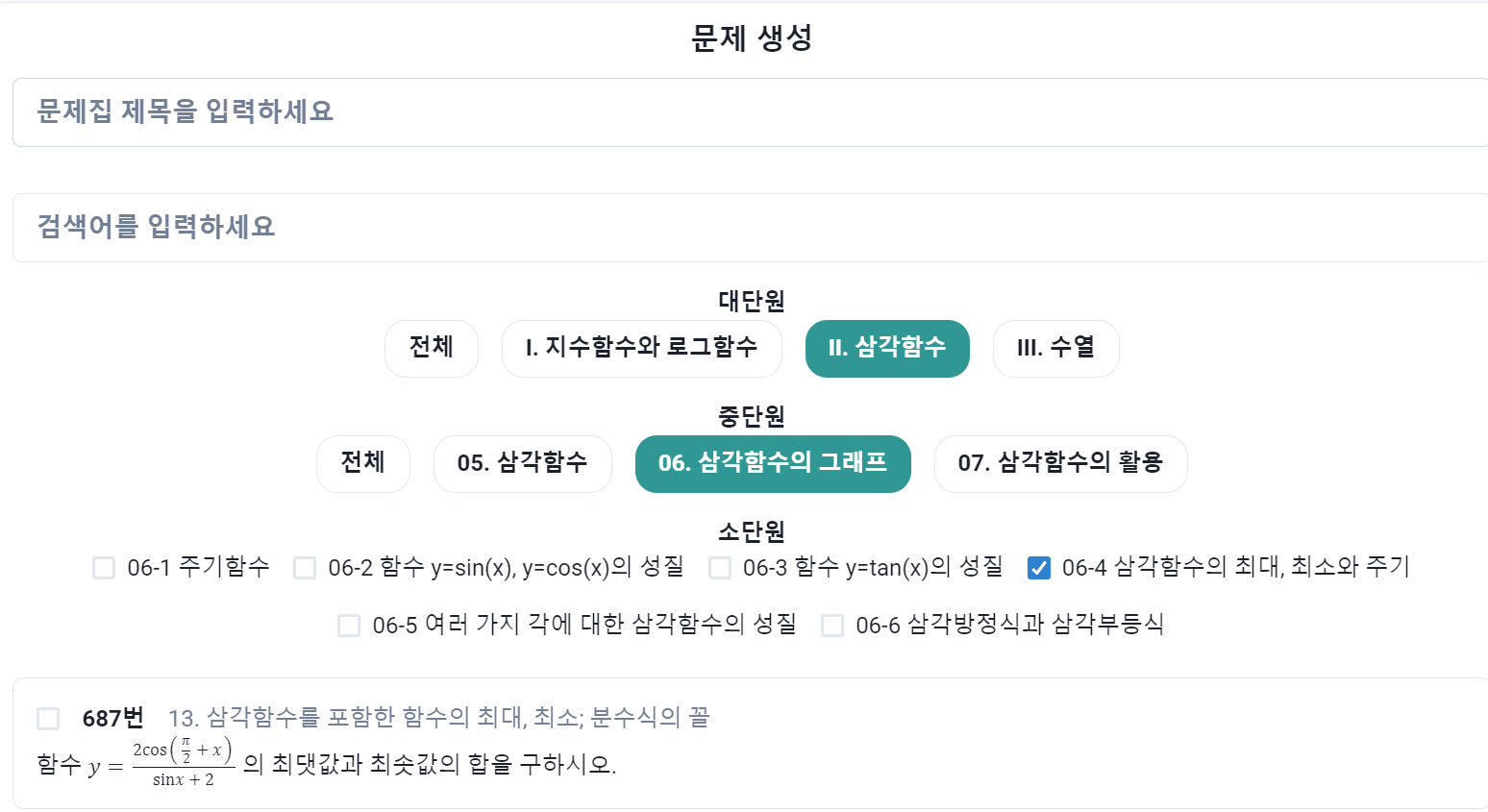
문제집을 생성하기 위해서 문제 은행이 필요하다.
모든 문제를 나타내는 endpoint url을 생성하고 view에서 serializer를 통해 return 해준다.
선생님들의 편의를 위하여 문제 은행에서 대, 중, 소 단원을 기준으로 문제를 search 할 수 있게끔 만들어 줘야한다.
