
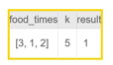
1. 문제
- food_times 각 음식을 먹는데 걸리는 시간이 리스트로 들어온다.
- k , 방송이 종료되는 시간 (k초 이후 방송이 종료된다.)
- 방송이 중단된 이후, 복구 되었을 때, 몇 번째 음식부터 다시 먹으면 되는지 구하라.
- 만약, 더 섭취해야할 음식이 없다면 -1을 반환하라.
제한사항

입출력 예시
2. 아이디어
- 스스로는 전혀 아무것도 생각해낼 수 없었다.
- 유튜브의 친절한 설명과 저자의 코드를 리뷰해보는 것을 목표로 한다.
- 참조 : https://www.youtube.com/watch?v=zpz8SMzwiHM
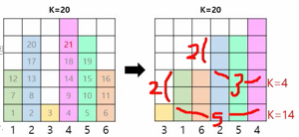
왼쪽의 그림에서 음식이 6가지고 그것의 먹는 시간을 리스트로 하면 [3, 5, 1, 6, 5, 3]이 된다.
k초 이후에 방송이 종료된다고 하고, 차례대로 먹는 시간을 써넣은 것이다. 이렇게 전체를 탐색하는 방법도 있을 수 있으나, 이렇게 하면 효율성 테스트를 통과하지 못할 것이다.
그래서 오른쪽의 그림처럼 음식을 먹는데 걸리는 시간으로 정렬을 하고 생각한다. 시간으로 정렬하고 나면, 음식을 먹는데 걸린 시간을 덩어리화 해서 연산할 수 있게 된다. k시간내에 처리되는 덩어리들을 먼저 처리한 후 남은 시간들을 처리하여 연산을 줄이는 것이 이 문제의 핵심일 것이다.
그림에서 가로는 음식의 수이고, 세로는 음식을 먹는데 걸리는 시간이다. 가장 아래단 먹는 시간 1, 음식의 수 6 이를 곱한 값 (1 x 6 = 6 )을 시간 k = 20에서 빼면, 남은 시간은 20-6 = 14 가 된다. 두번째단은 첫번째단의 높이와의 차이와 남은 음식수를 곱한 값 (2 x 5 = 10)을 남은 시간 k = 14에서 빼면, 남은 시간은 14 - 10 = 4 가 된다. 세번째단 덩어리는 6으로 남은 시간 k = 4 보다 크기 때문에 덩어리째로 처리할 수 없다.
다른 음식들은 먹고, 두번째 네번째 다섯번째 음식이 [2, 3, 2]와 같이 남은 상황이다. 이를 처리하기 위해서, 이전에 시간순으로 정렬해뒀던 음식들을 다시 음식의 순서대로 재정렬을 한다. 그런 다음 남은 시간을 음식의 수로 나눈 몫이 남은 음식리스트에서 다음 음식의 인덱스가 된다.
이를 참조한 후 저자의 설명을 보았을 때 더 잘 이해가 되었다. 구현 방식은 다르지만 핵심적인 생각은 같다.
3-1. 예제 코드1 (유튜브 version)
def solution(food_times, k):
foods = []
n = len(food_times)
for i in range(n):
foods.append((food_times[i], i+1))
foods.sort()
pretime = 0 # 이전 음식을 다 먹는 시간
for i , food in enumerate(foods):
diff = food[0] - pretime # 이전 음식과 현재 음식 먹는 시간 차이
if diff != 0: # 차이가 없으면 스킵
spend = diff * n
if spend <= k: # 남은 시간내에 음식이 먹어지면
k -= spend
pretime = food[0] # 이전 음식 재설정
else : # 남은 시간내에 음식이 먹어지지 않으면
k %= n # 남은시간을 음식수로 나눈 나머지를 인덱스로
sublist = sorted(foods[i:], key = lambda x : x[1])
# 음식순서대로 재정렬
return sublist[k][1]
n -= 1
return -1 3-2. 예제 코드2 (저자 version)
import heapq
def solution(food_times, k):
if sum(food_times) <= k :
return -1
q = []
for i in range(len(food_times)):
heaqq.heappush(q, (food_times[i], i+1))
sum_value = 0 # 음식 먹는데 사용한 시간
previous = 0 # 직전 음식을 다 먹는데 걸리는 시간
length = len(food_times) # 남은 음식의 수
while sum_value + (q[0][0] - previous * length) <= k :
now = heapq.heappop(q)[0]
sum_value += (now - previous) * length
length -= 1
previous = now
result = sorted(q, key = lambda x : x[1])
return result[(k - sum_value) % length][1]느낀점
- 카카오 코딩테스트 통과하려면 다시 태어나야 할 듯.
참고
- 이것이 취업을 위한 코딩테스트다 with 파이썬
- 유튜브 채널 ezsw , https://www.youtube.com/watch?v=zpz8SMzwiHM
