AI School_0404TIL


1950년대에 인공지능 개념 처음 나오고
1980년대에 머신러닝!(데이터를 학습시키고 수학적 알고리즘 적용)
2010년 수학을 사람의 뇌처럼 만들고, 스스로 문제를 학습하게 해보자
사람이 아니라 기계가 학습을 해야한다.
컴퓨터 언어로 배워야 한다(데이터를)
학습에 필요한 알고리즘이 필요하다!(수학)
바로 이 알고리즘을 사람이 만드는 것이다.

머신러닝은 왼쪽과 같은 모습이다.
우리는 f를 만드는 사람이 될 것!

컴퓨터 사이언스는 이렇지만..


a와 b, c는 알지만
f는 너가 알아서 찾아내라! 라고 하는 것이 머신러닝이다.

머신러닝과 컴퓨터사이언스의 차이점

머신러닝의 종류!

머신러닝 종류
1)지도학습 : 문제와 답을 알려준 뒤 학습시키는 것

feature와 Label을 주고 학습 시킨 뒤,
분류를 해본다 (새로운 사진이 들어오면 고양이일 확률이 70%..?)

회귀 알고리즘

머신러닝 종류
2)비지도 학습 : 문제만 제공한다!

이상징후 감지 알고리즘 :
카드사에서 이 알고리즘을 많이 사용하는데,
사용 한도 임계치를 넘어가면 카드의 거래를 중단시킨다.(콜센터에서 연락함)

군집 :
선을 잔뜩 그어서 라인을 만든 후
비슷한 것들끼리 모은다

머신러닝 종류
3)강화 학습
보상을 제공하여 행동을 강화하기(배변패드에 똥...!)


한번씩 섞어주는게 좋은 랜덤 스플릿이다
점심시간 이후
오렌지 데이터



QT는 ui를 만드는 라이브러리
오렌지데이터를 깐 뒤
파일을 넣고
타이타닉.csv를 넣었다

데이터 시각화하기!

Tree알고리즘 모델을 예측에 넣고
데이터 또한 예측에 넣은 값

CA가 정확도라고 보면 된다.


오렌지데이터마이닝의 주요 기능!

회귀 분석 알고리즘
점을 찍고 평균점을 선으로 통과시킨다


MAE (Mean Absolution Error) : 절대 오차

CA : 정확도

MAE : 전체 에러의 평균값
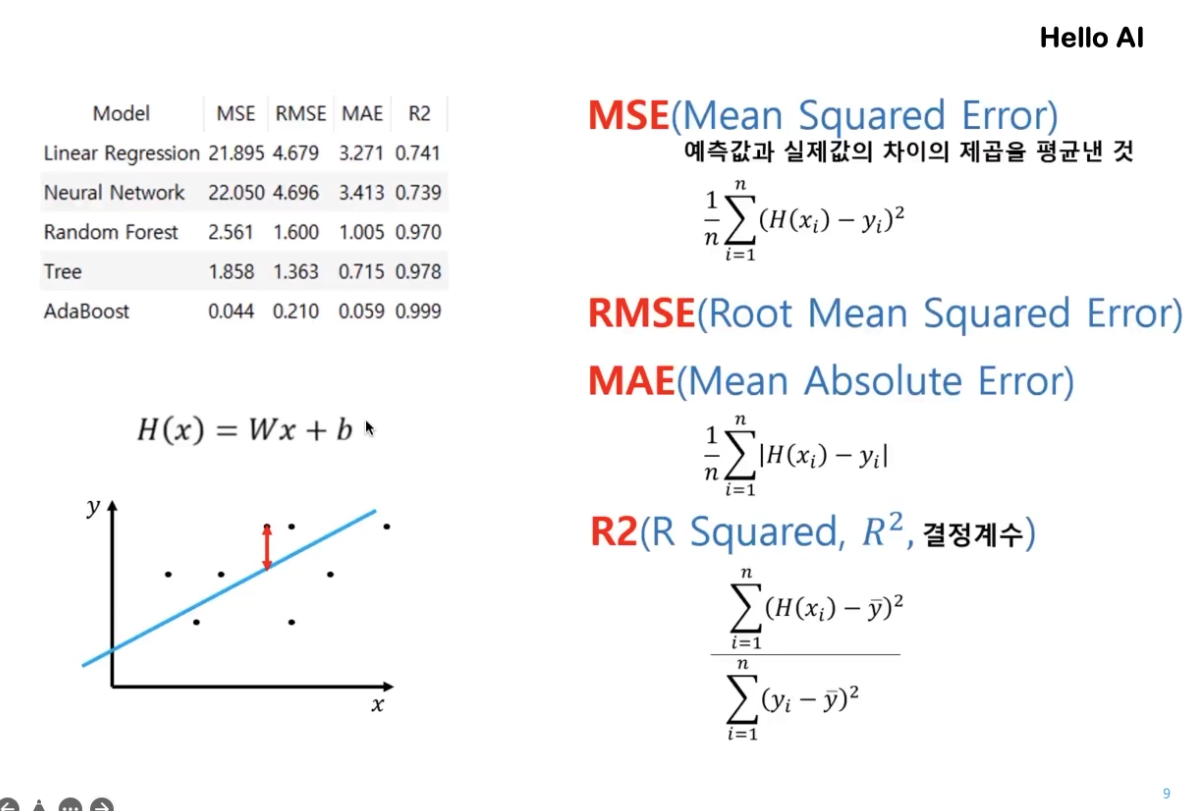
MSE (Mean Square Error) : 에러의 총 합을 제곱해서 본다
