이번장에서는 카프카 스트림즈 API(Streams API)에 대해서 알아보겠습니다.
카프카는 대규모 메시지를 저장하고 빠르게 처리하기 위해 만들어진 플랫폼입니다. 처음에는 메시지를 다른 프로세스나 애플리케이션에 전달하기 위해 사용되었지만, 카프카의 강력한 성능으로 인해 연속된 메시지인 스트림을 처리하는 데도 점차 사용되기 시작했습니다. 카프카 스트림즈 API를 이용하면 스파크(Spark)나 스톰(Storm)과 같은 별도의 스트리밍 엔진을 사용하지 않고도 간단하게 실시간 분석을 수행할 수 있습니다.
스트림즈를 본격적으로 알아보기전에 스트림 프로세싱과 배치 프로세싱에 대해 알아보겠습니다.
1. 스트림 프로세싱, 배치 프로세싱
스트림 프로세싱(Stream Processing)은 데이터들이 지속적으로 유입되고 나가는 과정에서 이 데이터에 대한 분석이나 질의를 수행하는 것을 의미합니다. 데이터가 분석 시스템이나 프로그램에 도달하자마자 처리하기 때문에 스트림 프로세싱은 실시간 분석(Real-time Analysis)라고 불리기도 합니다.
이와 대비되는 배치 프로세싱(Batch Processing) 또는 정적 데이터 프로레싱(Data-at-rest Processing)이 있습니다. 이는 이미 저장된 데이터를 기반으로 분석이나 질의를 수행하고 특정 시간에 처리하는 특징이 있습니다. 이런 처리방법은 이전에 사용하던 처리 방식으로 오늘날은 실시간성과 정확성을 모두 높이는 형태로 스트림 프로세싱을 발전시켰습니다.
1-1. 스트림 프로세싱의 장점
스트림 프로세싱의 장점은 아래와 같습니다.
- 애플리케이션이 이벤트에 즉각적으로 반응 가능하다(스트림 프로세싱을 통한 분석은 항상 최신의 데이터를 반영합니다).
- 데이터를 저장한 후에 분석을 하지 않으므로 정적 분석보다 더 많은 데이터를 분석할 수 있다.
- 시간에 따라 지속적으로 유입되는 데이터 분석에 최적화 되어 있다.
- 대규모 공유 데이터베이스에 대한 요구를 줄일 수 있어서 인프라에 독립적으로 수행할 수 있다.
2. 상태 기반과 무상태 스트림 처리
스트림 처리르 하다 보면 이전 스트림을 처리한 결과를 참조해야 할 경우가 있습니다. 이런 처리 방식을 상태 기반(stateful) 처리라고 합니다. 애플리케이션에서 각각의 이벤트를 처리하고 그 결과를 저장할 상태 저장소(state store)가 필요합니다. 스트림 처리 애플리케이션이 이 저장소를 관리하면 내부 상태 저장소라고 하고, 스트림 처리 애플리케이션이 DB와 같이 별도의 상태 저장소를 사용하는 것을 외부 상태 저장소라고 합니다.
이와 반대로 무상태(stateless) 스트림 처리는 이전 스트림의 처리 결과와 관계 없이 현재 애플리케이션에 도달한 스트림만 기준으로 처리하는 것을 말합니다.
3. 카프카 스트림즈
카프카 스트림즈는 카프카에 저장된 데이터를 처리하고 분석하기 위해 개발된 클라이언트 라이브러리입니다. 카프카 스트림즈는 이벤트 시간과 처리 시간을 분리해서 다루고 다양한 시간 간격 옵션을 지원하기에 실시간 분석을 간단하지만 효율적으로 진행할 수 있습니다.
3-1. 카프카의 특징
카프카의 특징은 아래와 같습니다.
- 간단하고 가벼운 클라이언트 라이브버리이기 때문에 기존 애플리케이션이나 자바 애플리케이션에서 쉽게 사용할 수 있다.
- 시스템이나 카프카에 대한 의존성이 없다.
- 이중화된 로컬 상태 저장소를 지원한다.
- 카프카 브로커나 클라이언트에 장애가 생기더라도 스트림에 대해선 1번만 처리되도록 보장한다.
- ms 단위의 처리 지연을 보장하기 위해 한번에 한 레코드만 처리한다.
- 간단하게 만들 수 있도록 고수준의 스트림 DSL(Domain Specific Language)을 지원하고, 저수준의 프로세싱 API도 제공한다.
3-2. 프로세서 토폴로지
카프카 스트림즈는 스파크 스트림이나 스톰과 같이 스트림 처리를 하는 프로세스들이 서로 연결되어 토폴로지(topology)를 만들어 처리하는 API입니다.
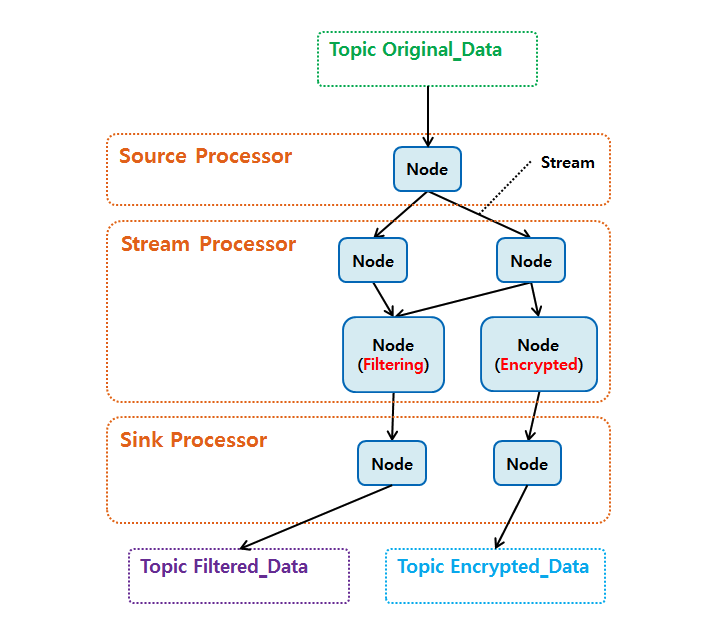
프로세서 토폴로지는 각각 아래와 같습니다 [1].
- 소스 프로세서 (Source Processor)
소스 프로세서는 토폴로지의 시작 노드이며,
데이터를 처리하기 위해 최초로 선언해야 하는 노드입니다.
카프카와 연결된 프로세서이며, 하나 이상의 토픽에서 데이터를 가져오는 역할을 합니다. - 스트림 프로세서 (Stream Processor)
스트림 프로세서는 다른 프로세서(소스 프로세서, 스트림 프로세서)가 반환한 데이터를 처리하는 역할을 합니다. - 싱크 프로세서 (Sink Processor)
싱크 프로세서는 토폴로지의 마지막 노드이며,
데이터 전달을 위해 마지막에 선언해야 하는 노드입니다.
카프카와 연결된 프로세서이며, 데이터를 카프카의 특정 토픽으로 저장하는 역할을 합니다.
카프카 스트림즈는 이와 같은 프로세서들을 만드는 데 2가지 방법을 제공합니다. 하나는 카프카 스트림즈 DSL에서 데이터를 처리할 때 공통적으로 필요한 map, filter, join, aggregations 와 같은 데이터 프로세싱 메서드를 제공하는 것이며, 다른 하나는 프로세서 API를 제공해서 저수준의 처리를 직접할 수 있게 하는 것입니다.
3-3. 카프카 스트림즈 아키텍쳐
카프카 스트림즈에 들어오는 데이터는 카프카 토픽의 메시지입니다. 이 두 관계는 아래와 같습니다.
- 각 스트림 파티션은 카프카의 토픽 파티션에 저장된 정렬된 메시지입니다.
- 스트림의 데이터 레코드는 카프카 해당 토픽의 메시지(key-value)입니다.
- 데이터 레코드의 키를 통해 다음 스트림(=카프카 토픽)으로 전달됩니다.
카프카 스트림즈는 입력 스트림의 파티션 개수만큼 태스크를 생성합니다. 각 태스크에는 입력 스트림 파티션들이 할당되고, 이것은 한번 정해지면 입력 토픽의 파티션에 변화가 생기지 않는 한 변하지 않습니다. 태스크는 사용자가 지정한 토폴로지를 자신에게 할당된 파티션을 기반으로 실행합니다.
카프카 스트림즈는 사용자가 스레드의 개수를 지정할 수 있게 해 주며, 1개의 스레드는 1개 이상의 테스크를 처리할 수 있습니다.
카프카 스트림즈는 더 많은 스레드를 띄우거나 인스턴스를 생성하는 것만으로도, 토폴로지를 복제해서 카프카 파티션을 서로 나눈 다음에 효과적으로 병렬 처리를 수행할 수 있습니다. 이 경우 여러 개의 스트림에 대해 각 파티션을 나누는 것은 별도의 스트림즈 코디네이션 없이 카프카 코디네이션 방식을 사용합니다.
[REFERENCE]
해당 글의 모든 레퍼런스는 "카프카, 데이터 플랫폼의 최강자" (고승범, 공용준 지음)을 알립니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."

