
아파치 카프카의 유래 🧑💻
아파치 카프카(Apache Kafka)는 미국의 대표적인 비즈니스 인맥 소셜네트워크 서비스인 링크드인(linkedin)에서 처음 출발한 기술로, 제이 크랩스(Jay Kreps), 니하 나케디(Neha Narkhede), 준 라오(Jun Rao) 와 함께 팀을 구성하여 모든 시스템으로 데이터를 전송할 수 있고, 실시간 처리도 가능하며, 급속도로 성장하는 서비스를 위해 확장이 용이한 시스템입니다.
초기 아파치 카프카의 목표
이 팀의 목표 4가지를 가지고 새로운 시스템을 만들었습니다.
- 프로듀서와 컨슈머의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일아웃이 가능한 시스템
왜 이런 4가지의 목표를 가지고 시스템을 만들었는지는 카프카에 관심을 가지게 된 사람이라면 어느정도 예상이 가능합니다.
링크드인은 전 세계적으로 인기가 많아짐에 따라서 시스템의 구성도가 매우 복잡해지고 있었으며, 서비스가 점차 커지면서 자연스럽게 데이터 스토어가 분화됩니다. 그에 따라서 복잡도가 증가 할 수 밖에 없고, 데이터 파이프라인의 관리가 어려워졌습니다. 처음에는 각자 목적에 맞게 만들었지만, 통합하는 파이프라인이 생기고 데이터 파이프라인마다 포멧과 처리하는 방법이 달라질 수 있어서 파이프라인을 확장하기가 매우 어려웠습니다. 또한 파이프라인의 포멧과 처리하는 방법을 맞추고 처리하다보면 데이터의 신뢰도 마저 낮아 질 수 있습니다. 그래서 링크드인에서는 서비스가 확장됨에 따라서 복잡도와 데이터 파이프라인의 관리를 쉽게 할 수 있도록 시스템을 만들게 된 것 입니다.
카프카를 적용한 시스템 👨🏫
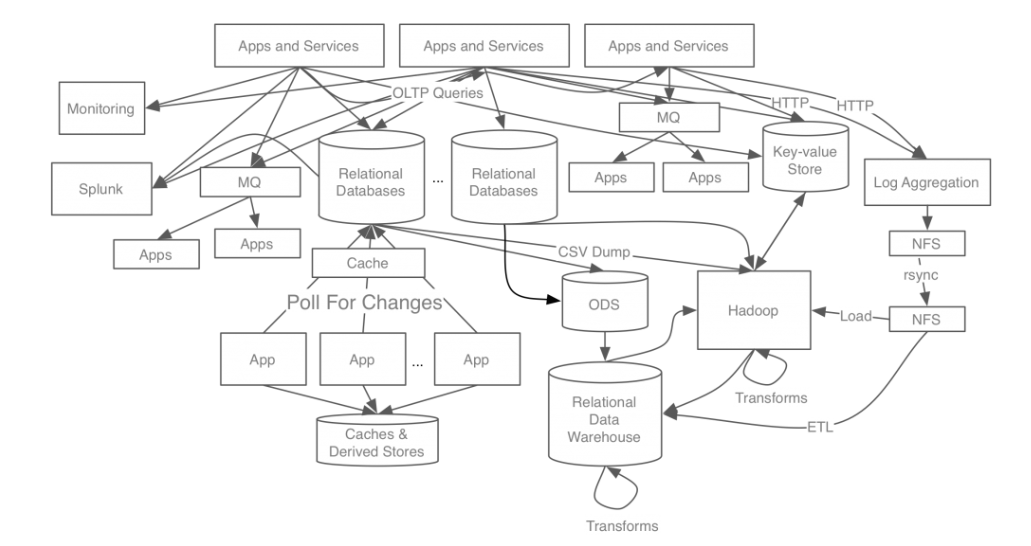
과거 링크드인 시스템
카프카를 이용한 링크드인 시스템
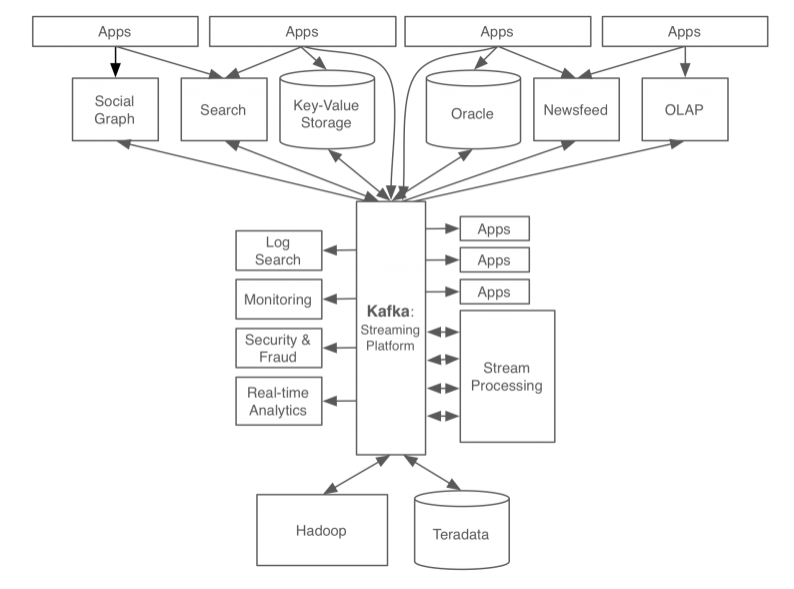
위 사진은 실제 링크드인에서 카프카를 적용하기 전과 후를 보여주는 사진으로 눈으로 봐도 시스템의 복잡도가 낮아지는 것을 확인 할 수 있다. 또한 카프카는 중간에서 데이터를 전송해주는 일종의 메시징 시스템으로 모든 노드에 신뢰성있게 데이터를 전송 할 수 있도록 도움을 주는것을 확인 할 수 있다.
이처럼 카프카는 매우 유용한 대용량, 대규모 메시지 데이터를 빠르게 처리하도록 개발된 메시징 플랫폼으로 현재 인기가 많다. 이를 뒷받침해주는 걸로 아파치 카프카의 최근 5년간 구글 트랜드 그래프와 깃허브 스타 수, 스택오버플로에서 질문 수 들이 있습니다.
이제 이 인기있는 메시징 플랫폼을 알아보도록 합시다.
REFERENCE
해당 글의 모든 레퍼런스는 "카프카, 데이터 플랫폼의 최강자" (고승범, 공용준 지음) 을 알립니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
