
"Do it! 자바 완전 정복" 책을 바탕으로 intellij와 함께 하는 JAVA 공부
1. 변수와 자료형
변수
메모리 공간에 부여하는 이름
자료형
데이터를 저장하기 위해 생성하고, 목적에 따라 크기와 특징이 다른 메모리 공간
1. 자료형 선언하기
C, Java와 같은 컴파일(Compile) 언어는 변수를 사용하기 전에 반드시 자료형을 선언
선언 시 주의할 점
- 자료형은 반드시 사용하기 전에 선언
자료형이 선언되지 않은 변수는 사용할 수 없다. - 자료형은 반드시 한 번만 선언
자료형이 한번 선언된 변수의 자료형은 바꿀 수 없다.
변수의 한 번 지정된 자료형을 바꿀 수 없는 이유
변수의 자료형이 처음 선언되면 메모리에는 선언된 자료형의 데이터만 저장할 수 있는 공간이 만들어지는데, 메모리에서 한 번 만들어진 공간은 사라질 수는 있어도 데이터를 저장하는 기능은 변경할 수 없기 때문이다.
2. 변수 사용하기
1. 변수 선언과 함께 값 대입
int a = 3;명령 하나로 2개의 수행 내용(선언 및 대입)을 처리하지만,
내부에서는 변수 선언이 먼저 수행돼 메모리에 공간이 생성된 다음 생성된 공간에 값이 대입
2. 변수 선언과 값 대입 분리
int a;
a = 3;변수의 선언과 값의 대입을 분리해 수행
변수의 선언이 먼저 이뤄져야 한다
int a 에서는 메모리에 a라는 이름의 공간만 생성되기에 변수 a이 공간은 비어 있는 상태
따라서 해당 상황에서 값을 읽으려한다면 컴파일 오류가 발생
2. 이름 짓기
변수와 상수의 이름을 지을 때는 필수 사항과 권장 사항을 준수해야 한다.
필수 사항은 지키지 않으면 문법 오류(Syntax error)가 발생해 컴파일 자체가 불가
권장 사항은 개발자끼리의 약속 정도로, 문법 오류는 발생하지 않음
1. 이름을 지을 때 지켜야 하는 필수 사항
변수, 상수, 메서드의 이름을 지을 때 반드시 지켜야 하는 공통 사항
- 영문 대소 문자와 한글을 사용할 수 있다.
- 특수 문자는 밑줄(_)과 달러($) 표기만 사용할 수 있다.
- 아라비아 숫자를 사용할 수 있다. 단, 첫 번째 글자로는 사용할 수 없다.
- 자바에서 사용하는 예약어는 사용할 수 없다.
2. 이름을 지을 때 지키면 좋은 권장 사항
변수명을 지을 때 권장 사항
- 영문 소문자로 시작한다.
- 영문 단어를 2개 이상 결합할 때는 새로운 단어의 첫 글자를 대문자로 한다.
낙타의 혹처럼 생겼다고 하여 '낙타 표기법(camel case)'이라고도 한다.
상수명을 지을 때 권장 사항
상수는 변수와 구분하기 위해 모두 대문자로 표기, 다만 단어가 여러 개 결합하면 가독성을 위해 각각 밑줄(_)을 사용해 분리
메서드명을 지을 때 권장 사항
메서드명을 지을 때의 권장 사항은 변수명일 때와 동일
3. 변수의 생존 기간
변수의 생존 기간
메모리에 변수가 만들어진 이후 사라지기까지의 기간
변수 생성은 Developer가 하지만, 메모리에서 변수를 삭제하는 작업은 JVM이 수행한다.
만일, 사라진 변숫값을 읽거나 값을 대입하려고 하면 문법 오류가 발생하기 때문에 메모리에서 변수가 사라지는 시점을 이해하는 것은 매우 중요하다.
변수는 선언된 시점에 생성된다. 이후, 자신이 선언된 열린 중괄호({)의 쌍인 닫힌 중괄호(})를 만나면 메모리에서 삭제된다.
3. 자료형의 종류
자료형은 크게 '기본 자료형'과 '참조 자료형'으로 나눌 수 있다.
