처음
연결리스트 (LinkedList)는 List를 구현하지만, 배열, List 등의 다른 자료구조와 달리, 리스트지만 각각의 원소가 연속성을 갖지 않는다. 쉽게 말하자면 모든 원소가 통째로 저장되어있지 않다. 원소는 node로, 자신의 다음 원소의 주소를 참조하고, 참조된 원소 또한 다음 원소의 주소를 참조하는 것이다. 따라서 모든 노드들은 메모리 상에 독립적으로 저장된다.
이렇게 해도 array, list와 같이 선형 구조인데, LinkedList를 사용하는 이유는 무엇인가 하면, 위와 같은 저장 방식으로 인해 생기는 장점들이 존재한다.
LinkedList의 특징
-
데이터의 추가, 삭제에 유리하다.
ArrayList의 경우 중간에 있는 데이터를 삭제/추가하기 위해서는 그 다음부터의 원소를 통째로 옮겨야한다. 이 과정에서 O(n)의 시간복잡도가 발생하는 반면에, LinkedList는 node를 삭제/추가한 뒤, node들의 주소 참조관계만 수정해주면 되는 것이다. (O(1))
예를 들어, [1,2,3,4,5]의 list에서 3을 삭제할 때는, 바로 직전 원소인 2에게, 3이 참조하는 다음 원소의 주소를 넘겨주고, 원소 3을 메모리 상에서 삭제하기만 하면 되는 것이다. 데이터를 추가하는 경우도 이와 비슷하다. -
특정 원소로의 접근 (검색 등)에 불리하다.
통째로 저장되어있는 ArrayList 등은 index로 바로 접근할 수 있는 반면에, LinkedList는 모든 원소가 불연속적으로 존재한다. 따라서 특정 원소로 접근하기 위해서는 처음부터 모든 원소들의 참조 관계를 거쳐가야만 한다. (O(n))
이러한 특징과 관련한 추가적인 내용으로, 배열에서 추가/삭제하려는 원소의 위치에 따라서도 시간복잡도가 달라진다. 원소가 앞쪽에 있을수록 ArrayList는 처리해야할 일이 많은 것이고 (요소의 위치 변경이 어렵기 때문), 반면에 원소가 뒤쪽에 있을 수록 LinkedList가 처리해야할 일이 많아진다.(요소에 접근이 어렵기 때문)
그래서 우리는, 반복적으로 배열 중간의 요소들을 수정/삭제 해야하는 경우에 LinkedList를 활용해야할 것이다.
중간
1. BOJ1406 - 에디터
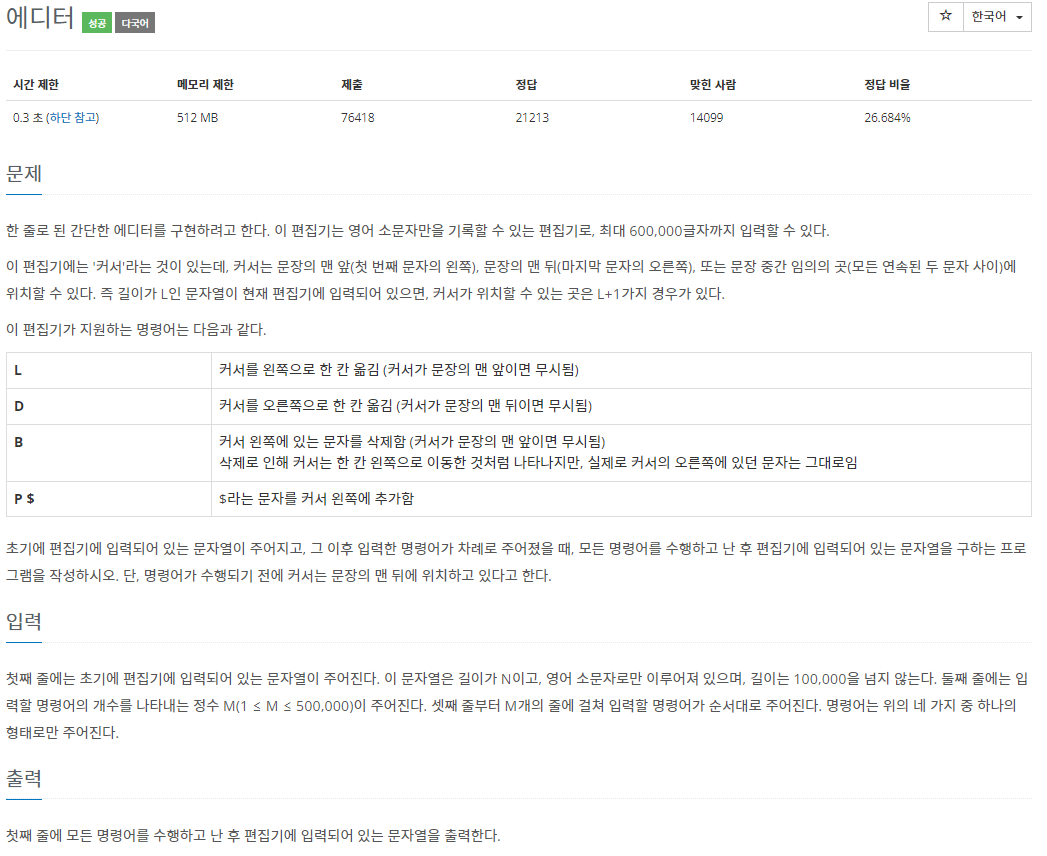
입력하는 명령어가 최대 500000이기 때문에, ArrayList로 구현한다면 시간복잡도가 엄청나게 높을 것이다. 따라서 LinkedList를 이용해서 해결해야 한다.