46개의 댓글

Great article Lot's of information to Read...Great Man Keep Posting and update to People..Thanks S9 Game

This is my first visit to your web journal! We are a group of volunteers and new activities in the same specialty. Website gave us helpful data to work. Предложен онлайн сайт
Discover the excitement of IDN poker online with Panenpoker, Indonesia's trusted platform. Offering a variety of card betting games, exciting bonuses, and events, Panenpoker ensures a complete gambling experience. Play anytime with mobile access. Join now and start winning with Panenpoker.panenpoker
Top Verification for Toto Sites: The Eat-and-Run Verification Community provides safe, verified Toto sites. Our professional analysis and user reviews prevent fraud, offering a secure gaming environment.먹튀사이트 모음
Nice post. I was checking constantly this blog and I’m impressed! Extremely useful info specially the last part I care for such information a lot. I was seeking this certain info for a long time. Thank you and good luck. link map
ALEXISTOGEL offers precise togel predictions using advanced analytics and comprehensive historical data. Our numbers for Toto Macau, Hongkong, and Singapore are regularly updated to keep you informed. Join ALEXISTOGEL to access the best predictions, special bonuses, and a superior togel playing experience. prediksi togel
Ace Stills is a leader in manufacturing distillation equipment, offering custom solutions for all types of distilleries. Our expert-designed systems cater to both new and existing operations, providing equipment for producing whisky, gin, and more. With sizes ranging from 50 to 5000 liters, find your perfect still with us. Ace Alambiques