기본 자료형에는 8가지, 나머지 이외의 모든 자료형은 참조 자료형으로 분류된다.
자료형을 구분하는 이유
기본 자료형과 참조 자료형의 값 저장 방식이 서로 다르기 때문
자료형의 구분을 이해하려면 먼저 메모리의 구조를 알아야 하는데,
메모리
목적에 따라 크게 3가지 영역으로 나뉨
- 클래스(class) 영역, 정적(static) 영역, 상수(final) 영역, 메서드(method) 영역이라는 4개의 이름으로 불리는 영역
- 스택(stack) 영역: 변수들이 저장되는 공간
- 힙(heap) 영역: 객체들이 저장되는 공간

1. 기본 자료형과 참조 자료형의 차이
자료형의 이름 규칙
첫 번째 차이점은 자료형 자체의 이름 규칙에 있다.
기본 자료형 8개의 이름은 모두 소문자(int, long, float, double, ...)로 시작하는 반면, 참조 자료형의 이름은 모두 대문자(String, System, ...)로 시작한다. (하지만 이는 권장 사항이므로 어기더라도 오류는 발생하지 않는다.)
실제 데이터값의 저장 위치
두 번째 차이점은 실제 데이터값의 저장 위치가 다르다는 것이다.
기본 자료형과 참조 자료형 모두 변수의 공간이 스택 메모리에 생성되지만, 그 공간에 저장되는 값의 의미가 서로 다르다.
기본 자료형
스택 메모리에 생성된 공간에 실제 변숫값을 저장
참조 자료형
실제 데이터값은 힙 메모리에 저장하고, 스택 메모리의 변수공간에는 실제 변숫값이 저장된 힙 메모리의 위칫값을 저장
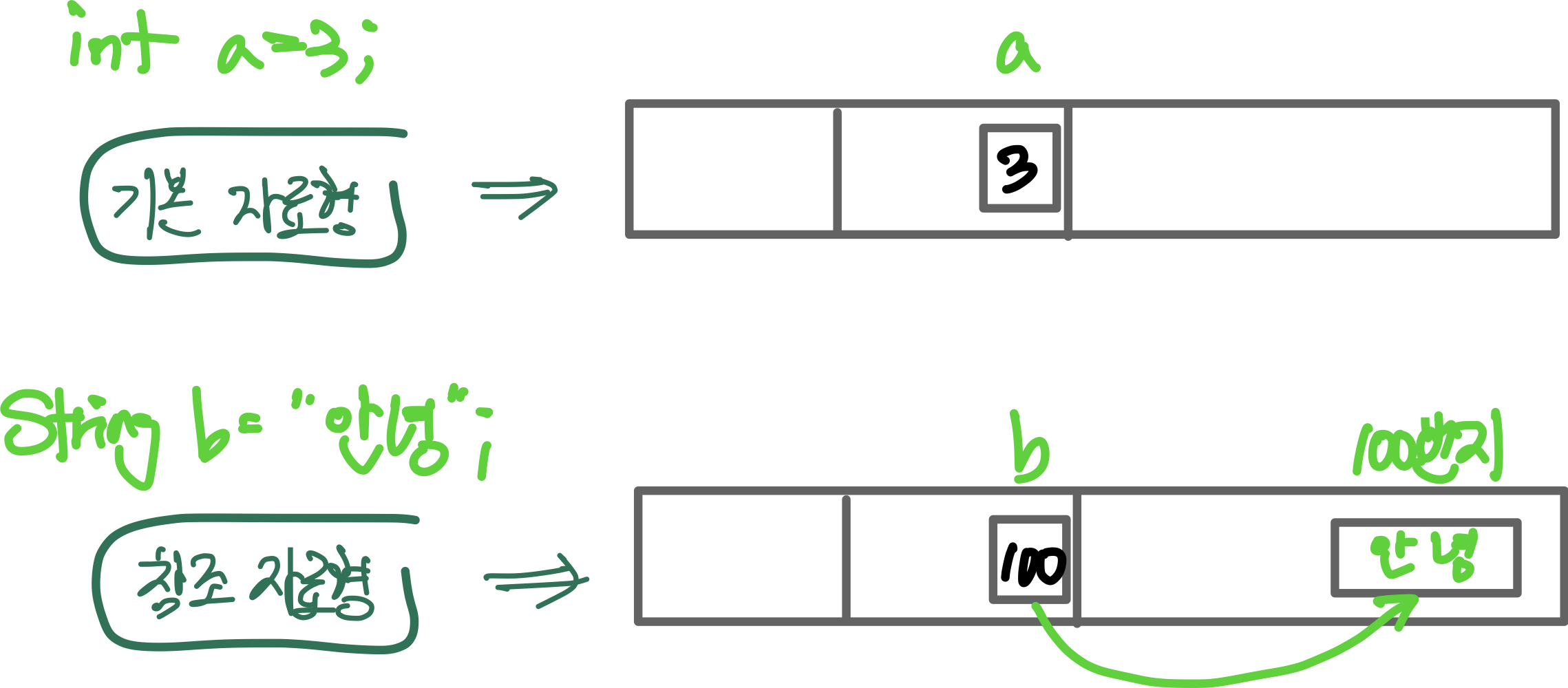
Java는 힙 메모리에 직접 접근할 수 없으므로 반드시 위칫값을 저장하고 있는 참조 변수 b가 필요
2. 기본 자료형의 메모리 크기와 저장할 수 있는 값의 범위
정수를 저장할 수 있는 자료형 4개(byte, short, int, long)를 보면,
자료형의 크기가 클수록 저장하는 값의 범위도 넓어지는 것을 알 수 있다.
표현할 수 있는 값이 많은 만큼 차지하는 메모리의 크기도 증가하는 방식이므로 당연한 결과이다.
각 정수 자료형의 값 범위 결정 방식
n개의 비트로 표현할 수 있는 정수: 2^n개