public class BOJ1406 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String str = br.readLine();
List<Character> result = new LinkedList<>();
for (char x : str.toCharArray()) {
result.add(x);
}
ListIterator<Character> cursor = result.listIterator();
while (cursor.hasNext()) cursor.next();
int commandNum = Integer.parseInt(br.readLine());
String[] coms = new String[commandNum];
char tmpCom;
char tmpChar;
for (int i = 0; i < commandNum; i++) {
coms[i] = br.readLine();
}
for (String curCom : coms) {
tmpCom = curCom.charAt(0);
if (tmpCom == 'L') {
if (cursor.hasPrevious()) cursor.previous();
} else if (tmpCom == 'D') {
if (cursor.hasNext()) cursor.next();
} else if (tmpCom == 'B') {
if (!cursor.hasPrevious()) continue;
cursor.previous();
cursor.remove();
} else {
tmpChar = curCom.charAt(2);
cursor.add(tmpChar);
}
}
Iterator<Character> iterator = result.iterator();
while (iterator.hasNext()) {
bw.write(iterator.next());
}
bw.close();
}
}
LinkedList와 ListIterator를 활용했다.
2. BOJ5397 - 키로거
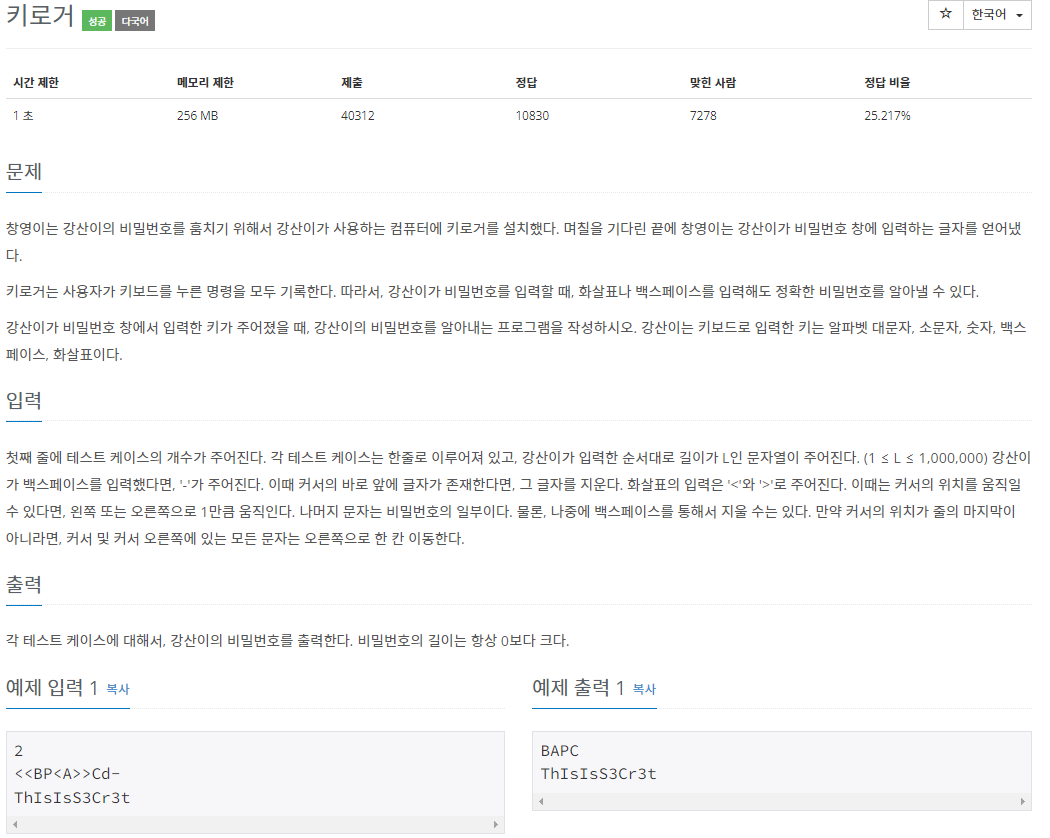
첫 번째 예제와 비슷한 문제였다. 특정한 문자열을 중간에서 반복적으로 수정/추가해야하기 때문에 linkedList가 적합할 것이다.
