고객(나🙂) 요구사항
사용자 관리
- 사용자는 회원가입 시 이름, 이메일, 주소, 비밀번호를 입력해야 하며, 이메일은 고유해야 합니다.
- 사용자는 buyer 또는 seller 역할을 가질 수 있으며, 기본 역할은 buyer로
설정됩니다.
제품 관리
- 판매자는 제품을 등록할 수 있으며, 제품에는 설명, 가격, 재고 정보가 포함
됩니다. - 재고는 기본값으로 0으로 설정되며, 가격과 설명은 반드시 입력되어야 합니
다. - 제품에는 여러 이미지를 첨부할 수 있으며, 각 이미지는 URL로 저장됩니다.
- 제품은 하나 이상의 카테고리에 속할 수 있습니다.
장바구니
- 사용자는 장바구니에 제품을 추가할 수 있습니다.
- 장바구니는 제품의 가격과 수량 정보를 저장하며, 기본 수량은 1로 설정됩니다.
카테고리 관리
- 관리자 또는 판매자는 새로운 카테고리를 추가할 수 있으며, 각 카테고리는
고유한 이름을 가집니다. - 제품은 여러 카테고리에 연관될 수 있습니다.
위시리스트
- 사용자는 위시리스트에 원하는 제품을 추가할 수 있습니다.
- 위시리스트는 사용자와 제품의 연관 정보를 저장합니다.
주문 관리
- 사용자는 장바구니에서 주문을 생성할 수 있습니다.
- 주문에는 총 금액, 결제 방법(예: 카드, 페이팔, 현금), 주문 상태(예:
pending, completed, canceled)가 포함됩니다. - 주문 상태는 기본값으로 pending으로 설정됩니다. 주문된 제품 관리
- 하나의 주문에는 여러 제품이 포함될 수 있으며, 각 제품의 가격과 수량 정보를 저장합니다.
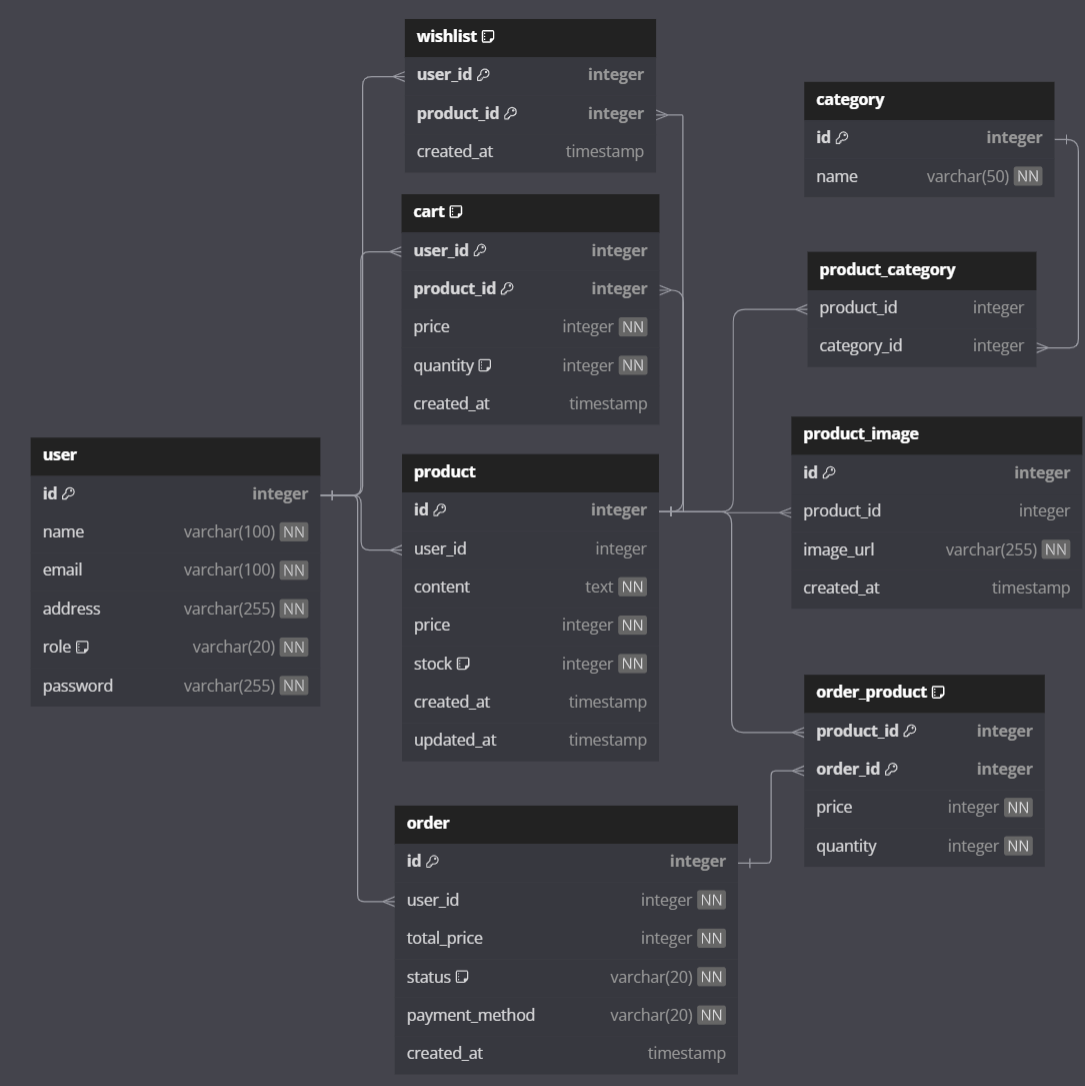
ERD (dbdiagram.io)
- erd diagram을 그릴 때는 표의 기능을 반드시 명시해야한다.
dbeaver 🦫
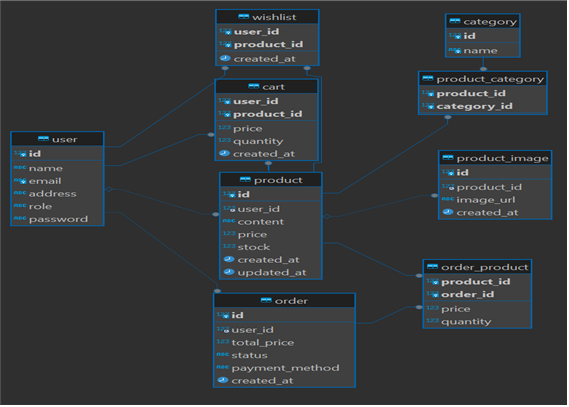
Table 설계
table을 설계할 때는 datatype을 고려해야 한다.
- varchar을 사용할 때는 적당한 memory를 할당해 줘야지 비용을 아낄 수 있다.
- null or not null 고민해보자
- 중간 table이 많으면 좋지만 indexing을 잘 활용해야지 성능을 높일 수 있다.
- PK는 indexing을 위해 내부적으로 변하지 않는 id로 설정한다.
- 3NF 까지는 구현해보고 성능이 만족스럽지 않으면 BCNF로 전환 or 프로시저, index 설정.
- entity는 고유하고 무결성이 있어야한다.
- Dbeaver를 활용할 때 transaction 내에서 commit은 에러 여부를 확인한 후 반드시 마지막에!!
- user
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
address VARCHAR(255) NOT NULL,
role VARCHAR(20) NOT NULL DEFAULT 'buyer',
password VARCHAR(255) NOT NULL
); # 한글 : 1byte 영어 : 2byte**
- product
CREATE TABLE product (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
content TEXT NOT NULL,
price INT NOT NULL,
stock INT NOT NULL DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE SET NULL
); #user가 삭제되면 해당 FK는 null이 된다(ON DELETE SET NULL)
- cart
CREATE TABLE cart (
user_id INT,
product_id INT,
price INT NOT NULL,
quantity INT NOT NULL DEFAULT 1,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (user_id, product_id),
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE,
FOREIGN KEY (product_id) REFERENCES product(id) ON DELETE CASCADE