정수는 음수, 0, 양수를 포함하므로 표현할 수 잇는 전체 개수 중 반은 음수, 나머지 반은 0과 양수에 할당한다.
그 결과 byte 자료형의 값 범위는 -2^7 ~ 2^7-1이다.
각 실수 자료형의 값 범위 결정 방식
float와 double 자료형은 각각 4byte와 8byte로 int, long과 같지만, 저장할 수 있는 값의 범위는 훨씬 넓다. 이는 실수의 저장 방식이 부동 소수점, 즉 '가수X밑(지수)'의 형태이기 때문이다.

부동 소수점 표현 방식에서,
지수
표현할 수 있는 값의 범위에 영향을 미치는 요소
가수
값의 정밀도에 영향을 미치는 요소
일반적으로 float 의 정밀도는 소수점 7자리, double 의 정밀도는 소수점 15자리 정도이다. 정밀도를 넘는 소수점 자리수를 대입하게 되면 오차가 발생한다.
3. 부울대수 자료형 - boolean
boolean은 true, false의 2가지 값만 포함할 수 있으므로 실제로는 1bit로도 충분하지만, 자료 처리의 최소 단위가 바이트이므로 1byte가 할당된다. 그리고 할당된 1byte 중 상위 7bit는 사용하지 않는다.
4. 정수 자료형 - byte, short, int, long
항상 대입 연산자(=)를 중심으로 양쪽의 자료형이 같아야 하고, 그렇지 않는 경우엔 문법 오류가 발생한다.
리터럴
코드에 직접 작성한 값
- byte와 short 자료형에 저장할 수 있는 범위 내의 정숫값이 입력된 경우
- byte 또는 short 자료형으로 인식
- byte, short에 저장할 수 없는 범위의 정숫값이 입력된 경우
- 모두 int 자료형으로 인식
- 또는 크기와 상관없이 int, long에 정수 리터럴을 입력할 때도 int 자료형으로 인식
다만, 정수 리터럴 뒤에 long을 나타내는 L(또는 l)을 붙여 표기하면 long 자료형으로 인식
// 1.
byte a = 3;
// 2.
byte a = 130;1번의 경우, byte에 저장할 수 있는 값이 byte 자료형에 대입된 경우이므로 byte로 인식
2번의 경우, byte에 저장할 수 없는 범위의 정숫값이 입력된 경우이므로 int로 인식
long a = 3 ?
