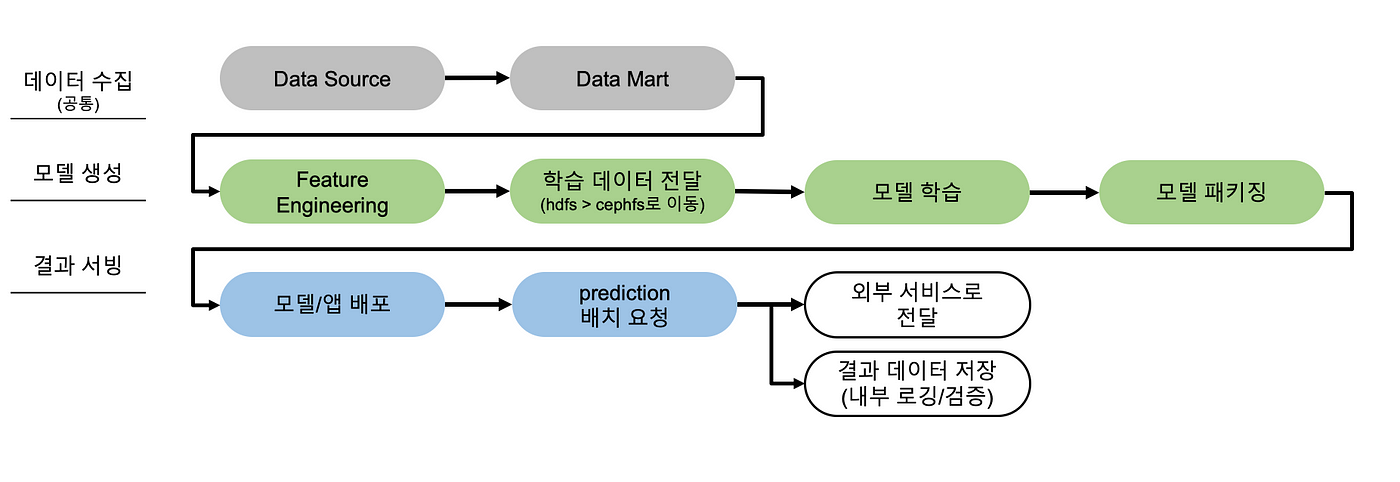
데이터를 처리하거나 작업을 수행할 때 여러 단계를 연결하여 효율적으로 처리하는 설계패턴
한 단계의 출력을 다음 단계의 입력으로 사용
주요 개념
- 단계
특정 작업을 수행하며, 이전 단계의 출력을 받아 처리한 결과를 다음 단계로 전달 - 데이터 흐름
데이터는 각 단계 사이를 흐르며, 작업이 완전히 완료될 때까지 진행됨 - 병렬 처리 가능
각 단계는 독립적으로 동작 가능
특징
- 모듈화 : 각 단계는 다른 단계에 영향을 주지 않음
- 재사용성 : 동일한 파이프라인을 여러 작업에서 재사용 가능
- 유연성 : 단계를 추가하거나 변경하여 새로운 기능 쉽게 구현 가능
- 효율성 : 데이터를 순차적으로 처리하거나 병렬로 처리 가능
활용사례
- 데이터 처리 : ETL
추출(Extract) → 정제(Transform) → 로드(Load) - 소프트웨어 개발 : CI/CD 파이프라인
빌드 → 테스트 실행 → 배포 - 컴퓨터 아키텍쳐 : CPU 명령어 파이프라인
명령어 가져오기 → 디코딩 → 실행 → 쓰기 - Unix/Linux 명령어
쉘에서 명령어의 출력을 다음 명령어의 입력으로 전달 - 머신러닝 워크 플로
데이터 전처리 → 특징 추출 → 모델 학습 → 모델 평가
장점
- 성능 향상 : 병렬처리와 작업 분할로 효율적인 작업 수행
- 유지보수 용이 : 모듈화된 설계로 각 단계의 수정이 다른 단계에 영향을 주지 않음
- 확장성 : 새로운 단계를 쉽게 추가 가능
단점
- 복잡성 증가 : 많은 단계가 포함되면 전체 파이프라인을 관리하는 데 어려움
- 단일 실패 지점 : 한 단계가 실패하면 전체 파이프라인이 중단될 수 있음
- 리소스 사용량 증가 : 각 단계가 독립적으로 동작하면 메모리와 CPU 사용량이 증가할 수 있음
