안녕하세요. 이번 시간엔 DB 인덱싱에 대하여 포스팅 해보도록 하겠습니다!
인덱스(Index)란?
인덱스(Index)는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다. (왜냐하면 보통 인덱스는 키-필드만 갖고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문이다.) 관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본이다.
인덱스는 고유 제약 조건을 실현하기 위해서도 사용된다. 고유 인덱스는 중복된 항목이 등록되는 것을 금지하기 때문에 인덱스의 대상인 테이블에서 고유성이 보장된다.
출처) 위키백과
위의 내용을 정리하자면
- 테이블에 대한 검색의 속도를 높여주는 자료 구조입니다.
- 색인이고 메모리 영역의 일종의 목차를 생성하는 개념입니다.
- 따라서 이런 목차를 이용하여 검색 범위를 줄여 속도를 높일 수 있습니다.
인덱스의 종류
다음과 같이 정리할 수 있습니다!
- B(Balanced)-tree Index
- Bitmap Index
- IOT Index
- Clustered Index
위와 같이 존재하며 주로 B-tree 구조로 사용된다고 합니다!
왜 사용해야하나?
위에서 말씀드렸듯이 검색의 속도를 높여주기 때문입니다. 근데 어떻게 검색의 속도를 높여주는것이며 어떻게 사용되는지 감이 안잡히기 때문에 이 내용에 대하여 설명해보겠습니다!
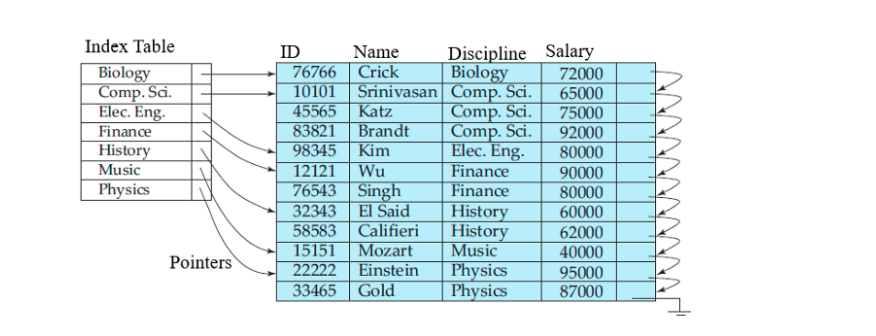
예를 들어 오른쪽 테이블의 Physics값을 조회해본다고 가정해보겠습니다.
해당 과정을 표현하면
- Select 절을 활용하여 조회
- 어느 위치에 데이터가 존재하는지 모르기 때문에 Table Full scan 진행
이처럼 테이블의 전체 데이터를 조회하기 때문에 데이터의 수가 적은 테이블이면 영향이 덜하겠지만,
만약 수십만개의 데이터가 들어있는 테이블의 데이터를 조회하는데 조회 기능이 자주 사용되는 서비스라면 성능이 굉장히 떨어지게 될것입니다!
그렇기 때문에 왼쪽과 같이 인덱스를 따로 생성하여 해당 데이터만 빠르게 찾을 수 있게 됨으로써 다이나믹한 성능 향상을 기대할 수 있는 부분입니다!
어떻게 동작하는것인가?
위의 예시를 이어서 설명하겠습니다!
- 해당 테이블을 생성시 생성하고 싶은 인덱스 컬럼을 지정
- 생성 후 인덱스 조회 시, WHERE 절이 포함된 쿼리로 조회
- 인덱스로 저장된 Key-Value값을 참조해서 결과 출력
위와 같이 진행되게 됩니다!
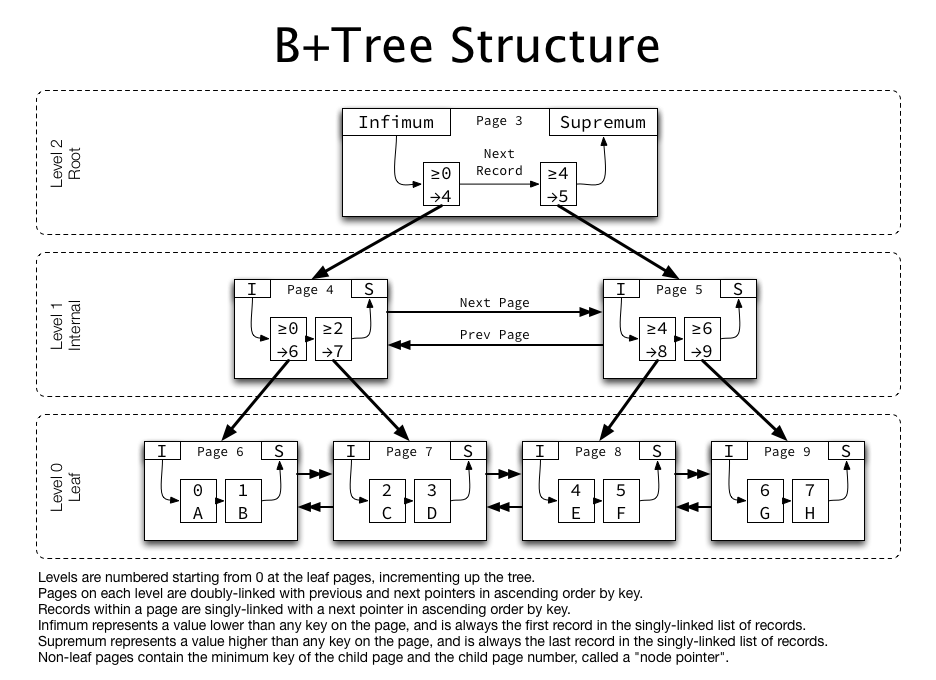
다음과 같이 B-tree 알고리즘을 통하여 조회하게 되고, 리프노드로 도착하기 까지 자식 노드에 대한 포인터가 저장되어 있어 탐색에 있어서 한개의 경로만 조회하면 되기 때문에 조회에 있어서 굉장히 효율적인 알고리즘이라고 합니다!
언제 사용해야하나?
주로 검색 및 조회를 할때 큰 효율성을 낼 수 있다고 합니다!
기본적으로 이진 트리를 사용하기 때문에 이미 정렬이 되어있는 상태에서 추가, 수정, 삭제가 자주 일어나게 되면 인덱스에서도 마찬가지로 해당 동작들이 수행되기 때문에 성능 저하를 초래할 수 있다고 합니다!
예를 들어, 한 쇼핑몰에 여러가지 카테고리가 존재할때 해당 카테고리의 상품들을 조회할때 이러한 인덱스 기능을 잘 사용하게 된다면 큰 효율을 발휘하게 되지만, 인스타그램같은 소셜 서비스들은 끊임없이 게시글이 작성되고 수정, 삭제되기 때문에 오히려 인덱싱을 하게되면 엄청난 성능 저하가 되기 때문입니다!
이상으로 DB 인덱싱에 대한 포스팅을 마치도록 하겠습니다!
