📌 문제 설명
신입사원 무지는 게시판 불량 이용자를 신고하고 처리 결과를 메일로 발송하는 시스템을 개발하려 합니다. 무지가 개발하려는 시스템은 다음과 같습니다.
- 각 유저는 한 번에 한 명의 유저를 신고할 수 있습니다.
- 신고 횟수에 제한은 없습니다. 서로 다른 유저를 계속해서 신고할 수 있습니다.
- 한 유저를 여러 번 신고할 수도 있지만, 동일한 유저에 대한 신고 횟수는 1회로 처리됩니다.
- k번 이상 신고된 유저는 게시판 이용이 정지되며, 해당 유저를 신고한 모든 유저에게 정지 사실을 메일로 발송합니다.
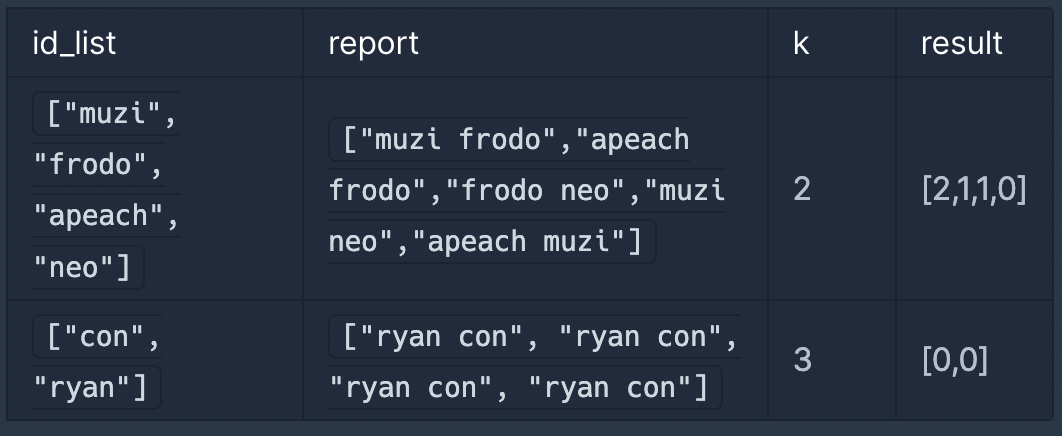
- 유저가 신고한 모든 내용을 취합하여 마지막에 한꺼번에 게시판 이용 정지를 시키면서 정지 메일을 발송합니다.다음은 전체 유저 목록이 ["muzi", "frodo", "apeach", "neo"]이고, k = 2(즉, 2번 이상 신고당하면 이용 정지)인 경우의 예시입니다.
각 유저별로 신고당한 횟수는 다음과 같습니다.
위 예시에서는 2번 이상 신고당한 "frodo"와 "neo"의 게시판 이용이 정지됩니다. 이때, 각 유저별로 신고한 아이디와 정지된 아이디를 정리하면 다음과 같습니다.
따라서 "muzi"는 처리 결과 메일을 2회, "frodo"와 "apeach"는 각각 처리 결과 메일을 1회 받게 됩니다.이용자의 ID가 담긴 문자열 배열 id_list, 각 이용자가 신고한 이용자의 ID 정보가 담긴 문자열 배열 report, 정지 기준이 되는 신고 횟수 k가 매개변수로 주어질 때, 각 유저별로 처리 결과 메일을 받은 횟수를 배열에 담아 return 하도록 solution 함수를 완성해주세요.
제한 사항
- 2 ≤ id_list의 길이 ≤ 1,000
- 1 ≤ id_list의 원소 길이 ≤ 10
- id_list의 원소는 이용자의 id를 나타내는 문자열이며 알파벳 소문자로만 이루어져 있습니다.
- id_list에는 같은 아이디가 중복해서 들어있지 않습니다.- 1 ≤ report의 길이 ≤ 200,000
- 3 ≤ report의 원소 길이 ≤ 21
- report의 원소는 "이용자id 신고한id"형태의 문자열입니다.