public static void main(String[] args) throws IOException {
int testCaseNum = Integer.parseInt(br.readLine());
String[] testCase = new String[testCaseNum];
for (int i = 0; i < testCaseNum; i++) {
testCase[i] = br.readLine();
}
List<Character> tmpPassword;
ListIterator<Character> tmpIterator;
String answer;
for (int i = 0; i < testCase.length; i++) {
tmpPassword = new ArrayList<>();
tmpIterator = tmpPassword.listIterator();
answer = "";
for (char x : testCase[i].toCharArray()) {
if (x == '<') {
if (tmpIterator.hasPrevious()) tmpIterator.previous();
} else if (x == '>') {
if (tmpIterator.hasNext()) tmpIterator.next();
} else if (x == '-') {
if (tmpIterator.hasPrevious()) {
tmpIterator.previous();
tmpIterator.remove();
}
} else {
tmpIterator.add(x);
}
}
for (Character x : tmpPassword) {
answer += x;
}
bw.write(answer);
bw.newLine();
}
}하지만 똑같은 방법으로 풀면 시간 초과된다. 테스트케이스가 여러개에다가, 명령어의 최대 길이도 이전 문제의 두 배이기 때문이다.
answer 문자열을 만드는 방식도 비효율적이라는 것을 알게 되었다. 이것이 시간초과의 주요한 원인이었던 것 같다. string끼리 더하고 빼는 연산은 비효율적이다. 연산이 일어날 때마다 새로운 문자열을 생성하게 되기 때문이다. 길이 n의 문자열과 길이 k의 문자열을 더할 때의 시간복잡도는 O(n+k)인 반면에, stringBuilder 객체를 이용하면 O(1)로 문제를 해결할 수 있다. StringBuilder는 ArrayList처럼, 내부의 char배열을 갖고 이것을 동적으로 변화시키기 때문에, 문자열을 추가하는 데 시간복잡도가 낮다.
public static void main(String[] args) throws IOException {
//스택 활용한 방법
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int testCaseNum = Integer.parseInt(br.readLine());
String[] testCase = new String[testCaseNum];
for (int i = 0; i < testCaseNum; i++) {
testCase[i] = br.readLine();
}
Stack<Character> leftOfCursor = new Stack<>();
Stack<Character> rigthOfCursor = new Stack<>();
String answer;
for (int i = 0; i < testCase.length; i++) {
answer = "";
for (char x : testCase[i].toCharArray()) {
if (x == '<') {
if (!leftOfCursor.isEmpty()) {
rigthOfCursor.push(leftOfCursor.pop());
}
} else if (x == '>') {
if (!rigthOfCursor.isEmpty()){
leftOfCursor.push(rigthOfCursor.pop());
}
} else if (x == '-') {
if (!leftOfCursor.isEmpty()) {
leftOfCursor.pop();
}
} else leftOfCursor.push(x);
}
StringBuilder pwd = new StringBuilder();
while (!leftOfCursor.isEmpty()) {
rigthOfCursor.push(leftOfCursor.pop());
}
while (!rigthOfCursor.isEmpty()) {
pwd.append(rigthOfCursor.pop());
}
System.out.println(pwd);
}
}
두 번째 풀이는, StringBuilder를 이용해 정답 문자열을 만들고, 알고리즘 구현은 두 개의 stack을 이용했다. 커서 앞쪽의 문자들을 저장하는 스택, 뒷쪽의 문자들을 저장하는 스택으로 구분해 해결했다.
위에서 언급한 문제를 해결한다면, 시간은 전자의 경우가 더 빠를 것이라고 생각한다. ListIterator를 활용했기 때문에 LinkedList의 탐색 문제를 해결했고, 커서 이동에서 스택은 두 번의 연산이 필요하기 때문에 여기에서 조금의 추가 연산이 있기 때문이다.
