📣 문제 설명
프렌즈대학교 컴퓨터공학과 조교인 제이지는 네오 학과장님의 지시로, 학생들의 인적사항을 정리하는 업무를 담당하게 되었다.
그의 학부 시절 프로그래밍 경험을 되살려, 모든 인적사항을 데이터베이스에 넣기로 하였고, 이를 위해 정리를 하던 중에 후보키(Candidate Key)에 대한 고민이 필요하게 되었다.
후보키에 대한 내용이 잘 기억나지 않던 제이지는, 정확한 내용을 파악하기 위해 데이터베이스 관련 서적을 확인하여 아래와 같은 내용을 확인하였다.
-
관계 데이터베이스에서 릴레이션(Relation)의 튜플(Tuple)을 유일하게 식별할 수 있는 속성(Attribute) 또는 속성의 집합 중, 다음 두 성질을 만족하는 것을 후보 키(Candidate Key)라고 한다.
-
유일성(uniqueness) : 릴레이션에 있는 모든 튜플에 대해 유일하게 식별되어야 한다.
-
최소성(minimality) : 유일성을 가진 키를 구성하는 속성(Attribute) 중 하나라도 제외하는 경우 유일성이 깨지는 것을 의미한다. 즉, 릴레이션의 모든 튜플을 유일하게 식별하는 데 꼭 필요한 속성들로만 구성되어야 한다.
제이지를 위해, 아래와 같은 학생들의 인적사항이 주어졌을 때, 후보 키의 최대 개수를 구하라.
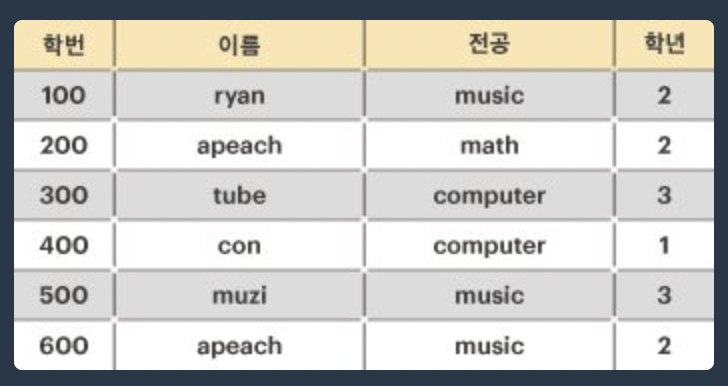
💡 문제 풀이
1. Attribute 개수가 n개일 때, 1 ~ n개의 조합으로 컬럼 인덱스를 만든다.
from itertools import combinations as combi
candidates = []
for i in range(1, col+1):
candidates.extend(combi(range(col), i))📌 list 자료형에서
append와extend의 차이점
append: list 맨 뒤에 요소 1개를 추가extend: iterable한 모든 요소를 추가
2. 유일성 체크
위에서 만든 조합의 인덱스에 해당하는 모든 속성을 튜플 형태로 뽑고,
그 개수가 relation 행의 개수와 동일한 경우만 unique 리스트에 담는다.
unique = []
for candi in candidates:
tmp = []
for item in relation:
tmp.append(tuple([item[i] for i in candi]))
if len(set(tmp)) == row:
unique.append(candi)3. 최소성 체크
unique 리스트에서 하나씩 뽑은 요소의 길이와 그 다음 요소와의 교집합 개수를 비교하여, 길이가 같은 경우는 최소성을 만족하지 않으므로 discard로 제거한다.
answer = set(unique)
for i in range(len(unique)):
for j in range(i+1, len(unique)):
if len(unique[i]) == len(set(unique[i]) & set(unique[j])):
answer.discard(unique[j])📌 set 자료형에서 remove와 discard 차이점
remove(): 지우려는 element가 없으면 KeyError 발생discard(): 지우려는 element가 없어도 정상적으로 종료
👩🏻💻 전체 코드
from itertools import combinations as combi
def solution(relation):
row = len(relation)
col = len(relation[0])
# 전체 조합
candidates = []
for i in range(1, col+1):
candidates.extend(combi(range(col), i))
# 유일성
unique = []
for candi in candidates:
tmp = []
for item in relation:
tmp.append(tuple([item[i] for i in candi]))
if len(set(tmp)) == row:
unique.append(candi)
# 최소성
answer = set(unique)
for i in range(len(unique)):
for j in range(i+1, len(unique)):
if len(unique[i]) == len(set(unique[i]) & set(unique[j])):
answer.discard(unique[j])
return len(answer)출처