- 예를 들어 "muzi frodo"의 경우 "muzi"가 "frodo"를 신고했다는 의미입니다.
- id는 알파벳 소문자로만 이루어져 있습니다.
- 이용자id와 신고한id는 공백(스페이스)하나로 구분되어 있습니다.
- 자기 자신을 신고하는 경우는 없습니다.- 1 ≤ k ≤ 200, k는 자연수입니다.
- return 하는 배열은 id_list에 담긴 id 순서대로 각 유저가 받은 결과 메일 수를 담으면 됩니다
입출력 예
입출력 예 #2 설명
"ryan"이 "con"을 4번 신고했으나, 주어진 조건에 따라 한 유저가 같은 유저를 여러 번 신고한 경우는 신고 횟수 1회로 처리합니다. 따라서 "con"은 1회 신고당했습니다. 3번 이상 신고당한 이용자는 없으며, "con"과 "ryan"은 결과 메일을 받지 않습니다. 따라서 [0, 0]을 return 합니다.
제한시간 안내
- 정확성 테스트 : 10초



🤔 How?
- {유저 : 신고당한 횟수} 형태를 저장하는 dictionary 사용
- {유저 : 유저가 신고한 대상} 형태를 저장하는 dictionary 사용
- 중복된 신고 제거
한 유저가 같은 유저를 여러 번 신고한 경우는 신고 횟수 1회로 처리한다고 하였으니 주어진 report 변수에서 중복된 요소를 제거해야 한다. 처음에는 for문을 이용하였지만, 복잡도 측면에서 다른 방법을 이용하는 것이 좋을 거라 생각하여 "python list 중복 제거" 라는 키워드로 여러 방법을 찾았다.
그 중, set 의 특성을 이용하여 중복 제거를 할 수 있다는 것을 알았다.report = set(report)
- 지문에 따라서 1번과 2번의 dictionary를 만든 후, 주어진 k값을 기준으로 answer를 저장한다.
- 리스트의 index 반환 함수
index(x) 함수는 리스트에 x 값이 있으면 x의 위치 값을 돌려준다.
answer는 id_list에 담긴 id 순서대로 각 유저가 받은 결과 메일 수를 담아야 하기 때문에, id_list.index(u1)을 이용하였다!
💻 구현 코드
def solution(id_list, report, k) answer = [0] * len(id_list) # delete duplicate report report = set(report) # define dictionary 1 (key: user & value: reported user) # define deciotary 2 (key: user & value: reported count) d1 = {} d2 = {} for x in report: u1, u2 = x.split() if u1 not in d1: d1[u1] = [u2] else: d1[u1] += [u2] # print("d1 = ", d1) if u2 not in d2: d2[u2] = 1 else: d2[u2] += 1 # print("d2 = ", d2) # calculate stopped id for user, count in d2.items() : if count >= k: for u1, u2 in d1.items(): if user in u2: answer[id_list.index(u1)] += 1 return answer
🤓 느낀점
- set의 특성을 익히고 있으면 알고리즘을 구현할 때 유용하겠다.
- list.index(a) 처럼 알아두면 편할 함수들을 코테 준비하면서 정리하고, 반복해서 사용해야 겠다.
- 가독성 높은 변수명을 제작해야 겠다.
- 프로그래머스에서 '다른 사람의 풀이'를 보았는데..
https://school.programmers.co.kr/learn/courses/30/lessons/92334/solution_groups?language=python3&type=all
내가 구현한 코드라인에 비해 매우 짧은 길이의 코드였다..! 😳
이 정도 경지까지 되려면 얼마나 많은 문제를 풀어야 할까? 라는 생각이 들었고,
과연 코드가 짧을수록 좋은 걸까...?
그래 짧을수록 실행속도가 줄어들겠지 모.. ㅋㅋㅋ 쥬륵🥲

👩🏻💻 iOS Developer