과연 틀린 표현일까?
정수 리터럴 뒤에 L을 붙이지 않았으므로, int 자료형으로 인식할 것이고, 그렇다면 long = int의 형태가 되어 자료형이 불일치하는 것처럼 보인다.
하지만 오류는 발생하지 않는다.
바로 크기가 작은 자료형을 큰 자료형에 대입하면 컴파일러가 자동 타입 변환(type casting)을 수행하기 때문이다. 즉 long = long의 형태로 자료형이 일치
반면, 위의 2번의 예시에서는 오류가 발생하는데 이는 큰 자료형에서 작은 자료형으로의 변환은 자동으로 일어나지 않기 때문이다.
5. 실수 자료형 - float, double
실수도 크기가 서로 다른 2가지 자료형을 제공
부동 소수점 방식
- 저장하고자 하는 실숫값을 지수와 가수로 표현하는 방식
- 오차가 발생할 수 있지만, 매우 넓은 범위의 값 저장 가능
Java는 실수 리터럴을 double 자료형으로 인식하지만 float를 나타내는 F(또는 f)를 실수 리터럴 뒤에 붙이면 float 자료형으로 인식
6. 문자 자료형
char
문자를 저장하는 자료형으로, 작은따옴표('') 안에 표기
char a = 'A';- 'A'라는 문자를 char 자료형에 저장하기 위해 코드를 위와 같이 작성한 경우, 메모리에는 변수 a의 공간이 만들어지고, 그 안에 문자가 들어가야 할 것
하지만 메모리는 2진수 값만 저장할 수 있는 공간이기 때문에, 메모리에는 문자를 기록할 수 없다.
따라서, 모든 문자를 특정 정숫값으로 바꿔 저장 !