3. BOJ1158 - 요세푸스 문제
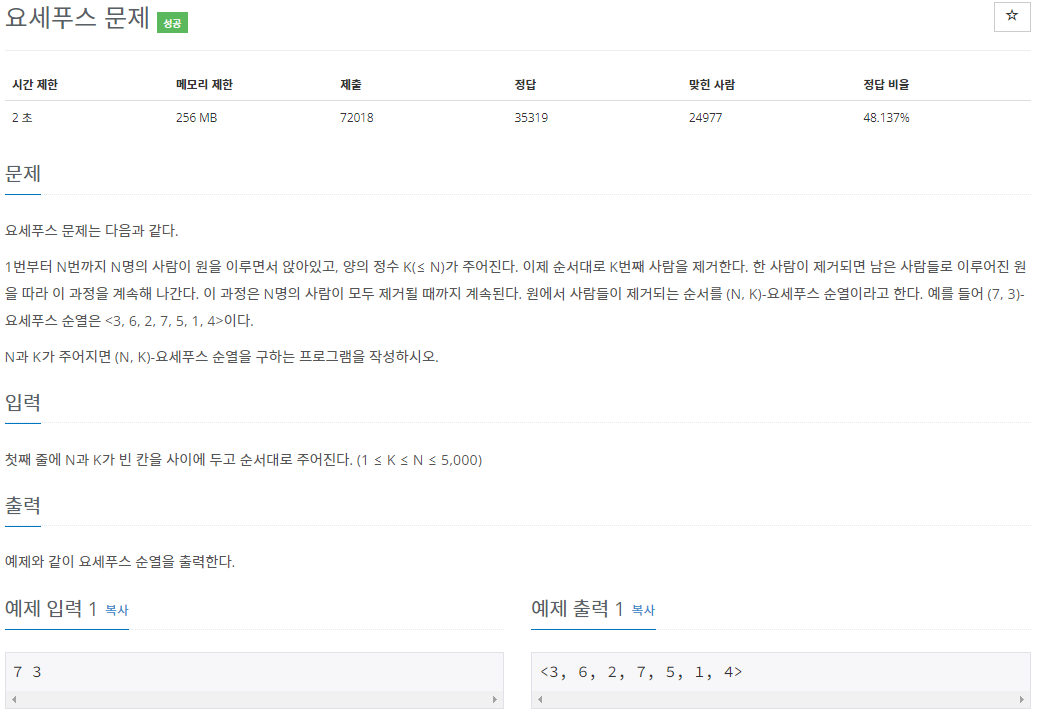
문제를 보고 처음 떠올린 해결 방법은 queue를 활용하는 것이었다. queue를 활용하는 게 가장 직관적이면서 빠를 것이라고 생각했지만, 연결리스트를 활용한 구현을 해봤다.
public class BOJ1158 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] a = br.readLine().split(" ");
int K = Integer.parseInt(a[1]);
int N = Integer.parseInt(a[0]);
LinkedList<Integer> people = new LinkedList<>();
List<Integer> answer = new ArrayList<>();
for (int i = 1; i <= N; i++) {
people.add(i);
}
int cnt = 0;
while (!people.isEmpty()) {
Iterator<Integer> iterator = people.iterator();
while (iterator.hasNext()) {
int tmp = iterator.next();
if (++cnt == K) {
answer.add(tmp);
iterator.remove();
cnt = 0;
continue;
}
}
}
String answer2 = answer.toString();
String answer3 = answer2.substring(1, answer2.length() - 1);
System.out.println("<" + answer3 + ">");
}
}
리스트가 끝날 때마다 iterator를 새로 생성해서 게속해서 검사하는 방식으로 구현했다. 시간 초과였다. iterator를 계속해서 생성해야하고, linkedList의 길이가 0이 될 때까지 원소를 하나하나 검사했기 때문에 비효율적이다.
public class BOJ1158Queue {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] a = br.readLine().split(" ");
int K = Integer.parseInt(a[1]);
int N = Integer.parseInt(a[0]);
Queue<Integer> people = new LinkedList<>();
for (int i = 1; i <= N; i++) {
people.offer(i);
}
StringBuilder sb = new StringBuilder();
sb.append("<");
while (people.size() > 1) {
for (int i = 0; i < K-1; i++) {
people.offer(people.poll());
}
sb.append(people.poll()).append(", ");
}
sb.append(people.poll()).append(">");
System.out.println(sb);
br.close();
}
}처음 생각한 queue를 활용한 방법이다. iterator로 모든 원소를 검사하는 과정이 생략되는 대신, 매번 원소를 빼고 넣는 과정이 추가됐다. 또 for문을 활용해서 counter를 매번 조건문으로 확인하는 과정을 없앴다. 이 아이디어는 이 블로그에서 참고했다.