First Step
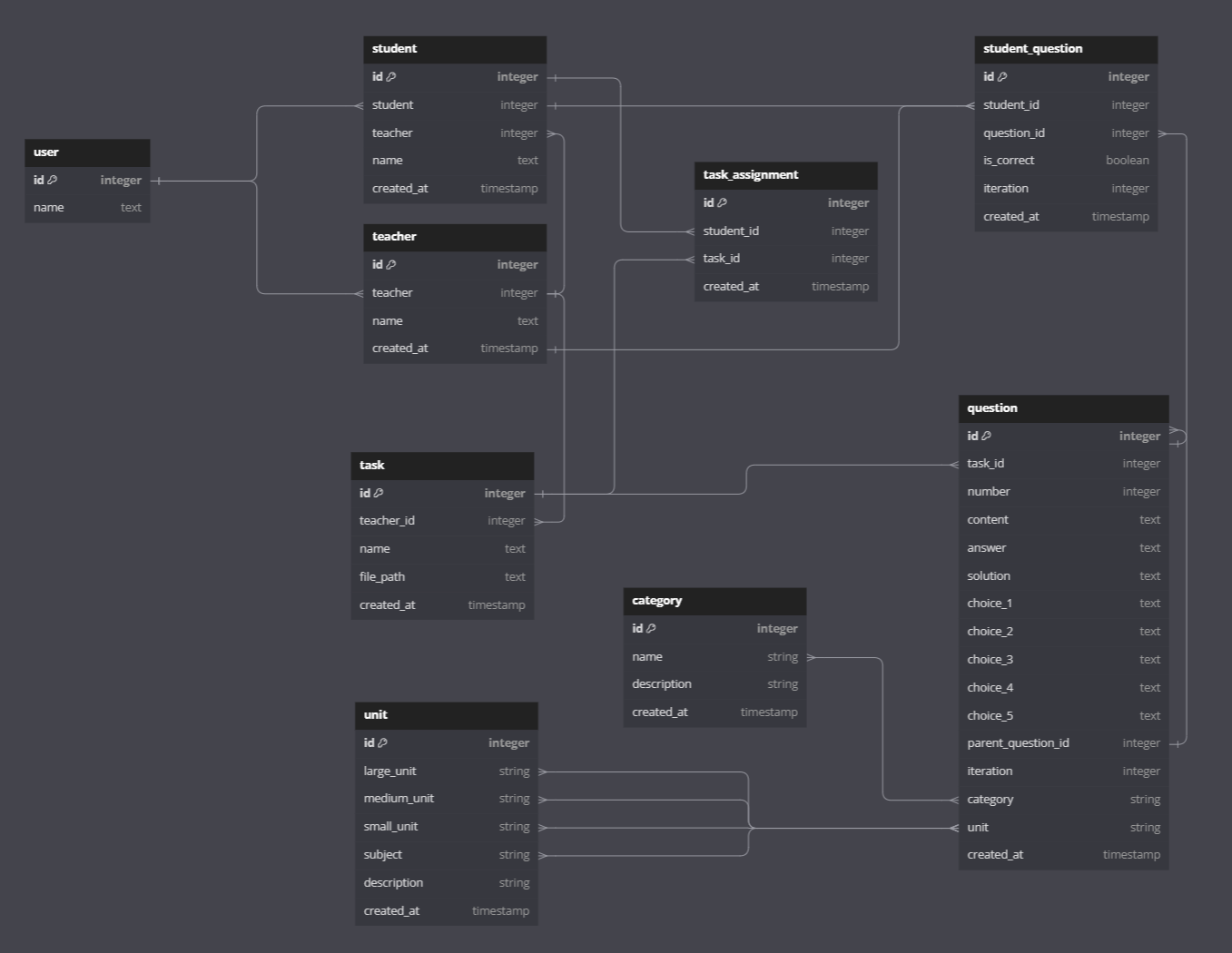
데이터 베이스 구조를 짜보자. 대, 중 단원은 각 문제 당 1개씩 존재하지만, 소단원은 중복 선택이 가능하다. 따라서 unit(단원), category(유형) table을 각각 만들어주고, questions Table과 Many To Many 맵핑해주었다.
Second Step
BE 에 구현해준다.