이를 위해 문자에 대한 정숫값을 매겨놓은 표가 유니코드(unicode) 표
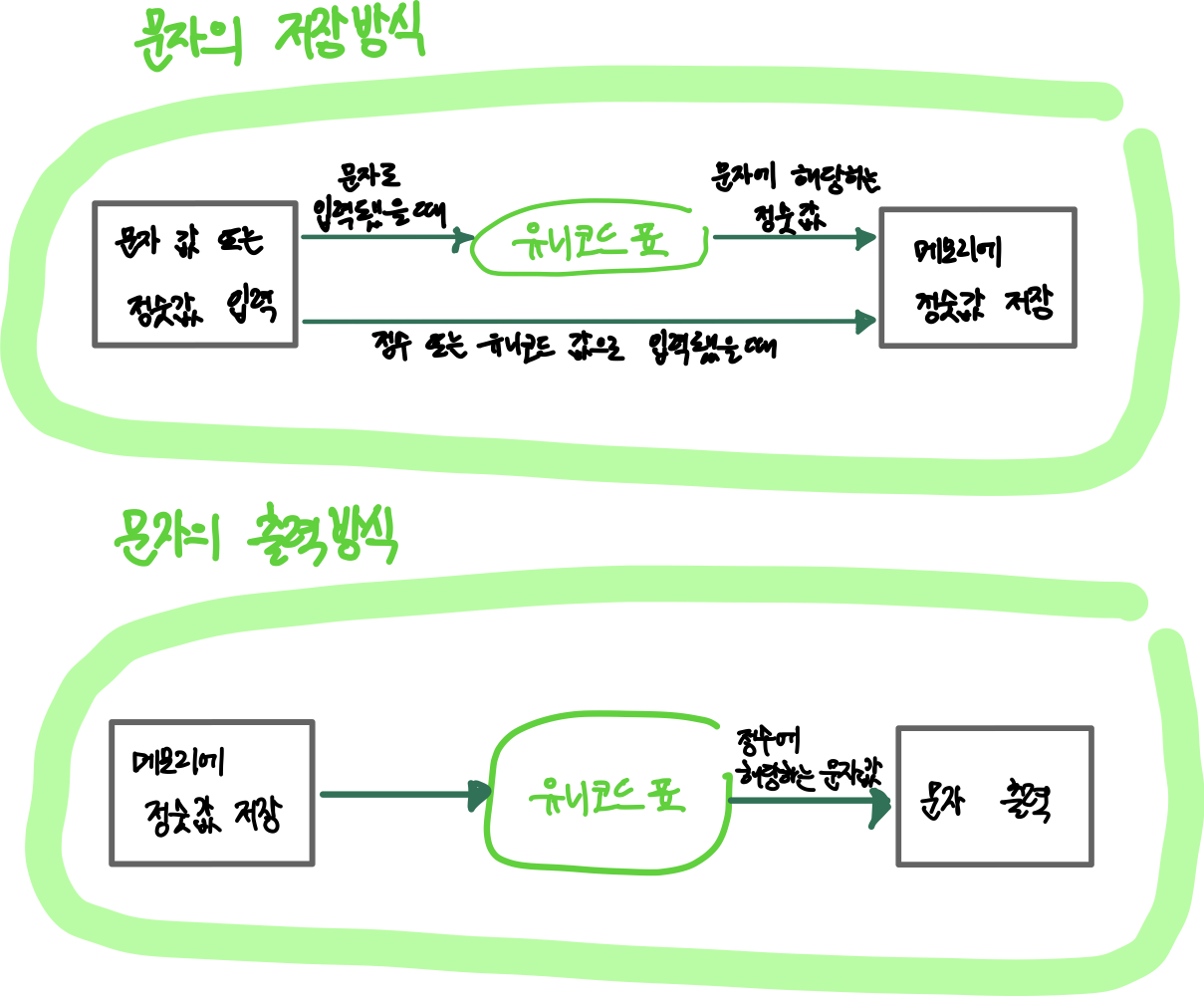
char 자료형 메모리 안은 문자가 아니라 정수가 저장된 형태이므로 char에 문자에 해당하는 정숫값을 직접 입력해도 같은 결과
4. 기본 자료형 간의 타입 변환
타입 변환(type casting)
boolean을 제외한 기본 자료형 7개가 자료형을 서로 변환하는 것
단순히 변환 대상 앞에 (자료형)만 표기하면 타입 변환이 가능
정수나 실수 리터럴은 숫자 뒤에 L이나 F를 붙여 long과 float으로 변환이 가능
타입 변환을 수행할 때는 저장할 수 있는 값의 범위나 종류가 달라지므로 값이 변할 수 있다.
1. 자동 타입 변환과 수동 타입 변환
자동 타입 변환
컴파일러가 자동으로 수행
수동 타입 변환
개발자가 직접 타입 변환을 수행
업캐스팅(up-casting)
크기가 작은 자료형을 큰 자료형에 대입하는 경우 어떠한 데이터 손실도 발생하지 않는다.
따라서 굳이 타입 변환 코드가 없어도 컴파일러가 자동으로 타입 변환을 실행하는데, 이를 '업캐스팅(up-casting)'이라 한다.
업캐스팅이 아닌데도 자동 타입 변환이 적용되는 때
모든 정수 리터럴 값은 int 자료형으로 인식
하지만 byte 및 short 자료형에 저장할 수 있는 범위 내의 정수 리터럴 값이 대입될 때는 자동 타입 변환이 각각의 자료형으로 수행
다운캐스팅(down-casting)