); # ON DELETE CASCADE : FK가 참조하고 있는 key가 삭제되면 자동으로 삭제됩니다. user나 product가 out of stock 등 으로 삭제되면 cart에서 사라집니다.
[ cart는 여러 product를 담을 수 있으므로 추후에 수정이 필요해 보입니다. ]
- wishlist
CREATE TABLE wishlist (
user_id INT,
product_id INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (user_id, product_id),
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE,
FOREIGN KEY (product_id) REFERENCES product(id) ON DELETE CASCADE
);
wishlist도 cart처럼 ON DELETE CASCADE가 걸려있습니다.
- order
CREATE TABLE `order` (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
total_price INT NOT NULL,
status VARCHAR(20) NOT NULL DEFAULT 'pending',
payment_method VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE
);
user가 주문을 한다면 order table에 추가됩니다. 해당 user가 삭제된다면 order row도 삭제됩니다.
- order_product
CREATE TABLE order_product (
product_id INT,
order_id INT,
price INT NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (product_id, order_id),
FOREIGN KEY (product_id) REFERENCES product(id) ON DELETE CASCADE,
FOREIGN KEY (order_id) REFERENCES `order`(id) ON DELETE CASCADE
);
order product many to many를 연결해주는 table로 order나 product가 삭제되면 같이 삭제됩니다.
- product_image
CREATE TABLE product_image (
id INT PRIMARY KEY AUTO_INCREMENT,
product_id INT,
image_url VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (product_id) REFERENCES product(id) ON DELETE CASCADE
);
product image url을 저장하는 table입니다. s3 presigned url이 들어갈 예정입니다.
- category
CREATE TABLE category (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) UNIQUE NOT NULL
);
product의 category입니다.
- product_category
CREATE TABLE product_category (
product_id INT,
category_id INT,
PRIMARY KEY (product_id, category_id),
FOREIGN KEY (product_id) REFERENCES product(id) ON DELETE CASCADE,
FOREIGN KEY (category_id) REFERENCES category(id) ON DELETE CASCADE
);
product와 category를 many to many로 mapping 하는 table입니다. 해당 product나 category가 삭제된다면 역시 자동으로 삭제됩니다.복잡한 테이블 관계 설정 및 데이터 삽입
1. '품목' 카테고리의 모든 제품 가격을 5% 인상하세요.
select * from product

