatch.stop();
long totalTimeMillis = stopWatch.getTotalTimeMillis();
System.out.println("100만 로그에 걸린 시간: " + totalTimeMillis + "ms");
}
parallel()을 빼고 동기적으로 했을 떄 걸린 시간

100만개가 유실없이 들어갔다. 몇번을 시도 해도 같은 결과이다.
결론
백엔드 서버에서 바로 로그 수집 서버로 로그를 보내면 로그 수집 서버의 처리량의 한계로 데이터 유실이 있을 수 있다. 물론 로그 수집 서버를 스케일링하여 처리 가능량을 늘릴 수 있다.
벡엔드와 로그 수집서버 사이에 메시지 큐를 넣음으로써 메시지 유실 없이 로그를 처리할 수 있었다. 물론 로그 수집 사버의 처리량이 늘어난게 아니라 메시지 큐 서버에서 로그를 가지고 있다가 전달해 주기 때문이다.
Kafka와 ELK 조합의 장점
- 트래픽이 많을 때 로그 유실을 줄일 수 있다.
단점
- kafka서버를 따로 관리해줘야 한다는 단점이 있다.
Reference

와.. 빵승 네트워크님, 수고많으셨습니다!
역시 킹승재;