사실 가장 깔끔한 방법은, 간단하게 원형 연결리스트를 구현해서 해결하는 것이었지만, 시간 측면에서 알고리즘 테스트에서는 이 방법이 어려울 것 같았다.
2. 손코딩 문제 2
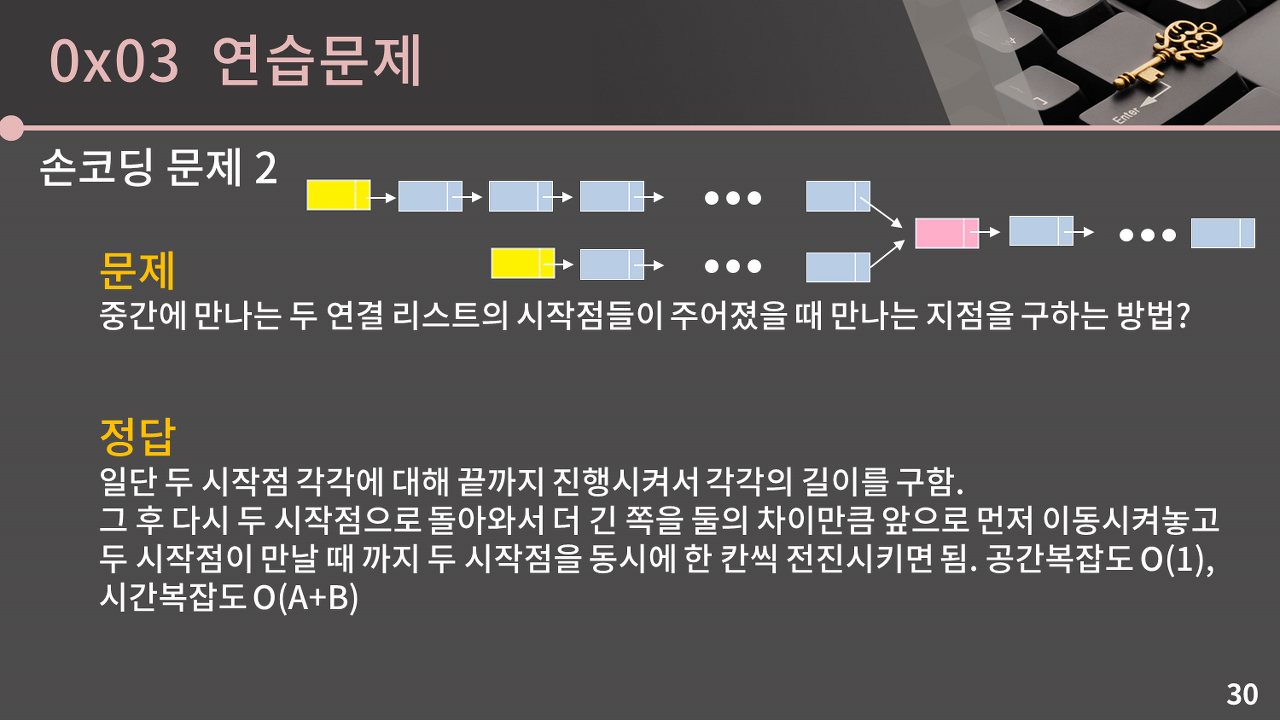
생각한 해결 방법
1. 모든 노드의 주소를 저장해가면서 끝까지 도달한 뒤, 같은 주소 검사
2. 두 연결리스트 모두 마지막 인덱스로 iterator를 이동한 뒤, 주소가 달라지는 지점을 확인한다. (공간복잡도는 낮지만 시간복잡도는 높은듯..) -> 양방향 연결 리스트여야 함.
3. 길이를 구해놓고, 더 긴 리스트를 길이의 차이만큼 이동시킨 뒤 만날 때까지 전진하며 검사
3. 손코딩 문제 3

생각한 해결 방법
모든 주소를 저장하는 방법 외에 있나?? -> floyd's cycle-finding algorithm
끝
연결리스트에 대한 개괄적인 내용을 복습하고 관련된 문제들을 풀어봤다. 연결리스트의 장/단점을 잘 파악하고 적재적소에 잘 활용해야할 것이다. 예제들을 보면 알겠지만, 연결리스트를 사용하는 경우는 반복적으로 배열 중간의 원소들을 수정해야하는 경우인데, 이 때는 stack이나 queue 등으로도 해결할 수 있는 경우가 많다. 가능한 방법을 유연하게 생각하고 때에 따라서 적용하는 것이 좋은 방법일 것 같다.
연습 문제 출처 : baaaaarkingDog 블로그