price는 integer type으로 선언했기 때문에 소수점 첫째자리에서 반올림하여 정수값이 나오도록 ROUND를 사용하였습니다.

상품의 가격이 5% 인상되었습니다.

2. 2025년 1월 이전에 가입한 고객의 주문 중 '배송완료' 상태가 아닌 주문을 모두 '배송완료'로 변경하세요.
select * from order

status가 pending이고 해당 order을 한 user의 가입일이 2025-01-01 미만인 주문만 completed로 업데이트 합니다.

user는 전부 1월 1일 전에 가입하였기 때문에 pending 이었던 status들이 completed로 업데이트 되었습니다.


3. 재고가 10개 미만인 제품을 주문한 모든 주문 상세 내역을 삭제하고, 해당 주문의 총 금액을 업데이트하세요.
product table에서 재고를 확인하고,

order_product 테이블에서 재고가 10개보다 낮은 product를 포함한 order id를 찾습니다.
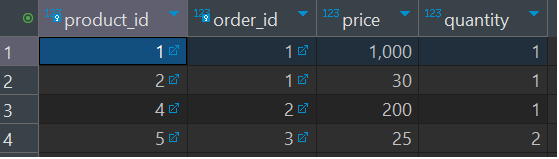
product id 1, 4, 5를 포함한 order_id는 1,2,3입니다.

stock이 10 미만인 order를 order_product에서 삭제합니다.
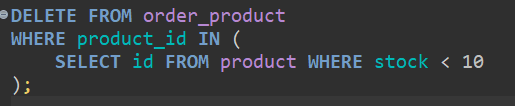
1개만 남아있습니다. (product_id 2는 재고가 20개 입니다.)

order 테이블에서 order_product에 없는 order_id row는 삭제합니다.