큰 자료형을 작은 자료형에 대입하는 행위
데이터 손실의 가능성이 있으므로 개발자가 직접 명시적으로 타입 변환을 수행해야 함
byte value4 = 9;
// int -> byte
short value5 = 11;
// int -> short위의 두 예제는 업캐스팅이 아닌데도 예외적으로 자동 변환이 수행
대입하는 값이 byte, short의 저장 범위 내의 값일 때는 자동 변환으로 자료형을 변환했을 때 값에 오차가 없으므로 가능
소수점 8자리 이상인 double 자료형의 실숫값을 float으로 변환하면 오차를 확인할 수 있음. (실수 리터럴은 기본적으로 double로 인식하기 때문)
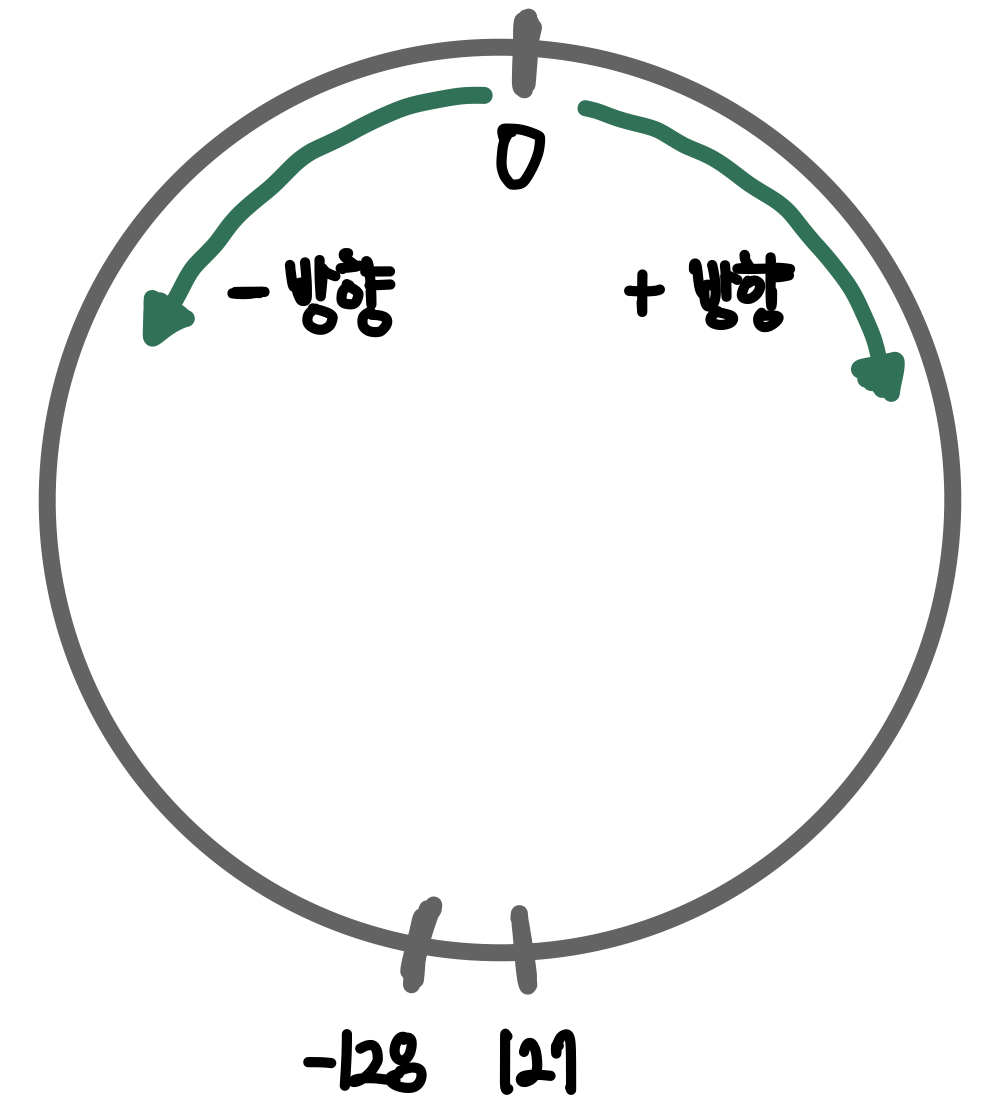
서큘러(circular) 구조
정수형 자료형을 작은 범위의 자료형으로 캐스팅할 때는 범위의 반대쪽 끝에서부터 다시 시작하는 구조를 보인다.
2. 기본 자료형 간의 연산
boolean을 제외한 나머지 기본 자료형은 서로 연산할 수 있고, 모든 연산은 같은 자료형끼리만 가능하다.
단, CPU에서 연산 최소 단위가 int이므로 int보다 작은 자료형도 일단 int로 읽어 와서 연산을 수행하기 때문에 int보다 작은 자료형 간의 연산 결과 또한 int이다.
int + long ?
다운캐스팅은 개발자가 직접 해 줘야 하지만, 업캐스팅은 자동 타입 변환이므로 int + long을 수행하면 컴파일러는 int를 long으로 자동 업캐스팅해 long + long으로 계산
