HashTable이란
키와 값을 가지는 자료구조이다. 해시 함수는 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이고 매핑 전 원래 데이터의 값을 키(key), 매핑 후 데이터의 값을 해시값(hash value), 매핑하는 과정 자체를 해싱(hashing)라고 합니다.
해시함수를 쓰는 이유는 메모리 관리가 효율적이기 때문이다. 키가 엄청 큰 데이터라고 했을 때 이것을 객체에 넣게 되면 메모리를 많이 잡아먹게 된다. 그래서 이를 해시함수를 통해서 숫자로 변환하여 메모리 사용량을 줄여 메모리 사용량을 줄일 수 있어 해시테이블을 사용한다.
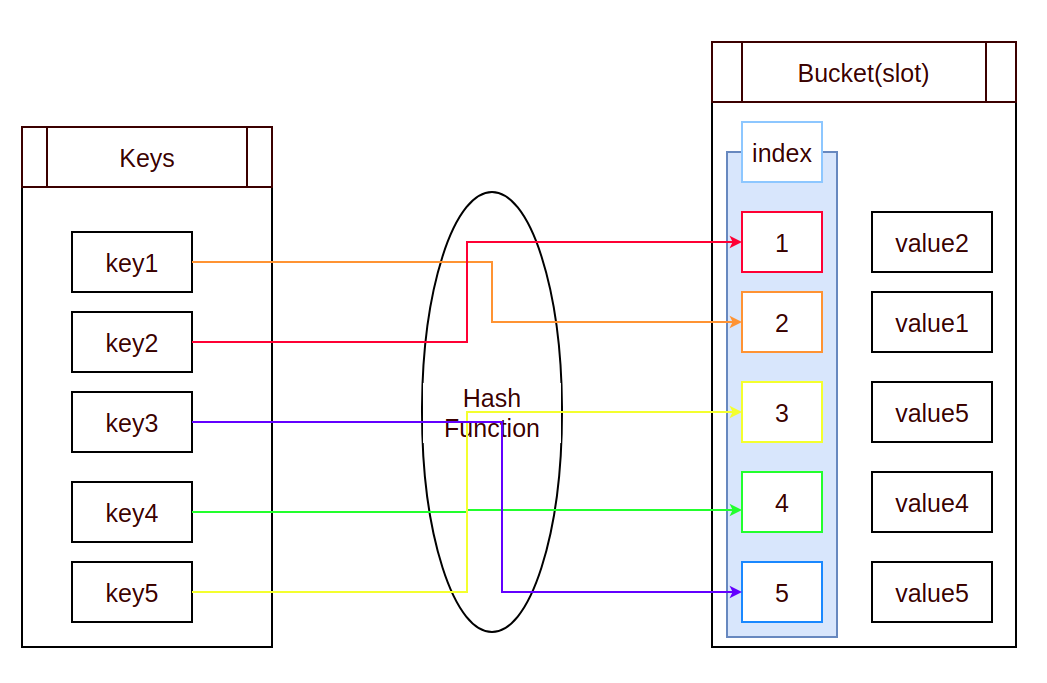
hashTable 그림
다시 간략히 설명하면 key('많은 문자열 및 서버 데이터(JSON) 등')를 입력하면 해시 함수를 통해서 해시값을 얻어내어 이를 통해 데이터를 매핑하는 그림을 약식으로 그려본 것이다. index는 해시값이고 bucket은 데이터가 저장되는 곳을 의미한다.
충돌
키의 길이가 정해지지 않아 많은 키를 해시함수를 통해 해시 값을 얻을 때 동일한 해시값을 얻을 수 있다.
이때 bucket에 데이터가 들어가 있지만 동일한 해시값이 나와 데이터가 또 들어가려고 할 때 충돌이 일어난다고 한다. 이때 여러 해결 방법 중 두가지를 알아설명해 보겠습니다. chaining과 open addressing이 있다. chaining은 해시 테이블의 크기를 유연하게 해주고 open addressing은 남는 공간을 잘 활용해준다.
chaining
충돌 시 bucket에 데이터를 저장할 때 연결 리스트로 저장하는 방법이다. 이때 시간 복잡도는 O(1)에서 O(n)으로 변경된다.
open addressing
충돌 시 bucket에 데이터를 저장할 때 빈 곳을 찾아 저장하는 방법이다.
해시 함수 특징
1. 해시 함수 결과는 배열의 인덱스 범위로 나와야한다.
2. 키를 여러번 입력해도 동일한 해시값이어야한다.
3. 이전의 키값이나 배열의 위치를 저장하지 않는다.
시간 복잡도
추가/삭제/조회 : O(1)
단, 충돌시 해결하기 위해 chaining / open addressing 방법을 사용하면 시간 복잡도가 변경될 수 있습니다.