이제 order_product(주문 상세 내역) 에 남아있는 order들은 가격을 업데이트합니다.
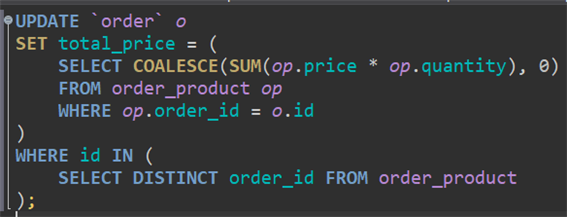
기존에 1030이었던 total_price가 30으로 수정되었습니다.

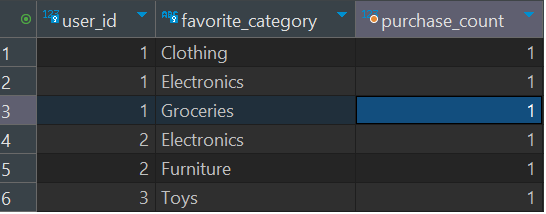
4. 고객별 가장 자주 구매하는 카테고리
이전 과정에서 데이터를 삭제했기 때문에 새로운 데이터를 추가해줬습니다.
-
order table
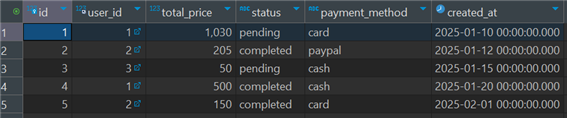
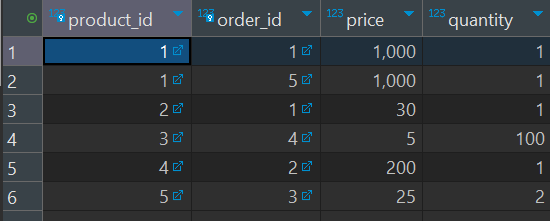
-
order_product table
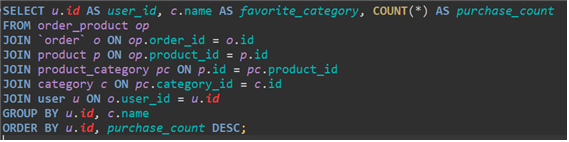
고객별 가장 많이 주문하는 카테고리를 찾기 위해서 join과 count(*)를 사용했습니다. u.id와 c.name을 group by 하였고 어느 품목을 몇 번 샀는지 확인할 수 있습니다.
- Spring boot JPA fetch join을 사용하면 Lazy Loading으로 mapping된 entity를 개별적으로 join할 수 있기 때문에 N+1 query 문제를 해결할 수 있습니다.
- Select o from order o join fetch o.user where o.id = :id(parameter로 가져옵니다)
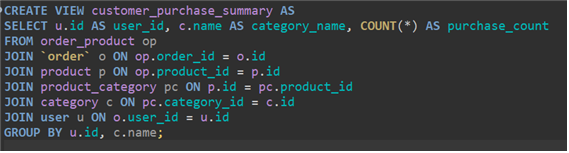
5번의 join 쿼리를 직접 작성하는건 비효율적이기 때문에 view를 추가했습니다.
- view create
- view도 table이기 때문에 select로 볼 수 있습니다.
‼️하지만, 데이터가 변경될 때 마다 view 또한 업데이트 되기 때문에 overhead가 커질 것 같습니다. 따라서, 실시간성이 중요하지 않다면 create event로 1시간에 1번씩 업데이트되는 테이블을 따로 만들어 놓는 것도 좋은 방법 같습니다. ( Create event vs Trigger )

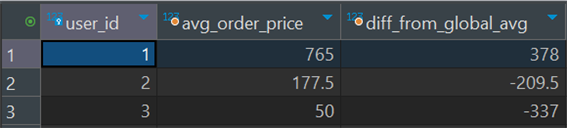
5. 고객별 평균 주문 금액과 전체 고객 평균과의 차이
우선 order 테이블에서 각 고객의 구매 금액 평균을 구해주고, 각 고객의 평균에서 전체 평균을 빼주었습니다.