Thank you so much for creating such a beautiful website. I originally came to know the automotive world. I can easily understand everything in the article. I hope to see more content in the future. Can you help me with information about Bangladesh motorcycles?
Thank you so much for creating such a beautiful website. I originally came to know the automotive world. I can easily understand everything in the article. I hope to see more content in the future. Can you help me with information about Bangladesh motorcycles?
Thank you so much for creating such a beautiful website. I originally came to know the automotive world. I can easily understand everything in the article. I hope to see more content in the future. Can you help me with information about [url=https://deshibiker.com/]Bangladesh motorcycles[/url] Bangladesh motorcycles?
Thank you so much for creating such a beautiful website. I originally came to know the automotive world. I can easily understand everything in the article. I hope to see more content in the future. Can you help me with information about [url=https://deshibiker.com/]Bangladesh motorcycles[/url] Bangladesh motorcycles?
Thank you so much for creating such a beautiful website. I originally came to know the automotive world. I can easily understand everything in the article. I hope to see more content in the future. https://deshibiker.com/
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free. best storage company in dubai
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place.. 슬롯
Nice post. I was checking constantly this blog and I am impressed! Extremely helpful information specially the last part I care for such info a lot. I was seeking this particular information for a very long time. Thank you and good luck. 출장홈타이
Superior Place, My organization is a great believer during ad opinions regarding online websites that will let the webpage novelists recognize that they’ve put in an item worthwhile that will the online market place! 코인커뮤니티

I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post익스피디아 할인코드
Plan your entire trip with Trip.com, offering bookings for hotels, flights, tours, train tickets, and car rentals. Manage all your travel reservations easily in one place. Experience the convenience and efficiency of Trip.com, ensuring a seamless travel experience for all your needs.마드리드 에어비엔비
Fantastic write-up, journeyed onward in addition to book-marked your web site. When i can’t hang on to learn to read far more by people.트립닷컴 할인코드
Fantastic write-up, journeyed onward in addition to book-marked your web site. When i can’t hang on to learn to read far more by people.아고다 할인코드
Nice to be visiting your blog again, it has been months for me. Well this article that i’ve been waited for so long. I need this article to complete my assignment in the college, and it has same topic with your article. Thanks, great share. https://sites.google.com/view/mooncakespecialtaste/
We have sell some products of different custom boxes.it is very useful and very low price please visits this site thanks and please share this post with your friends. 트립닷컴 할인코드 9월

Trip.com provides a complete travel booking service, including hotels, flights, tours, train tickets, and car rentals. Manage all your reservations effortlessly in one place. Enjoy the convenience and efficiency of Trip.com, ensuring a hassle-free travel experience for all your needs. 런던숙소위치추천
I would say that this is a a great post of a great person, i'm pleased to see this.
I would say that this is a a great post of a great person, i'm pleased to see this. 야놀자 쿠폰
Thank you for your submit and also fantastic suggestions.. also My partner and i furthermore believe work will be the main aspect of acquiring accomplishment. dmt vape pen uk
I have bookmarked your blog, the articles are way better than other similar blogs.. thanks for a great blog! Onlyfans Free
I have bookmarked your blog, the articles are way better than other similar blogs.. thanks for a great blog! Onlyfans Free
Make your travel dreams a reality with Expedia discount codes. Save on flights, accommodations, and car rentals when you book through Expedia. Whether heading to Japan, Europe, or the Philippines, our discount codes ensure you get the best prices and enjoy your trip for less. 익스피디아 쿠폰
If you are looking for more information about flat rate locksmith Las Vegas check that right away. slot bet 300
Hello, this weekend is good for me, since this time i am reading this enormous informative article here at my home. High quality replica jerseys
Superb blog post. Any place strikes numerous pressing obstacles of your modern culture. People can not be uninvolved that will those obstacles. The place delivers guidelines together with thoughts. Rather interesting together with handy.намерете повече информация
Discover the joy of owning a teacup Chihuahua! Our puppies for sale are raised in a loving environment and come with a health guarantee. Each puppy is AKC registered and ready to become your new best friend. Make a down payment today to reserve your perfect companion and enjoy their love. Teacup Chihuahuas for Sale
Our Chihuahua puppies are raised in a loving home, ensuring they are well-socialized and happy. Each puppy comes vaccinated, microchipped, and ready to join their forever family. Browse our selection of Chihuahua puppies for sale and bring home a delightful companion! Chihuahuas for sale near me
I just couldn't leave your website before telling you that I truly enjoyed the top quality info you present to your visitors? Will be back again frequently to check up on new posts. poduszka dekoracyjna