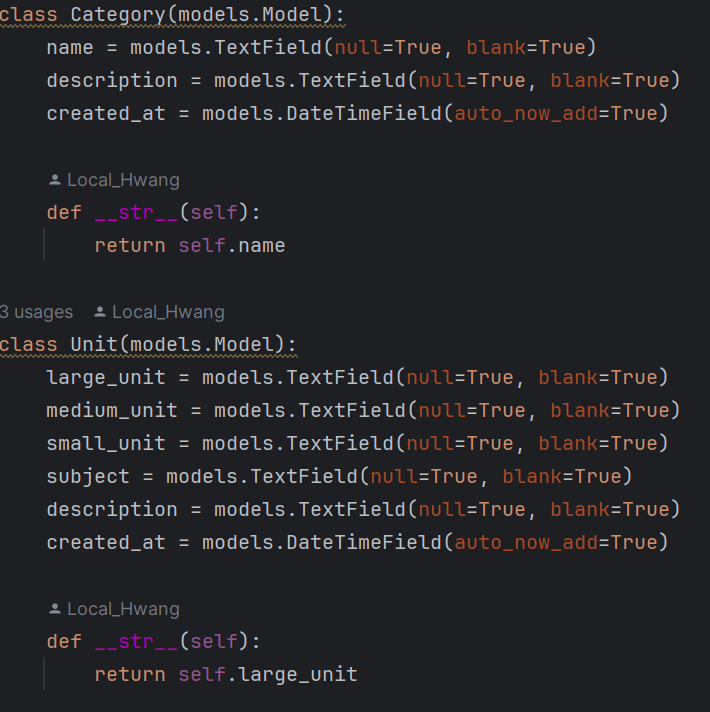
__str__ 은 admin page에서 보여주는 내용이다.
Third Step
문제의 분류 방법이 바뀌었기 때문에, jupyter에서 pandas를 통해 분류한 문제들을 데이터베이스에 넣어 주었다. (CSV -> pandas -> database)

Fourth Step
분류 방법을 기준으로 FE dashboard 코드와 BE views 코드를 수정해준다.
class StandardResultsSetPagination(PageNumberPagination):
page_size = 10 # 페이지 당 항목 수
page_size_query_param = 'page_size'
max_page_size = 100
class QuestionView(APIView):
permission_classes = [IsAuthenticated]
authentication_classes = [JSONWebTokenAuthentication]
pagination_class = StandardResultsSetPagination
def get(self, request, format=None):
"""
Return a paginated list of questions, filtered by categories and search term.
"""
large_unit = request.query_params.get('large_unit', '')
medium_unit = request.query_params.get('medium_unit', '')
small_units = request.query_params.get('small_unit', '').split('|') if request.query_params.get('small_unit',
'') else []
search_term = request.query_params.get('search', '')
# Base query
questions = Question.objects.filter(iteration=0).order_by('number').distinct()
# Apply filters
if large_unit:
questions = questions.filter(unit__large_unit=large_unit)
if medium_unit:
questions = questions.filter(unit__medium_unit=medium_unit)
if small_units:
questions = questions.filter(unit__small_unit__in=small_units)
if search_term:
questions = questions.filter(Q(content__icontains=search_term) | Q(number__icontains=search_term))
# Pagination
paginator = self.pagination_class()
result_page = paginator.paginate_queryset(questions, request)
serializer = QuestionSerializer(result_page, many=True)
return paginator.get_paginated_response(serializer.data)
🫨처음에 Delimter를 " , " (comma) 로 설정해 놓는 실수를 범해 소단원에
"06-4 삼각함수의 최대, 최소와 주기" 와 같이 comma가 존재한다면 "06-4 삼각함수의 최대", " 최소와 주기" 를 small_units로 받아오는 trouble이 발생하였다 ..!!!
Delimiter는 잘 사용하지 않는 "|" 같은 기호를 사용하자 !! (🐞디버깅은 신이야)
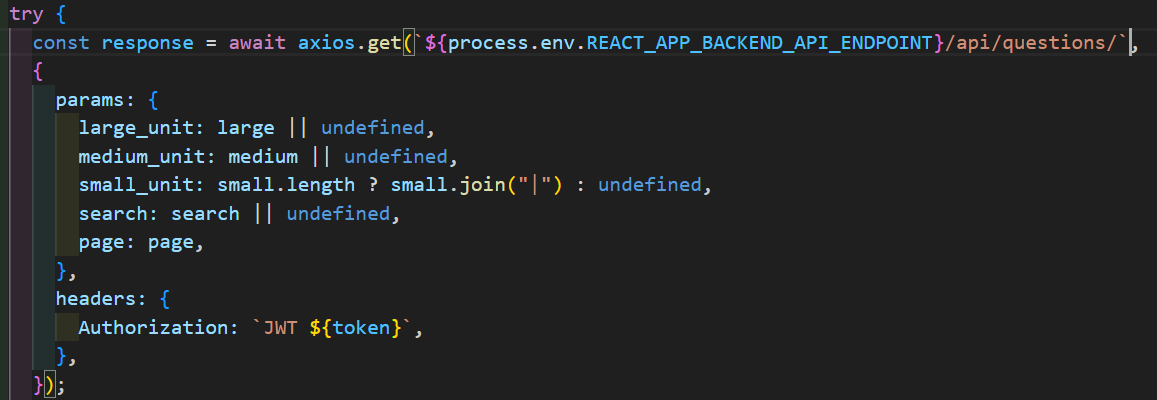
우선, FE 에서는 위와 같이 "|" 를 Delimiter로 보내는게 우선이다 !!
알게 된 사실
- Delimter는 잘 안쓰는 "|" 와 같은 기호를 사용하자 !!
- Pandas로 손쉽게 CSV 파일을 커스터마이징이 가능하다.
- Local server 에서 data를 가져오는 속도는 굉장히 느리다. 하지만 prod 서버에서 가져 오는 속도는 엄청 빨랐다. (EC2, RDS, AWS LET'S GO)
TODO
DOCKER FILE로 간소화된 OS를 올려놓기 때문이라고 생각했다. Docker에 대해 깊이 공부해보자.


💻