결과 :
5-1. query문 실행 순서
sql query는 실행 순서가 있습니다. 코드 작성자는 select부터 작성하지만 db는 다른 순서로 데이터를 불러옵니다.
-
- from and join
select * from user u left outer join
ordero on u.id = o.user_id
- from and join
-
- where
where u.id = o.user_id
- where
-
- group by
group by role, u.id
- group by
-
3-1. group by 함수 (SUM, COUNT, AVG)
-
- having (group의 where)
having u.id >= 2
- having (group의 where)
-
- select : 보여줄 coloumn 선택, 이름을 custom하게 설정할 수 있다. (as 권장)
-
- order by : 어떤 순서로 정렬할건지 default는 asc이고 desc로 내림차순 변경 가능
-
- limit : 정렬된 데이터를 몇 개까지 보여줄건지
-
example
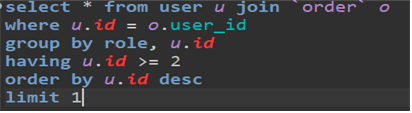
-
결과

6. 각 고객의 최근 주문과 이전 주문 사이의 평균 기간
from 안의 subquery에서 LEAD를 활용하여 각 주문의 다음 order 이 언제 create 되었는지 확인해주었습니다. 만약 다음 주문이 없었다면 포함시켜주지 않았습니다.

서브 쿼리를 확인해보면 다음과 같습니다.
- 서브 쿼리 결과

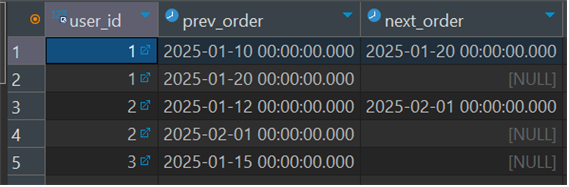
결과 : next_order이 없는 id 3 user는 보이지 않지만, 1과 2는 확인할 수 있습니다. (datediff는 timestamp format의 day의 차이를 가져옵니다)
TODO
ACID 공부
- 원자성(Atomicity)
transaction이 DB에 전부 반영되거나, 혹은 전혀 반영되지 않아야 된다.
- 일관성(Consistency)
transaction의 작업 처리 결과는 항상 일관성 있어야 한다.
- 독립성(Isolation)
둘 이상의 transaction이 동시에 병행 실행되고 있을 때, 어떤 transaction도 다른 transaction 연산에 끼어들 수 없다.
- 지속성(Durability)
transaction이 성공적으로 완료되었으면, 결과는 영구적으로 반영되어야 한다.
정규화 공부
- 1NF
- 중복 제거 : coloumn 내에 중복된 값이 없어야 한다.
- 원자성 : 각 coloumn은 더 이상 분할할 수 없는 최소 단위의 데이터로 구성해야 한다.
- 관계형 데이터 모델 기초 : 정규화의 첫 번째 단계로, 기본적인 데이터 무결성을 확보
- 2NF
- 1NF를 만족해야 한다.
- Non-key 속성이 primary key의 일부분에만 종속되는 경우 제거해야 한다.
- 3NF
- 1, 2 NF를 만족해야 한다.
- 이행적 함수 종속이 없어야 한다. (X -> Y, Y -> Z 라면 X -> Z도 성립하지만, Y가 후보키가 아닐 경우 이를 제거해야 한다.)
- BCNF
- 결정자(Determinant)가 후보키가 되도록 해야한다. (PK가 아닌 속성이 결정자가 되어선 안된다.)
- BCNF는 2NF를 만족할 수도 있고 만족하지 못할 수도 있다.
- 결정자, super key, 후보키(candidate key)가 뭐죠?
- Determinant : 결정자는 테이블 내에서 다른 속성(컬럼)의 값을 결정하
는 속성을 의미합니다. - super key : 테이블에서 각 행을 유일하게 식별할 수 있는 속성 또는 속성들의 집합 (중복이 없어야 하지만, 최소성을 보장하지는 않음)
- candidate key : Super key 중에서 최소성을 만족하는 key
